
Introduzione ad Azure Data Explorer
Azure Data Explorer è un servizio di analisi dati altamente scalabile e veloce, progettato per l’esplorazione di grandi volumi di dati (anche petabyte), prevalentemente dati di telemetria e time-series. Questo servizio è parte dell’ecosistema Microsoft Azure e offre funzionalità avanzate per l’analisi di dati in tempo reale e per l’acquisizione di insight da grandi quantità di dati non strutturati o semi-strutturati.
Azure Data Explorer (codename Kusto, prende il nome da Jacques Cousteau, in riferimento all'”esplorazione dell’oceano di dati”) utilizza un linguaggio di query proprietario, chiamato Kusto Query Language (KQL), che permette agli utenti di interrogare, analizzare e visualizzare dati in modo efficiente. Il servizio è ottimizzato per query ad alte prestazioni su grandi set di dati, rendendolo particolarmente adatto per scenari come il monitoraggio di applicazioni, l’analisi di log, l’analisi di sensori IoT, e molto altro.
Un aspetto chiave di Azure Data Explorer è la sua capacità di ingestione rapida di grandi volumi di dati. Può ricevere dati in tempo reale da diverse fonti, come applicazioni, siti web, dispositivi IoT, e altri servizi Azure. Una volta che i dati sono caricati nel sistema, possono essere analizzati quasi in tempo reale, il che è cruciale per le applicazioni che richiedono analisi immediate, come il monitoraggio delle prestazioni o il rilevamento di anomalie.
Inoltre, Azure Data Explorer si integra bene con altri servizi e strumenti di Azure, come Azure Machine Learning per l’analisi predittiva e l’intelligenza artificiale, Azure Data Factory per l’orchestrazione del flusso di dati, e Power BI per la visualizzazione dei dati. Questa integrazione consente agli utenti di costruire una piattaforma di analisi dati completa all’interno dell’ecosistema Azure.
La scalabilità è un altro punto di forza di Azure Data Explorer. È progettato per gestire carichi di lavoro elevati e può essere automaticamente scalato in su o in giù per soddisfare le esigenze specifiche di prestazioni e di costo. Questo rende il servizio adatto a una vasta gamma di applicazioni, dalle piccole aziende che hanno bisogno di analisi di dati occasionali fino alle grandi imprese che richiedono analisi continue su grandi set di dati.
Creazione di un cluster in Azure Data Explorer
Per utilizzare Azure Data Explorer è necessario prima creare un cluster. Si può creare un cluster gratuito, che NON richiede una sottoscrizione Azure. Il cluster gratuito può essere usato per qualsiasi scopo ed è la soluzione ideale per chiunque voglia iniziare rapidamente con Azure Data Explorer. Consente di esplorare l’ampia gamma di metodi di inserimento dati, usare la Linguaggio di query Kusto e sperimentare le prestazioni incredibili di inserimento e query.
Il periodo di valutazione del cluster è di 1 anno e può essere esteso automaticamente. Il cluster viene fornito come è e non è soggetto al contratto di servizio di Azure Data Explorer. In qualsiasi momento è possibile aggiornare il cluster a un cluster di Azure Data Explorer completo.
La versione gratuita di Azure Data Explorer offre la possibilità di sperimentare il servizio, ma presenta alcuni limiti rispetto alle versioni a pagamento. Questi limiti sono pensati per fornire un assaggio delle funzionalità del servizio senza sostituire un ambiente di produzione a pieno regime. Ecco alcuni dei limiti tipici della versione gratuita:
- Capacità di archiviazione: La quantità di dati che potete archiviare nella versione gratuita è limitata. Questo limite è spesso espresso in termini di gigabyte o terabyte e tende ad essere significativamente inferiore rispetto ai piani a pagamento.
- Potenza di calcolo: I cluster gratuiti hanno capacità di calcolo limitate, il che significa che le risorse (CPU, memoria) assegnate al vostro cluster sono ridotte. Questo può influenzare le prestazioni delle query, specialmente con set di dati più grandi o query complesse.
- Velocità di ingestione dei dati: La velocità con cui i dati possono essere caricati in Azure Data Explorer potrebbe essere limitata nella versione gratuita. Questo potrebbe rendere meno efficiente l’uso del servizio per l’analisi di dati in tempo reale o per grandi volumi di dati.
- Funzionalità avanzate: Alcune funzionalità avanzate potrebbero non essere disponibili o essere limitate nella versione gratuita. Ciò include alcune opzioni di integrazione, funzionalità di sicurezza avanzate, e strumenti di analisi e di machine learning.
Alla pagina Iniziare gratuitamente con Azure Esplora dati – Azure Data Explorer | Microsoft Learn trovate le specifiche e le quote per un cluster gratuito.
Per la creazione di un cluster gratuito collegatevi al link Azure Data Explorer e inserite le informazioni richieste per la creazione del nuovo cluster. Effettuate il login utilizzando un Microsoft Account gratuito oppure una utenza di Microsoft Entra ID.
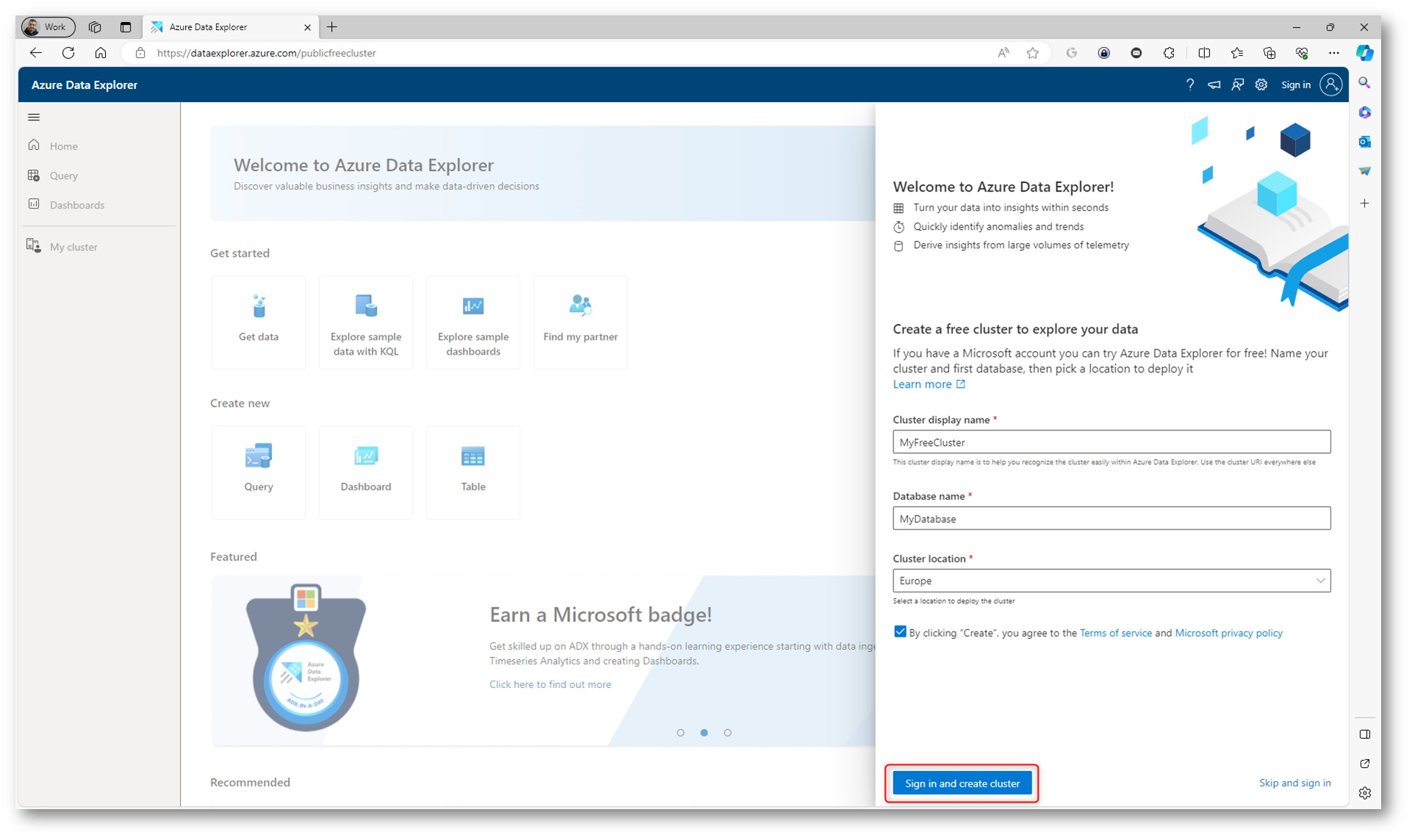
Figura 1: Login e creazione del nuovo cluster in Azure data Explorer
La creazione del cluster dura pochi secondi.
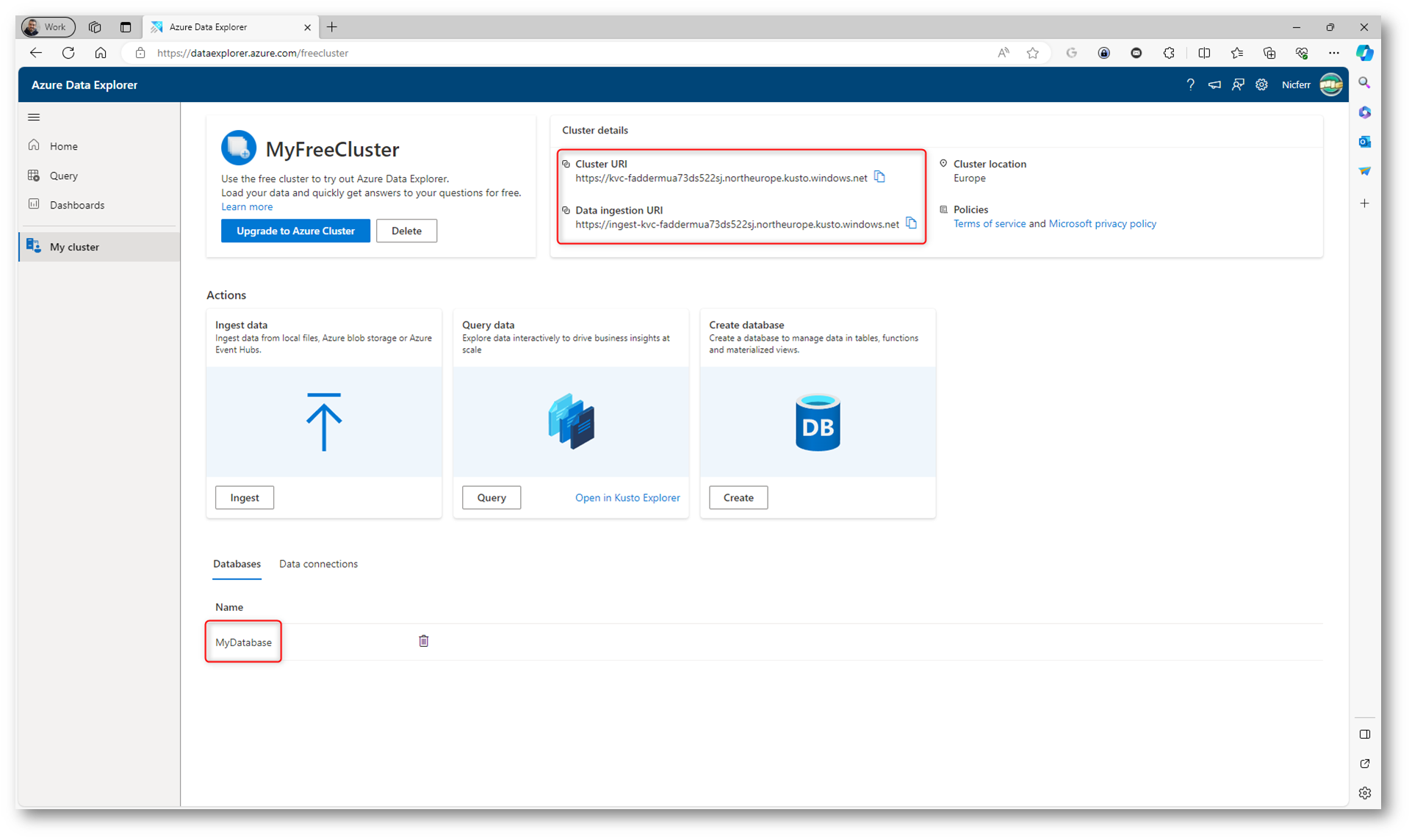
Figura 2: Creazione del cluster e del database completata
La Data Ingestion in Azure Data Explorer è un processo fondamentale che consente di caricare dati da varie fonti nel cluster di Azure Data Explorer per l’analisi. Questo processo è ottimizzato per gestire grandi volumi di dati con alta velocità. Vediamo come funziona:
- Sorgenti dei dati: Prima di tutto, è necessario avere dati da caricare. Azure Data Explorer può ingestire dati da diverse sorgenti, come file, flussi di dati in tempo reale, database, e altri servizi cloud.
-
Metodi di ingestione: Ci sono vari metodi per caricare dati in Azure Data Explorer:
- Ingestione diretta: caricare dati direttamente tramite il portale di azure o utilizzando strumenti come kusto.explorer o azure data studio.
- ingestione programmatica: Utilizzare SDK di Azure Data Explorer disponibili in vari linguaggi di programmazione per caricare dati.
- Azure Data Factory: Utilizzare Azure Data Factory per orchestrare e automatizzare il trasferimento di dati in Azure Data Explorer.
- Connettori per dati in streaming: Integrare con servizi come Azure Event Hubs o Azure IoT Hub per ingestire dati in streaming.
- Formati di dati: Azure Data Explorer supporta vari formati di dati, inclusi CSV, JSON, Avro, Parquet e altri. Questo permette di ingestire dati da una vasta gamma di applicazioni e piattaforme.
- Preparazione dei dati: Prima dell’ingestione, i dati possono essere trasformati o arricchiti. Questo può includere operazioni come il filtraggio, la modifica del formato, l’aggiunta di timestamp, ecc.
- Mapping dei dati: Durante l’ingestione, i dati devono essere mappati alle colonne delle tabelle nel database di Azure Data Explorer. Questo mapping definisce come i dati nei file o nei flussi vengono assegnati alle colonne appropriate nel database.
- Batch e ingestione in tempo reale: Azure Data Explorer supporta sia l’ingestione batch (caricare grandi quantità di dati in una volta) sia l’ingestione in tempo reale (continuamente ingestire flussi di dati).
- Scalabilità e performance: L’ingestione in Azure Data Explorer è altamente scalabile. Il servizio può gestire alti volumi di dati e velocità di ingestione, adattandosi alle esigenze di carico di lavoro.
- Monitoraggio e gestione dell’ingestione: dopo l’ingestione, è possibile monitorare lo stato e le prestazioni del processo di ingestione utilizzando strumenti forniti da Azure, come metriche e log.
- Sicurezza e conformità: Azure Data Explorer fornisce funzionalità per garantire la sicurezza e la conformità dei dati durante il processo di ingestione, inclusa la crittografia dei dati in transito e a riposo.
Per approfondimenti vi rimando alla lettura della pagina Azure Data Explorer data ingestion overview – Azure Data Explorer | Microsoft Learn
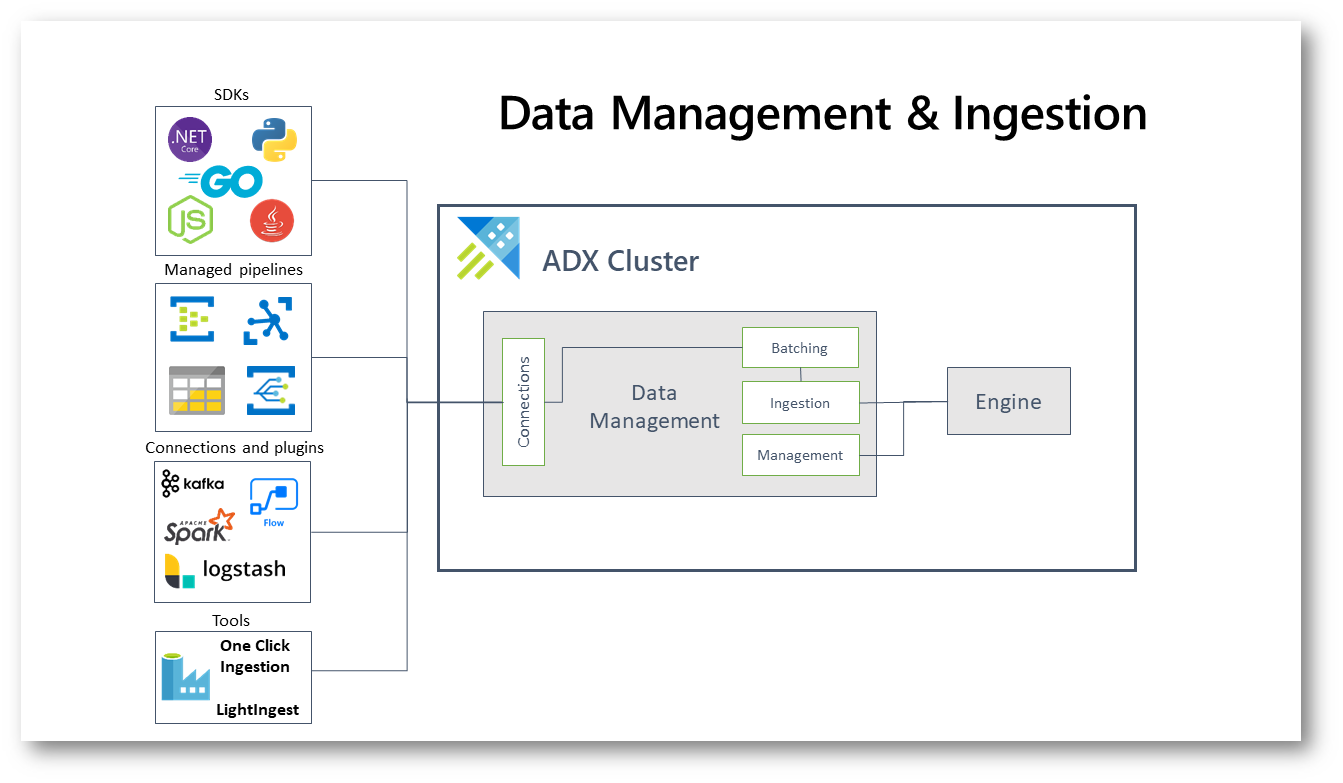
Figura 3: Azure Data Explorer data ingestion overview
Potete importare i vostri dati utilizzando il pulsante Ingest e selezionando il data source, come mostrato nella figura sotto:
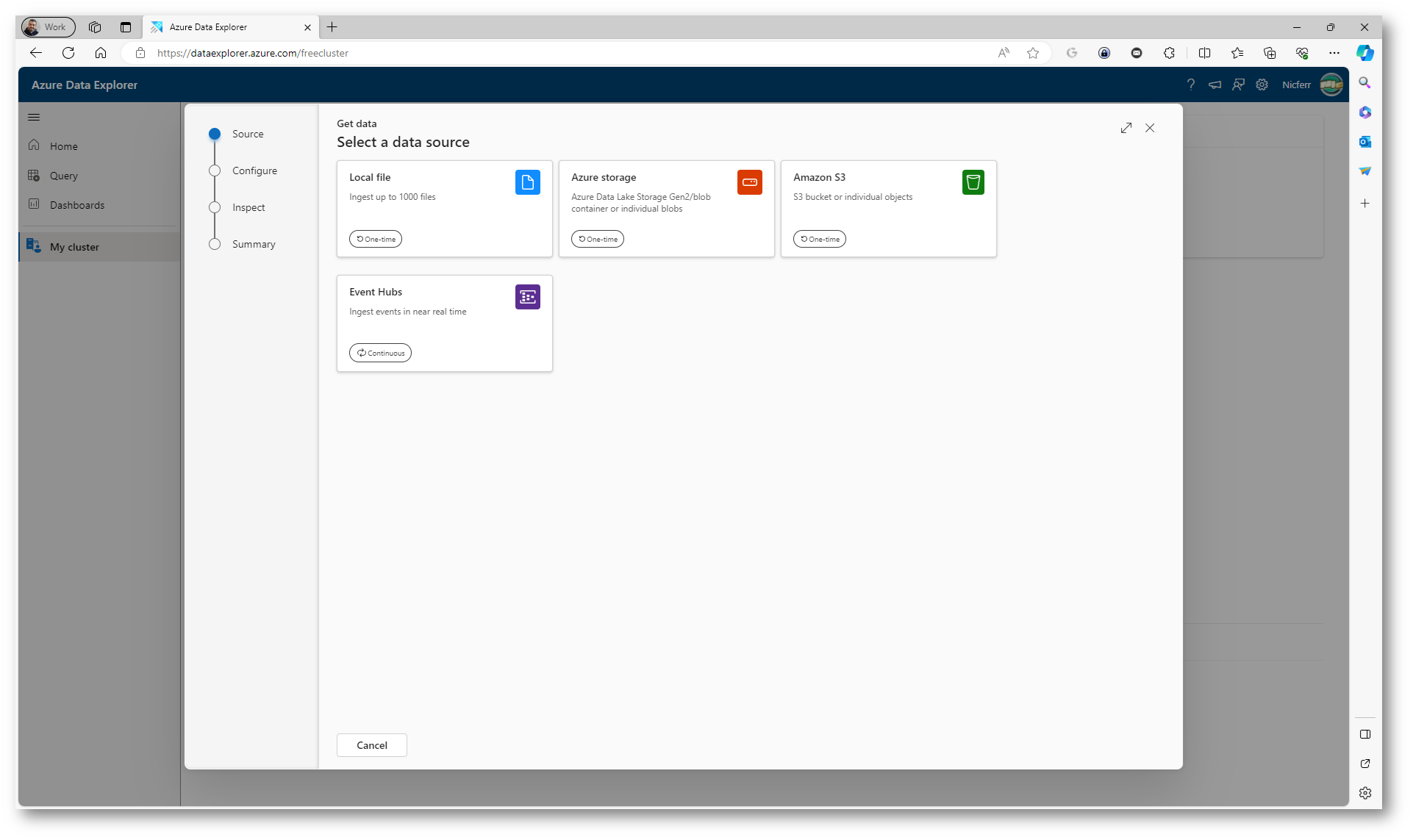
Figura 4: Inserimento dei dati partendo da un data source
Terminato il processo di ingestione dei dati potete cominciare a scrivere le vostre query utilizzando il pulsante Query.
Le query in Azure Data Explorer sono gestite tramite il Kusto Query Language (KQL), un linguaggio di query ricco e flessibile progettato per analisi di grandi volumi di dati in modo efficiente e rapido. Per cominciare a lavorare con KQL vi rimando alla lettura della guida Panoramica del Linguaggio di query Kusto (KQL) – Azure Data Explorer & Real-Time Analytics | Microsoft Learn
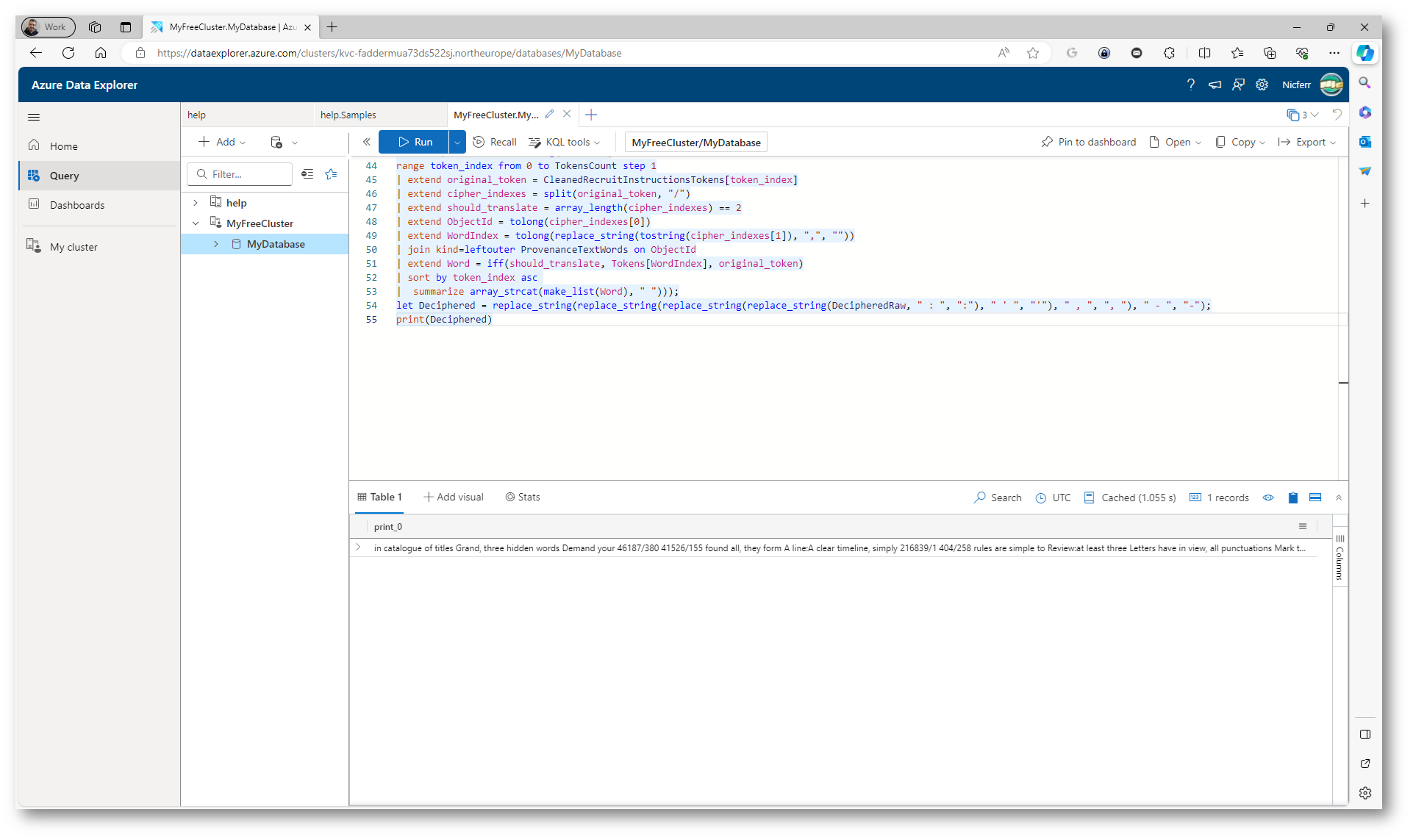
Figura 5: Utilizzo di query KQL in Azure Data Explorer
I dati poi possono essere visualizzati tramite le Dashboard. Le dashboard di Azure Data Explorer sono strumenti visivi interattivi utilizzati per monitorare, analizzare e visualizzare i dati. Sono essenziali per trasformare grandi set di dati in informazioni comprensibili e azionabili. Riassumo qui di seguito cosa sono e a che servono:
- Visualizzazione dei dati: Le dashboard permettono di visualizzare i dati in modi facilmente interpretabili. Possono includere grafici, tabelle, mappe e altre forme di rappresentazioni grafiche. Queste visualizzazioni aiutano a comprendere meglio i pattern, le tendenze e le anomalie nei dati.
- Personalizzazione e flessibilità: Gli utenti possono personalizzare le dashboard in base alle loro esigenze specifiche. Possono scegliere quali dati visualizzare, come organizzarli e in che modo rappresentarli graficamente. Questo rende le dashboard strumenti potenti per una vasta gamma di scenari di analisi.
- Analisi in tempo reale: Le dashboard di Azure Data Explorer sono spesso utilizzate per monitorare dati in tempo reale, come dati di telemetria, log di applicazioni, o flussi di dati da sensori IoT. Forniscono aggiornamenti continui che permettono agli utenti di vedere immediatamente gli impatti delle loro azioni o di eventi esterni.
- Interattività: Le dashboard non sono solo statiche; offrono interattività, consentendo agli utenti di esplorare i dati in modo più approfondito. Gli utenti possono ad esempio filtrare i dati, esaminare specifici intervalli di tempo, o cliccare su elementi del grafico per ottenere dettagli maggiori.
- Supporto decisionale: Forniscono supporto decisionale ai manager e agli analisti di business, consentendo loro di basare le loro decisioni su dati aggiornati e analisi approfondite.
- Condivisione e collaborazione: Le dashboard possono essere condivise con altri membri del team, facilitando la collaborazione e la comunicazione basata sui dati. Questo è particolarmente utile in ambienti aziendali dove team diversi devono lavorare insieme su dati comuni.
- Monitoraggio e alert: Possono essere utilizzate per monitorare le prestazioni di sistemi e applicazioni. Ad esempio, possono essere impostati degli alert basati sui dati visualizzati, in modo da avvisare gli utenti in caso di anomalie o problemi.
- Integrazione con altri servizi: Le dashboard di Azure Data Explorer possono essere integrate con altri servizi Azure, come Azure Monitor e Azure Logic Apps, per una gestione e analisi dei dati ancora più potente e centralizzata.
Per approfondimenti vi rimando alla lettura della pagina Creare dashboard in Esplora dati di Azure – Training | Microsoft Learn
Figura 6: Dashboard in Azure Data Explorer
Come ho già scritto prima, in qualsiasi momento è possibile aggiornare il cluster a un cluster di Azure Data Explorer completo. Basterà cliccare sul pulsante Upgrade to Azure Cluster e inserire le informazioni richieste. Completate l’upgrade facendo clic su Upgrade.
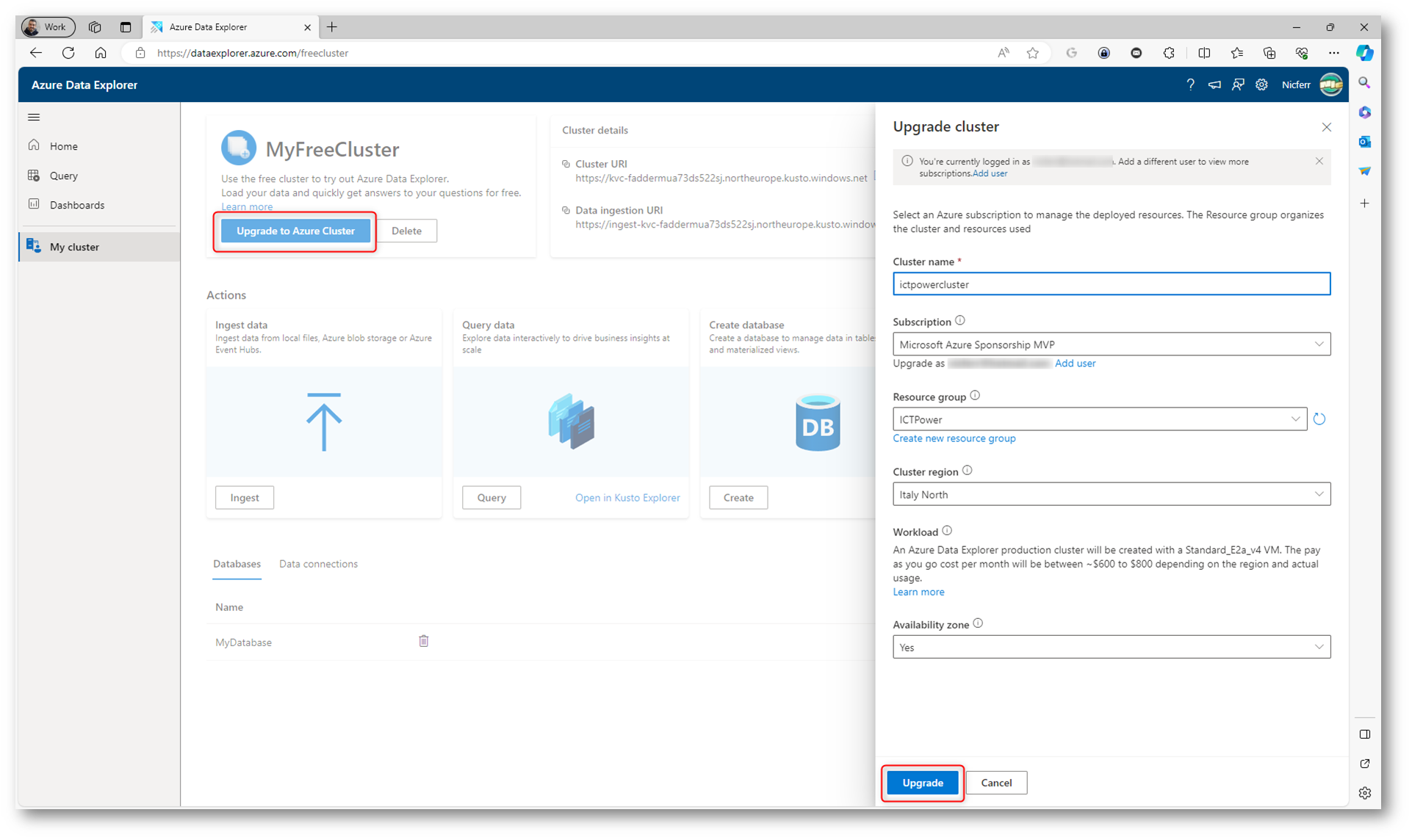
Figura 7: Upgrade del cluster gratuito a un cluster di Azure Data Explorer completo
Nel giro di qualche minuto il vostro cluster sarà disponibile nel portale Azure.
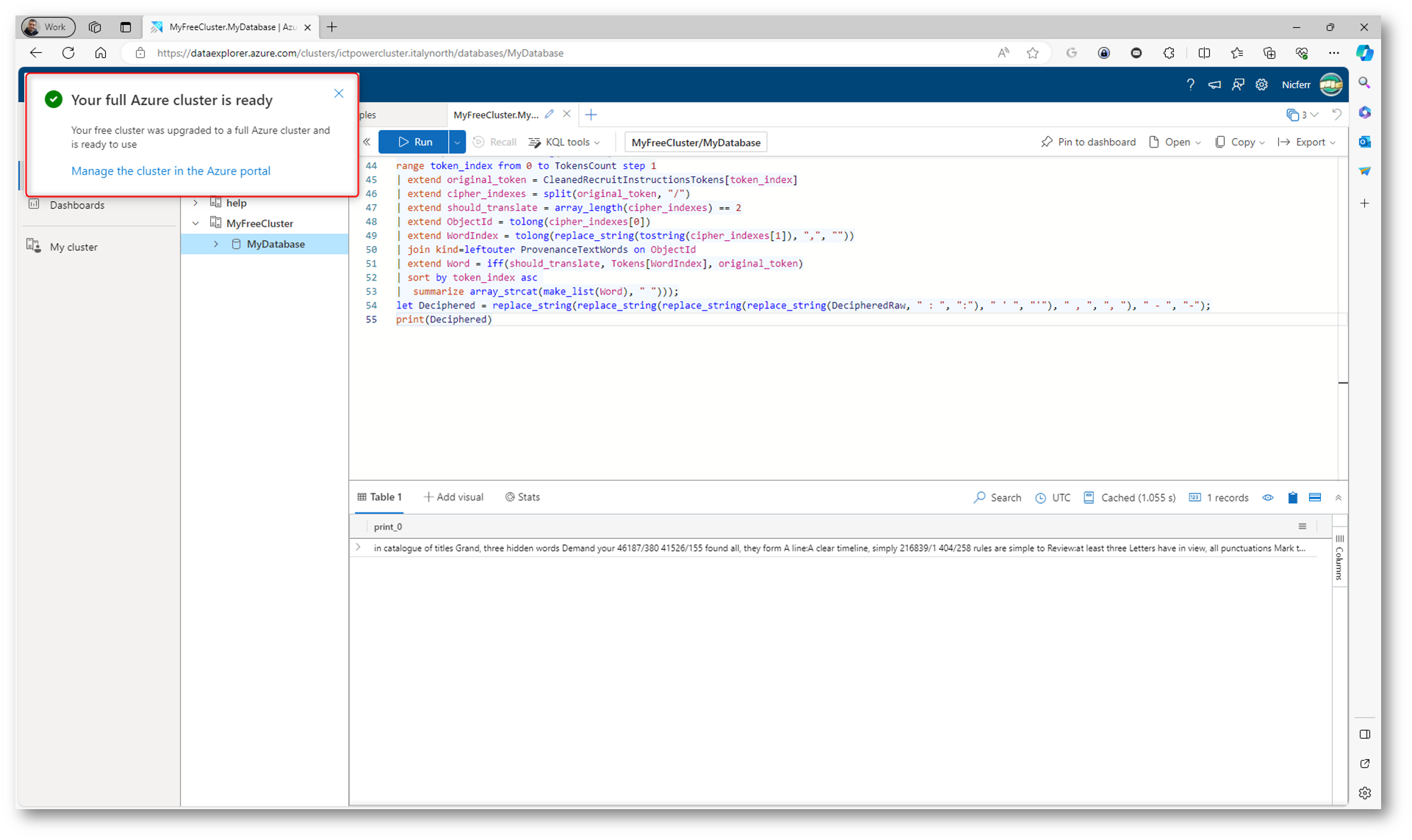
Figura 8: Upgrade del cluster gratuito completata
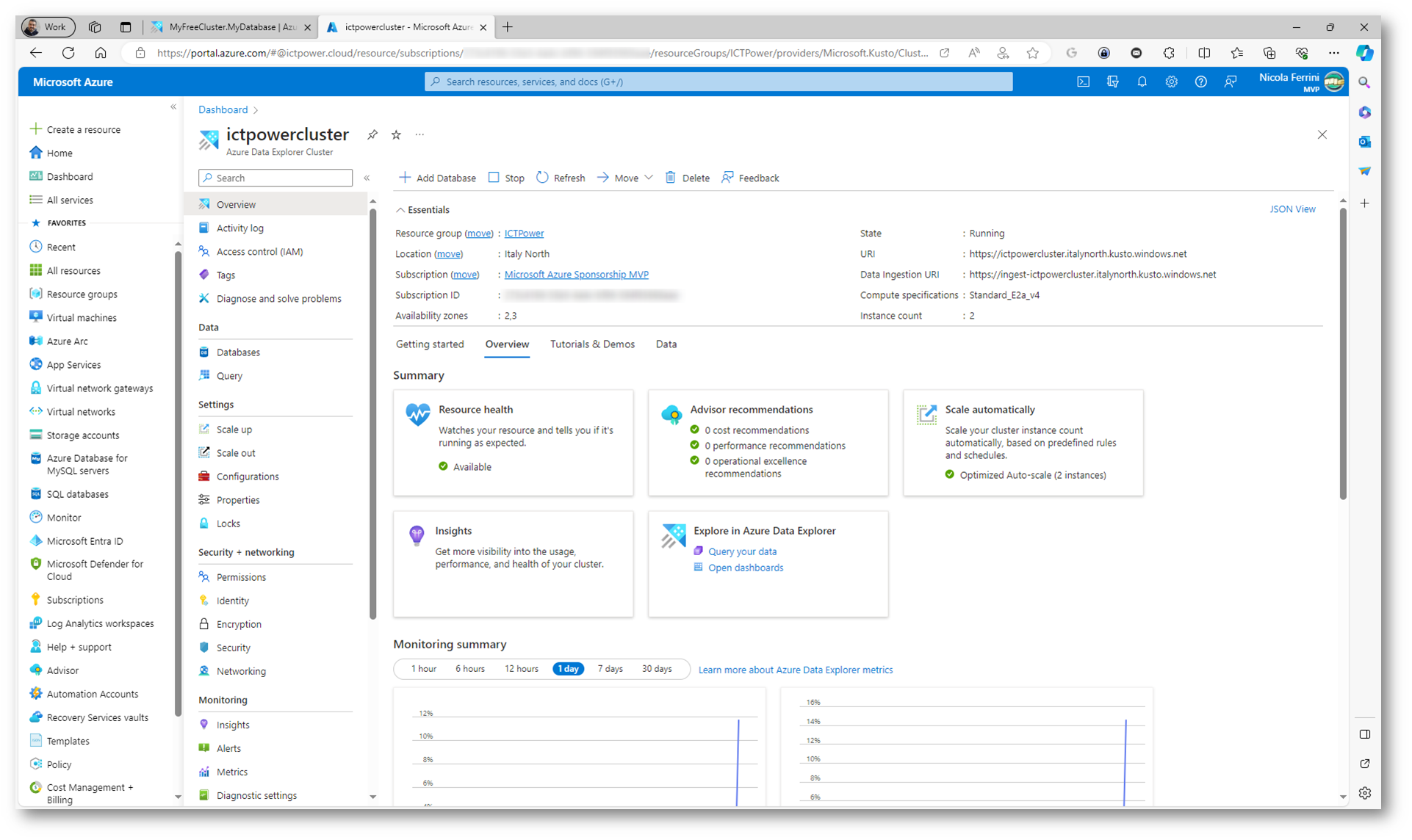
Figura 9: Cluster migrato e disponibile nel portale di Microsoft Azure
Creazione di un cluster di Azure Data Explorer dal portale di Microsoft Azure
Potete creare un cluster di Azure Data Explorer completo dal portale di Azure, a patto di avere una sottoscrizione Azure . Nel portale di Azure cercate “Azure Data Explorer” e seguite i passaggi per configurare un nuovo cluster.
Figura 10: Creazione di un nuovo Azure Data Explorer dal portale di Microsoft Azure
Scegliete un nome univoco che identifica il cluster. Il nome di dominio [region].kusto.windows.net viene accodato al nome del cluster specificato. Il nome può contenere solo lettere minuscole e numeri e deve avere una lunghezza compresa tra 4 e 22 caratteri. Per quanto riguarda le specifiche dell’ambiente di calcolo io ho scelto Dev/Test per questa guida introduttiva. Per un sistema di produzione selezionate la specifica più appropriata in base alle esigenze. L’attivazione delle Zone di disponibilità distribuisce le risorse di archiviazione e calcolo del cluster in più zone fisiche all’interno di una Region di Azure per una maggiore disponibilità e protezione da guasti. Per impostazione predefinita questa funzionalità viene attivata se le zone sono supportate nella Region che avete scelto.
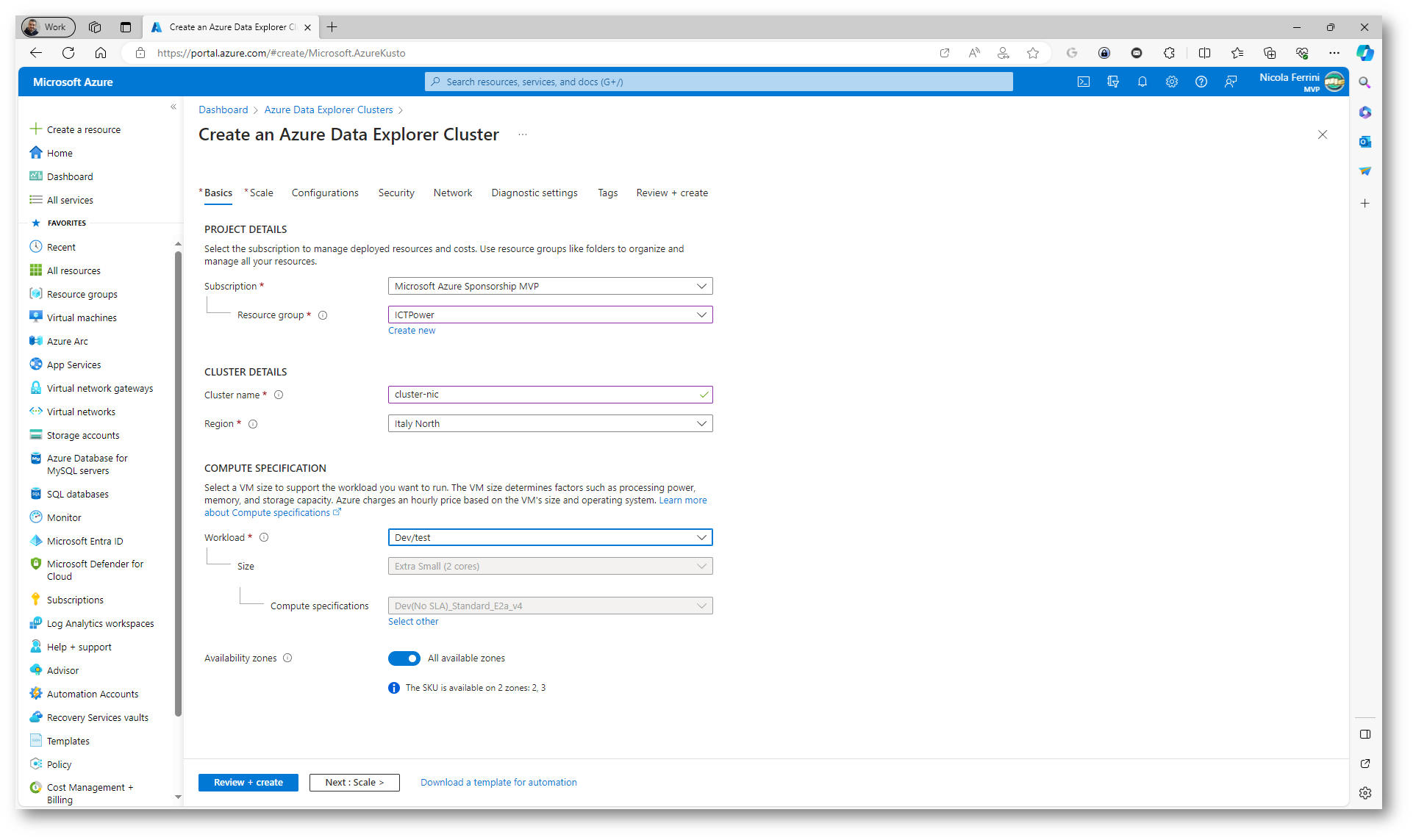
Figura 11: Scheda Basics del wizard di creazione del nuovo Azure Data Explorer cluster
Azure Data Explorer (ADX) è un servizio di analisi dati altamente scalabile e veloce offerto da Microsoft Azure. La scalabilità di un cluster di Azure Data Explorer è una delle sue caratteristiche principali. ADX supporta sia la scalabilità orizzontale (aggiungendo più nodi al cluster) sia quella verticale (aumentando le risorse come CPU e memoria in un nodo). Questo permette di gestire facilmente carichi di lavoro crescenti aggiustando le risorse in base alle esigenze. Nella scheda Scale potete scegliere se scalare manualmente oppure abilitare l’autoscaling.
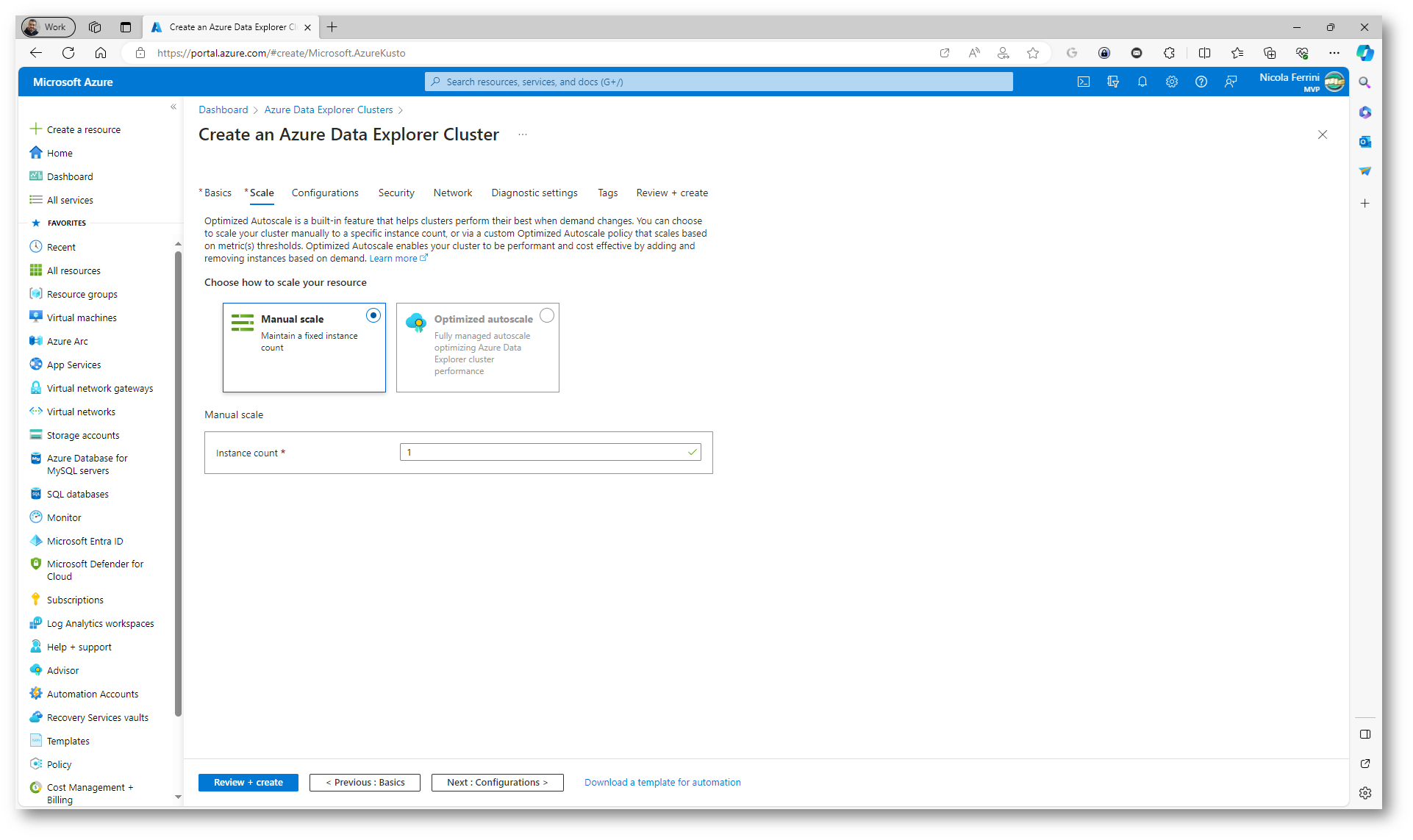
Figura 12: Scheda Scale del wizard di creazione del nuovo Azure Data Explorer cluster
Nella scheda Configurations sarà possibile abilitare o meno 3 diverse funzionalità: “Streaming Ingestion”, “Enable Purge” e “Auto-Stop Cluster”. Queste opzioni influenzano il modo in cui il cluster gestisce l’ingestione dei dati, la manutenzione dei dati e la gestione delle risorse.
La funzionalità di Streaming ingestion permette l’ingestione di dati in streaming in tempo reale, essenziale per analizzare dati generati continuamente, come i dati di telemetria o i log delle applicazioni. Ciò riduce notevolmente il tempo necessario per rendere i dati disponibili alle query. La funzionalità Enable purge fornisce agli amministratori la capacità di eliminare dati dal cluster, indispensabile per la rimozione di dati obsoleti o per aderire a normative specifiche, permettendo di eseguire operazioni di pulizia in base a criteri definiti. Infine, Auto-Stop cluster è una caratteristica di gestione delle risorse che consente al cluster di arrestarsi automaticamente dopo un periodo di inattività, un’opzione utile per ridurre i costi, specialmente in ambienti di sviluppo o test, garantendo che il cluster sia attivo solo quando necessario e possa essere riavviato in base alle esigenze.
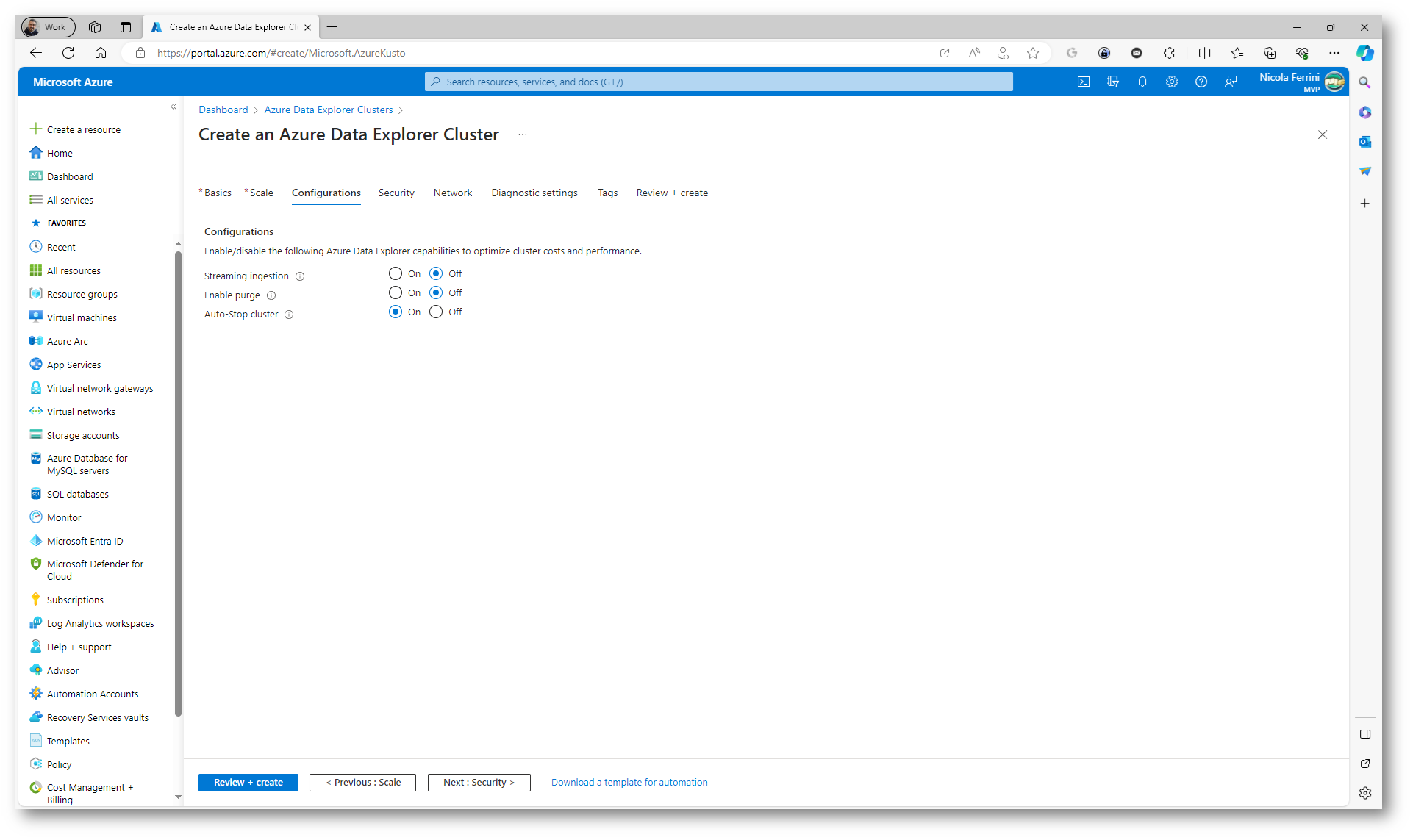
Figura 13: Scheda Configurations del wizard di creazione del nuovo Azure Data Explorer cluster
Nella scheda Security troviamo le voci Security e Identity che si riferiscono a importanti aspetti legati alla sicurezza e alla gestione delle identità all’interno del cluster. Security comprende tutte le misure e le configurazioni volte a proteggere il cluster da accessi non autorizzati e abilita funzionalità per la crittografia dei dati a riposo
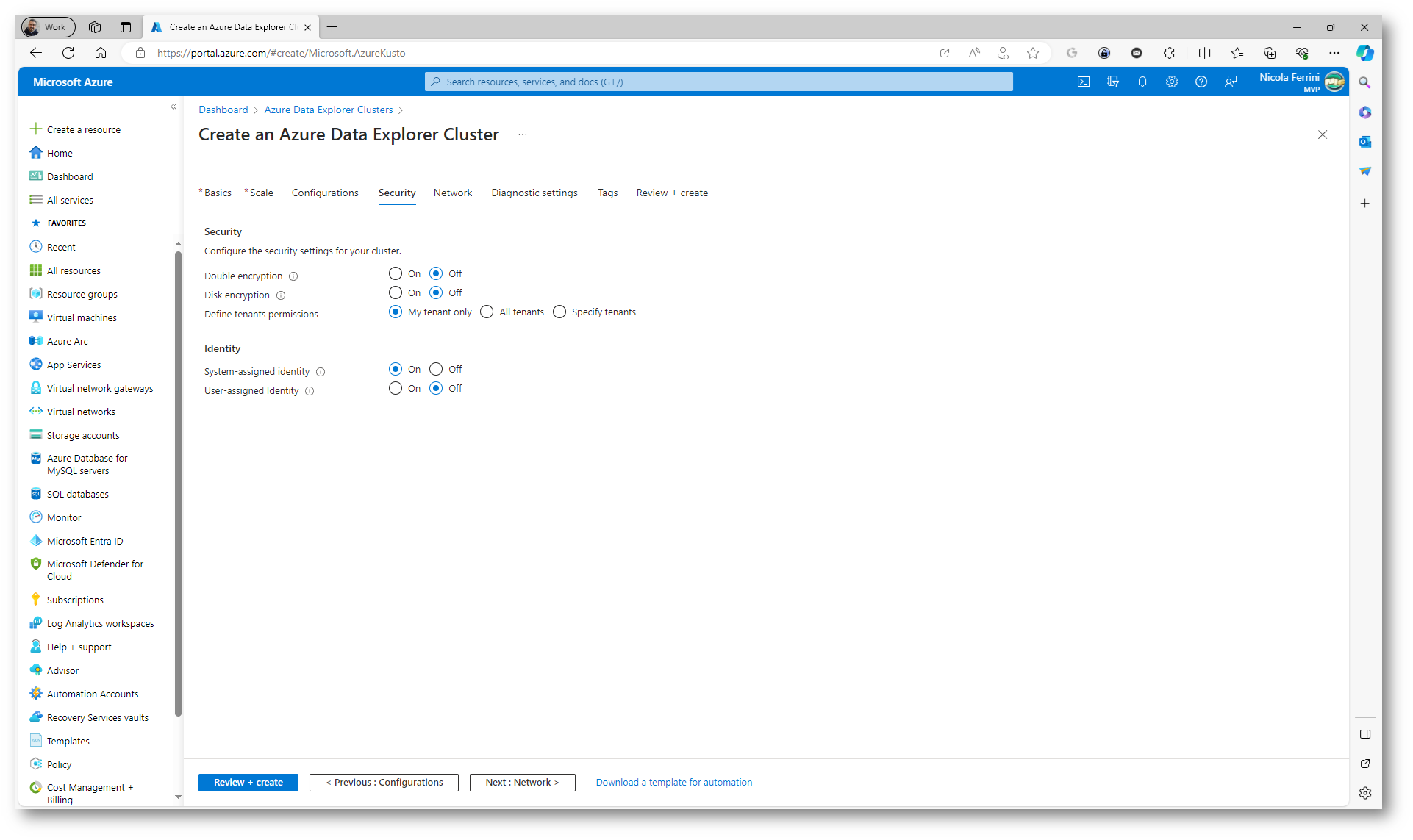
Figura 14: Scheda Security del wizard di creazione del nuovo Azure Data Explorer cluster
Nella scheda Network possiamo decidere se il cluster deve essere accessibile da Internet oppure soltanto da una rete di Azure tramite un Private endpoint. Un Private Endpoint in Azure è una funzionalità di rete che consente la connessione privata e sicura tra le risorse di Azure e i servizi Azure PaaS, come Azure Data Explorer, tra gli altri. Questa connessione viene stabilita all’interno della rete virtuale (VNet) di Azure. La caratteristica chiave del Private Endpoint è che fornisce una connettività sicura e privata alla rete virtuale, eliminando l’esposizione dei servizi Azure su un indirizzo IP pubblico. Questo è particolarmente importante per migliorare la sicurezza e ridurre il rischio di attacchi esterni.
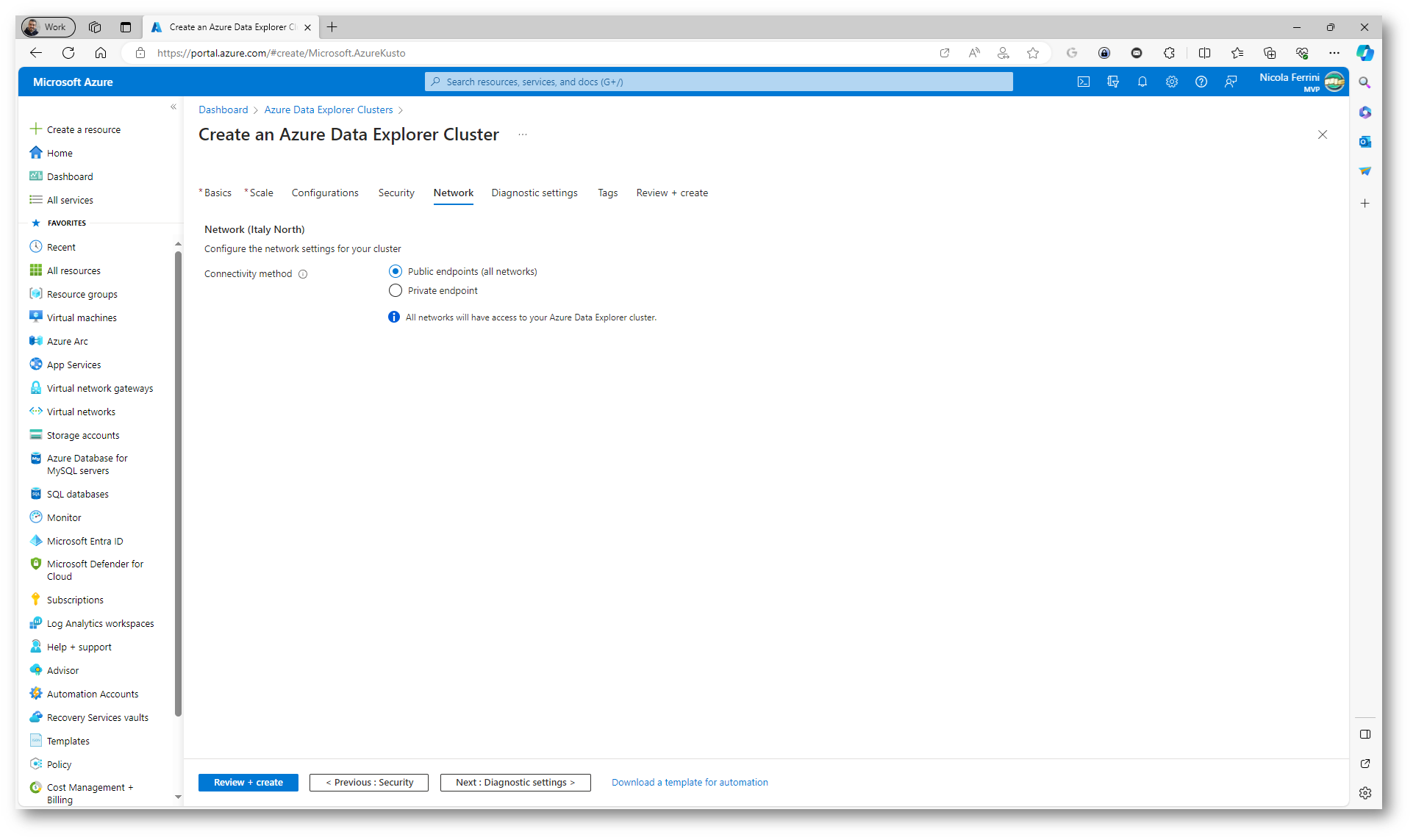
Figura 15: Scheda Network del wizard di creazione del nuovo Azure Data Explorer cluster
Nella scheda Diagnostic settings potete abilitare la possibilità di inviare i log di Azure Data Explorer cluster ad un workspace di Log Analytics. Attraverso i Diagnostic Settings, è possibile raccogliere log come quelli di audit, di sicurezza, di attività e di servizio, oltre a metriche che forniscono misurazioni sulle prestazioni delle risorse. Questi dati possono essere utili per la diagnostica, il monitoraggio, l’auditing, la performance tuning e l’analisi di sicurezza.
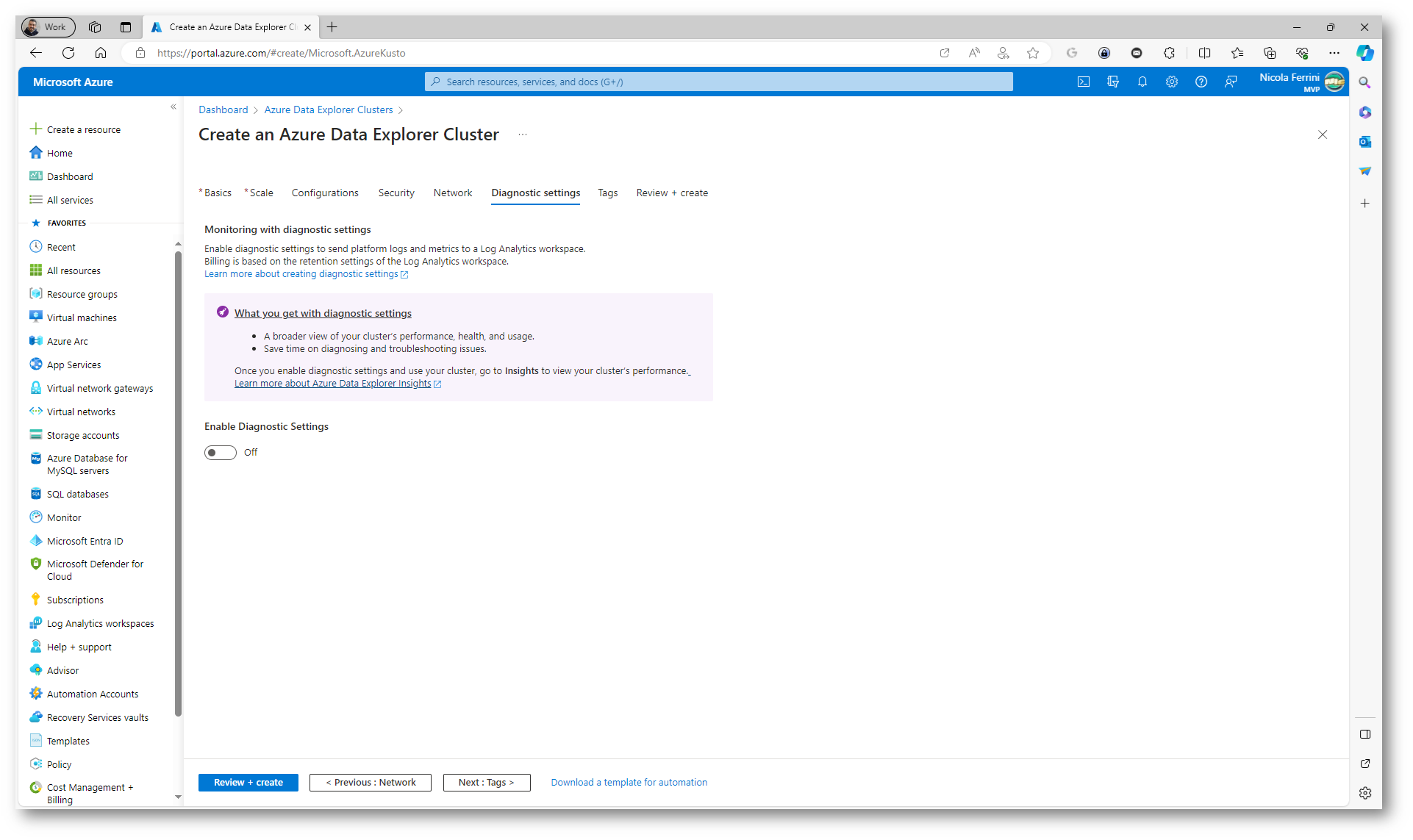
Figura 16: Scheda Diagnostic settings del wizard di creazione del nuovo Azure Data Explorer cluster
Completate il wizard dalla scheda Review + create verificando le informazioni inserite e cliccate su Create.
Figura 17: Schermata finale del wizard di creazione del nuovo Azure Data Explorer cluster
Nel giro di qualche secondo il vostro cluster sarà operativo.
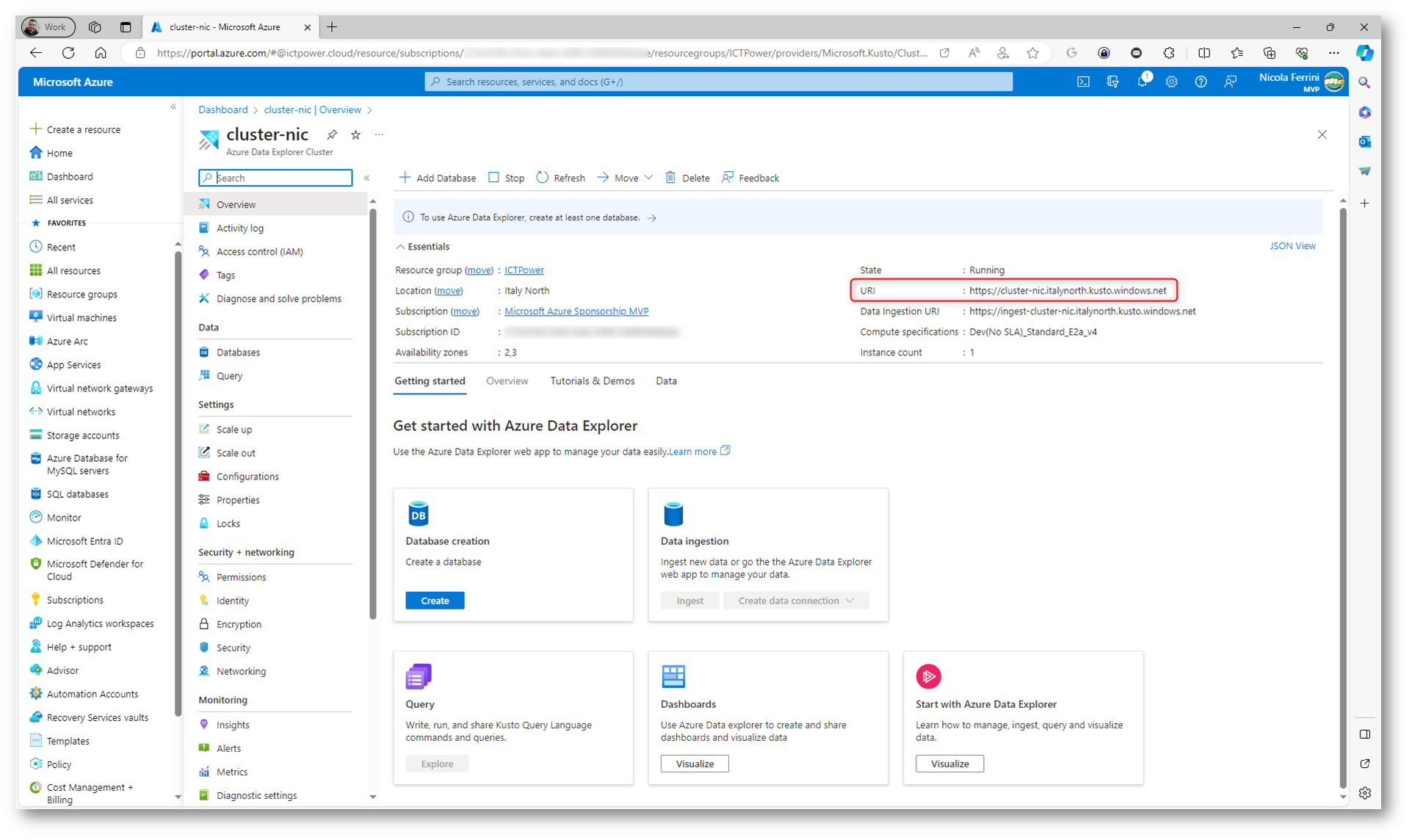
Figura 18: Creazione del cluster di Azure Data Explorer completata
Creazione di un database in un Azure Data Explorer cluster
Terminata la creazione del cluster potete creare un nuovo database. Il database in un cluster di Azure Data Explorer (ADX) serve come unità fondamentale per l’organizzazione, la gestione e l’analisi dei dati all’interno del servizio ed è il posto in cui i dati vengono immagazzinati ed interrogati.
Dalla schermata Overview fate clic su Create nell’area Database creation. Date un nome dal database (il nome deve essere univoco all’interno del cluster) e scegliete il numero di giorni che i dati devono essere mantenuti disponibili per l’esecuzione di query nel campo Retention period. Il periodo viene misurato dal momento in cui vengono inseriti i dati. Popolate anche il campo Cache period inserendo il numero di giorni per mantenere i dati sottoposti a query frequenti nell’archiviazione SSD o nella RAM per ottimizzare l’esecuzione di query.
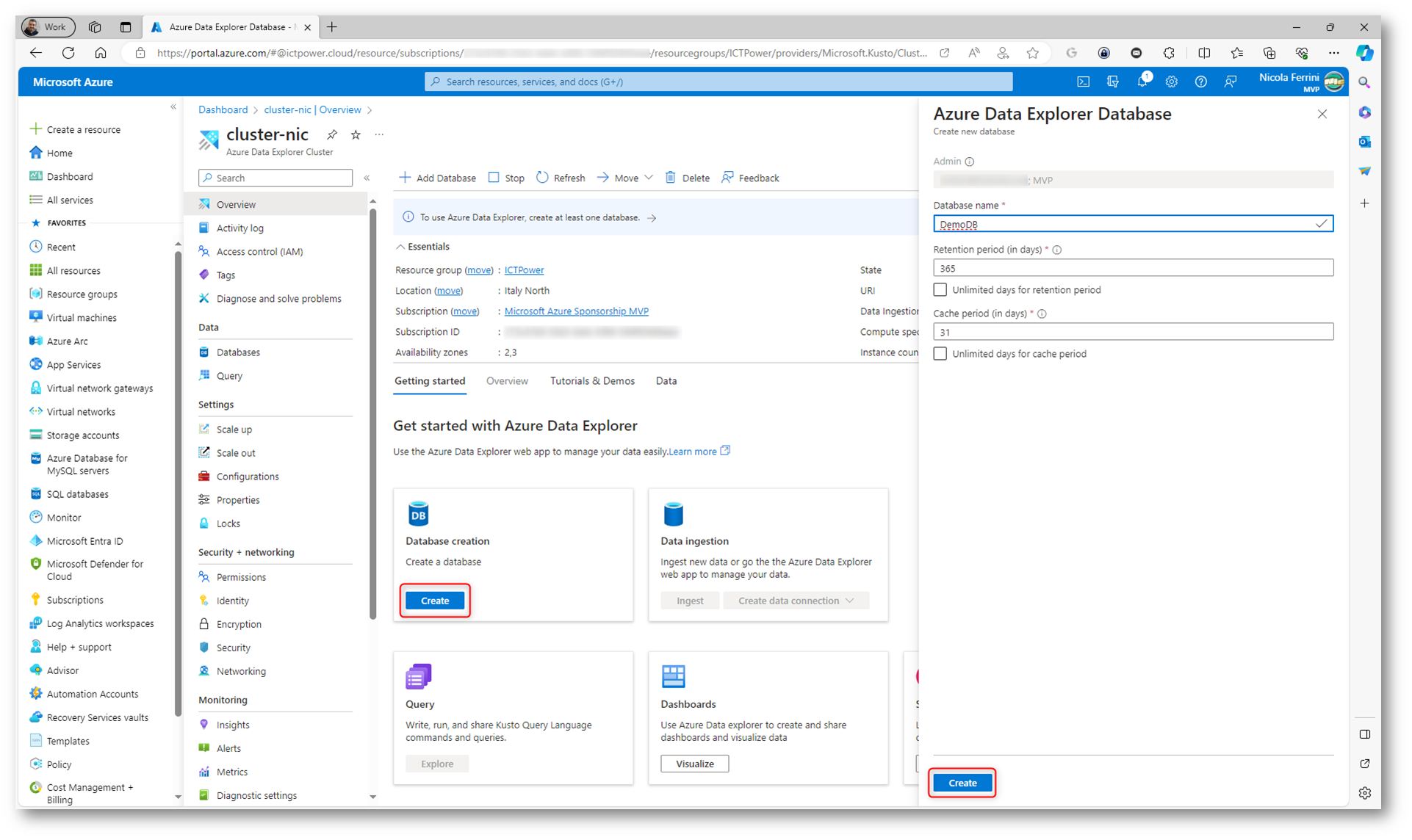
Figura 19: Aggiunta di un nuovo database
La creazione del database dura pochi secondi.
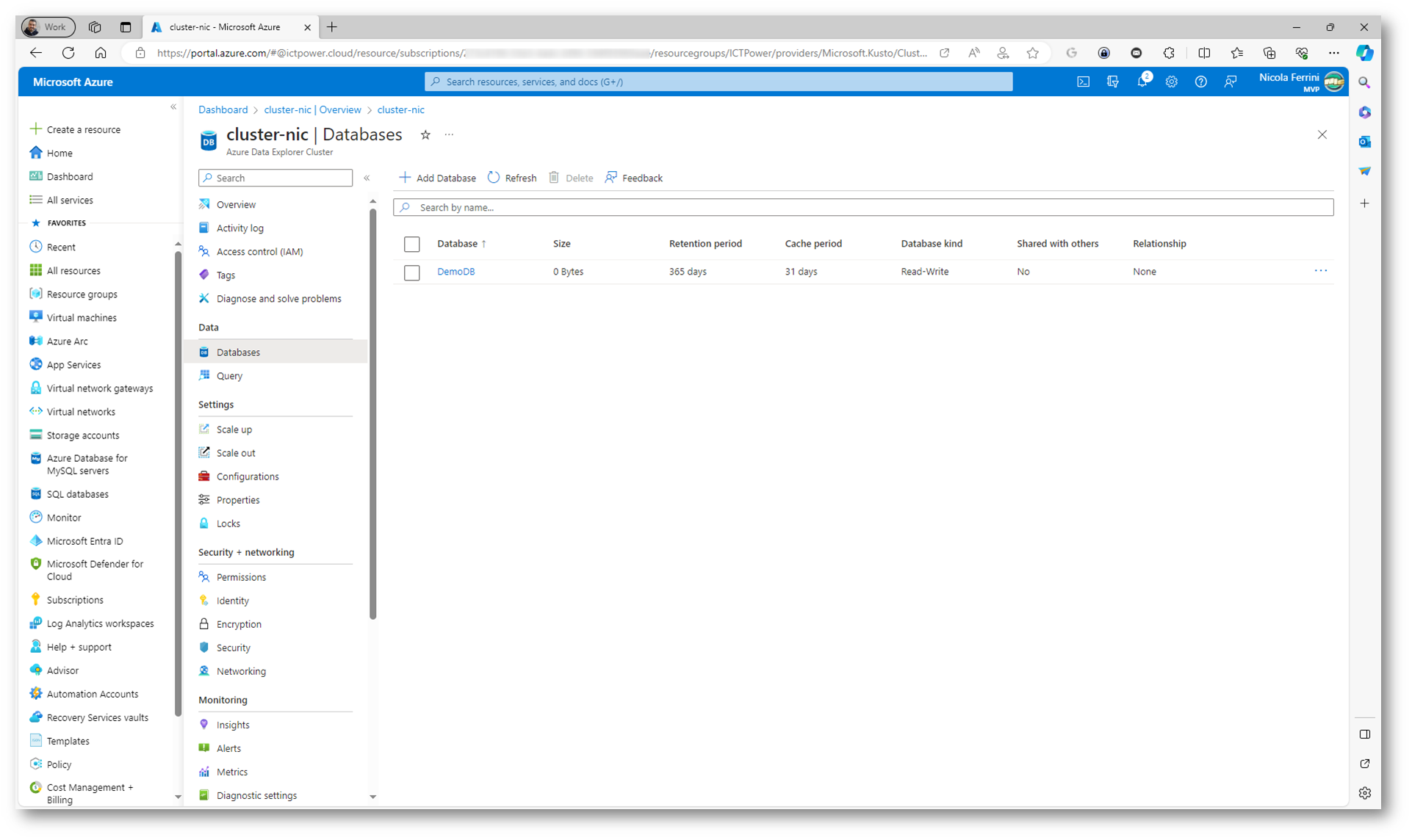
Figura 20: creazione del nuovo database completata
Cliccate sul database appena creato e dal nodo Query cliccate col tasto destro sul database e scegliete Create Table. La creazione di una tabella è un passaggio importante nel processo di inserimento e query dei dati in Azure Data Explorer perché serve come struttura principale per l’immagazzinamento e l’organizzazione dei dati. In ADX, un database può contenere una o più tabelle, ognuna delle quali è progettata per archiviare dati correlati in un formato strutturato.
Le tabelle forniscono una struttura definita per memorizzare i dati, organizzati in colonne e righe. Ogni colonna rappresenta un tipo specifico di dato (come numeri, stringhe, date), mentre ogni riga rappresenta un record o un’entità. La strutturazione dei dati in tabelle rende più efficiente l’esecuzione di query. ADX è ottimizzato per eseguire rapidamente query complesse su grandi volumi di dati, e la struttura tabellare aiuta a ottimizzare queste operazioni.
Le tabelle in ADX sono progettate per gestire efficacemente l’ingestione di grandi volumi di dati, che possono provenire da diverse fonti, come log di applicazioni, sensori IoT, flussi di dati in tempo reale e altro e forniscono la base per analisi dettagliate e operazioni di reporting. Gli utenti possono eseguire varie tipologie di analisi sui dati, dall’analisi di tendenze storiche all’elaborazione di query in tempo reale.
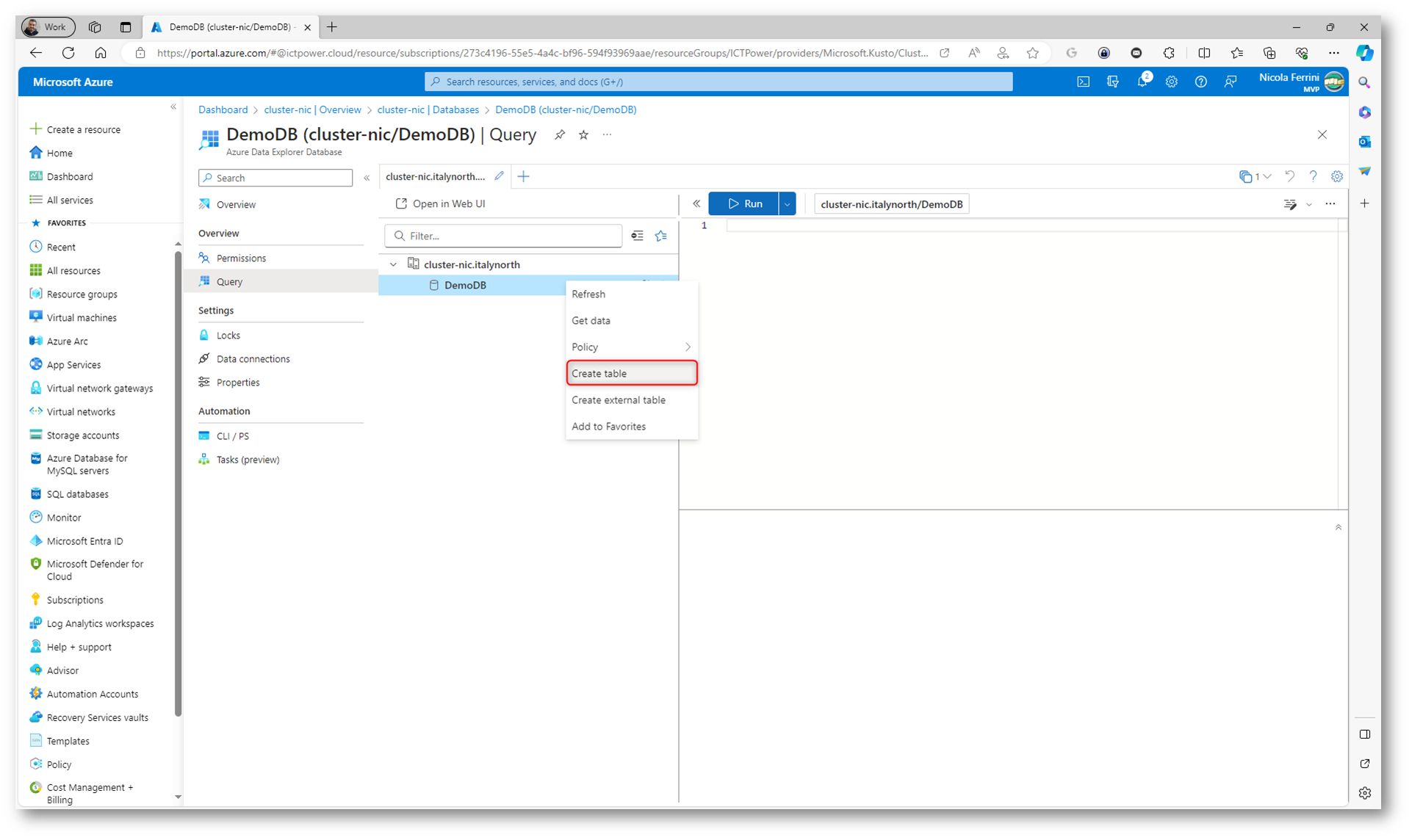
Figura 21: Creazione di una nuova tabella nel database di Azure Data Explorer
Nella nuova scheda del browser seguite il wizard per la creazione della nuova tabella e compilate i campi come richiesto.
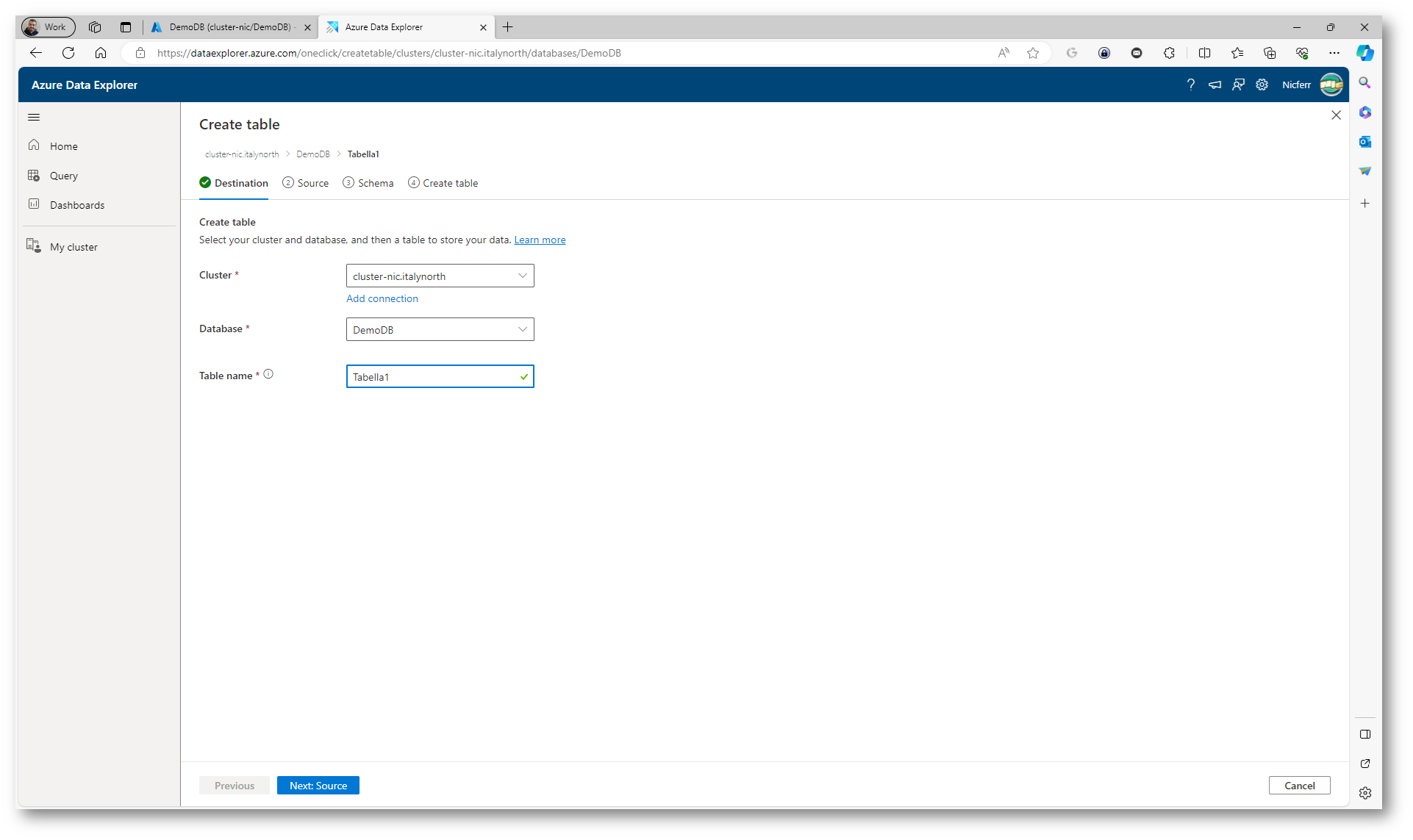
Figura 22: Creazione della nuova tabella
Nella scheda Source selezionate l’origine dati che userete per creare il mapping delle tabelle.
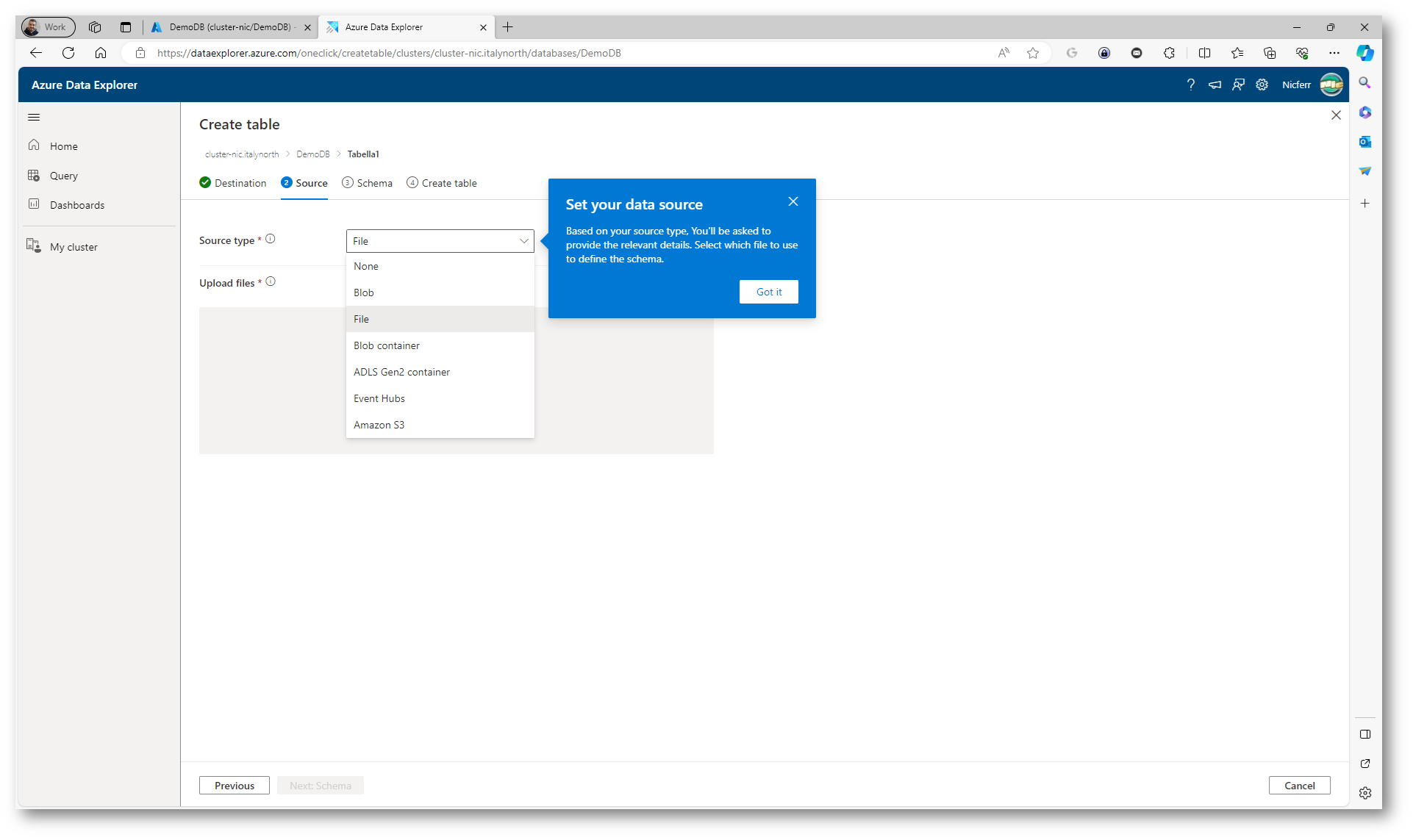
Figura 23: Scelta del Source type dei dati da inserire un tabella
Io ho scelto di utilizzare un file e l’ho caricato utilizzando l’apposito pulsante.
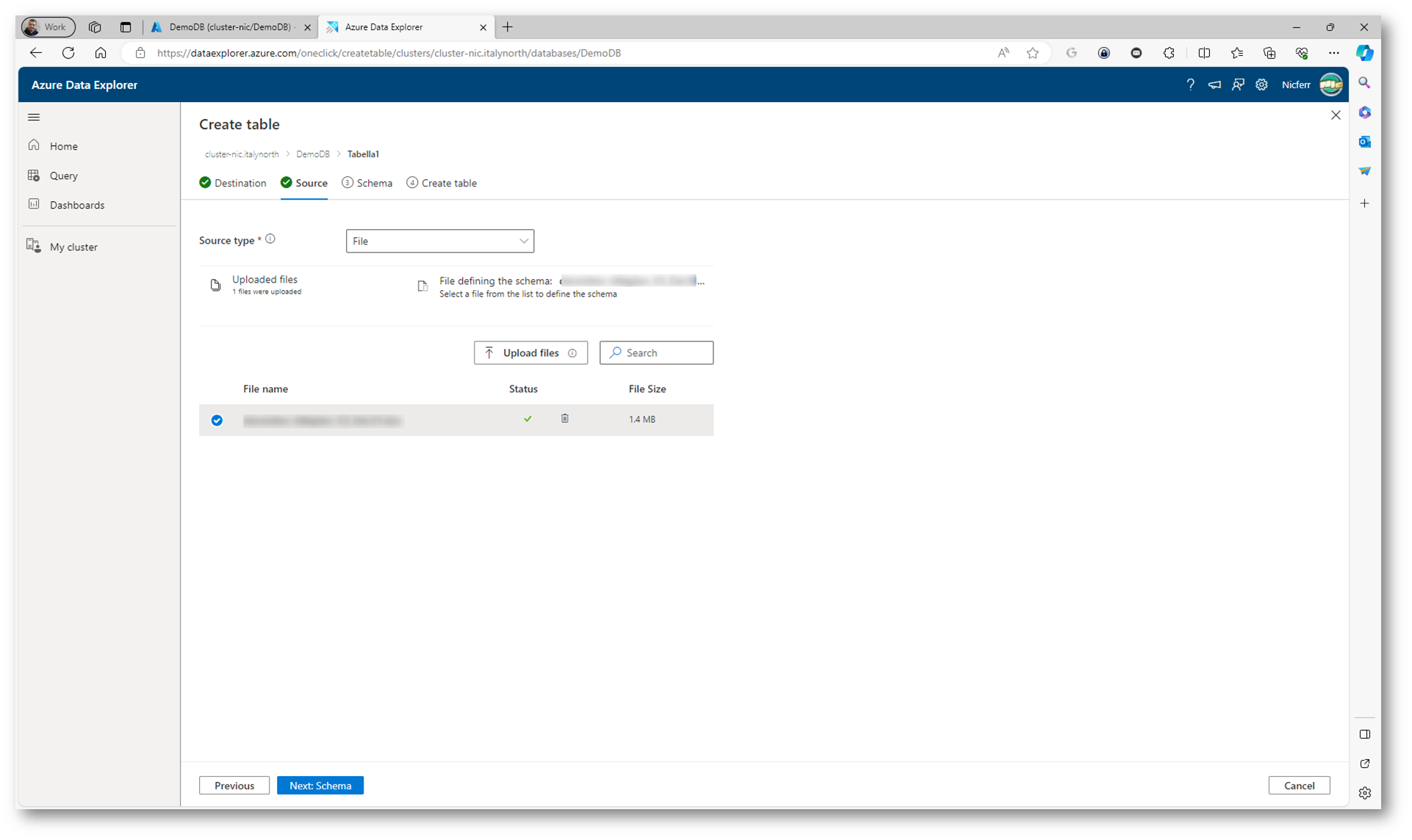
Figura 24: Dati della tabella caricati da un file
Nella scheda Schema il formato dati e la compressione vengono identificati automaticamente nel riquadro a sinistra. Se non è stato identificato correttamente, usare il menu a discesa Formato dati per selezionare il formato corretto.
- Se il formato dati è JSON, è necessario selezionare anche i livelli JSON, da 1 a 10. I livelli determinano la divisione dei dati nelle colonne della tabella.
- Se il formato di dati è CSV, selezionare la casella di controllo Ignora il primo record per ignorare la riga di intestazione del file.
Io ho usato un file CSV e ho specificato che il primo record deve essere ignorato perché è l’intestazione delle colonne. Dalla preview sarà possibile visualizzare se i dati sono stati riconosciuti correttamente.
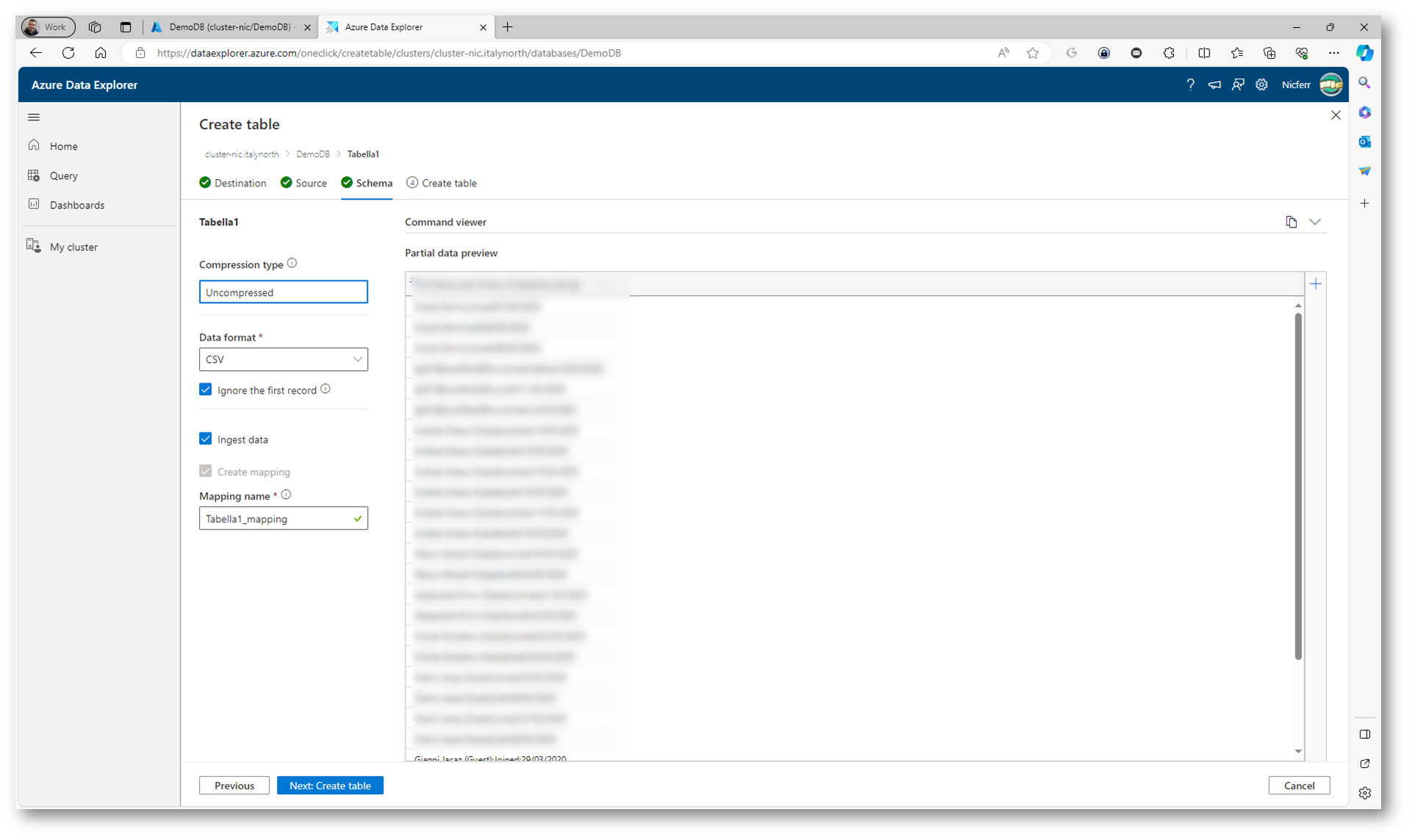
Figura 25: Lo schema del file e il formato sono stati riconosciuti automaticamente
Fate clic su Create Table per proseguire nella creazione della tabella e nell’ingestione dei dati. Dopo qualche secondo, il processo sarà completato. Potete fare clic su Close per tornare ad Azure Data Explorer.
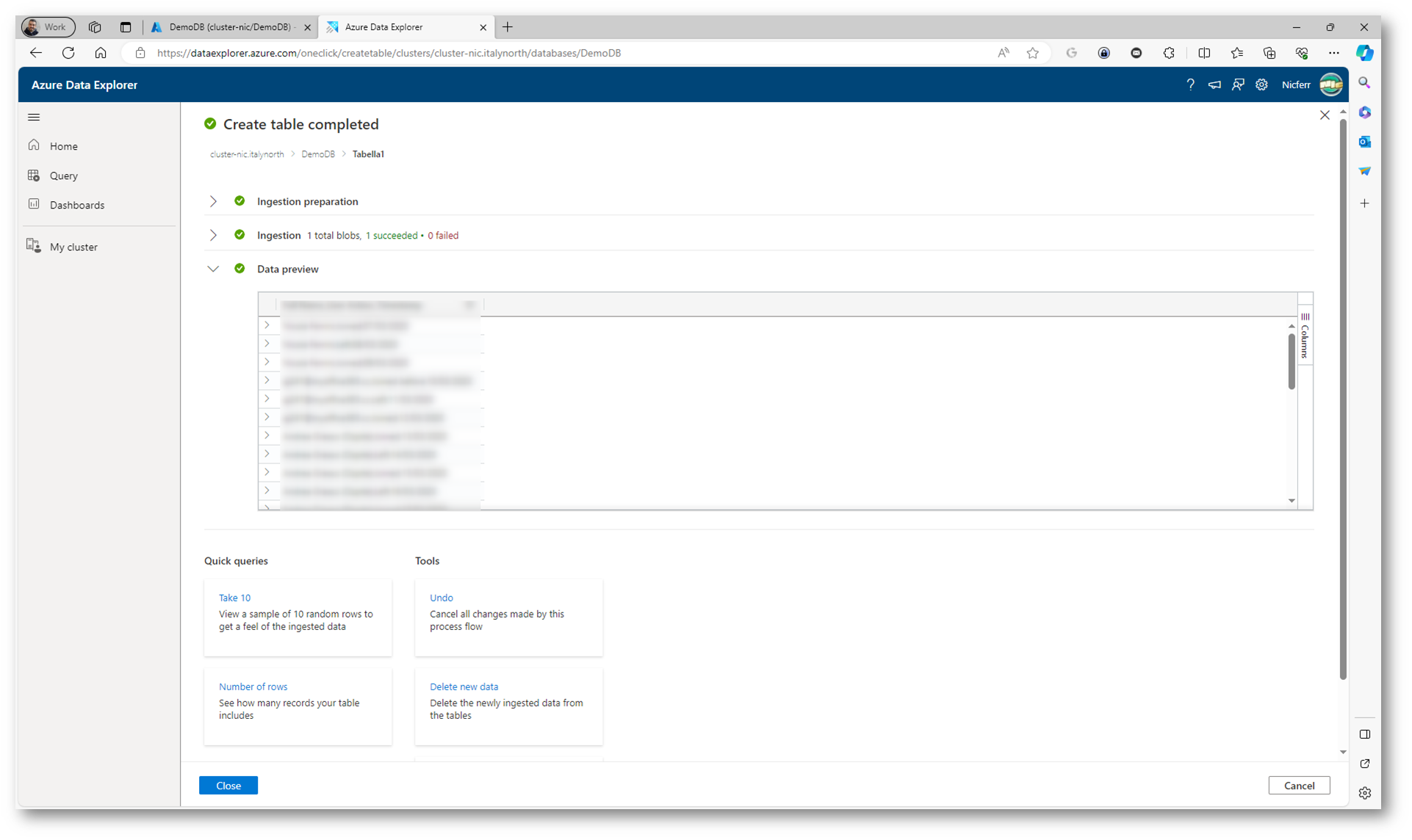
Figura 26: Creazione della tabelle e ingestione dei dati completata
Le operazioni di query possono poi essere fatte direttamente dal portale di Azure Data Explorer o dal portale di Microsoft Azure. Nelle due figure sotto sono mostrate le schermate da cui è possibile eseguire le query.
Figura 27: Esecuzione delle query dal portale di Azure Data Explorer
Figura 28: Esecuzione delle query dal portale di Microsoft Azure
È ovviamente possibile anche aggiungere dati provenienti da fonti diverse. Nella figura sotto sono mostrati alcuni connettori disponibili.
Le Data Connections (Connessioni di Dati) sono configurazioni che permettono il trasferimento automatico e continuo di dati da varie fonti esterne verso un database in Azure Data Explorer. Queste connessioni sono fondamentali per automatizzare il processo di ingestione dei dati, essenziale per applicazioni che richiedono l’analisi di flussi di dati in tempo reale o l’aggiornamento regolare dei dati.
Le Data Connections in ADX possono essere configurate per collegare una varietà di fonti di dati, come:
- Cosmos DB: Permette di trasferire dati da Cosmos DB, un servizio di database multi-modello e distribuito globalmente.
- Event Grid (Blob Storage): Per l’ingestione di grandi volumi di dati statici o archiviati, come file di log o dati storici.
- Event Hub: Per ottenere flussi di dati in tempo reale, come log di eventi o dati di telemetria.
- IoT Hub: Per raccogliere dati da dispositivi IoT.
Il vantaggio di utilizzare le Data Connections in ADX è che semplificano significativamente il processo di ingestione dei dati. Invece di dover manualmente caricare i dati nel database, gli utenti possono impostare una connessione di dati che automaticamente e continuamente trasferisce i dati dalla fonte a ADX. Questo permette di avere dati sempre aggiornati nel database, pronti per essere analizzati.
Inoltre, queste connessioni supportano varie opzioni di configurazione, come la definizione di schemi di dati, il filtraggio dei dati in ingresso e l’ottimizzazione delle prestazioni di ingestione, rendendo il processo di ingestione dei dati sia flessibile che efficiente.
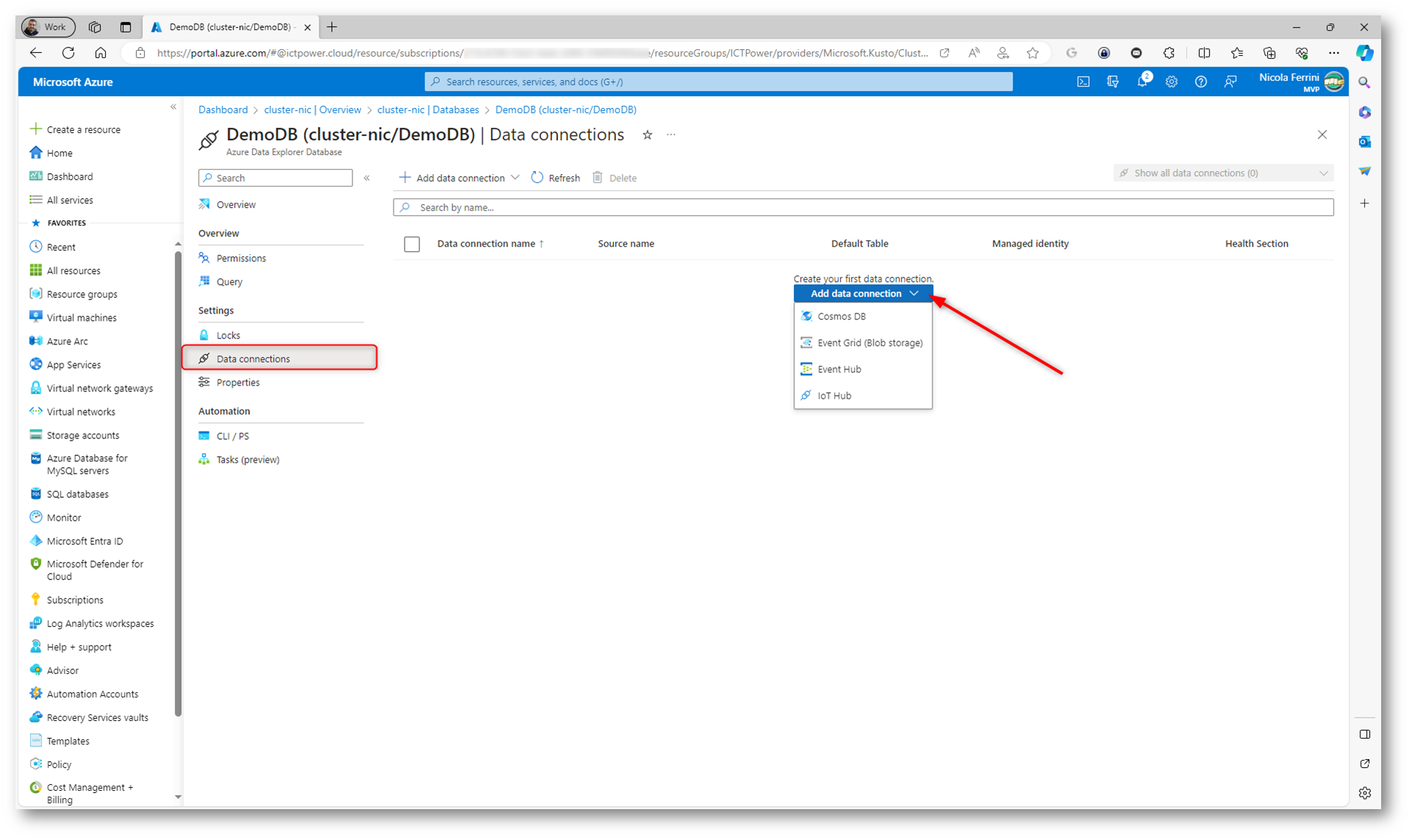
Figura 29: Data Connections
Azure Data Explorer è uno strumento potente per l’analisi di dati in tempo reale e per l’esplorazione di grandi quantità di dati. È particolarmente utile in scenari dove la velocità e la scalabilità dell’analisi dei dati sono fondamentali, come il monitoraggio di applicazioni, l’analisi di log, e l’analisi di sensori IoT. Con la sua integrazione con altri servizi Azure, offre una soluzione completa per molte esigenze di analisi dati.
Kusto Detective Agency – Imparare ad utilizzare KQL giocando
Se volete esercitarvi con il Kusto Query Language vi suggerisco di dare un’occhiata alla Kusto Detective Agency. La Kusto Detective Agency è una serie di sfide che aiutano a imparare il linguaggio di query Kusto (KQL), utilizzato da diversi servizi Azure, tra cui Azure Monitor, Sentinel, M365 Defender e Azure Data Explorer (ADX). È un’esperienza coinvolgente e divertente per chi vuole imparare KQL in modo interattivo. Potete accedere alla Kusto Detective Agency visitando il sito ufficiale Kusto Detective Agency
Figura 30: Kusto Detective Agency
Conclusioni
Azure Data Explorer emerge come una soluzione eccellente per le aziende che necessitano di analizzare e interpretare grandi volumi di dati in tempo reale. Offre una combinazione unica di velocità, potenza, e flessibilità, rendendolo uno strumento indispensabile per chiunque cerchi di trasformare i dati in decisioni informate e azioni strategiche. La sua capacità di integrarsi con altri strumenti e servizi Azure lo rende ancora più potente, garantendo che si adatti e cresca insieme alle esigenze dell’organizzazione.