
Progettare una soluzione di database SQL in Microsoft Azure
Azure offre diverse opzioni per eseguire database SQL nel cloud, ognuna con specifiche caratteristiche e casi d’uso ideali. Ecco una panoramica delle principali differenze tra Azure SQL Database, Azure SQL Managed Instance e SQL Server on Azure VMs:
-
Azure SQL Database
- Modello di servizio: PaaS (Platform as a Service), che offre una gestione semplificata senza la necessità di gestire l’infrastruttura sottostante.
- Casistica d’uso: Ideale per nuove applicazioni cloud-native che richiedono scalabilità, alta disponibilità e sicurezza avanzata senza il bisogno di personalizzazioni a livello di sistema operativo o di SQL Server.
- Caratteristiche: Supporta il modello di database singolo e il modello elastico di pool di database, permettendo una facile scalabilità e gestione delle risorse. Include funzionalità automatiche come backup, patching e aggiornamenti.
- Isolamento: I database sono isolati l’uno dall’altro, condividendo le risorse in modo sicuro attraverso il modello di tenancy multi-tenant.
-
Azure SQL Managed Instance
- Modello di servizio: PaaS (Platform as a Service), offre una gestione semplificata con maggiore compatibilità delle funzionalità di SQL Server rispetto ad Azure SQL Database.
- Casistica d’uso: Ottimale per la migrazione di applicazioni esistenti su SQL Server nel cloud senza dover modificare il codice applicativo, grazie alla sua elevata compatibilità con SQL Server.
- Caratteristiche: Fornisce un’istanza SQL Server completamente gestita che supporta la maggior parte delle funzionalità di SQL Server, inclusi i SQL Agent jobs, le reti virtuali e l’accesso a livello di istanza. Supporta anche funzionalità di rete più complesse come le reti virtuali.
- Isolamento: Offre un ambiente isolato che simula di più l’esperienza di un’istanza dedicata di SQL Server.
-
SQL Server on Azure VMs
- Modello di servizio: IaaS (Infrastructure as a Service), che consente la massima flessibilità e controllo sull’ambiente SQL Server e sull’infrastruttura sottostante.
- Casistica d’uso: Ideale per scenari che richiedono la piena compatibilità con SQL Server o configurazioni personalizzate del sistema operativo e del server SQL. È anche la scelta giusta per applicazioni che necessitano di funzionalità non disponibili in Azure SQL Database o Managed Instance.
- Caratteristiche: Gli utenti gestiscono manualmente la maggior parte degli aspetti, inclusi il sistema operativo, SQL Server, backup, patching e monitoraggio. Offre la flessibilità di usare qualsiasi versione di SQL Server e di configurare l’ambiente secondo necessità specifiche.
- Isolamento: Fornisce il massimo livello di isolamento, dato che l’utente gestisce le VM e può configurare l’ambiente in modo molto dettagliato.
La scelta tra queste opzioni dipende dalle specifiche esigenze aziendali, dalla necessità di controllo e gestione dell’infrastruttura, dalla compatibilità con SQL Server e dai requisiti di scalabilità e manutenzione. Azure SQL Database è più adatto per applicazioni che possono beneficiare di scalabilità automatica e gestione semplificata. Azure SQL Managed Instance è ideale per le migrazioni con minime modifiche, offrendo più funzionalità di SQL Server in un ambiente gestito. SQL Server on Azure VMs offre la massima flessibilità per scenari che richiedono configurazioni specifiche o versioni particolari di SQL Server.
Maggiori dettagli sono disponibili alla pagina Che cos’è SQL di Azure? – Azure SQL | Microsoft Learn
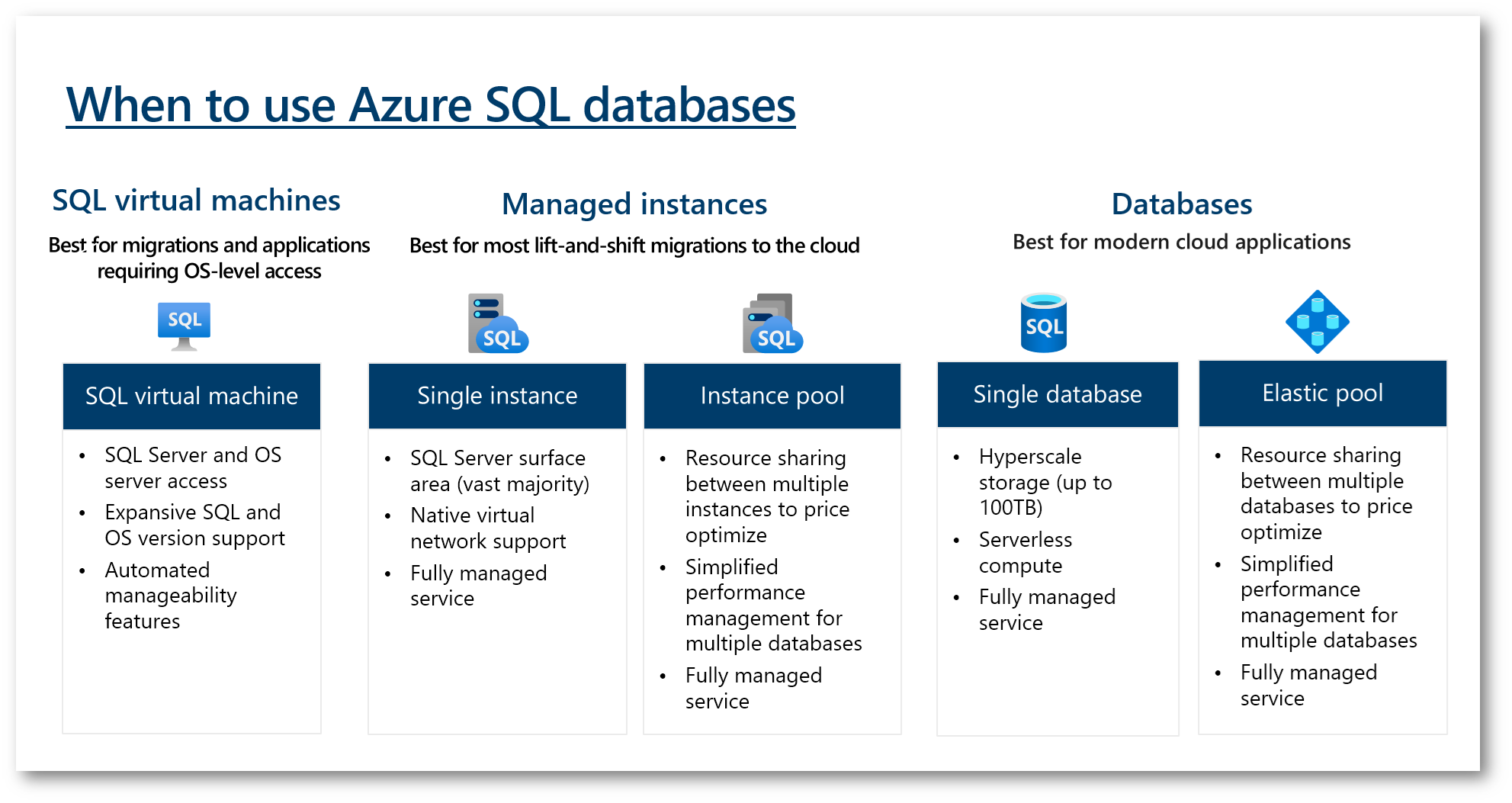
Figura 1: Scenari di utilizzo di Azure SQL Database
Funzionalità di scalabilità dei database: Elastic pool
Un Elastic Pool di Azure SQL è una funzionalità di Azure SQL Database che consente di ottimizzare la gestione delle risorse e dei costi per un gruppo di database nel cloud. Gli Elastic Pool sono progettati per situazioni in cui hai più database che hanno modelli di utilizzo variabili o imprevedibili e che non necessitano delle risorse massime allo stesso tempo. Offrendo un insieme condiviso di risorse (CPU, memoria, I/O) a più database, gli Elastic Pool permettono di massimizzare l’utilizzo delle risorse e ridurre i costi rispetto alla gestione individuale di ogni database con risorse dedicate.
Caratteristiche principali:
- Condivisione di risorse: Gli Elastic Pool consentono ai database di condividere un set di risorse compute e storage. Questo è particolarmente utile per i carichi di lavoro con pattern di utilizzo variabile, dove i picchi di uno o più database possono essere gestiti senza dover allocare risorse dedicate e costose per ciascuno.
- Flessibilità: È possibile aggiungere o rimuovere database dall’Elastic Pool senza downtime, offrendo grande flessibilità nella gestione dei carichi di lavoro.
- Costo-efficacia: Paghi per il pool di risorse condivise piuttosto che per singoli database, il che può risultare più economico per le organizzazioni con molti database che non utilizzano costantemente le loro risorse al massimo.
- Semplicità di gestione: La gestione delle prestazioni e del budget diventa più semplice, poiché puoi allocare un set di risorse a un gruppo di database e regolare le prestazioni a livello di pool piuttosto che per singolo database.
Casi d’uso ideali:
- Applicazioni SaaS (Software as a Service): Ideale per applicazioni SaaS che necessitano di gestire più database, uno per ogni cliente o tenant, con esigenze di risorse fluttuanti.
- Database con utilizzo variabile: Perfetto per i database che hanno requisiti di risorse imprevedibili o ciclici, permettendo di assorbire i picchi di utilizzo senza la necessità di sovradimensionare le risorse per ciascun database.
Per maggiori informazioni vi rimando alla pagina Gestire più database con pool elastici – Azure SQL Database | Microsoft Learn
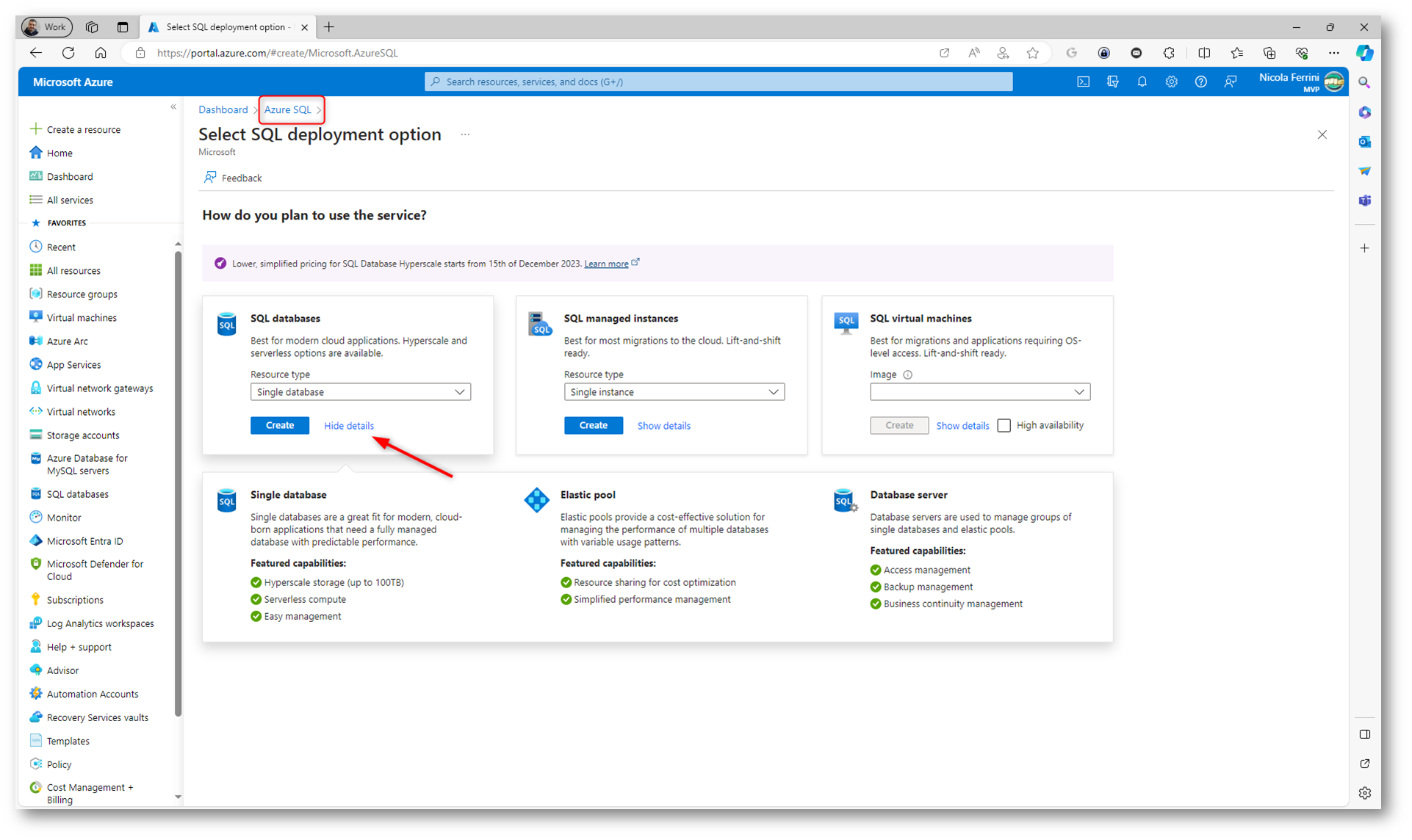
Figura 2: Wizard per la creazione di un nuovo Azure SQL
Modelli di acquisto di Azure SQL Database
Azure SQL Database offre due modelli di acquisto per soddisfare diverse esigenze di prestazioni, scalabilità e costo: il modello basato su vCore e il modello basato su DTU (Database Transaction Unit).
Modello basato su vCore
- Cosa offre: Il modello basato su vCore offre una maggiore flessibilità e controllo sulle risorse di calcolo e storage. Consente agli utenti di scegliere il tipo di processore, il numero di core virtuali (vCore), e la quantità di memoria e storage, oltre alla possibilità di utilizzare funzionalità avanzate come la replica geografica e il supporto per reti virtuali.
- Vantaggi: Questo modello è ideale per aziende che necessitano di una configurazione dettagliata delle prestazioni, della scalabilità e del costo. Offre anche trasparenza nelle prestazioni e nella fatturazione, rendendolo adatto per le migrazioni da ambienti on-premise a cloud.
- Scalabilità: Consente di scalare verticalmente le risorse di calcolo e storage indipendentemente, offrendo così una maggiore precisione nella gestione delle risorse.
- Casi d’uso: Adatto per carichi di lavoro di database più grandi e prevedibili, dove il controllo e l’ottimizzazione delle risorse sono cruciali.
Modello basato su DTU
- Cosa offre: Il modello basato su DTU (Database Transaction Unit) è un approccio più semplice, che offre un pacchetto combinato di risorse di calcolo, memoria e I/O. Una DTU rappresenta una misura mista della capacità di un database di gestire transazioni e carichi di lavoro.
- Vantaggi: Questo modello è progettato per semplificare la selezione delle prestazioni del database, rendendo più facile per gli utenti scegliere un livello di prestazioni senza dover configurare e gestire le risorse individualmente.
- Scalabilità: Fornisce scalabilità all’interno di un range di DTU predefinito, consentendo agli utenti di aumentare o diminuire le prestazioni complessive del database in base alle esigenze.
- Casi d’uso: Ideale per piccoli e medi carichi di lavoro, dove la semplicità e la facilità di gestione sono prioritarie rispetto al fine tuning delle risorse.
Confronto e scelta
- Costo: Il modello basato su vCore può essere più costoso ma offre maggiore flessibilità e controllo, mentre il modello DTU è spesso più semplice e potrebbe risultare più economico per piccoli carichi di lavoro.
- Scalabilità e Controllo: Il modello vCore offre scalabilità e controllo dettagliati, mentre il modello DTU offre un approccio più semplice e gestito.
- Casi d’uso: Il modello vCore è preferito per applicazioni aziendali e carichi di lavoro critici, mentre il modello DTU è adatto per progetti più piccoli, sviluppo e test.
La scelta tra i due modelli dipende dalle esigenze specifiche del vostro carico di lavoro, dal budget, dalla necessità di controllo sulle risorse e dalla preferenza per la semplicità rispetto alla personalizzazione.
Maggiori informazioni sono disponibili alla pagina Modelli di acquisto – Azure SQL Database | Microsoft Learn e alla pagina Modello di acquisto vCore – Azure SQL Database | Microsoft Learn
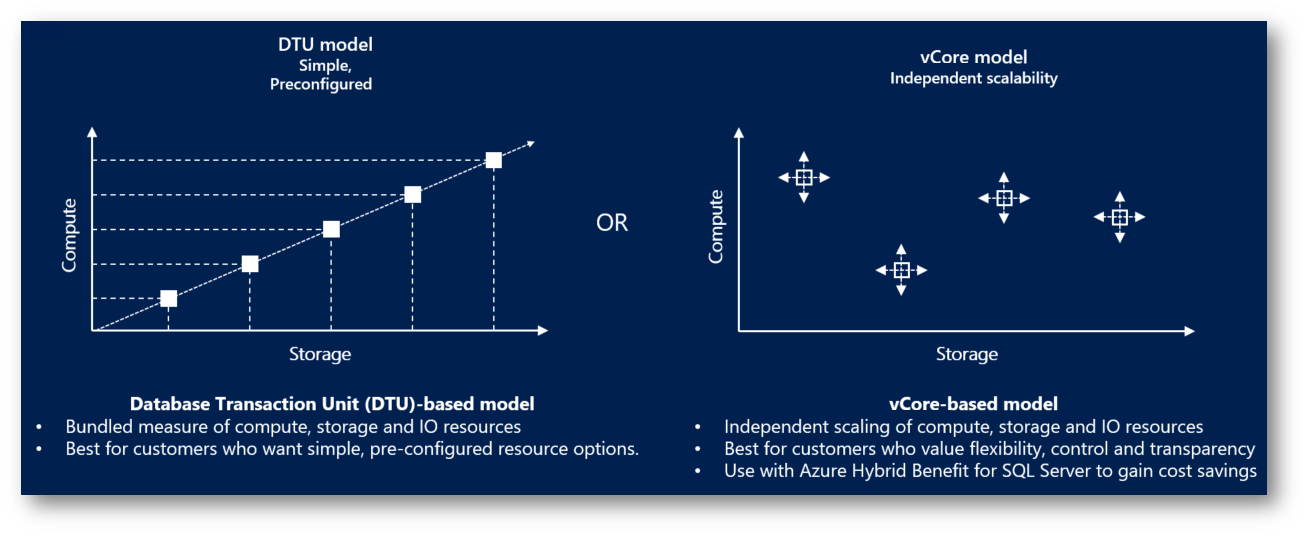
Figura 3: Modelli di acquisto di Azure SQL Database
Livelli di servizio (service tiers) di Azure SQL Database
Azure SQL Database offre tre principali livelli di servizio (service tiers) per soddisfare diverse esigenze di prestazioni, disponibilità e costo. Questi livelli sono progettati per offrire una varietà di opzioni per supportare carichi di lavoro che vanno dall’uso leggero e sviluppo fino ad applicazioni critiche per l’azienda. I tre livelli di servizio sono:
-
- Descrizione: Il livello Basic è progettato per le applicazioni che richiedono meno risorse di calcolo e storage. È ideale per le piccole applicazioni e i database con un basso volume di transazioni.
- Caratteristiche: Offre una quantità limitata di DTU (Database Transaction Units), che è una misura combinata di memoria, CPU e I/O, adatta per database di piccole dimensioni con carichi di lavoro leggeri.
- Caso d’uso: Perfetto per ambienti di sviluppo/test, piccole applicazioni web, e database personali.
-
- Descrizione: Il livello Standard fornisce un bilanciamento tra costo e prestazioni per le applicazioni aziendali. Supporta un’ampia gamma di carichi di lavoro, dai database di piccole e medie dimensioni fino a quelli con esigenze moderate di prestazioni e throughput.
- Caratteristiche: Offre una gamma più ampia di DTU e opzioni di storage, consentendo una maggiore flessibilità nel gestire le prestazioni del database e la scalabilità.
- Caso d’uso: Ideale per la maggior parte delle applicazioni aziendali, database SaaS, e soluzioni che richiedono un buon equilibrio tra prestazioni e costo.
-
- Descrizione: Il livello Premium è progettato per le applicazioni critiche che richiedono le massime prestazioni, disponibilità e velocità di recupero. Offre le migliori prestazioni e la massima disponibilità tra i tre livelli di servizio.
- Caratteristiche: Include il maggior numero di DTU disponibili, storage ad alte prestazioni e funzionalità avanzate come la replica geografica automatica per il recupero di emergenza e l’alta disponibilità.
- Caso d’uso: Adatto per carichi di lavoro critici per l’azienda, applicazioni ad alta transazionalità, e database che richiedono tempi di risposta rapidi e una disponibilità quasi costante.
Ogni livello di servizio è progettato per offrire un diverso equilibrio di prestazioni, disponibilità e costo, consentendo di scegliere la soluzione più adatta alle esigenze specifiche dell’applicazione o del progetto. La selezione del livello di servizio appropriato dipende dalla natura del carico di lavoro, dai requisiti di prestazione, dalla tolleranza di downtime e dal budget.
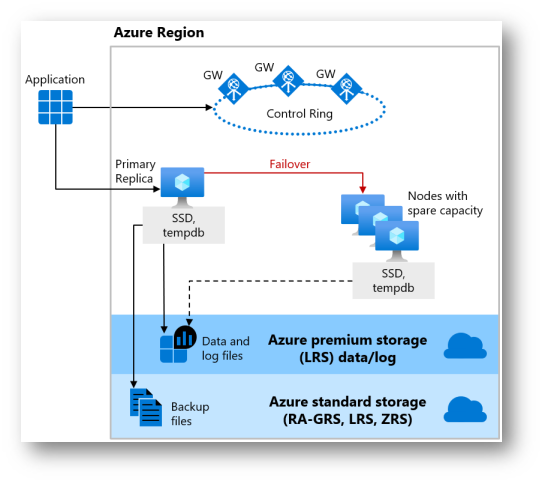
Figura 4: Basic, Standard and General Purpose service tiers
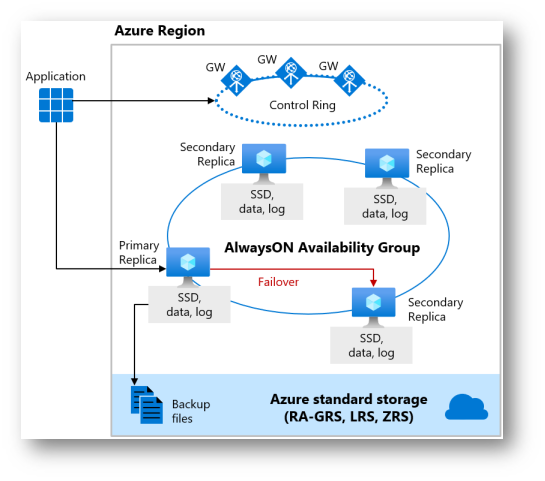
Figura 5: Premium and Business Critical service tier
In realtà dovremmo considerare anche un 4° livello: Hyperscale tier, una soluzione avanzata per carichi di lavoro che richiedono estrema scalabilità, prestazioni elevate e capacità di gestire volumi di dati molto grandi, mantenendo al contempo la flessibilità e l’efficienza operativa.
Il livello di servizio Hyperscale in Azure SQL Database è una delle opzioni disponibili che fornisce scalabilità orizzontale estremamente elevata, senza limiti pratici sulle dimensioni del database. Questo livello di servizio è progettato per superare i limiti di dimensione e prestazioni dei livelli di servizio tradizionali, come Basic, Standard e Premium, offrendo una piattaforma altamente flessibile e scalabile per il carico di lavoro dei database.
Caratteristiche principali di Hyperscale Hyperscale service tier – High availability – Azure SQL Database | Microsoft Learn
- Scalabilità dello storage: Hyperscale supporta dimensioni di database fino a 100 TB e oltre, offrendo una scalabilità del storage che va ben oltre i limiti dei livelli di servizio tradizionali.
- Rapidità nel ripristino dei dati: Grazie alla sua architettura innovativa, Hyperscale può effettuare il ripristino dei dati, il backup e le operazioni di snapshot del database quasi istantaneamente, indipendentemente dalle dimensioni del database.
- Scalabilità delle risorse di calcolo: Permette di scalare rapidamente le risorse di calcolo (CPU e memoria) su e giù senza influenzare il carico di lavoro o le operazioni del database.
- Architettura a più livelli: Utilizza un’architettura a più livelli che separa il calcolo, il log delle transazioni, il file di storage e il servizio di gestione degli snapshot del database, permettendo una scalabilità indipendente di queste componenti.
- Alta Disponibilità: Fornisce funzionalità integrate di alta disponibilità e recupero di emergenza, garantendo la resilienza del carico di lavoro del database.
Casi d’uso ideali per Hyperscale:
- Applicazioni ad ampio volume di dati: Hyperscale è particolarmente adatto per applicazioni che richiedono grandi volumi di storage e scalabilità orizzontale, come big data, data warehousing e applicazioni SaaS (Software as a Service) a elevato carico.
- Migrazione di grandi database On-Premises: Per le aziende che cercano di migrare grandi database esistenti verso il cloud, Hyperscale offre una soluzione senza dover ridimensionare o ristrutturare i dati.
- Sviluppo agile: Offre agli sviluppatori la flessibilità di scalare rapidamente le risorse in risposta alle esigenze in evoluzione dei loro progetti, senza preoccuparsi dei limiti di storage o delle prestazioni.
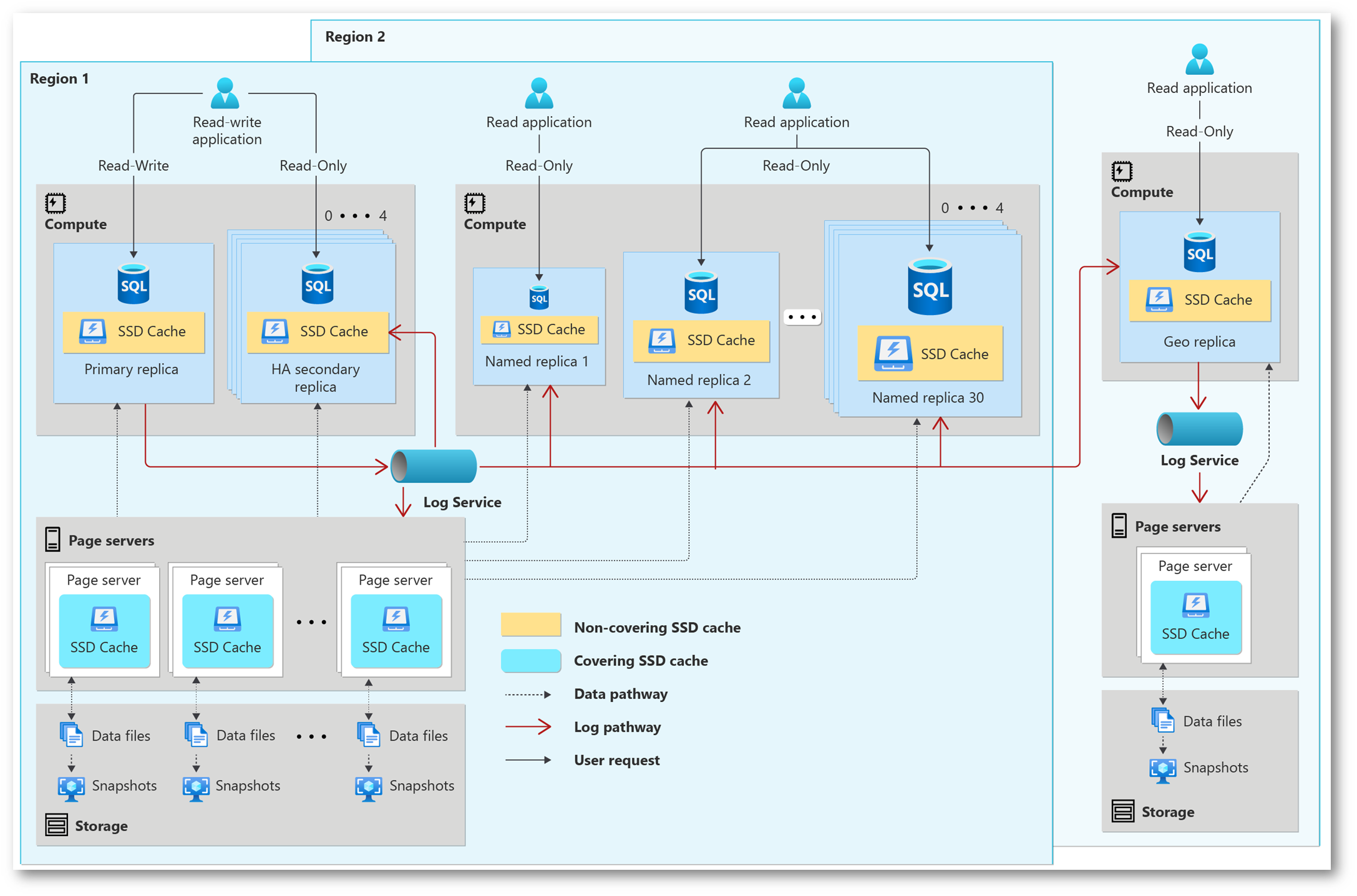
Figura 6: Hyperscale distributed functions architecture
Come faccio a scegliere una database strategy?
Per scegliere una strategia di database appropriata, è importante considerare diversi fattori che influenzano la selezione di una soluzione di database. Ho cercato quindi di segnalarvi alcuni passi da seguire:
-
Valutate i requisiti dell’applicazione:
- Tipo di dati: Che tipo di dati stai memorizzando? Relazionali, non relazionali, o una miscela di entrambi?
- Volume dei dati: Qual è il volume attuale dei dati e quale è l’attesa di crescita?
- Velocità dei dati: Con quale velocità i dati cambiano o vengono generati?
- Varietà dei dati: Hai bisogno di gestire una grande varietà di formati di dati?
- Accesso ai dati: Chi ha bisogno di accedere ai dati e come avverrà questo accesso?
-
Considerate il livello di scalabilità necessario:
- Scalabilità verticale vs orizzontale: Volete che il vostro sistema cresca aggiungendo più risorse a un singolo nodo (scalabilità verticale) o aggiungendo più nodi (scalabilità orizzontale)?
-
Prestazioni:
- Requisiti di latenza: Qual è la latenza accettabile per le operazioni di lettura e scrittura?
- Prestazioni in scrittura vs lettura: La vostra applicazione è più orientata alla lettura o alla scrittura?
-
Affidabilità e disponibilità:
- SLA (Service Level Agreement): Quali sono i vostri requisiti di uptime e quali garanzie offre il provider del servizio?
- Disaster Recovery e Backup: Quali meccanismi di backup e ripristino sono necessari?
-
Sicurezza dei dati:
- Compliance e regolamenti: Ci sono specifici requisiti di compliance che devono essere soddisfatti (GDPR, HIPAA, etc.)?
- Protezione dei dati: Quali sono i requisiti per la crittografia dei dati in transito e a riposo?
-
Costi:
- Modello di costo: Qual è il vostro budget? Preferite un modello di costo basato sul consumo o un costo fisso?
- Costi totali di proprietà (TCO): Considerate tutti i costi associati, inclusi quelli di sviluppo, gestione e manutenzione.
-
Esperienza e competenze del Team:
- Competenze esistenti: Quali sono le competenze tecniche del vostro team?
- Facilità d’uso: Quanto è facile utilizzare e gestire il database con le competenze esistenti?
-
Ecosistema e supporto:
- Integrazioni: Il database si integra facilmente con altre tecnologie che utilizzate?
- Supporto della community: C’è un buon supporto tecnico e comunitario per il database?
-
Flessibilità e Futuro:
- Evoluzione del prodotto: La soluzione di database è ben posizionata per evolversi con le tecnologie emergenti?
- Migrazione dei dati: Quanto è facile migrare i dati da o verso questa soluzione in futuro?
Dopo aver valutato questi punti, potete confrontare diverse opzioni di database, come SQL Server, Azure SQL Database, Azure SQL Managed Instance, o altre soluzioni come NoSQL, database in-memory, o piattaforme come Cosmos DB di Azure, valutando come ognuna allinea con i vostri requisiti specifici. Inoltre, spesso è utile effettuare dei test di performance e scalabilità, o utilizzare periodi di prova offerti dai provider di cloud per validare che la soluzione scelta soddisfi le vostre aspettative prima di impegnarvi in una migrazione su larga scala.
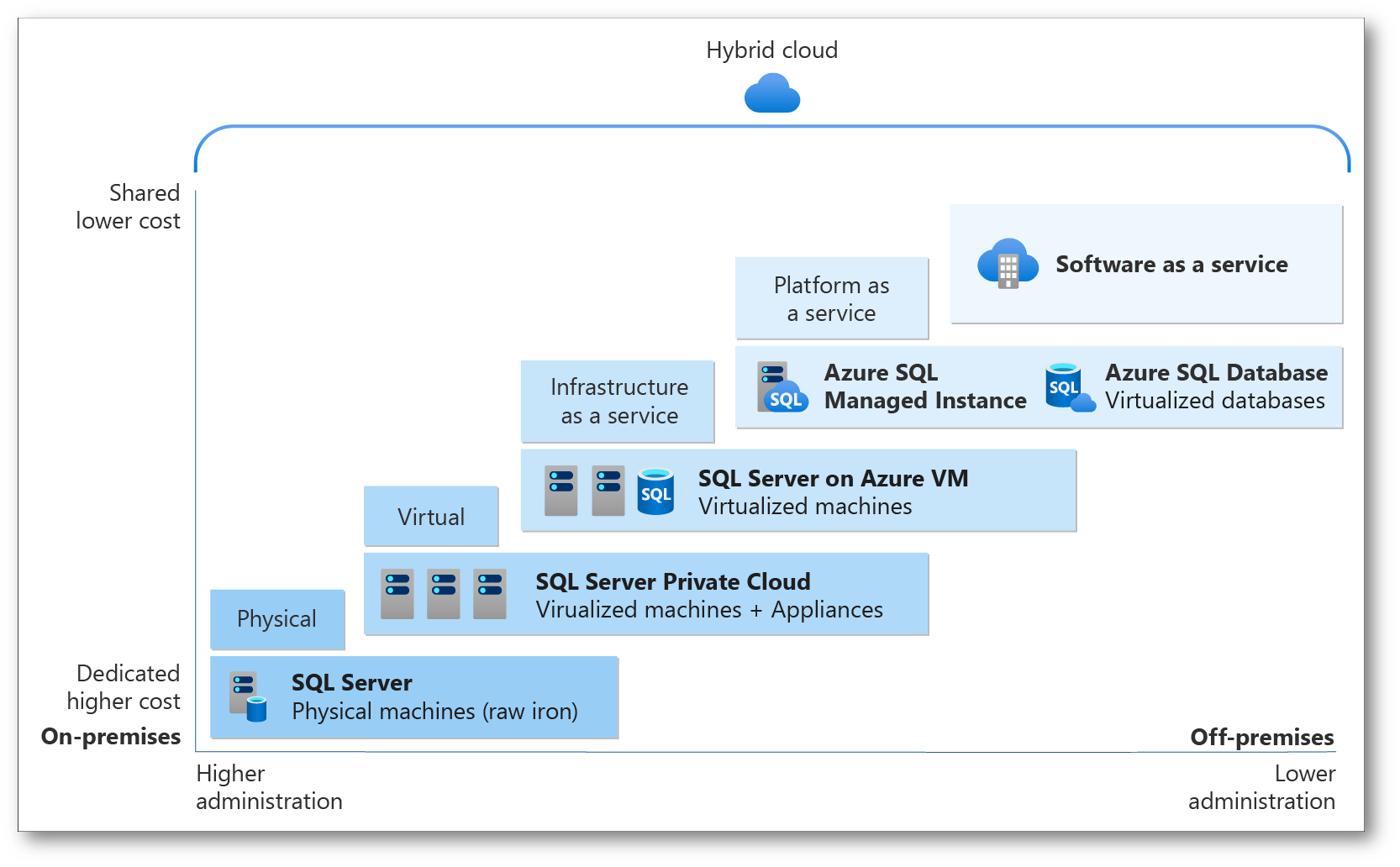
Figura 7: Azure SQL Service comparison
Conclusioni
Scegliere una strategia di database adeguata è un processo che richiede di esaminare attentamente i requisiti specifici della vostra applicazione e del vostro business. Dovreste considerare con attenzione il tipo e il volume dei dati, così come la velocità e la varietà degli stessi, oltre alle vostre esigenze di accesso. Le prestazioni, la scalabilità, l’affidabilità e la disponibilità sono altrettanto cruciali per assicurare che il database scelto possa supportare efficacemente le operazioni aziendali senza interruzioni. La sicurezza e la conformità ai regolamenti sono imperativi, in particolar modo in ambienti regolamentati, e devono essere considerati nel design del vostro sistema di gestione dei dati.
Inoltre, comprendere i costi totali di proprietà e il modello di costo del database vi aiuterà a rimanere nel budget senza sacrificare la qualità del servizio. La competenza e l’esperienza del vostro team influenzeranno la scelta del database, perché dovrete bilanciare tra funzionalità avanzate e usabilità. L’ecosistema e il supporto disponibili per il database sono fondamentali per garantire che avrete l’assistenza necessaria durante lo sviluppo e dopo il lancio. Infine, considerate la flessibilità e la capacità della soluzione di adattarsi a tecnologie e esigenze future, assicurandovi che la vostra strategia sia sostenibile a lungo termine.
La decisione finale dovrebbe essere guidata da un equilibrio di requisiti tecnici, competenze del team, considerazioni finanziarie e prospettive a lungo termine. Testate ampiamente e valutate le opzioni in modo critico per assicurarvi di scegliere una soluzione di database che non solo soddisfi le vostre esigenze attuali ma che sia anche robusta e scalabile per crescere con la vostra azienda nel futuro.
Per maggiori approfondimenti vi invito alla lettura della pagina What is Azure SQL? – Azure SQL | Microsoft Learn