
Sostituire DFS Replication con Azure File Sync: dalla replica locale di Windows Server alla sincronizzazione ibrida nel cloud
Molte infrastrutture Windows oggi usano DFS Replication (DFSR) per replicare file tra server (spesso con namespace DFS-N). Tuttavia DFSR presenta dei limiti, soprattutto su larga scala, in scenari WAN con latenza, gestione del riavvio, failover, consapevolezza della rete e backup centralizzato.
Azure File Sync (AFS) può diventare un ottimo sostituto o complemento: mantiene la compatibilità SMB/Windows, consente un backup centralizzato su Azure Files, offre il cloud tiering per ridurre lo storage on-premises e semplifica la continuità e la scalabilità della replica su sedi remote.
Questa guida mostra come migrare un deployment DFSR a Azure File Sync mantenendo le best practice e minimizzando i rischi (e il downtime).
Architettura di Azure File Sync
Lo schema qui di seguito mostra il funzionamento di Azure File Sync, in cui uno o più file server locali (registrati tramite l’agente Azure File Sync) sincronizzano i dati con un Azure Storage Account tramite il Storage Sync Service.
Ogni gruppo di sincronizzazione (Sync Group) collega una specifica cartella locale (Server Endpoint) a una share cloud (Cloud Endpoint).
I dati archiviati nel cloud possono inoltre essere protetti tramite Azure Backup, garantendo sicurezza e ridondanza.
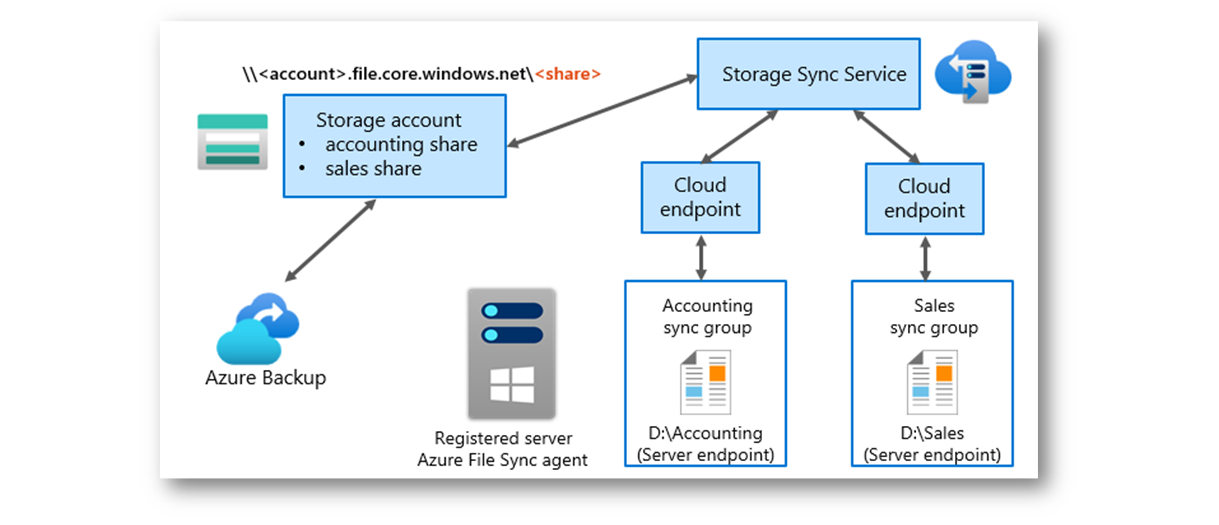
Figura 1: Architettura di Azure File Sync
Vantaggi di usare Azure File Sync al posto di DFSR
Prima di entrare nei dettagli operativi, vale la pena riassumere i principali benefici di AFS rispetto a DFSR:
| Vantaggio | Spiegazione |
| Replica verso il cloud / backup centralizzato | AFS sincronizza i dati con Azure File Share, consentendo backup e conservazione a livello centrale. |
| Riduzione dello storage on-premises (cloud tiering) | I file meno usati possono essere lasciati “solo in cloud” liberando spazio locale dinamicamente. |
| Recupero di namespace + rapid restore | In caso di danni locali, si può ricostruire velocemente un server usando la copia cloud come fonte. |
| Scalabilità geografica | Nuovi server in sedi remote possono essere aggiunti facilmente come “registered servers” al gruppo di sincronizzazione. |
| Meno sensibilità alla latenza WAN | Le modifiche vengono sincronizzate in Azure e propagate ai server, riducendo il “rimbalzo” DFSR su link lenti. |
Microsoft afferma che AFS e DFSR possono coesistere durante la migrazione, ma AFS tende a rimpiazzare DFSR perché offre queste funzionalità aggiuntive.
Introduzione a DFS-N e DFS Replication
Prima di affrontare la migrazione verso Azure File Sync, è utile ripassare brevemente i componenti principali della tecnologia DFS (Distributed File System) integrata in Windows Server, in particolare DFS Namespaces (DFS-N) e DFS Replication (DFSR).
DFS Namespaces (DFS-N)
DFS-N consente di raggruppare in un unico spazio dei nomi logico (namespace) le condivisioni presenti su più server. In pratica, permette agli utenti di accedere ai file tramite un percorso unificato (ad esempio \\azienda.local\documenti) anche se i dati reali sono distribuiti su più file server e percorsi fisici diversi.
Vantaggi principali:
- Semplifica l’accesso e la gestione delle condivisioni;
- Aumenta la trasparenza: l’utente non deve sapere dove si trovano realmente i file;
- Permette di spostare dati tra server senza modificare i percorsi di rete usati dagli utenti.
DFS Replication (DFSR)
DFSR è il servizio che consente la replica asincrona e multimaster dei dati tra due o più server che fanno parte di un replication group. Usa un algoritmo di compressione e differenziazione a livello di blocco (Remote Differential Compression) per replicare solo le modifiche, riducendo il traffico di rete.
È comunemente usato per:
- Mantenere copie aggiornate di cartelle condivise in sedi diverse;
- Fornire tolleranza ai guasti (fault tolerance) nei file server;
- Supportare i namespace DFS in scenari di alta disponibilità.
Tuttavia, DFSR presenta anche alcune limitazioni:
- La replica può diventare lenta su grandi volumi o con molti piccoli file;
- Non è pensata per ambienti con centinaia di sedi o connessioni WAN instabili;
- La risoluzione dei conflitti è elementare e può creare duplicati;
- Non esiste un’integrazione nativa con i servizi cloud per backup o tiering.
Proprio per superare questi limiti, Microsoft ha introdotto Azure File Sync, che estende i concetti di replica e sincronizzazione verso il cloud, mantenendo la compatibilità SMB di Windows Server ma aggiungendo funzionalità di livello enterprise come il cloud tiering, la replica globale e il backup centralizzato.
Nella presente guida non tratterò la creazione dell’ambiente DFS (né la configurazione di DFS-N né la creazione della replica DFSR). Per questi passaggi vi rimando direttamente alla documentazione ufficiale Microsoft:
- Guida Microsoft per il deployment di DFS Namespaces (creazione del namespace, aggiunta di target, tipo domain-based o stand-alone): Deploying DFS Namespaces | Microsoft Learn
- Panoramica e installazione di DFS Replication (requisiti, installazione via Server Manager o PowerShell, configurazione di gruppi di replica): Install Distributed File System (DFS) Replication on Windows Server | Microsoft Learn
- Documentazione di riferimento generale su DFS-N + DFSR: DFS Namespaces and DFS Replication Overview | Microsoft Learn
Passaggi di migrazione (high-level)
La migrazione può essere suddivisa in queste fasi:
- Preparazione in Azure (storage account, file share, servizio Azure File Sync)
- Creazione del Sync Group che rispecchia la topologia DFSR
- Installazione dell’agente AFS sul server principale (che contiene la copia completa)
- Registrazione del server e creazione del primo Server Endpoint (senza abilitare cloud tiering)
- Attendere la sincronizzazione completa verso Azure (Cloud Endpoint)
- Installazione dell’agente AFS sugli altri server DFSR rimanenti
- Disabilitazione della replica DFSR
- Creazione dei Server Endpoint su ciascun server migrato (senza tiering inizialmente)
- Verifica sincronizzazione completa, test dei failover e cut-over
- Ritiro definitivo di DFSR e abilitazione cloud tiering ove desiderato
Nell’immagine sotto potete vedere la console di DFS Management di Windows Server, che mostra la configurazione iniziale dell’ambiente di partenza. È presente un namespace denominato \\Contoso.com\Root\Data, al quale sono associati due folder target, rispettivamente sui server SEA-SVR1 e SEA-SVR2, entrambi con replica abilitata. 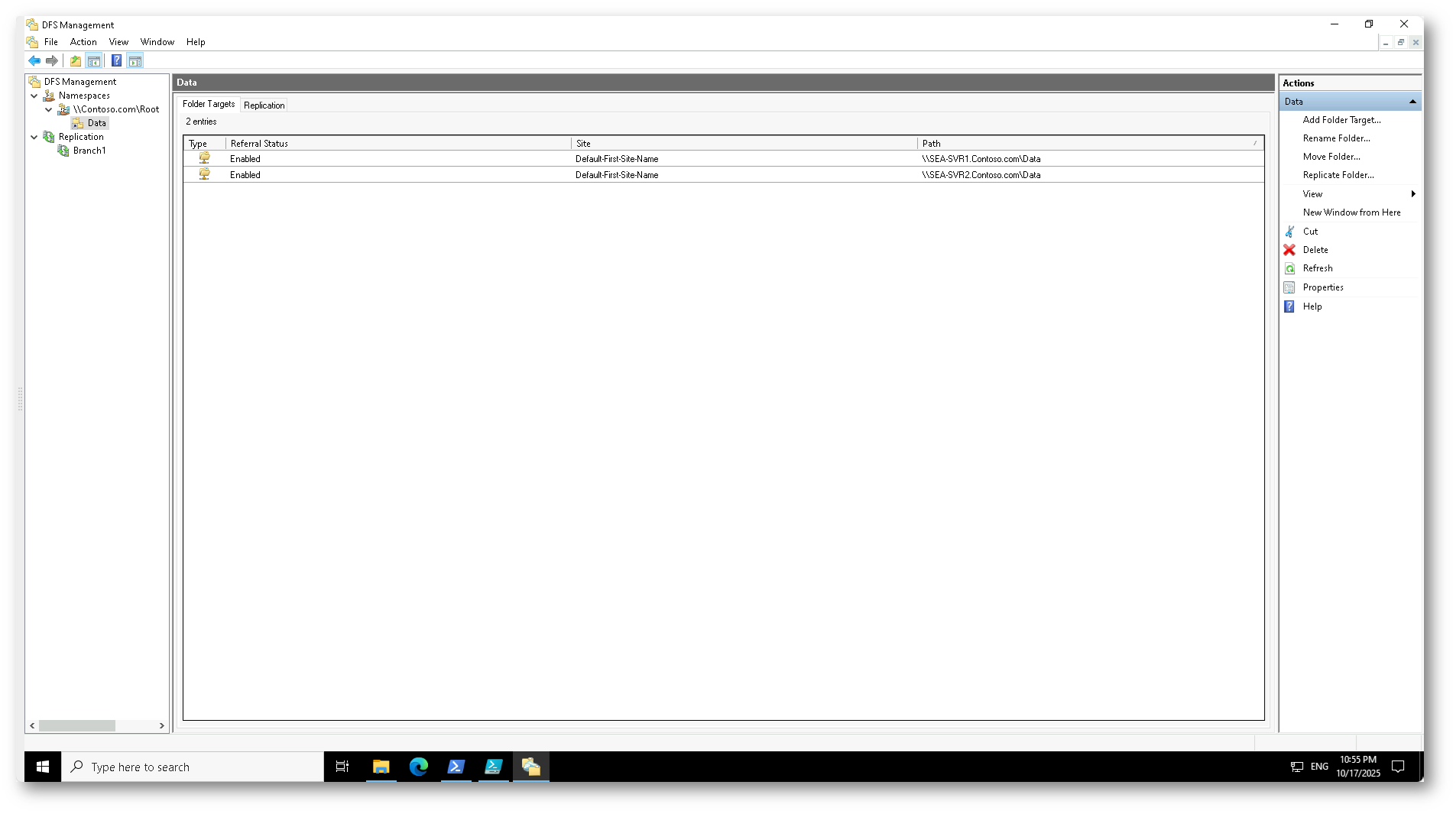
Figura 2: Configurazione iniziale di DFS Management con due folder target replicati (SEA-SVR1 e SEA-SVR2) nel namespace \Contoso.com\Root\Data
Nella foto sotto è mostrata la sezione Replication della console DFS Management, con il gruppo di replica denominato Branch1. Il gruppo include due membri: i server SEA-SVR1 e SEA-SVR2, entrambi con lo stato di membership impostato su Enabled. La cartella replicata è denominata Data e si trova nel percorso locale S:\Data su entrambi i server.
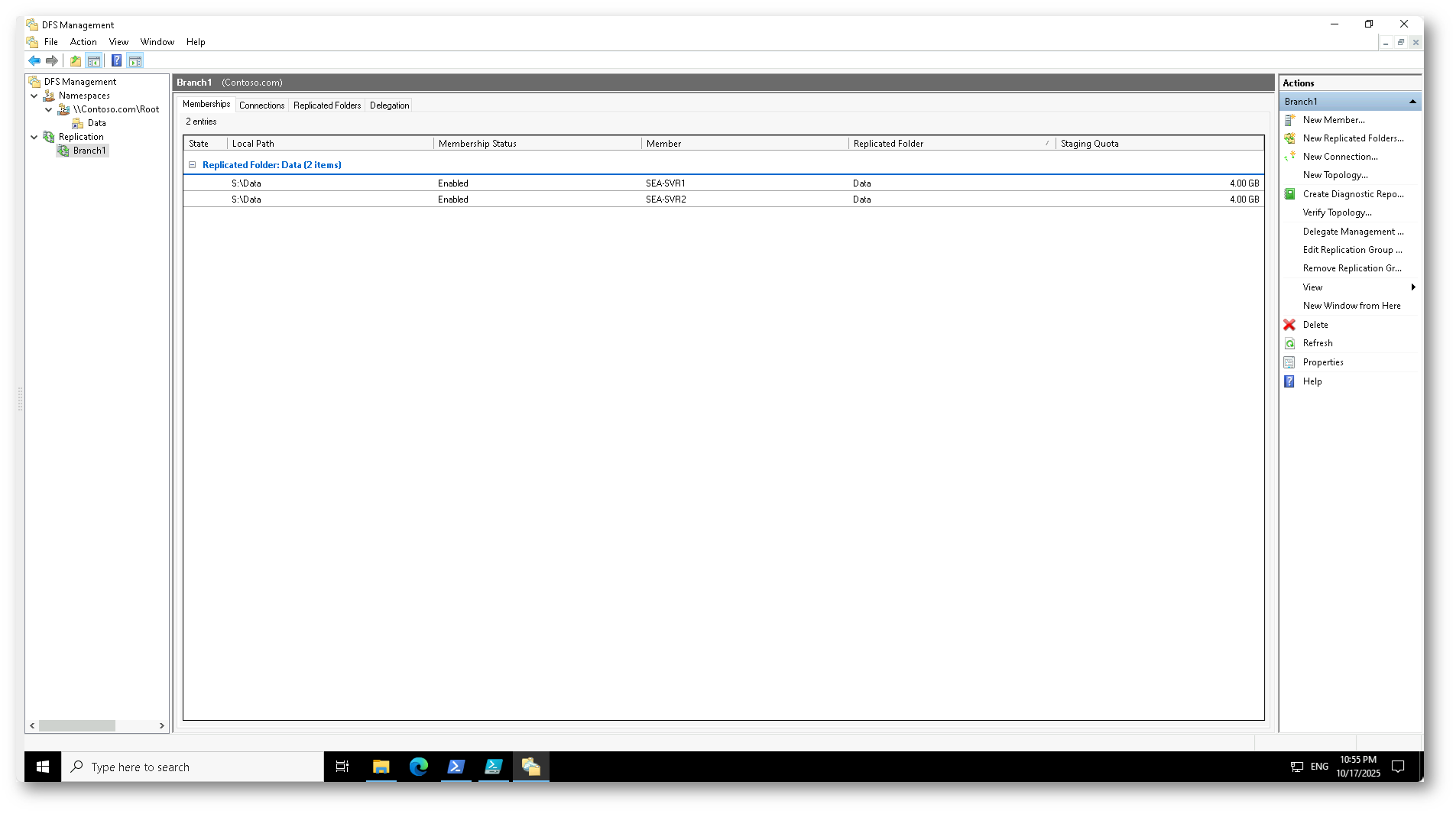
Figura 3: Vista del gruppo di replica DFSR “Branch1”, con i server SEA-SVR1 e SEA-SVR2 che replicano la cartella Data tramite DFS Replication
Creazione dello Storage Account su Azure
Per poter configurare Azure File Sync è necessario disporre di uno Storage Account su Azure. Questo servizio fungerà da repository centrale per i vostri file, ospitando la Azure File Share che sarà sincronizzata con i server on-premises.
Accedete al portale di Azure e aprite la sezione Storage accounts dal menu laterale. Se non sono ancora presenti account configurati, selezionate il pulsante Create storage account per avviare la procedura guidata di creazione.
Figura 4: Vista iniziale del portale Azure, sezione Storage accounts: creazione di un nuovo account di archiviazione
Nella prima scheda Basics del wizard dovrete specificare i parametri fondamentali del vostro storage account.
Scegliete la subscription e il resource group da utilizzare (potete crearne uno nuovo se necessario). Assegnate quindi un nome allo storage account e selezionate la region più vicina alla vostra infrastruttura locale, nel mio caso (Europe) Italy North.
Per il tipo di account, lasciate il valore predefinito StorageV2 (general purpose v2). Impostate la Performance su Standard (sufficiente nella maggior parte degli scenari) e la Redundancy su Locally-redundant storage (LRS) per mantenere tre copie locali dei dati all’interno del datacenter scelto.
Figura 5: Configurazione dei parametri principali dello storage account, inclusi nome, area geografica e impostazioni di ridondanza
Nelle schede successive potete lasciare le impostazioni predefinite. Quando arrivate alla sezione Review + create, il portale mostrerà un riepilogo di tutte le opzioni configurate.
Controllate attentamente che i parametri siano corretti e poi selezionate Create per avviare la distribuzione della risorsa.
Figura 6: Riepilogo finale e conferma di creazione dello storage account su Azure
Una volta completato il deployment, aprite lo storage account appena creato per verificarne la configurazione.
Da questa schermata potete controllare i dettagli generali (nome, area, tipo di replica, livello di prestazioni) e accedere ai servizi disponibili, come File shares, Blobs, Tables e Queues.
Nel nostro caso ci concentreremo sul servizio File shares, che sarà utilizzato per creare la condivisione cloud da sincronizzare con i file server on-premises.
Figura 7: Storage account creato e pronto all’uso: overview delle impostazioni principali e dei servizi abilitati, inclusi i file share per Azure File Sync
Creazione della Azure File Share
Dopo aver configurato lo Storage Account, il passo successivo consiste nel creare una Azure File Share. Questa condivisione rappresenterà il punto centrale di sincronizzazione dei file provenienti dai vostri server locali.
All’interno dello storage account appena creato, aprite la sezione File shares dal menu di sinistra. Da qui potete gestire tutte le condivisioni SMB ospitate nello storage account.
Per crearne una nuova, fate clic su + File share e assegnate un nome descrittivo alla condivisione (ad esempio share1). Potete mantenere le impostazioni predefinite per il livello di accesso (Transaction optimized) e per la capacità massima, che di default è impostata su 100 TiB.
Figura 8: Creazione di una nuova Azure File Share all’interno dello storage account, pronta per essere sincronizzata con i file server on-premises
Una volta creata la condivisione, apritela per accedere alla schermata di gestione. Da qui potete caricare file, configurare snapshot, modificare i livelli di accesso e, soprattutto, ottenere le informazioni necessarie per connettere la share da Windows Server.
Fate clic su Connect: si aprirà un pannello laterale che mostra le opzioni di connessione per Windows, Linux e macOS. Selezionate Windows e poi Show Script per visualizzare il comando PowerShell che consente di mappare la share come unità di rete (ad esempio, come drive Z:).
Questo script verifica la connettività verso la porta TCP 445 (necessaria per SMB 3.0) e, se disponibile, monta in modo persistente la condivisione.
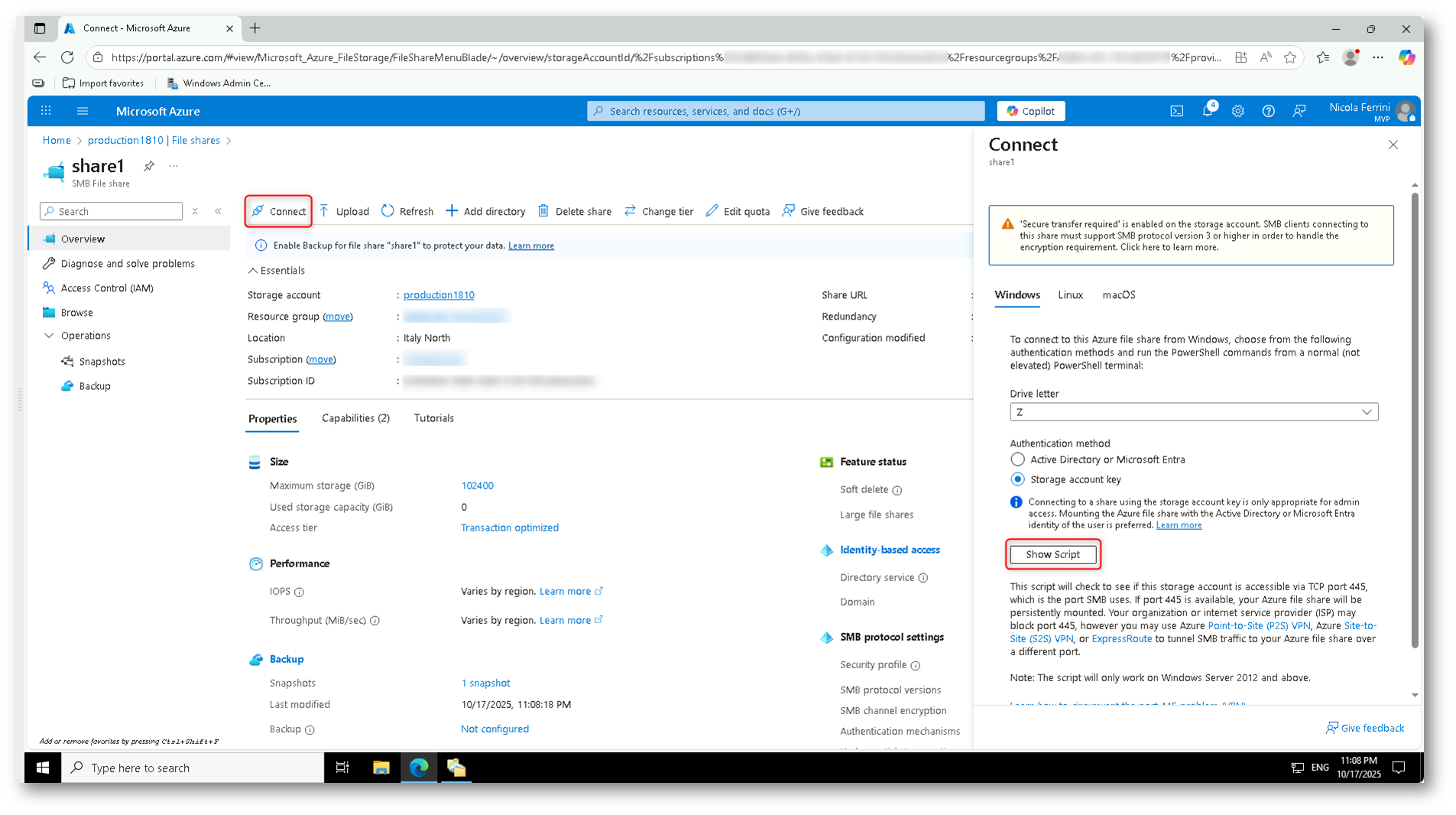
Figura 9: Connessione alla Azure File Share e generazione dello script PowerShell per il mapping da Windows Server
Dopo aver eseguito lo script PowerShell fornito dal portale di Azure, la condivisione è ora correttamente mappata come unità di rete sul server locale.
Potete verificare la connessione aprendo File Explorer, dove la Azure File Share appare tra le risorse del computer con la lettera di unità assegnata (nel nostro esempio Z:).
Differenza tra connessione amministrativa e accesso utente per le Azure File Share
Lo script PowerShell generato dal portale di Azure, che utilizza le chiavi di accesso dello storage account, serve esclusivamente per verificare la connettività o eseguire test amministrativi. In questa fase, la connessione viene stabilita direttamente verso la Azure File Share tramite SMB 3.0 e autenticazione a livello di storage, non tramite Active Directory.
Gli utenti finali, invece, non accedono alla Azure File Share in modo diretto, ma continuano a lavorare tramite le condivisioni SMB dei loro file server locali. I permessi NTFS e le ACL di Active Directory restano pienamente validi, poiché è il servizio Azure File Sync a sincronizzare sia i file che le autorizzazioni con la share cloud.
Se si desidera consentire l’accesso diretto alle Azure File Shares (senza passare dai file server), sarà necessario abilitare l’integrazione con Active Director , così da mantenere la stessa gestione di autenticazione e permessi.
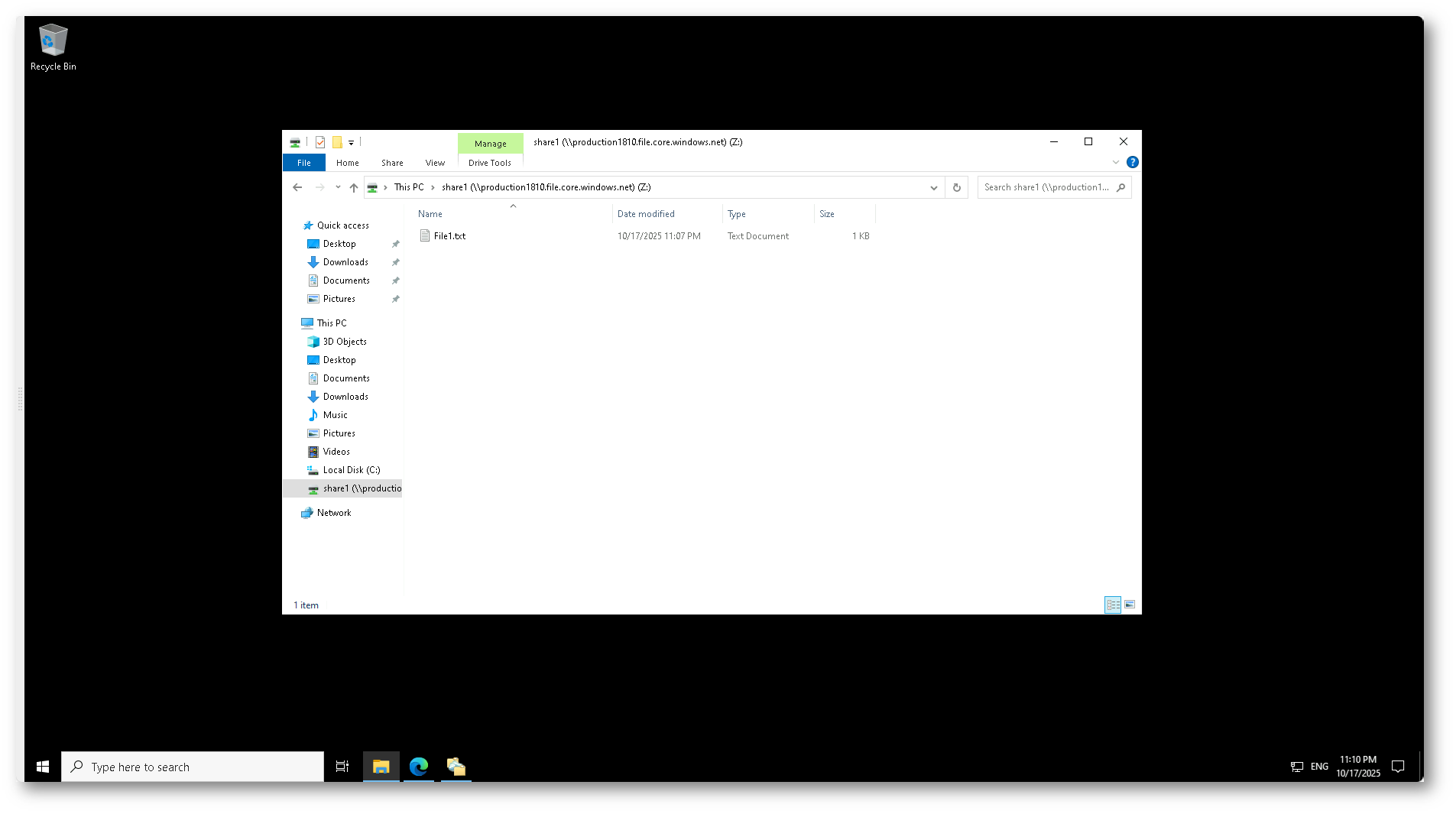
Figura 10: Connessione completata alla Azure File Share tramite SMB: la condivisione è montata come unità di rete e pronta all’uso
Distribuzione del servizio Azure File Sync e creazione del gruppo di sincronizzazione
Una volta pronta la Azure File Share, il passo successivo è configurare Azure File Sync, il servizio che permetterà di collegare i file server locali alla condivisione cloud e di gestire la sincronizzazione dei dati.
Accedete al portale di Azure e aprite la sezione Storage center → File Sync. Qui vengono elencati tutti i servizi di sincronizzazione disponibili nella sottoscrizione; se non ne avete ancora configurato uno, selezionate + Create storage sync service per iniziare la procedura guidata.
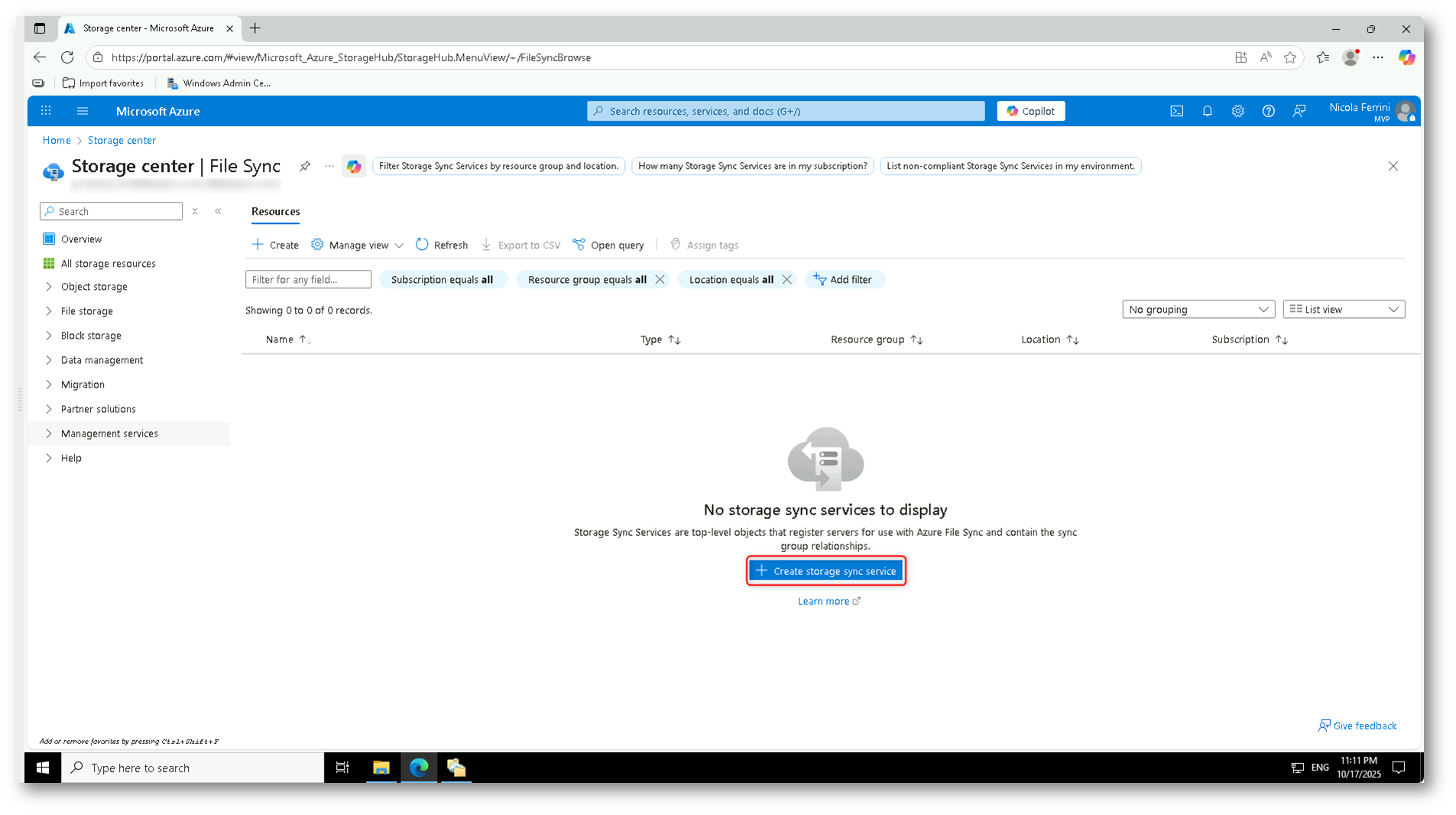
Figura 11: Creazione di un nuovo servizio Azure File Sync dal portale di Azure
Nella schermata Deploy Azure File Sync inserite i dettagli richiesti: scegliete la subscription, il resource group, assegnate un nome al servizio (ad esempio ItalySync) e selezionate la regione più vicina ai vostri file server, nel mio caso (Italy North).
Lasciate invariate le impostazioni di rete e proseguite con Review + Create per confermare la configurazione.
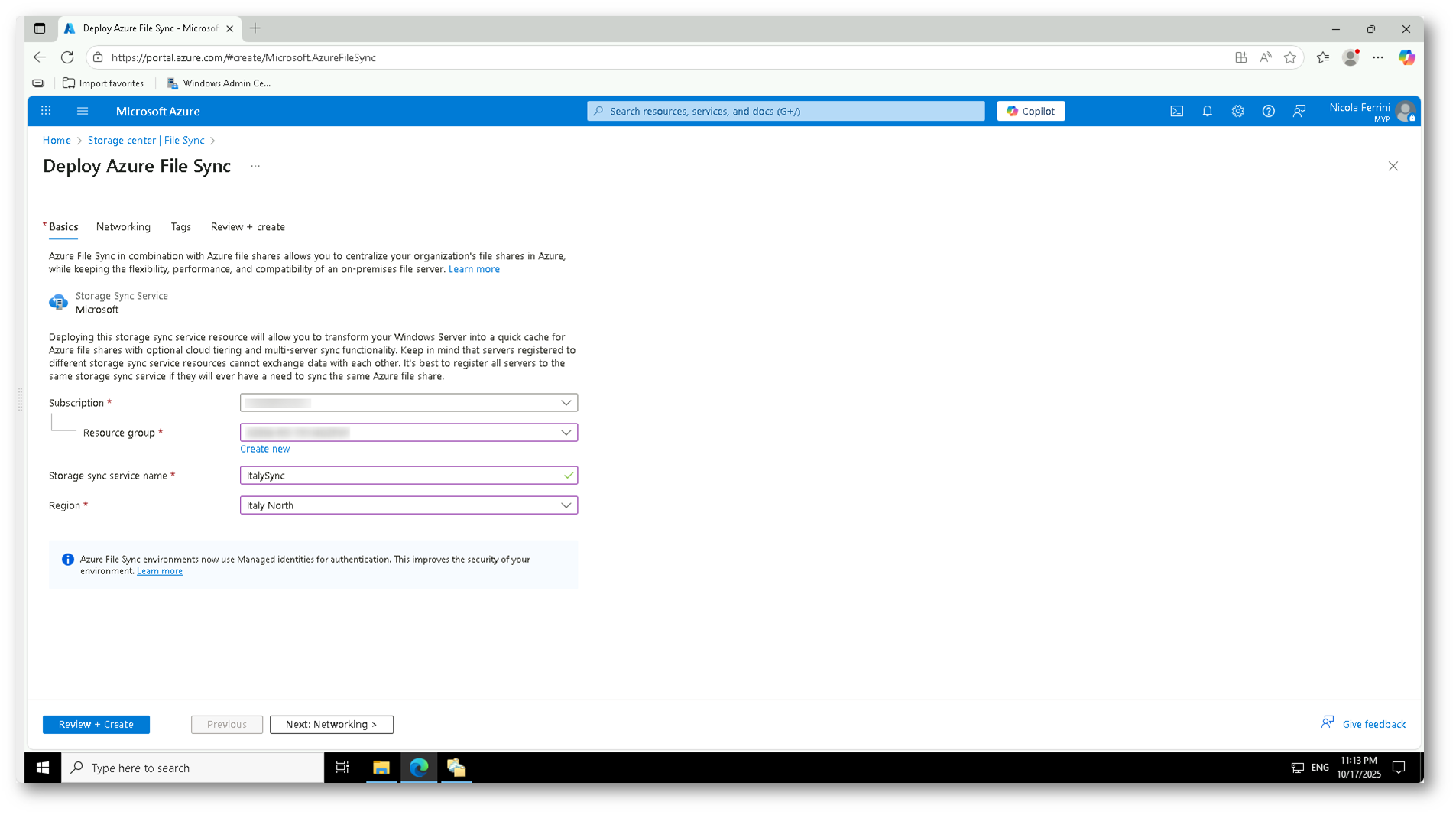
Figura 12: Configurazione dei parametri di base del servizio Azure File Sync, con assegnazione di nome e area geografica
Controllate il riepilogo dei parametri nella sezione Review + create e fate clic su Create per avviare il deployment del servizio. Dopo pochi minuti, il servizio sarà disponibile nel portale e potrà essere utilizzato per la creazione dei gruppi di sincronizzazione.
Figura 13: Riepilogo finale e avvio del deployment del servizio Azure File Sync
Una volta completata la creazione, aprite la risorsa per verificare che lo stato generale. In questa sezione potete monitorare i gruppi di sincronizzazione (Sync groups) e i server registrati (Registered servers), che al momento saranno ancora vuoti.
Figura 14: Servizio Azure File Sync creato e pronto all’uso
Configurazione del Sync Group
Il Sync Group rappresenta il collegamento logico tra la Azure File Share nel cloud e una o più cartelle locali sui vostri file server. In altre parole, è il componente che definisce quali dati devono essere sincronizzati e tra quali endpoint avviene la replica.
Quando create un Sync Group, state sostanzialmente stabilendo:
- Il cloud endpoint, cioè la Azure File Share che funge da repository centrale nel cloud;
- I server endpoint, cioè le cartelle locali sui vostri server Windows che parteciperanno alla sincronizzazione.
Tutti i membri dello stesso Sync Group condividono e mantengono sincronizzato lo stesso set di file: qualsiasi modifica apportata a un file su un server (ad esempio l’aggiunta, l’eliminazione o la modifica di un documento) viene automaticamente propagata verso Azure e poi distribuita agli altri server registrati nello stesso gruppo.
Questo approccio consente di sostituire la replica tradizionale di DFSR con una soluzione molto più flessibile e scalabile, in cui Azure diventa il punto di convergenza e distribuzione dei dati.
Dal menu laterale selezionate Sync groups e poi fate clic su + Create a sync group per avviare la procedura.
Figura 15: Creazione di un nuovo gruppo di sincronizzazione all’interno del servizio Azure File Sync
Nel modulo di configurazione specificate un nome per il gruppo (ad esempio SyncGroup1), selezionate la subscription, lo storage account e infine la Azure File Share creata in precedenza (share1).
Fate clic su Create per completare la creazione del gruppo.
Figura 16: Creazione di un nuovo gruppo di sincronizzazione all’interno del servizio Azure File Sync
Dopo qualche istante il nuovo gruppo comparirà nell’elenco dei Sync groups con stato Healthy, pronto per l’aggiunta dei server locali. Questo gruppo costituirà il punto di riferimento per collegare i vostri file server Windows, che diventeranno i server endpoints di Azure File Sync.
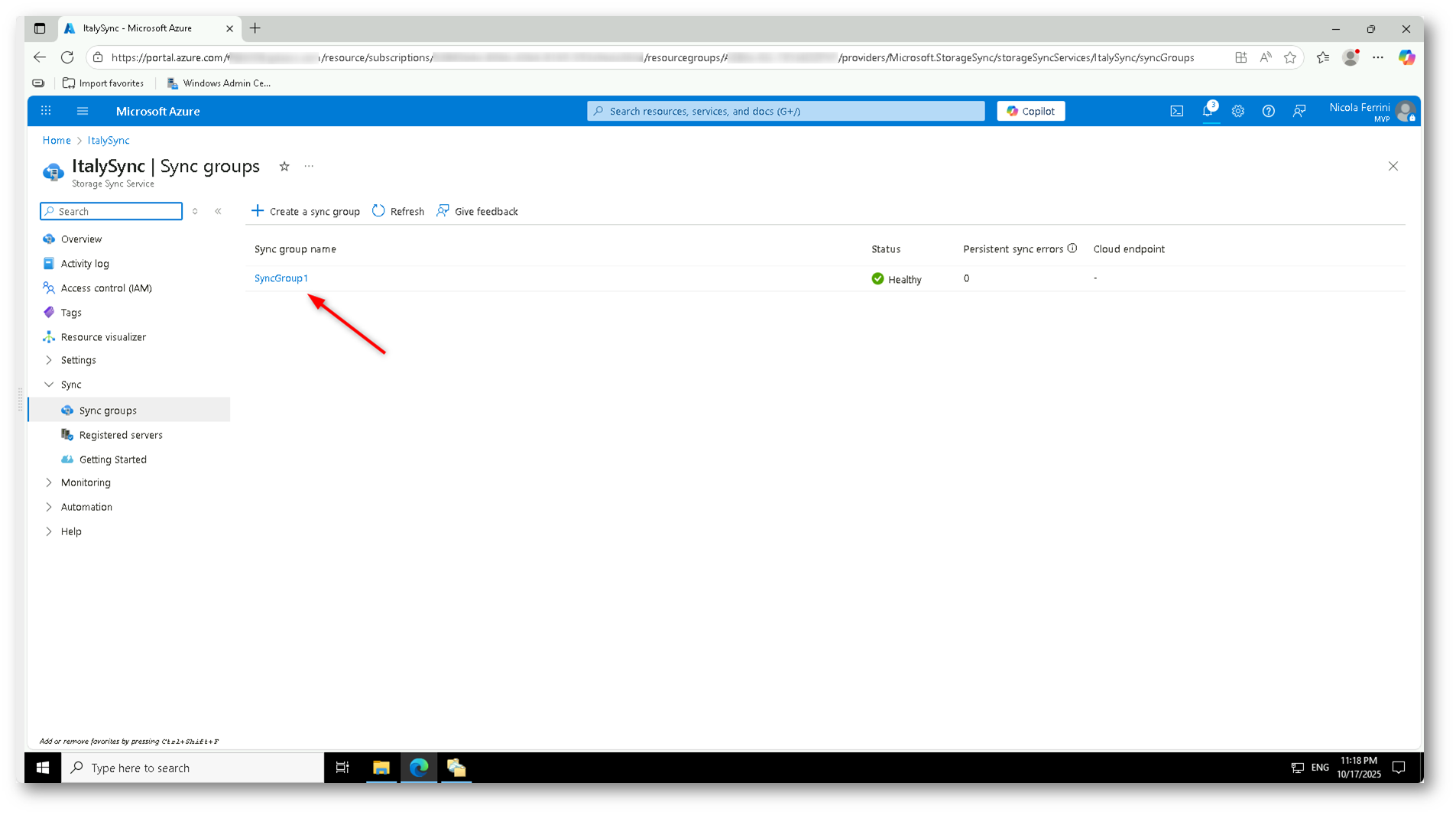
Figura 17: Sync Group creato correttamente e in stato Healthy, pronto per l’aggiunta dei server on-premises
Registrazione dei server Windows nel servizio Azure File Sync
Una volta creato il gruppo di sincronizzazione è necessario aggiungere i file server locali che dovranno sincronizzare i dati con la Azure File Share. Questa operazione si effettua installando l’Azure File Sync Agent su ciascun server Windows e registrandolo nel servizio creato in precedenza.
Dal portale di Azure, all’interno del servizio ItalySync aprite la sezione Registered servers e seguite il collegamento Download the Azure File Sync agent.
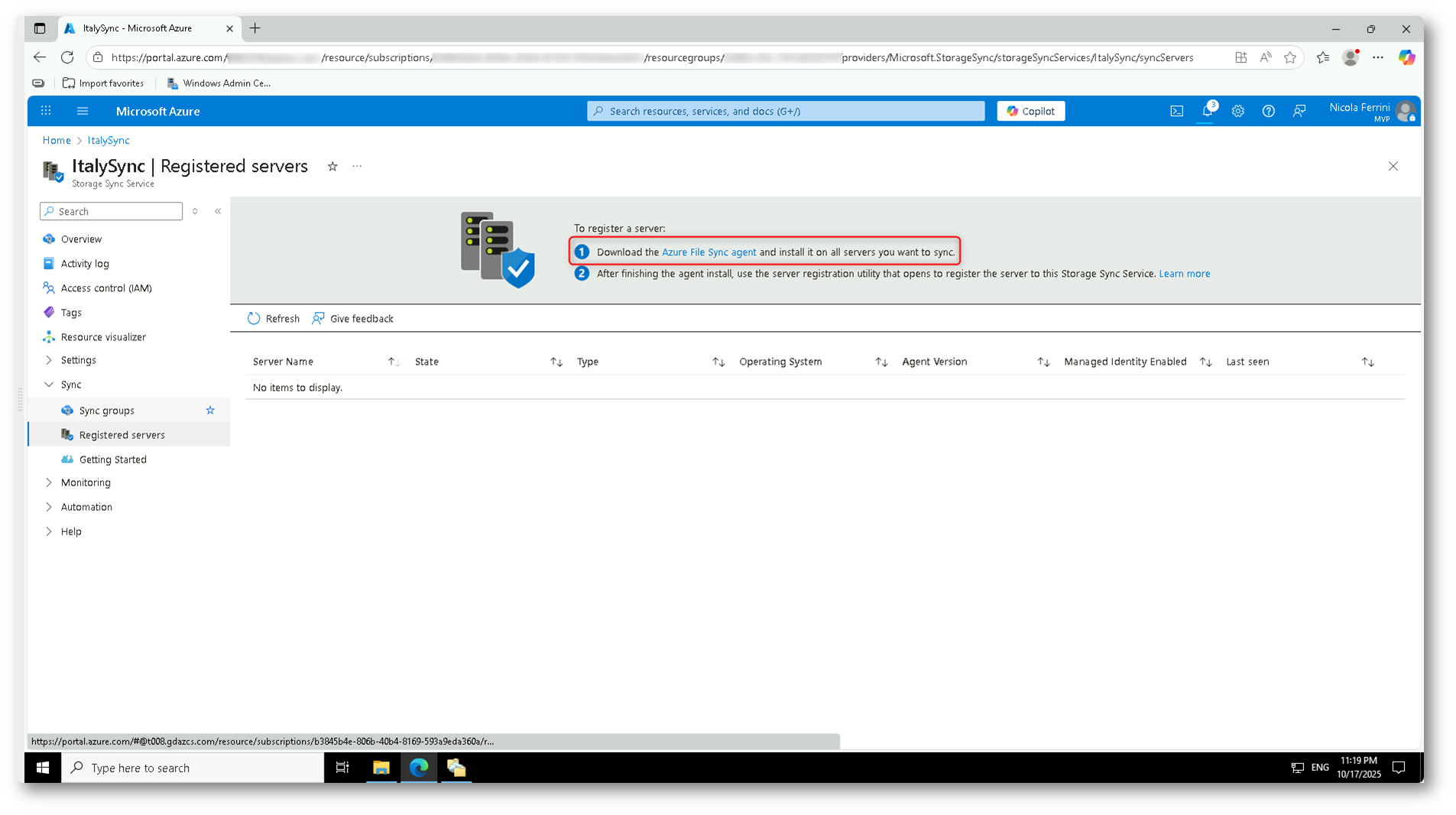
Figura 18: Download dell’agente Azure File Sync dal portale di Azure tramite collegamento al Microsoft Download Center
Il link vi porterà alla pagina ufficiale del Microsoft Download Center, da cui potete scaricare l’agente appropriato per la versione di Windows Server in uso.
Figura 19: Download dell’agente Azure File Sync dal portale di Azure tramite collegamento al Microsoft Download Center
Figura 20: Download dell’agente Azure File Sync dal portale di Azure tramite collegamento al Microsoft Download Center
Eseguite l’installer sul server che parteciperà alla sincronizzazione. Durante l’installazione, il setup provvederà a installare i componenti necessari e, al termine, verrà avviata automaticamente l’utilità di Server Registration.
Questa procedura guidata consente di collegare il server al servizio di sincronizzazione che avete creato nel portale (nel nostro caso ItalySync). Per completare la registrazione, dovrete accedere con un account con privilegi di amministratore su Azure e selezionare il tenant, la subscription e il resource group corretti.
Nel caso in cui il vostro file server utilizzi Windows Server Core, l’installazione dell’agente Azure File Sync dovrà essere eseguita tramite PowerShell.
In questo scenario, potete automatizzare l’intero processo, dall’installazione del pacchetto alla registrazione del server nel servizio Azure File Sync, utilizzando uno script come quello riportato di seguito.
Lo script crea una directory temporanea sul server, copia l’installer dell’agente, installa i moduli necessari per la comunicazione con Azure e registra automaticamente il server nel servizio ItalySync.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
$srvName = 'SEA-SVR1' $rgName = 'RGName' $fsName = 'ItalySync' New-Item -Type Directory -Path "\\$srvName\c$\Temp" -Force Copy-Item -Path C:\Labfiles\StorageSyncAgent_WS2022.msi -Destination "\\$srvName\c$\Temp\" -PassThru Invoke-Command -ComputerName $srvName -ArgumentList ($rgName, $fsName) { param($rgName, $fsName) Install-PackageProvider -Name NuGet -Force; Install-Module az.StorageSync -Force; Start-Process -FilePath "C:\Temp\StorageSyncAgent_WS2022.msi" -ArgumentList "/quiet" -Wait; Connect-AzAccount -UseDeviceAuthentication; Register-AzStorageSyncServer -ResourceGroupName $rgName -StorageSyncServiceName $fsName | Out-Null; Write-Output "Script finished" } |
Questo approccio risulta particolarmente utile in ambienti headless o gestiti da remoto, dove non è possibile utilizzare l’interfaccia grafica del setup. Al termine dell’esecuzione dello script, il server sarà automaticamente visibile nel portale di Azure all’interno della sezione Registered servers.
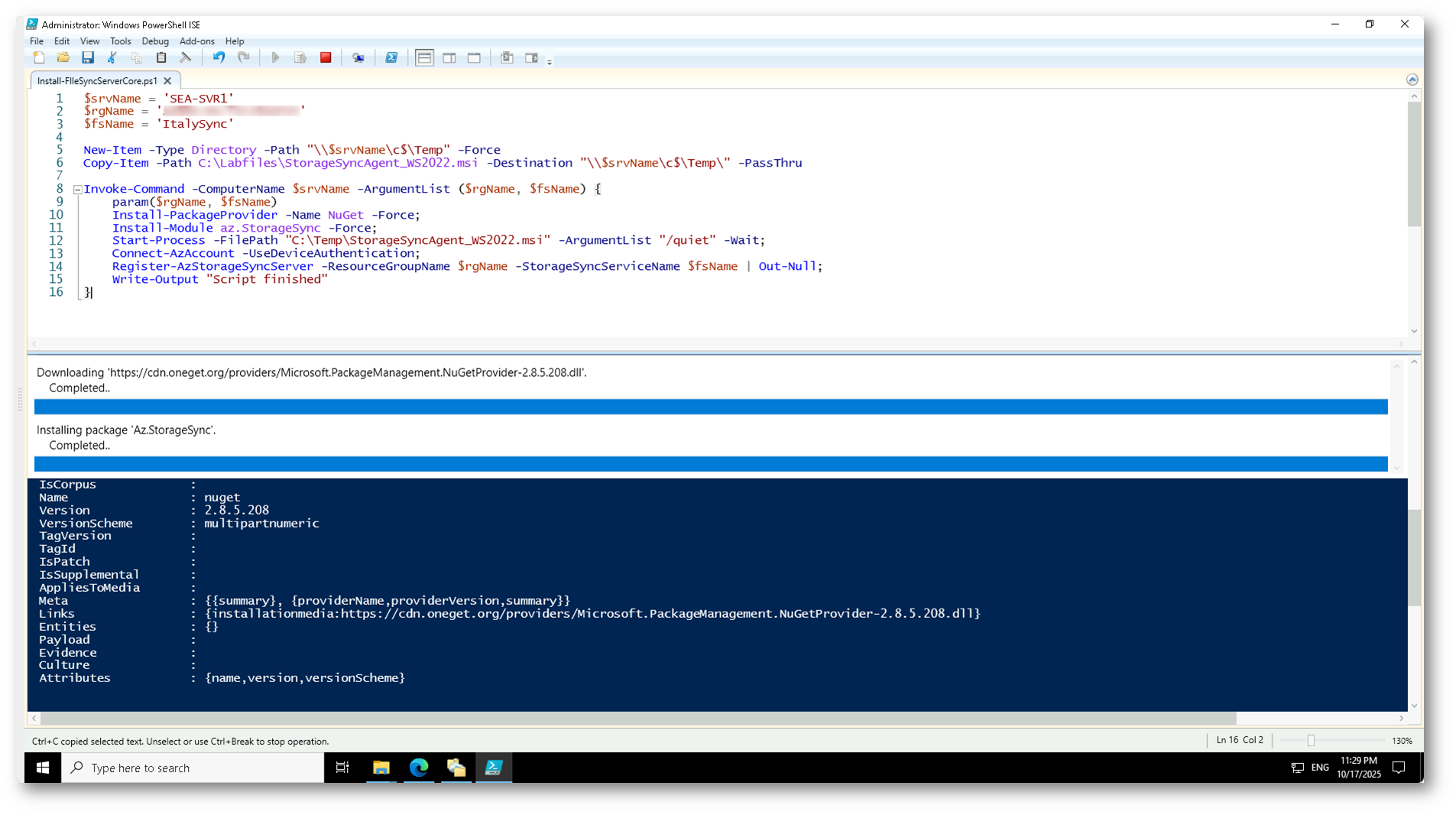
Figura 21: Installazione dell’agente Azure File Sync e registrazione automatica del primo server tramite PowerShell in ambiente Windows Server Core
L’intera procedura di installazione e registrazione dell’agente Azure File Sync richiede in genere un paio di minuti.
Nel portale di Azure comparirà il nome del server (SEA-SVR1.Contoso.com) nella sezione Registered servers del servizio ItalySync, con stato Online.
Questo conferma che il server è correttamente connesso al servizio Azure File Sync e pronto per essere associato a un Sync Group come server endpoint.
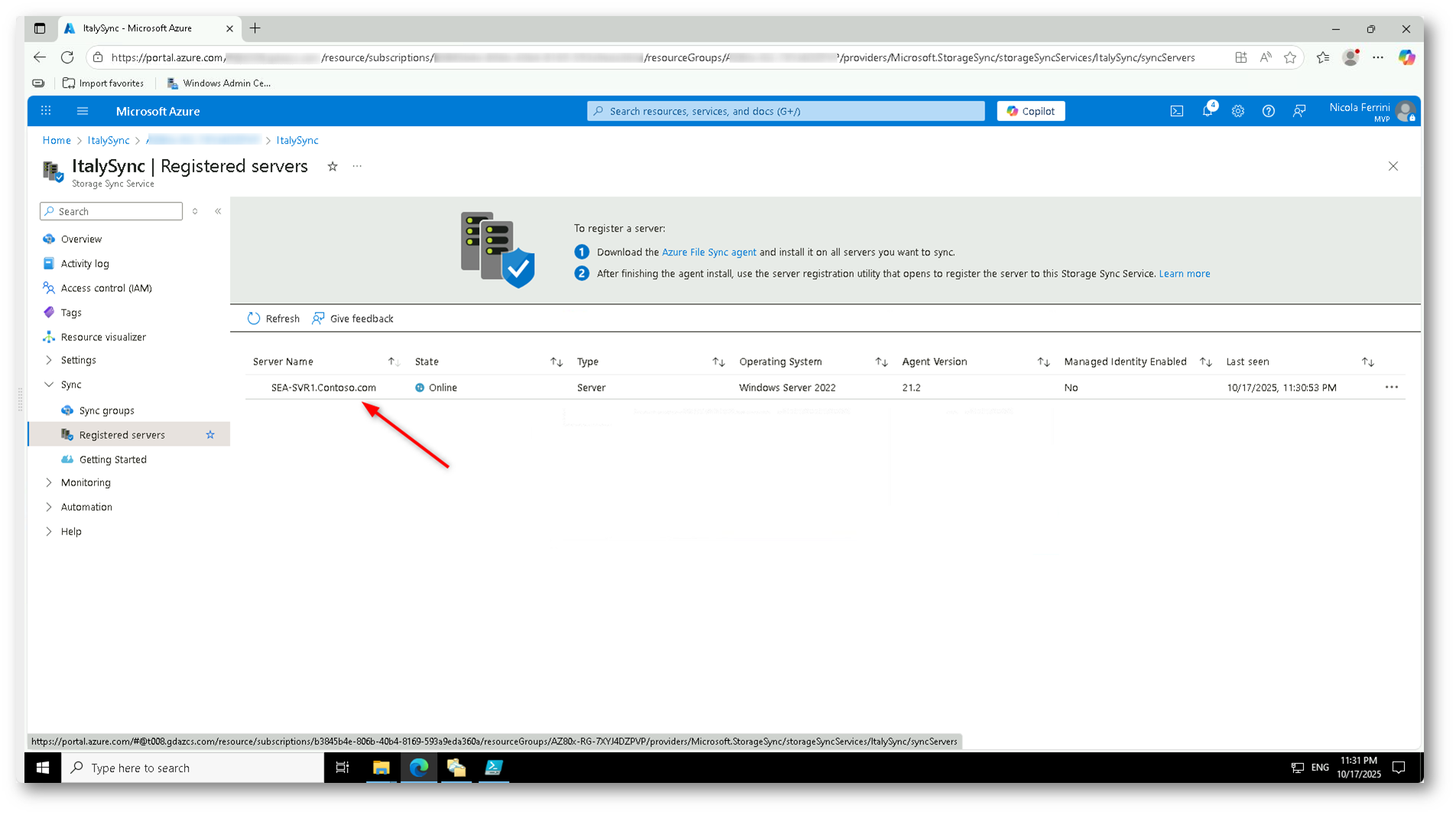
Figura 22: Verifica nel portale Azure dell’avvenuta registrazione del server SEA-SVR1 nel servizio di sincronizzazione ItalySync.
Potete ora procedere con la registrazione del secondo server, seguendo lo stesso processo utilizzato per il primo.
Figura 23: Installazione dell’agente Azure File Sync e registrazione automatica del secondo server tramite PowerShell in ambiente Windows Server Core
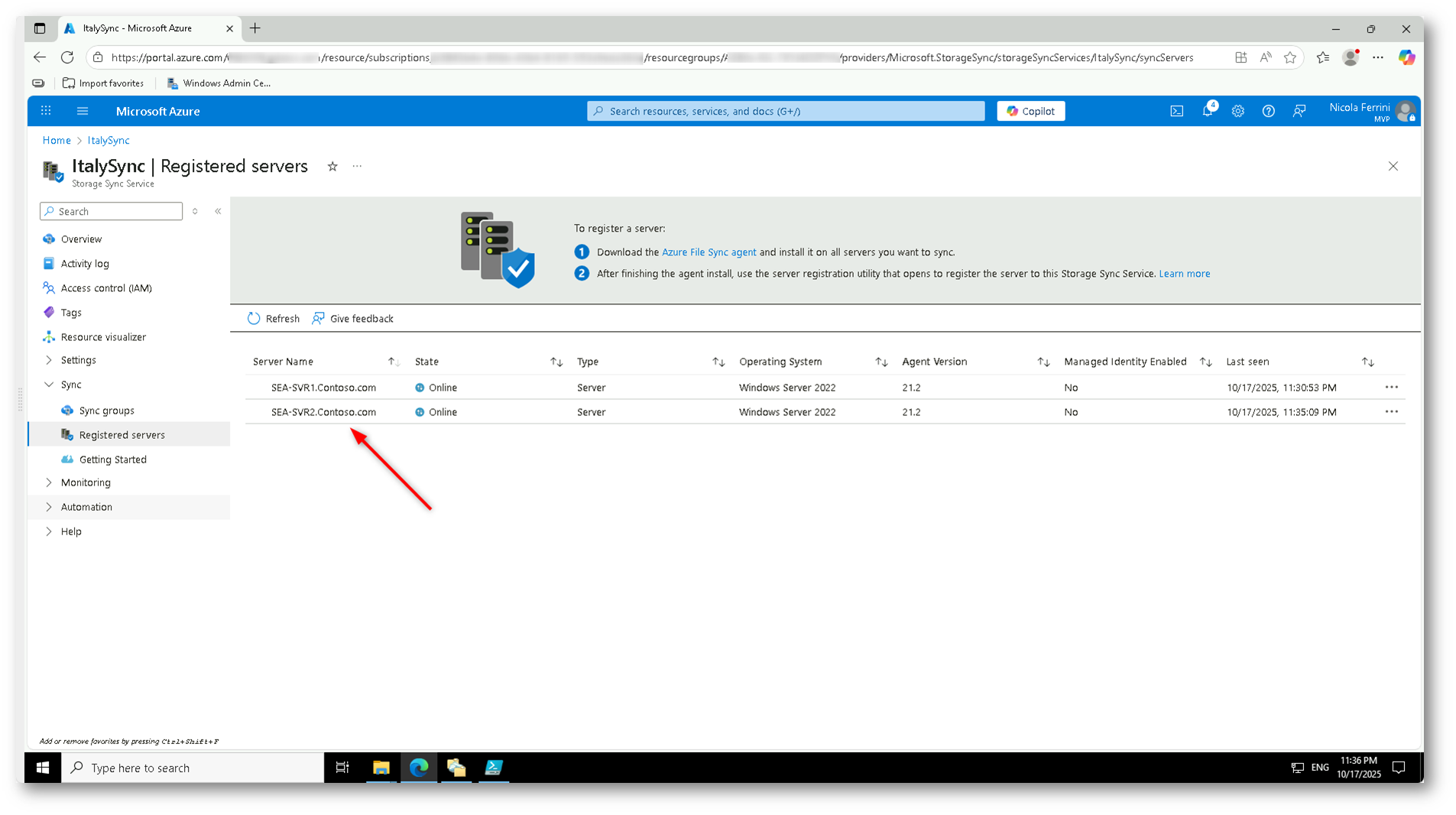
Figura 24 Registrazione completata del secondo file server SEA-SVR2. Entrambi i server risultano online e pronti alla sincronizzazione tramite Azure File Sync
Ora è il momento di aggiungere il server SEA-SVR1 come server endpoint nel gruppo di sincronizzazione.
Un server endpoint è una cartella su un server Windows collegata a un gruppo di sincronizzazione (Sync Group) in Azure File Sync. Rappresenta il punto locale dove i file vengono sincronizzati con l’Azure File Share nel cloud, mantenendo i dati aggiornati sia in locale che su Azure.
Nel portale di Azure, all’interno del gruppo SyncGroup1, selezionate Add server endpoint e compilate i campi come segue:
- Registered Server → scegliete SEA-SVR1.Contoso.com.
- Path → specificate la cartella locale che verrà sincronizzata (es. C:\Share).
- Cloud Tiering → abilitate l’opzione Enable cloud tiering se volete ottimizzare lo spazio sul server.
- Quando è attivo, solo i file usati più di recente rimangono in locale, mentre gli altri restano su Azure e vengono scaricati su richiesta.
- Quando è disattivato, tutti i file restano fisicamente sul disco locale.
Consigliato abilitarlo se lo spazio su disco è limitato o se l’intero dataset non deve essere sempre disponibile in locale.
- Volume Free Space Policy → impostate la percentuale minima di spazio libero da mantenere sul volume (es. 20%). Azure File Sync libererà automaticamente spazio sostituendo i file meno usati con segnaposto.
- Data Policy → abilitate l’opzione Recall files per mantenere in locale solo i file modificati o utilizzati negli ultimi n giorni (es. 10 giorni).
- Initial Sync / Initial Download → scegliete come scaricare i file dal cloud verso il server alla prima sincronizzazione:
- Namespace only: scarica solo la struttura di cartelle e nomi file, ideale per ambienti con spazio ridotto o molti dati “archiviati”.
- Partial or full download: scarica anche il contenuto dei file, utile se il server deve offrire subito accesso completo ai dati.
In generale, la modalità “Namespace only” è perfetta per i branch office o file server con spazio limitato, mentre il download completo è indicato per i server centrali o ambienti dove la disponibilità immediata dei file è prioritaria.
Infine, cliccate su Create per completare la configurazione.
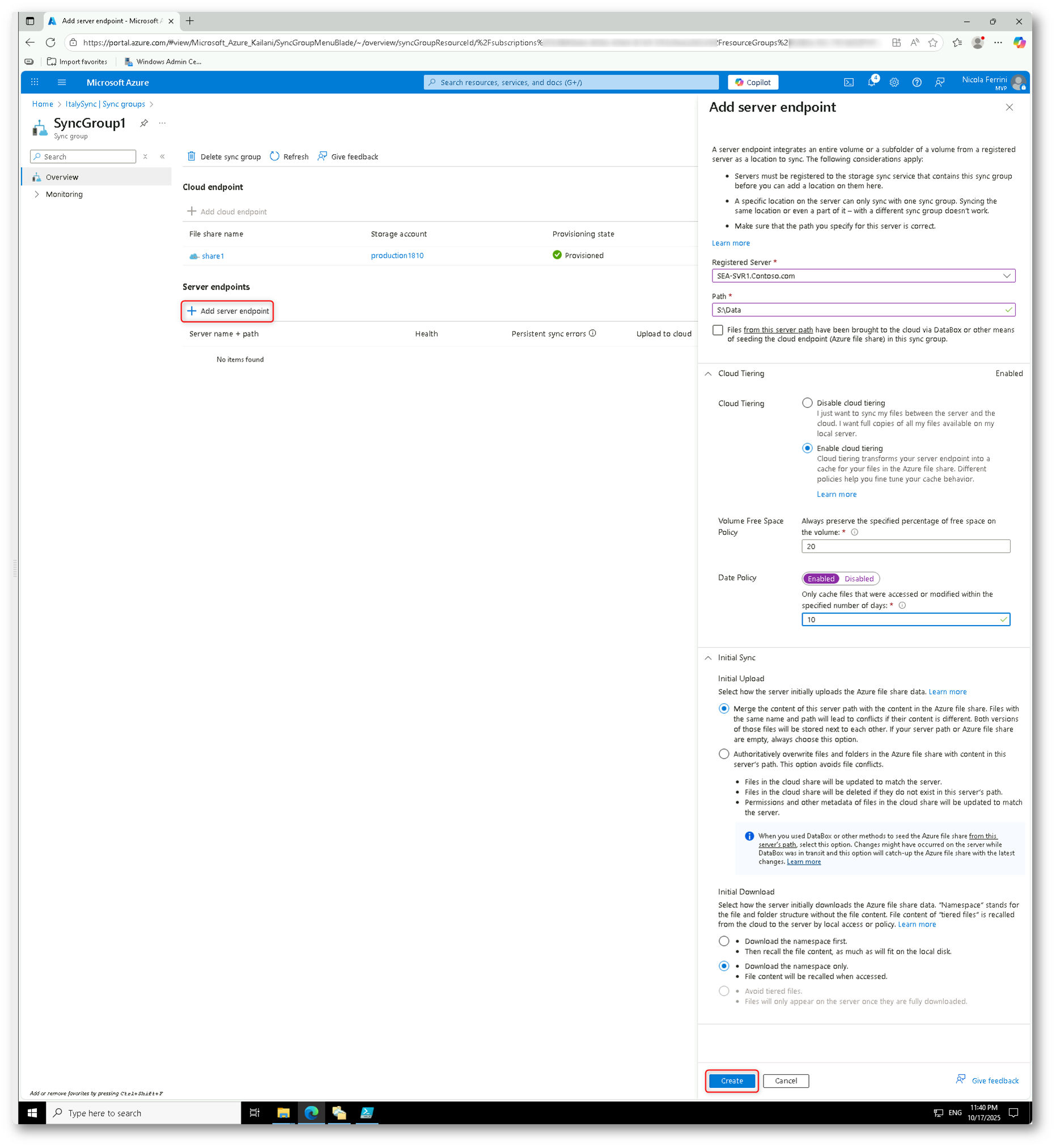
Figura 25: Creazione del server endpoint SEA-SVR1 nel gruppo di sincronizzazione SyncGroup1, con opzioni di cloud tiering e policy di gestione dati configurate
Dopo aver completato la creazione del server endpoint, nel portale di Azure comparirà la nuova voce corrispondente al percorso configurato, in questo caso SEA-SVR1.Contoso.com + S:\Data.
Lo stato iniziale sarà Pending, con le voci “Waiting for initial upload to start” e “Waiting for initial download to start”, a indicare che la sincronizzazione deve ancora avviarsi.
Dopo alcuni minuti (in base alle dimensioni dei dati e alla connessione), il servizio inizierà a sincronizzare i file tra il server locale e la share in Azure.
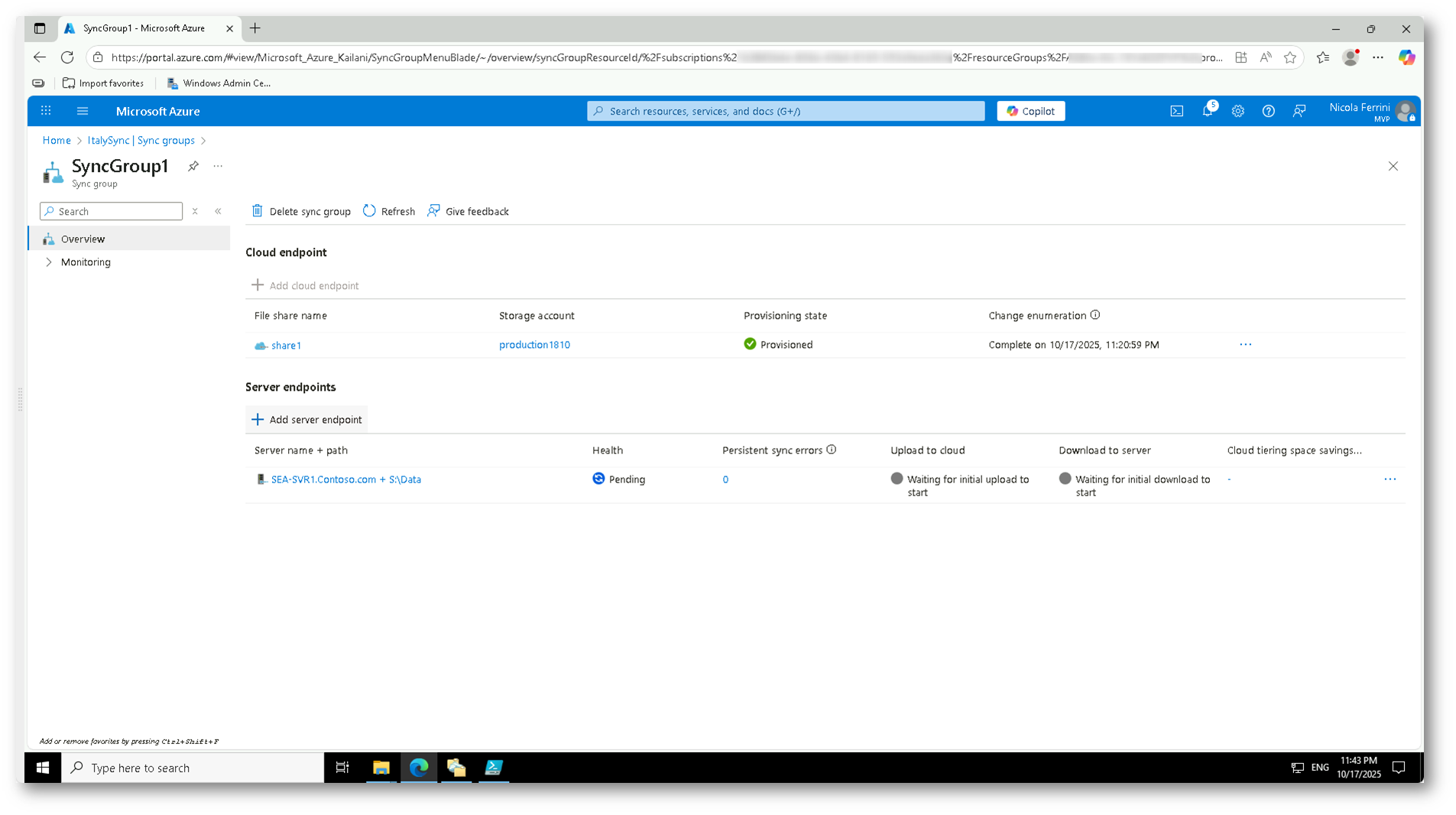
Figura 26: Visualizzazione del server endpoint appena creato, in attesa dell’avvio della prima sincronizzazione iniziale tra il file server locale e Azure File Share
Ora è possibile aggiungere anche il secondo server, SEA-SVR2, come server endpoint nello stesso gruppo di sincronizzazione SyncGroup1.
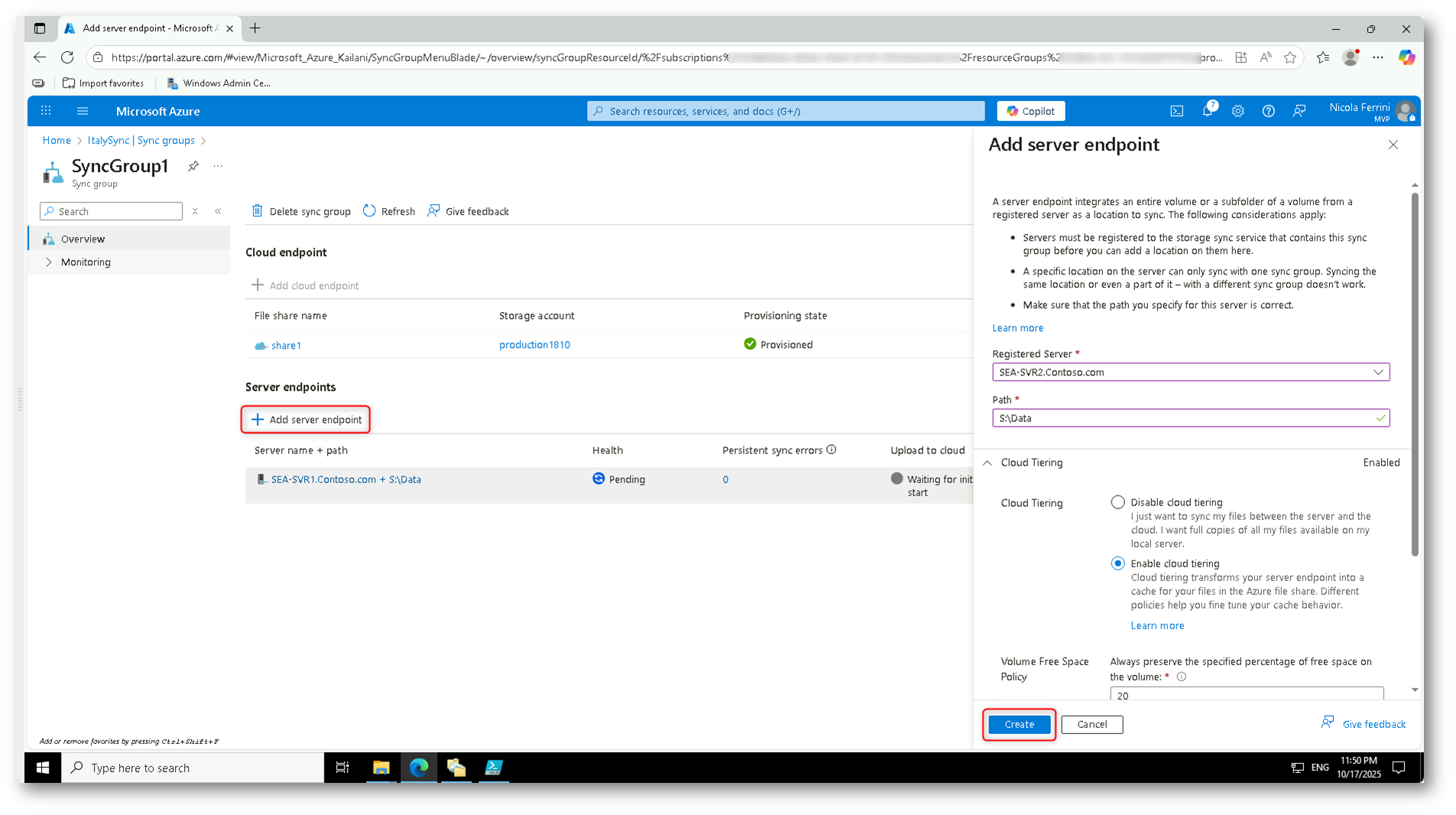
Figura 27: Registrazione del server SEA-SVR2 come secondo endpoint nel gruppo di sincronizzazione, completando la configurazione multi-server di Azure File Sync
Il nuovo endpoint verrà aggiunto e inizierà la fase di sincronizzazione iniziale.
Nell’elenco degli endpoint si potrà notare che SEA-SVR1 risulta già Healthy, mentre SEA-SVR2 compare come Pending, in attesa di completare la sincronizzazione.
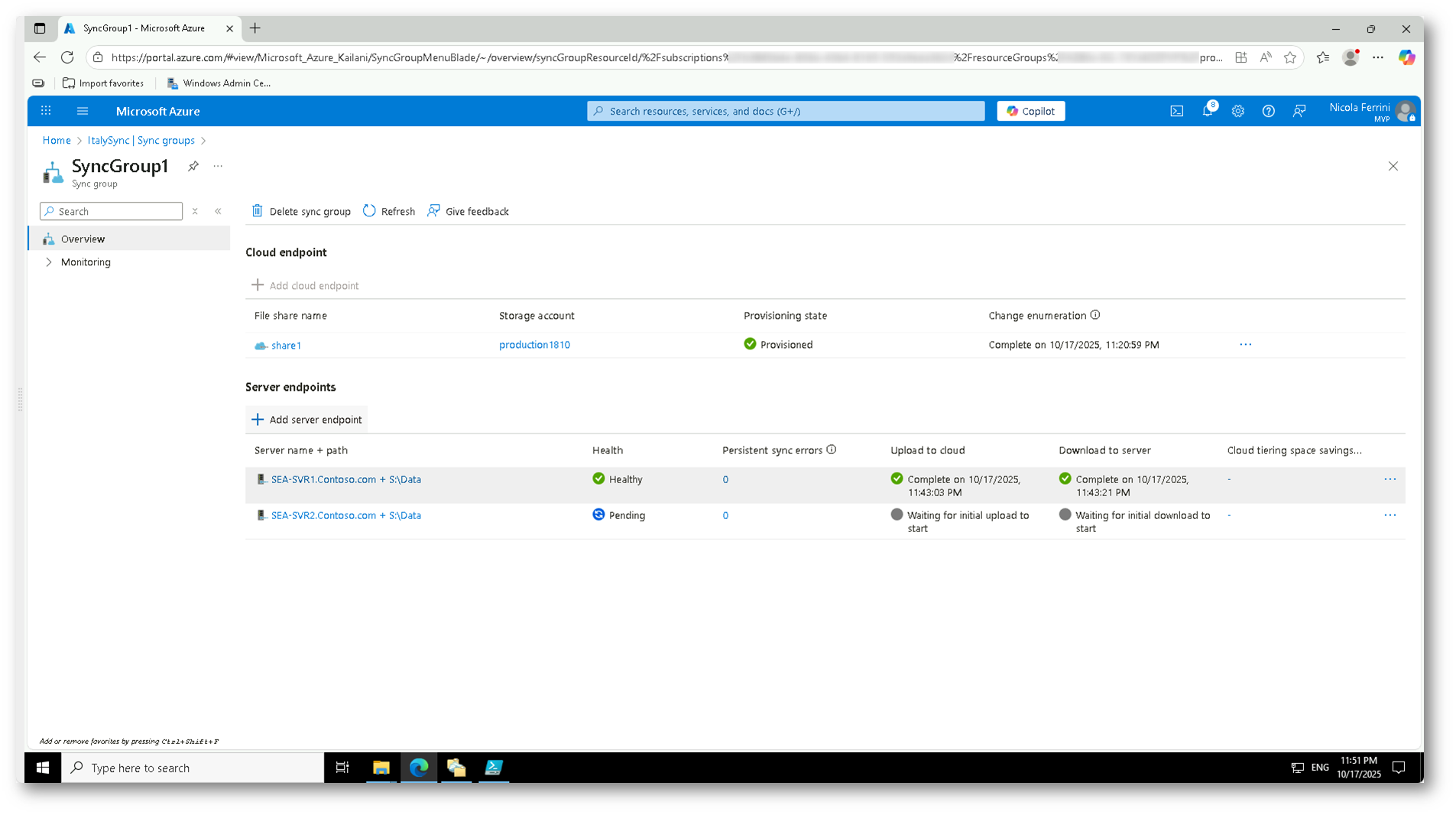
Figura 28: Vista del gruppo di sincronizzazione con entrambi i server registrati: il primo già sincronizzato, il secondo in fase di inizializzazione
Ricordate che gli utenti non accederanno direttamente alla Azure File Share, ma continueranno a utilizzare le condivisioni SMB locali dei file server. L’autenticazione e i permessi restano gestiti da Active Directory, e Azure File Sync ne mantiene la sincronizzazione nel cloud.
Rimozione della replica DFS-R
La rimozione della replica DFS-R (Distributed File System Replication) è un passaggio necessario quando si migra la sincronizzazione dei dati verso Azure File Sync.
Finché DFS-R rimane attivo, i due server continuano a replicare i file tra loro in locale, indipendentemente dal nuovo servizio di sincronizzazione. Questo può creare conflitti o inconsistenze con Azure File Sync, che diventa ora l’unico meccanismo di replica centralizzato tramite il cloud.
Dalla console DFS Management e si seleziona il gruppo di replica (in questo caso Branch1) che era precedentemente utilizzato per la sincronizzazione dei dati tra i server locali. Dal menu contestuale è necessario scegliere Delete per avviare la rimozione del gruppo.
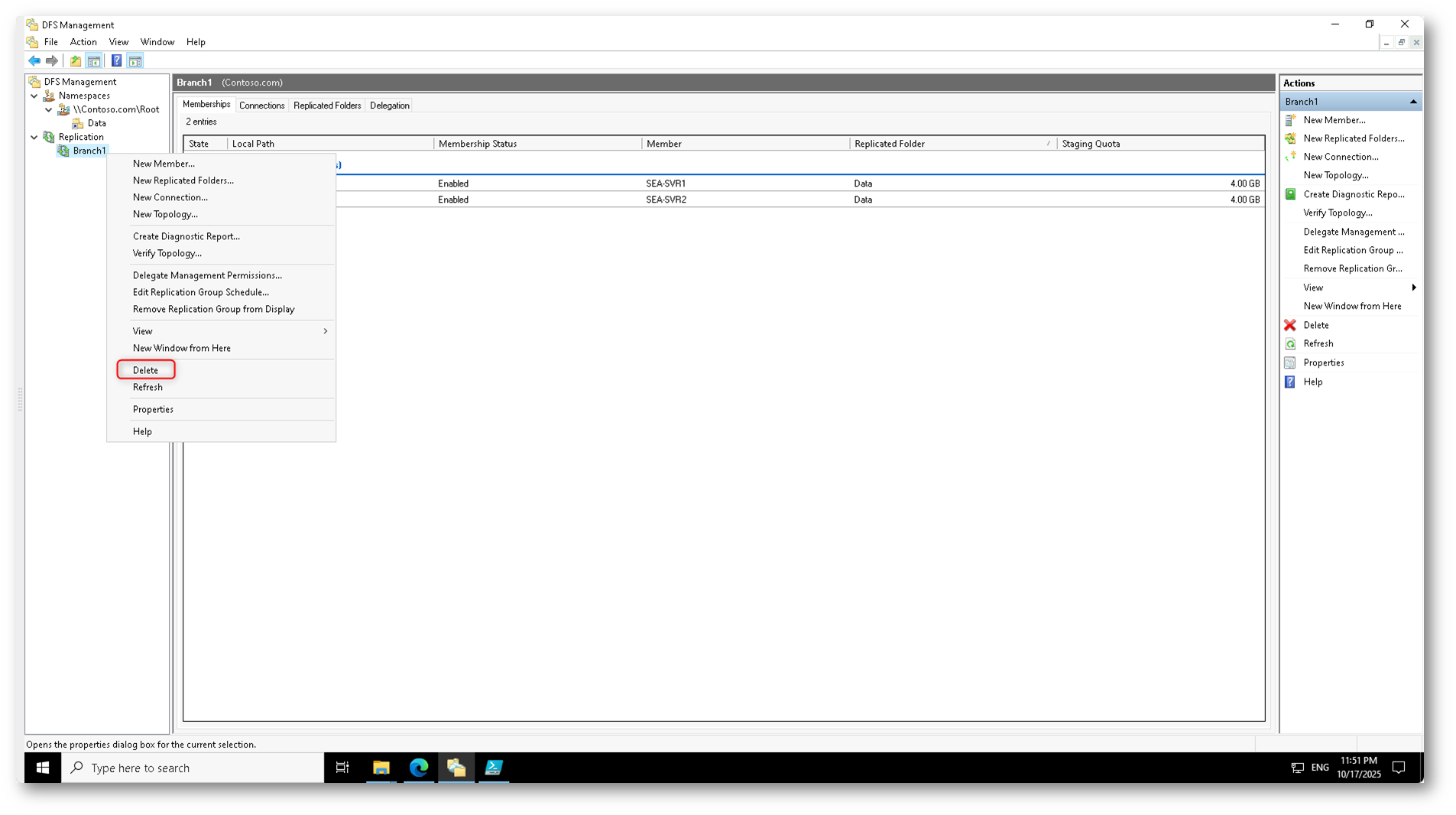
Figura 29: Eliminazione del gruppo di replica DFS-R “Branch1” dalla console di gestione DFS
Dopo aver cliccato su Delete, viene visualizzata una finestra di conferma. Selezionate l’opzione “Yes, delete the replication group…”, che interrompe la replica e rimuove tutti i membri associati al gruppo.
Nessun file locale verrà cancellato: verrà soltanto disattivato il meccanismo di replica DFS-R.
D’ora in poi la sincronizzazione verrà gestita unicamente da Azure File Sync, evitando duplicazioni e sovrapposizioni.
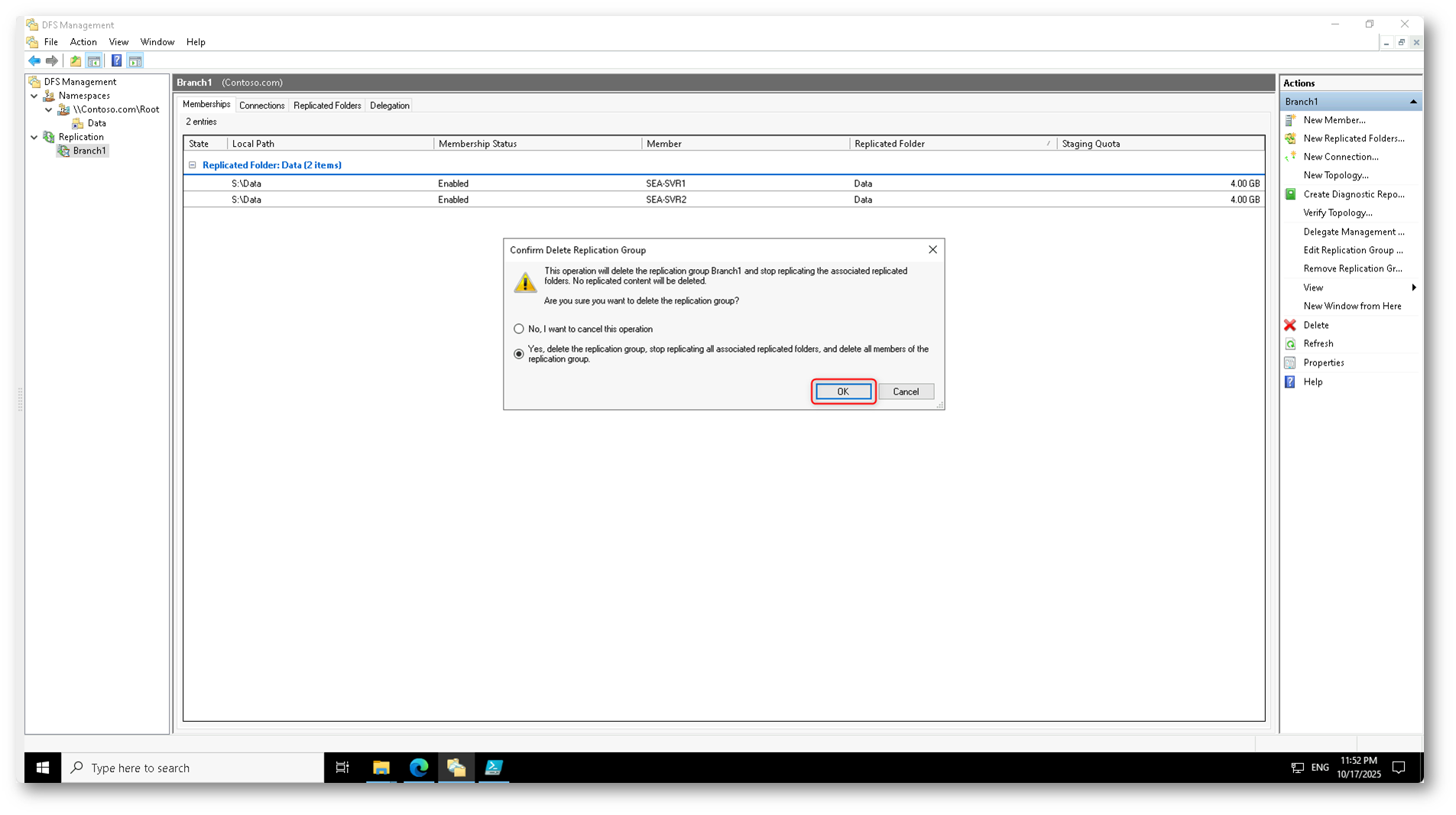
Figura 30: Conferma della rimozione definitiva del gruppo di replica DFS-R e disattivazione del vecchio sistema di sincronizzazione locale
Una volta completata la configurazione, controllate lo stato dei vostri server endpoint dal portale di Microsoft Azure nella sezione Storage Sync Service → Sync groups → [Nome del vostro Sync Group] → Overview.
Assicuratevi che:
- Entrambi i server compaiano nella sezione Server endpoints;
- La colonna Health mostri lo stato Healthy per ciascun server;
- Le colonne Upload to cloud e Download to server riportino la dicitura Complete.
Queste informazioni confermano che la sincronizzazione tra i server locali e la share di Azure è stata completata con successo e che Azure File Sync sta gestendo correttamente la replica dei file, sostituendo il precedente sistema DFS-R.
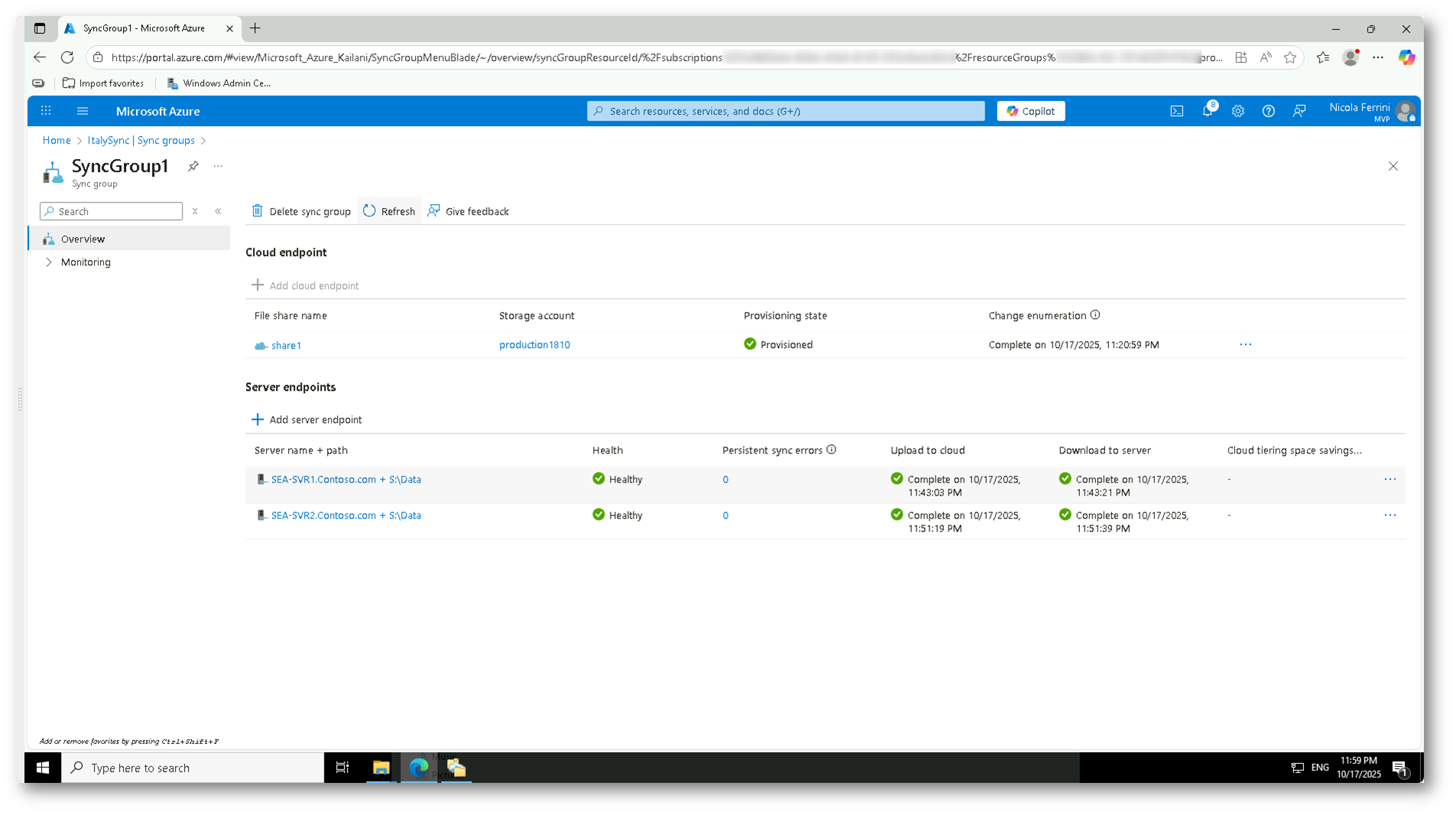
Figura 31: Verifica dello stato del gruppo di sincronizzazione nella sezione “Overview”: entrambi i server in stato “Healthy” indicano che la replica con Azure File Sync è pienamente operativa
Test di funzionamento finale
A questo punto potete procedere con un test di funzionamento per verificare che la replica tramite Azure File Sync sia operativa.
Aprite le cartelle condivise sui due server, ad esempio \\SEA-SVR1\Data e \\SEA-SVR2\Data, e controllate che i file siano identici. Per ulteriore conferma, potete anche accedere alla Azure File Share (nel nostro esempio share1 montata come unità Z:) e verificare che contenga gli stessi file.
Se le modifiche effettuate su uno dei nodi vengono rapidamente replicate sugli altri e sulla share cloud, significa che Azure File Sync sta gestendo correttamente la sincronizzazione dei dati.
Per verificare che la replica funzioni correttamente, aggiungete alcuni file di test all’interno di una delle cartelle sincronizzate, ad esempio su \\SEA-SVR1\Data. Potete creare o copiare documenti di testo o file Word, come mostrato in figura.
Dopo pochi istanti, controllate che gli stessi file compaiano automaticamente anche su \\SEA-SVR2\Data e nella share di Azure (Z:).
Questo test conferma che la replica è bidirezionale e che i dati vengono sincronizzati correttamente tra i server locali e il cloud.
Per completare la verifica, potete anche testare la gestione delle modifiche simultanee, simulando un caso di conflitto di replica.
Provate, ad esempio, a modificare lo stesso file su entrambi i server (es. File1.txt su \\SEA-SVR1\Data e \\SEA-SVR2\Data) nello stesso intervallo di tempo. Azure File Sync rileverà automaticamente la situazione e preserverà entrambe le versioni del file, rinominando una delle due per evitare la sovrascrittura. Il file duplicato conterrà nel nome l’identificativo del server e la data della modifica (ad esempio: File1-SEA-SVR2-20251018.txt).
Questo comportamento garantisce l’integrità dei dati e consente agli amministratori di analizzare i conflitti senza perdita di informazioni.
Ricordate che potete monitorare l’attività di sincronizzazione e verificare eventuali conflitti o errori direttamente nel portale di Azure, alla voce: Storage Sync Service → Sync groups → [Nome del vostro Sync Group] → Server endpoints → [Nome server].
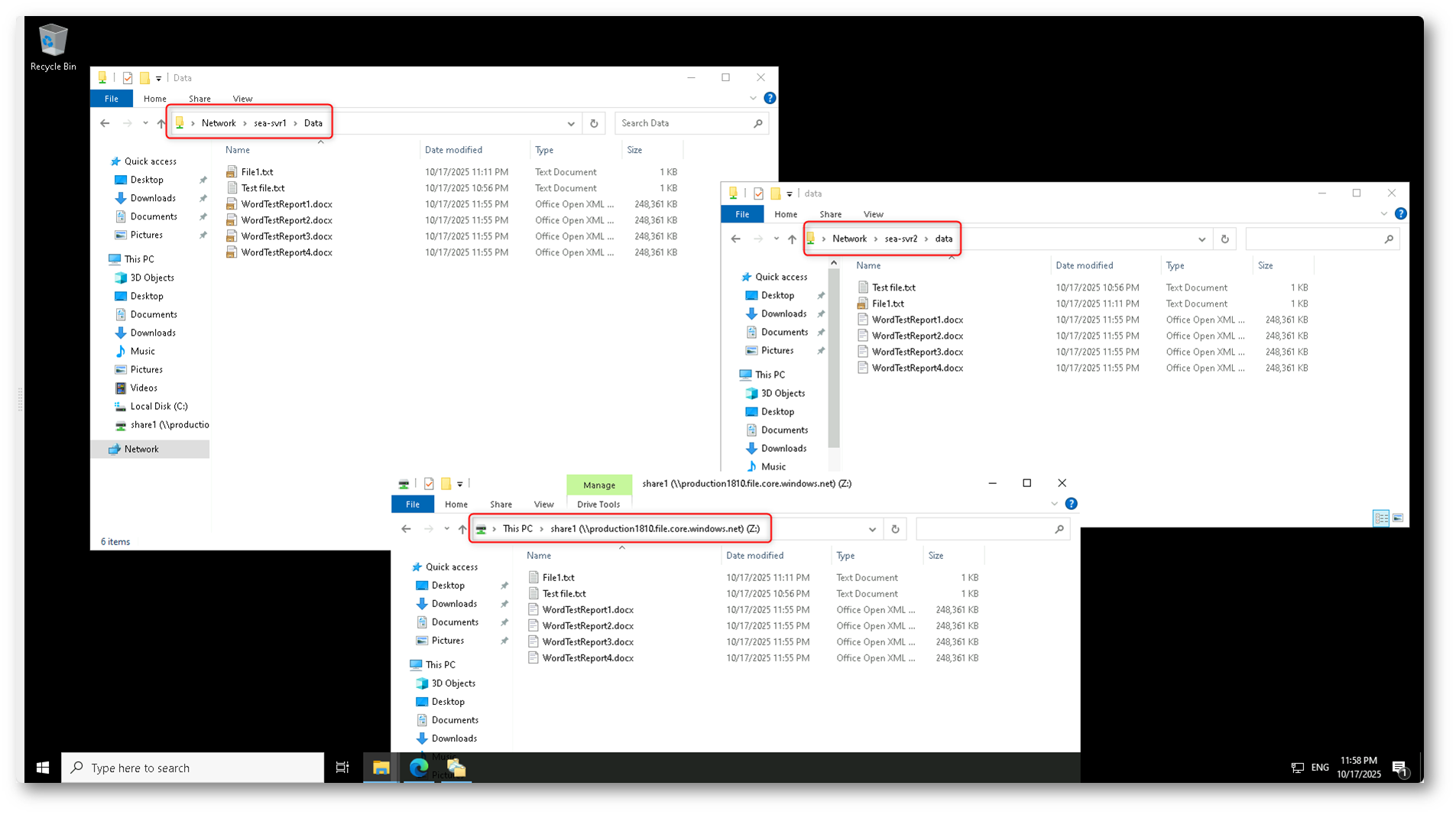
Figura 32: Verifica finale della replica: i file presenti nei server SEA-SVR1, SEA-SVR2 e nella share cloud sono perfettamente sincronizzati grazie ad Azure File Sync
Vantaggi di Azure File Sync rispetto a DFS-R
Con il completamento della configurazione, la replica dei dati è ora gestita da Azure File Sync, che offre una serie di benefici significativi rispetto alla tradizionale replica tramite DFS-R (Distributed File System Replication):
- Scalabilità e semplicità di gestione: Azure File Sync consente di centralizzare i dati nel cloud mantenendo solo le copie necessarie nei file server locali, riducendo il carico di archiviazione e semplificando l’amministrazione.
- Sincronizzazione ibrida: I dati sono disponibili sia on-premises che nel cloud, permettendo agli utenti di accedere ai file anche in caso di indisponibilità temporanea dei server locali.
- Cloud Tiering: Grazie a questa funzionalità, i file meno utilizzati vengono mantenuti solo nel cloud, liberando spazio sui dischi locali e migliorando le prestazioni complessive.
- Protezione e resilienza dei dati: Tutti i file sono replicati e salvati in un account di archiviazione Azure, con ridondanza geografica opzionale e possibilità di integrazione con i backup nativi di Azure.
- Aggiornamenti e monitoraggio centralizzato: La gestione tramite il portale Azure consente di controllare in tempo reale lo stato della sincronizzazione, i conflitti e la salute dei server registrati, eliminando la complessità di configurazioni distribuite.
Accesso degli utenti dopo la migrazione
Per gli utenti non cambia praticamente nulla. Azure File Sync lavora dietro le quinte, sincronizzando i dati tra i file server locali e la share su Azure, ma non modifica i percorsi SMB o DFS-N utilizzati dai client.
In altre parole, gli utenti continueranno ad accedere ai file nello stesso modo di prima:
- tramite le stesse condivisioni SMB (\\Server\Data o \\Domino\Condivisione);
- oppure, se usavate DFS Namespaces (DFS-N), tramite lo stesso percorso logico (\\azienda.local\documenti).
Azure File Sync agisce a livello di volume e cartella, non interferendo con la modalità di accesso ai file, ma migliorandone disponibilità e gestione.
Nota tecnica: Lo script PowerShell che utilizza le chiavi di accesso dello storage account serve solo agli amministratori, per testare la connessione alla Azure File Share o verificarne la configurazione.
Gli utenti non accedono mai direttamente alla share cloud, ma continuano a lavorare sul file server locale, dove restano validi i permessi NTFS e le ACL di Active Directory.
È Azure File Sync a occuparsi di sincronizzare automaticamente file e autorizzazioni tra il server locale e la share in Azure.
Solo nel caso in cui si voglia consentire l’accesso diretto alla Azure File Share (senza passare dal server) sarà necessario abilitare l’integrazione con Active Directory, per mantenere coerenza tra autenticazione e permessi.
Cosa cambia concretamente per gli utenti
- Nessuna modifica sui client: non è necessario riconfigurare i percorsi di rete, le unità mappate o i collegamenti DFS.
- Esperienza identica: i file appaiono e si comportano come sempre, anche se alcuni di essi possono essere “tiered” (cioè presenti solo nel cloud finché non vengono aperti).
- File on-demand: se il cloud tiering è attivo, un file contrassegnato come “solo cloud” viene scaricato automaticamente quando un utente lo apre — in modo trasparente, senza interruzioni.
- Prestazioni locali: l’accesso ai file usati di frequente resta rapido perché restano memorizzati sul file server locale.
Gli utenti non devono fare nulla: continuano a lavorare come prima, ma i loro dati ora sono sincronizzati e protetti nel cloud. Per loro, l’esperienza rimane identica, ma per voi amministratori cambia tutto: gestione semplificata, replica centralizzata e maggiore resilienza dei dati.
Conclusioni
Azure File Sync rappresenta l’evoluzione naturale dei sistemi di replica tradizionali come DFS-R. Grazie all’integrazione con il cloud di Azure, consente di sincronizzare, proteggere e ottimizzare i file server on-premises, mantenendo la stessa esperienza d’uso per gli utenti.
Tra i principali vantaggi troviamo la centralizzazione dei dati, il Cloud Tiering per ridurre lo spazio occupato in locale e la possibilità di ripristinare rapidamente i dati in caso di guasti o sostituzioni dei server. La gestione tramite il portale Azure rende inoltre il monitoraggio e la manutenzione molto più semplici ed efficienti.
Azure File Sync, di fatto, offre una replica moderna, flessibile e sicura, ideale per chi desidera portare la propria infrastruttura di file server verso un modello ibrido cloud.