
Introduzione a Cluster-Aware Updating (CAU) in Windows Server
La gestione degli aggiornamenti in ambienti Windows Server Failover Cluster è da sempre una delle attività più delicate per chi amministra infrastrutture critiche. Patch di sicurezza, aggiornamenti cumulativi e driver sono indispensabili per mantenere i sistemi protetti e supportati, ma applicarli senza impattare sulla disponibilità dei servizi richiede pianificazione, competenze e finestre di manutenzione complesse da gestire.
Cluster-Aware Updating (CAU) nasce proprio per rispondere a questa esigenza: automatizzare il processo di aggiornamento dei nodi di un cluster senza interrompere i carichi di lavoro, sfruttando le funzionalità native di failover e migrazione dei ruoli.
Introdotta a partire da Windows Server 2012 e costantemente migliorata nelle versioni successive, CAU consente di:
- Applicare aggiornamenti Microsoft in modo sequenziale e orchestrato
- Spostare automaticamente i ruoli clusterizzati tra i nodi
- Ridurre al minimo (o azzerare) il downtime percepito dagli utenti
- Standardizzare e rendere ripetibile il processo di patching
Cluster-Aware Updating è particolarmente indicato per scenari come:
- Hyper-V Failover Cluster
- Scale-Out File Server
- Cluster utilizzati per workload mission-critical
In questa guida vedremo cos’è CAU, come funziona a livello architetturale e come configurarlo correttamente, evidenziando prerequisiti, modalità operative e best practice per utilizzarlo in ambienti di produzione.
Configurazione di Cluster-Aware Updating
Per iniziare la configurazione di Cluster-Aware Updating, operate direttamente dalla console Failover Cluster Manager.
Una volta selezionato il cluster, fate clic con il tasto destro sul nome del cluster nel riquadro di sinistra e accedete al percorso More Actions → Cluster-Aware Updating
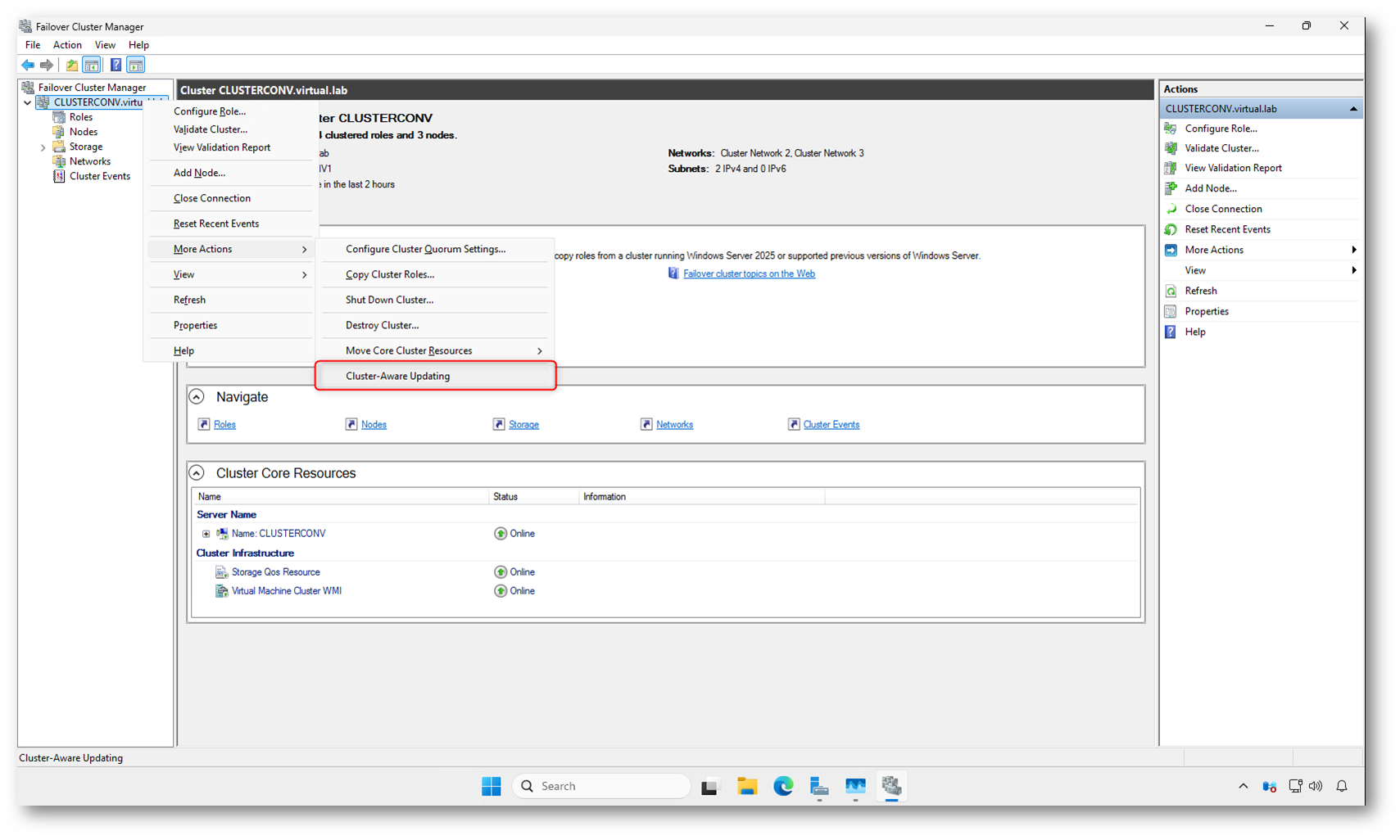
Figura 1: Accesso alla funzionalità Cluster-Aware Updating dal Failover Cluster Manager
Dalla console di Cluster-Aware Updating, come indicato nella documentazione Microsoft, il primo passaggio consigliato è l’esecuzione dell’analisi di readiness del cluster. Selezionate Analyze cluster updating readiness dal riquadro Cluster Actions per verificare che tutti i prerequisiti siano soddisfatti.
Il controllo analizza la configurazione dei nodi, la gestione remota tramite WMI e PowerShell, la versione di Windows Server, lo stato del servizio Cluster e le impostazioni di aggiornamento. Al termine viene mostrato un report con l’esito dei singoli test, evidenziando eventuali Error o Warning che devono essere valutati prima di procedere.
Nel caso mostrato, l’errore principale riguarda l’assenza di una regola firewall che consenta il remote shutdown dei nodi, requisito necessario affinché CAU possa riavviare correttamente i server durante l’Updating Run. Microsoft raccomanda di risolvere tutti gli errori bloccanti prima di applicare gli aggiornamenti.
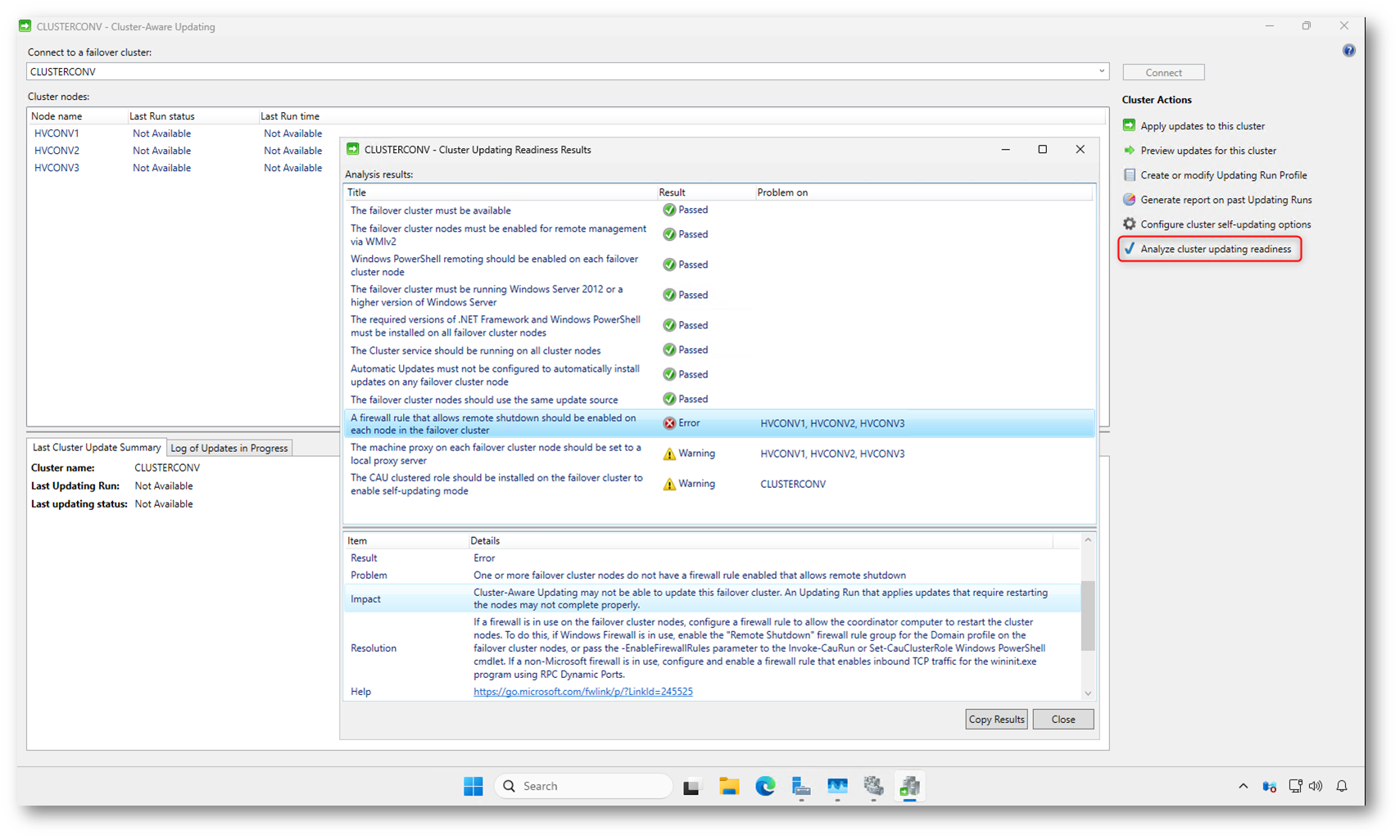
Figura 2: Verifica dei prerequisiti del cluster tramite “Analyze cluster updating readiness”
La schermata Getting Started introduce la modalità self-updating e chiarisce cosa cambia rispetto all’uso manuale di Cluster-Aware Updating. Proseguendo con questo wizard state dicendo al cluster che gli aggiornamenti non verranno più lanciati a mano, ma eseguiti automaticamente in base alla pianificazione che andrete a definire.
Un punto importante evidenziato qui riguarda il firewall. Se sui nodi è in uso Windows Firewall, il wizard è in grado di configurare automaticamente le regole necessarie per consentire i riavvii remoti durante l’Updating Run. Questo è fondamentale perché, senza queste regole, CAU non sarebbe in grado di riavviare correttamente i nodi dopo l’installazione degli aggiornamenti.
In pratica, da questo momento in poi il cluster diventa autonomo nella gestione del patching: sposta i ruoli, aggiorna i nodi uno alla volta, li riavvia e riporta i carichi di lavoro online senza richiedere interventi manuali.
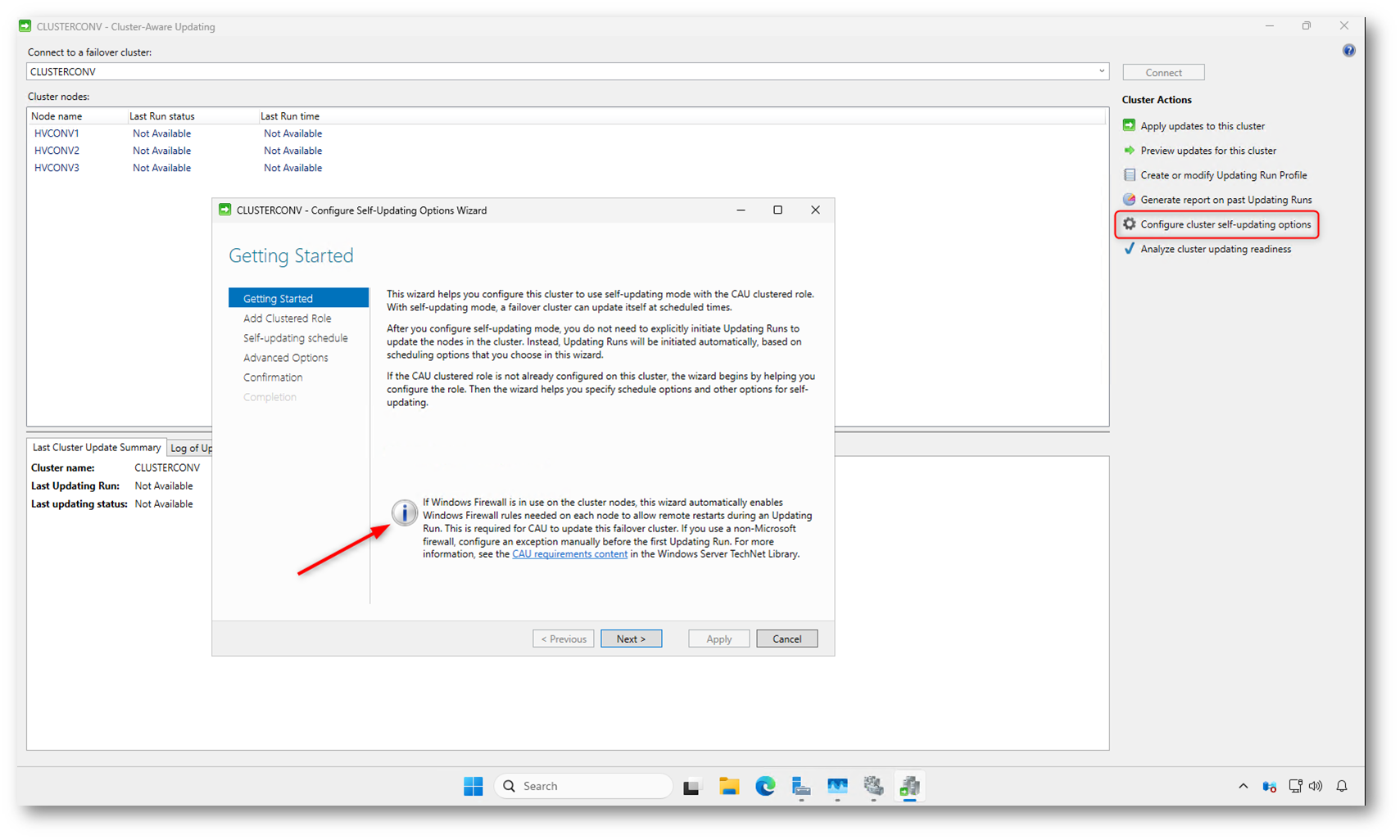
Figura 3: Schermata iniziale del wizard di configurazione della modalità self-updating
Nella schermata Add CAU Clustered Role with Self-Updating Enabled abilitate la creazione del ruolo clusterizzato di Cluster-Aware Updating, necessario per eseguire gli aggiornamenti in modalità automatica. Confermando questa opzione, il cluster crea un nuovo ruolo interno che verrà utilizzato come coordinatore degli Updating Run.
Dal punto di vista di Active Directory, se non utilizzate un computer object prestaged, il cluster provvede automaticamente a creare un Computer Object dedicato al ruolo CAU all’interno dell’OU predefinita dei computer. Questo oggetto viene usato per autenticarsi e per eseguire le operazioni necessarie sui nodi durante il processo di aggiornamento, inclusi i riavvii.
In ambienti con policy restrittive, dove la creazione automatica di oggetti computer non è consentita, è necessario predisporre manualmente l’oggetto in AD e selezionare l’opzione I have a prestaged computer object for the CAU clustered role. In tutti gli altri casi potete lasciare la configurazione di default e proseguire senza interventi manuali.
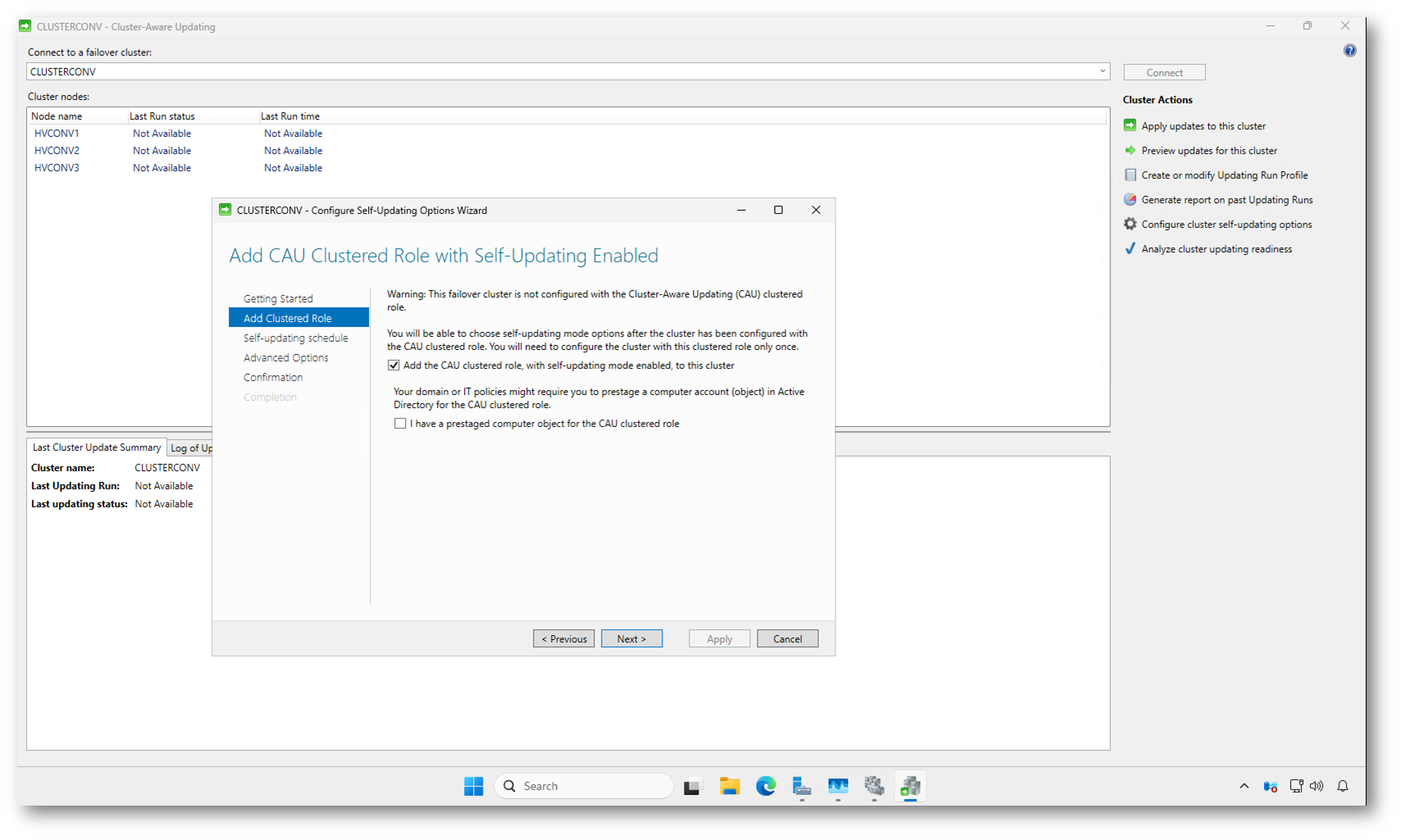
Figura 4: Creazione del ruolo clusterizzato di Cluster-Aware Updating e del relativo computer object in Active Directory
Nella schermata Specify self-updating schedule impostate quando il cluster deve eseguire gli aggiornamenti in automatico. Scegliete la frequenza e l’orario più adatti alla vostra finestra di manutenzione, così da ridurre al minimo l’impatto sui servizi.
In questo esempio viene configurata una pianificazione mensile, con avvio notturno, una scelta comune in ambienti di produzione dove gli aggiornamenti vengono concentrati in momenti ben definiti.
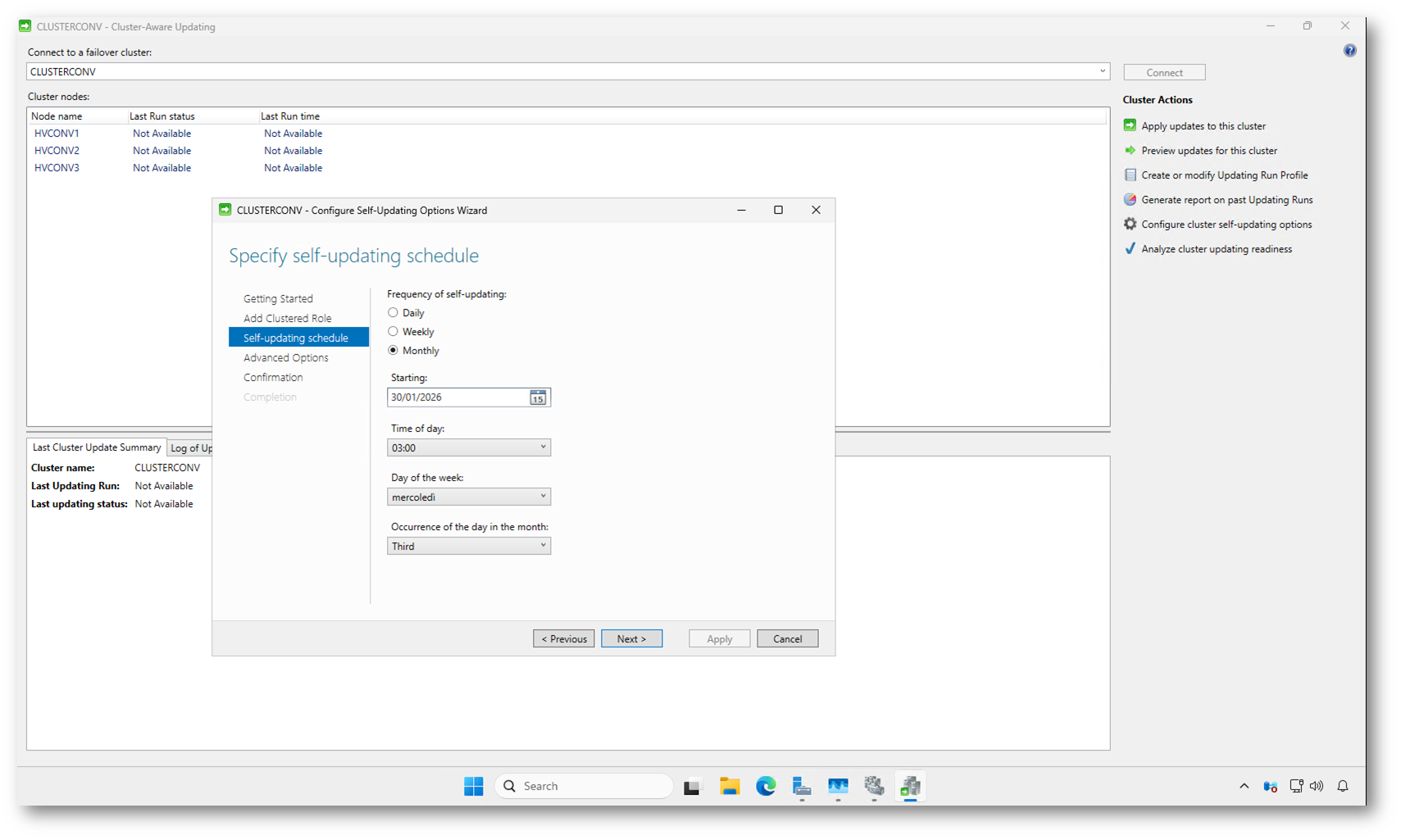
Figura 5: Definizione della pianificazione automatica degli aggiornamenti nella schermata “Specify self-updating schedule”
Nella schermata Advanced Options potete controllare nel dettaglio il comportamento dell’Updating Run. Di default viene utilizzato il file defaultparameters.xml, che nella maggior parte degli scenari è più che sufficiente e non richiede modifiche.
In ambienti di produzione è comunque consigliabile intervenire su alcuni parametri chiave per rendere il processo più prevedibile. Un’impostazione tipica prevede, ad esempio, di limitare il numero di tentativi per nodo impostando MaxRetriesPerNode a 2 o 3, così da evitare loop prolungati in caso di problemi durante l’installazione degli aggiornamenti.
Se volete assicurarvi che il cluster interrompa l’Updating Run in presenza di condizioni anomale, potete valorizzare StopAfter o WarnAfter, definendo dopo quanti nodi o minuti il processo deve fermarsi o generare un avviso. In cluster con carichi critici può avere senso anche abilitare RequireAllNodesOnline, per evitare che l’aggiornamento parta se non tutti i nodi sono disponibili.
Questa sezione è inoltre il punto giusto per integrare script personalizzati tramite PreUpdateScript e PostUpdateScript, ad esempio per mettere in maintenance applicazioni, disabilitare job schedulati o inviare notifiche prima e dopo l’aggiornamento.
Se non avete esigenze particolari, potete lasciare tutte le opzioni ai valori di default e proseguire: CAU funziona correttamente anche senza personalizzazioni.
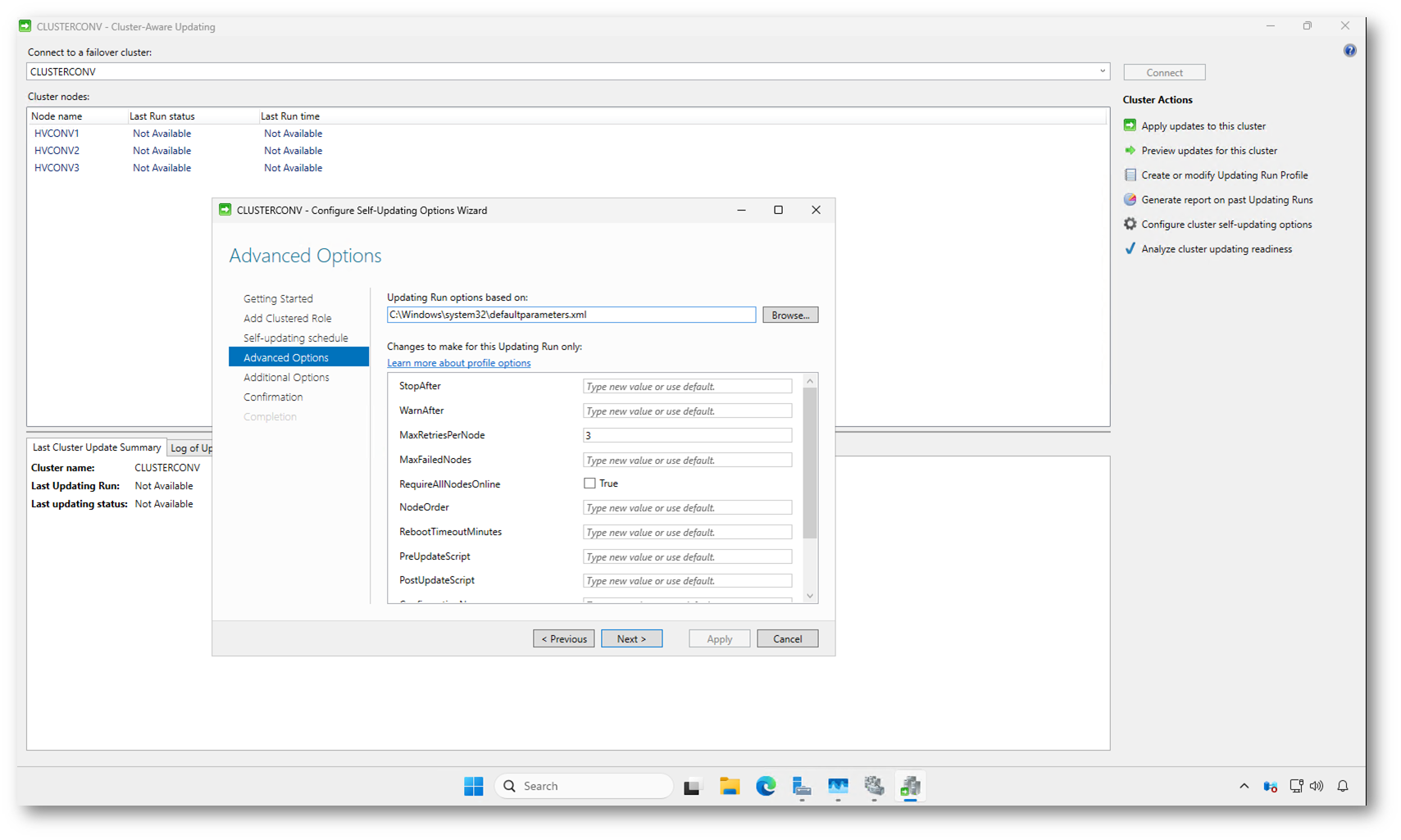
Figura 6: Configurazione avanzata del comportamento dell’Updating Run nella schermata “Advanced Options”
Nella schermata Additional Update Options decidete se includere anche gli aggiornamenti Recommended oltre a quelli classificati come Important. Abilitando l’opzione Give me recommended updates the same way that I receive important updates, il cluster installerà anche aggiornamenti non critici, come miglioramenti di affidabilità o compatibilità.
In ambienti di produzione è comune lasciare questa opzione disabilitata, limitando l’installazione agli aggiornamenti realmente necessari. Può invece avere senso abilitarla in ambienti di test o in cluster meno critici, dove si vuole mantenere il sistema il più possibile allineato.
Questa impostazione influisce direttamente su quali aggiornamenti verranno presi in carico durante gli Updating Run automatici.
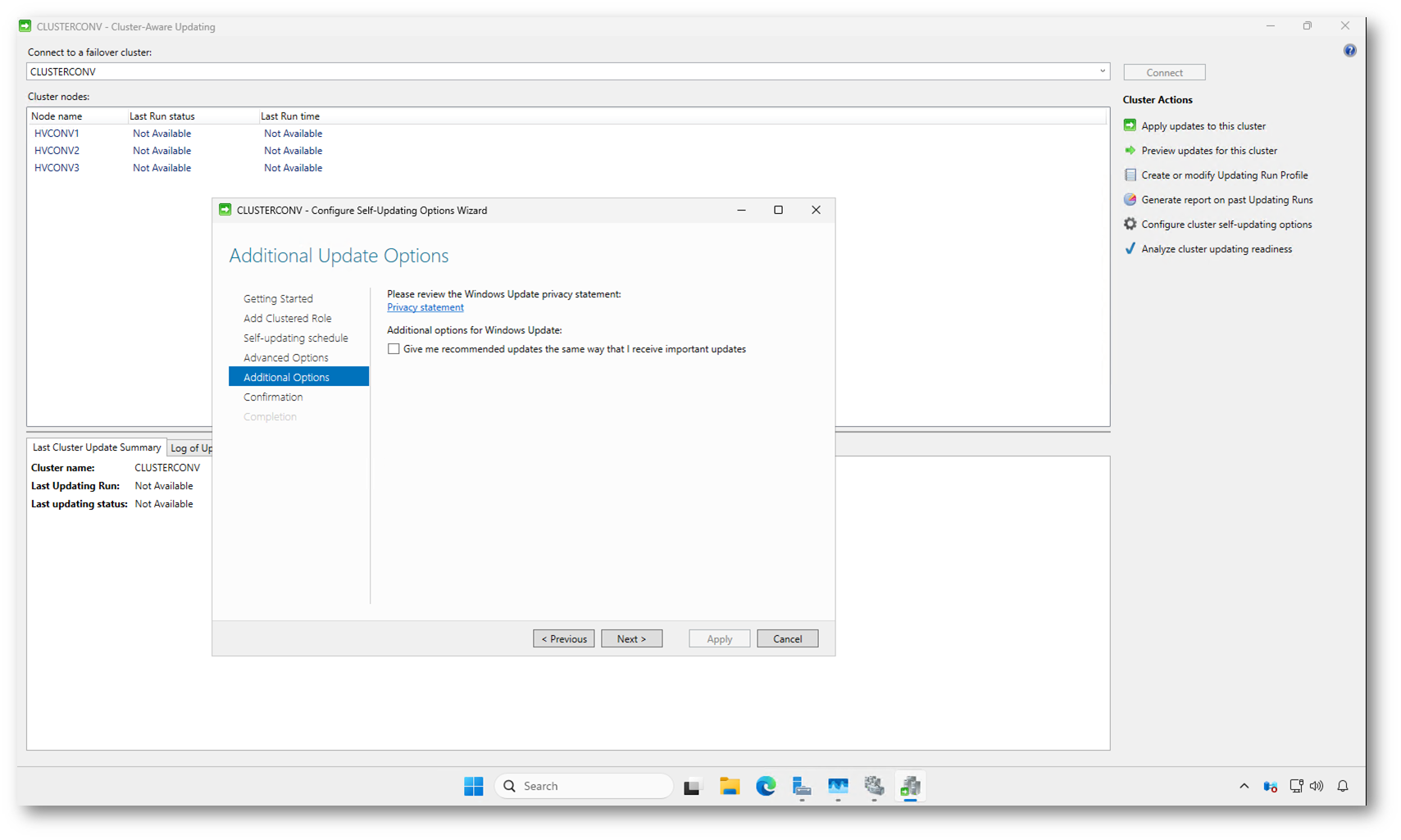
Figura 7: Scelta del tipo di aggiornamenti da includere durante gli Updating Run automatici
Nella schermata Confirmation viene mostrato il riepilogo completo della configurazione che state per applicare. Qui potete verificare rapidamente il nome del cluster, l’abilitazione della modalità self-updating, la pianificazione scelta e i parametri avanzati dell’Updating Run.
Se tutto è corretto, fate clic su Apply per rendere effettive le impostazioni. A questo punto il cluster crea il ruolo clusterizzato di CAU, applica la pianificazione e salva i parametri di esecuzione. Non viene avviato alcun aggiornamento immediato: gli Updating Run partiranno automaticamente secondo la schedule configurata.
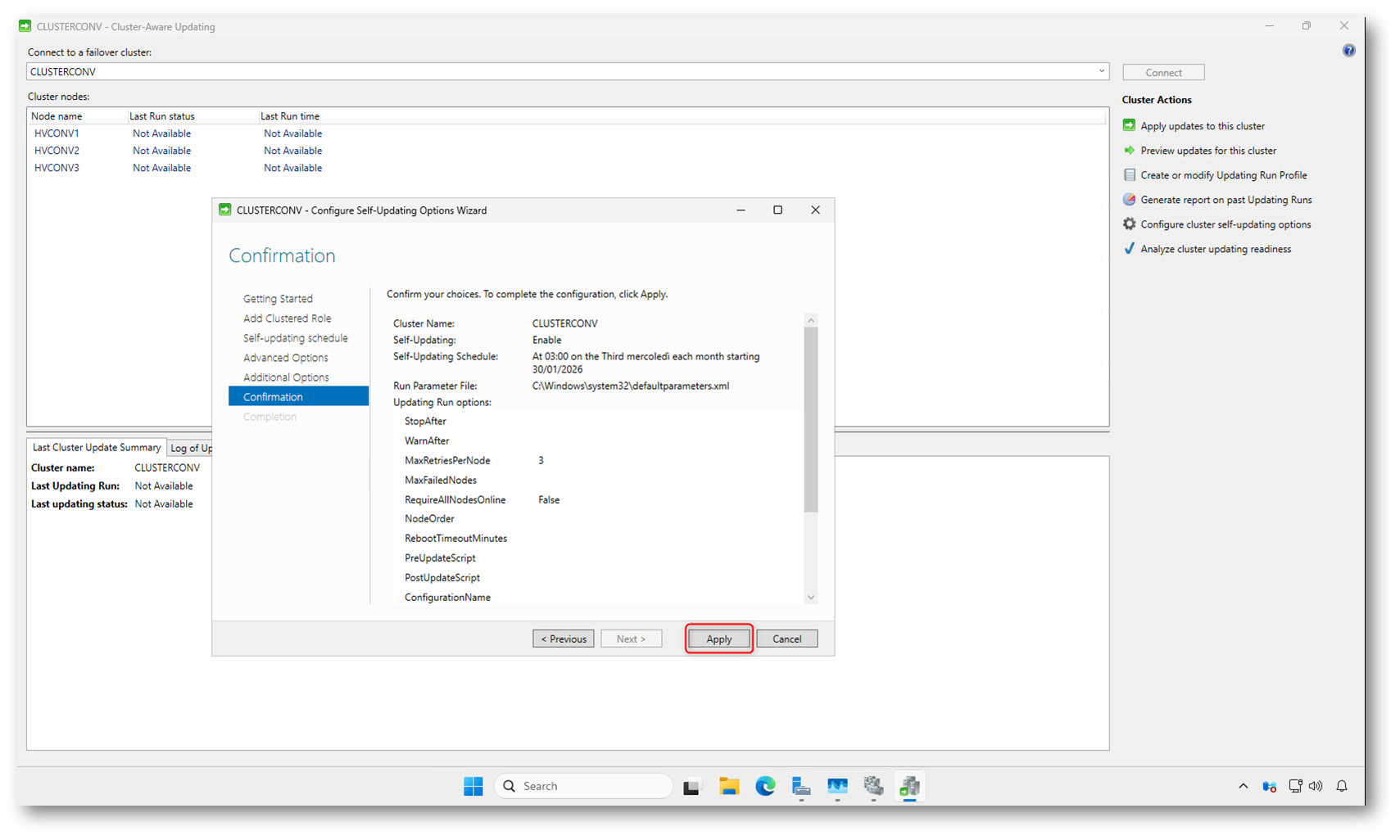
Figura 8: Riepilogo finale della configurazione di Cluster-Aware Updating e applicazione delle impostazioni
Nella schermata Completion il wizard conferma che la configurazione è stata completata con successo. Il ruolo clusterizzato di Cluster-Aware Updating è stato creato e la modalità self-updating è ora attiva sul cluster.
Da questo momento il cluster è pronto a gestire gli aggiornamenti in autonomia, seguendo la pianificazione e le opzioni che avete configurato. Non viene eseguita alcuna azione immediata: il primo Updating Run partirà alla data e all’ora previste dalla schedule.
Chiudendo il wizard potete tornare alla console di Cluster-Aware Updating, dove vedrete il nuovo ruolo attivo e, in futuro, lo storico delle esecuzioni automatiche.
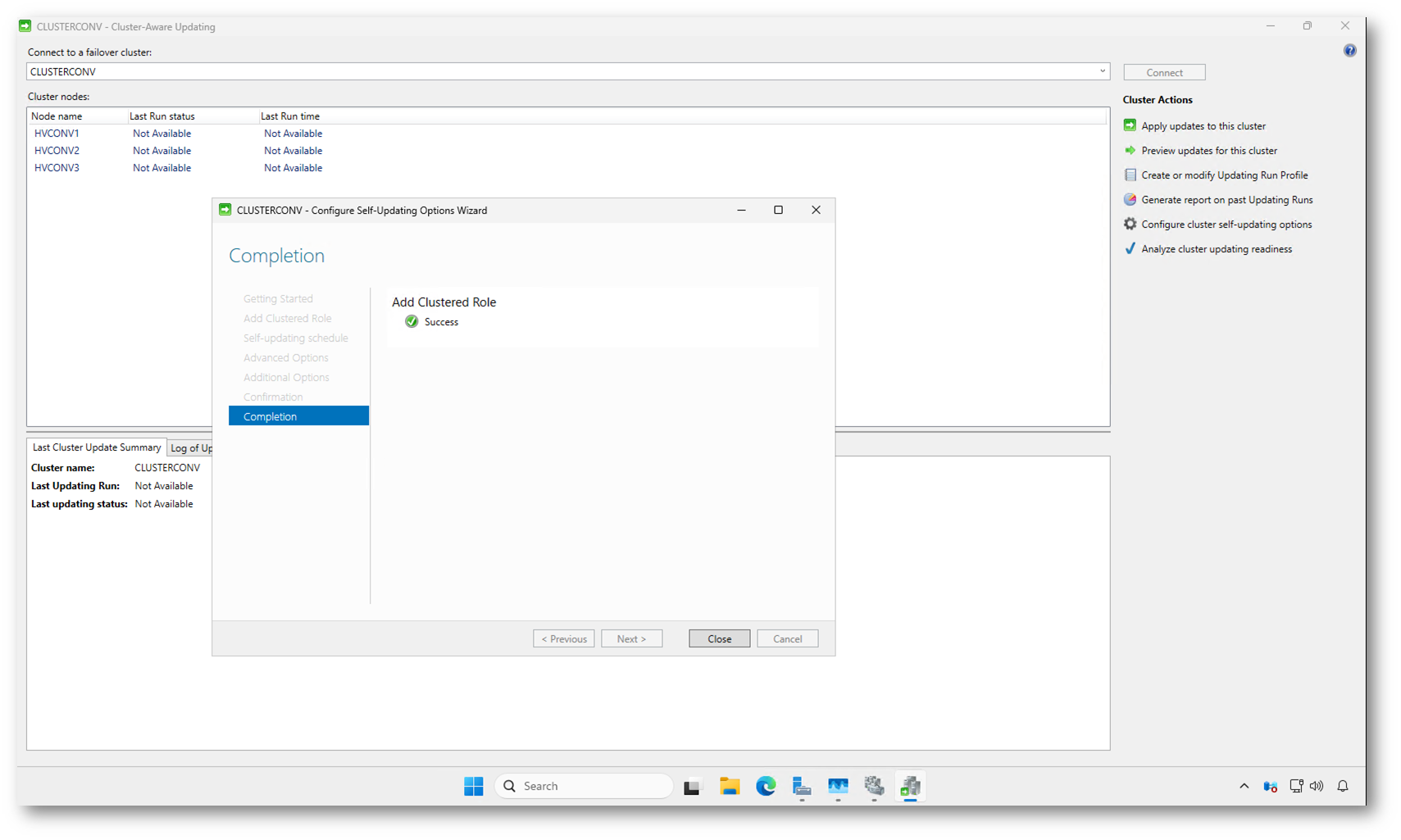
Figura 9: Completamento della configurazione della modalità self-updating di Cluster-Aware Updating
Dopo il completamento del wizard, in Active Directory Users and Computers compare un nuovo Computer Object associato a Cluster-Aware Updating. Nell’esempio è visibile l’oggetto CAUCLUST3$, creato automaticamente perché non è stato utilizzato un computer object prestaged.
Questo oggetto rappresenta il nome di rete del ruolo CAU clusterizzato e viene usato dal cluster per autenticarsi e coordinare le operazioni di aggiornamento sui nodi. Non è un server reale e non deve essere associato a servizi applicativi: serve esclusivamente come identità per CAU.
Dal punto di vista operativo:
- l’oggetto viene creato nell’OU di default dei computer
- i permessi necessari vengono gestiti automaticamente dal cluster
- non è necessario modificarlo o spostarlo, a meno di policy aziendali specifiche
La presenza di questo computer account conferma che la configurazione della modalità self-updating è andata a buon fine anche lato Active Directory.
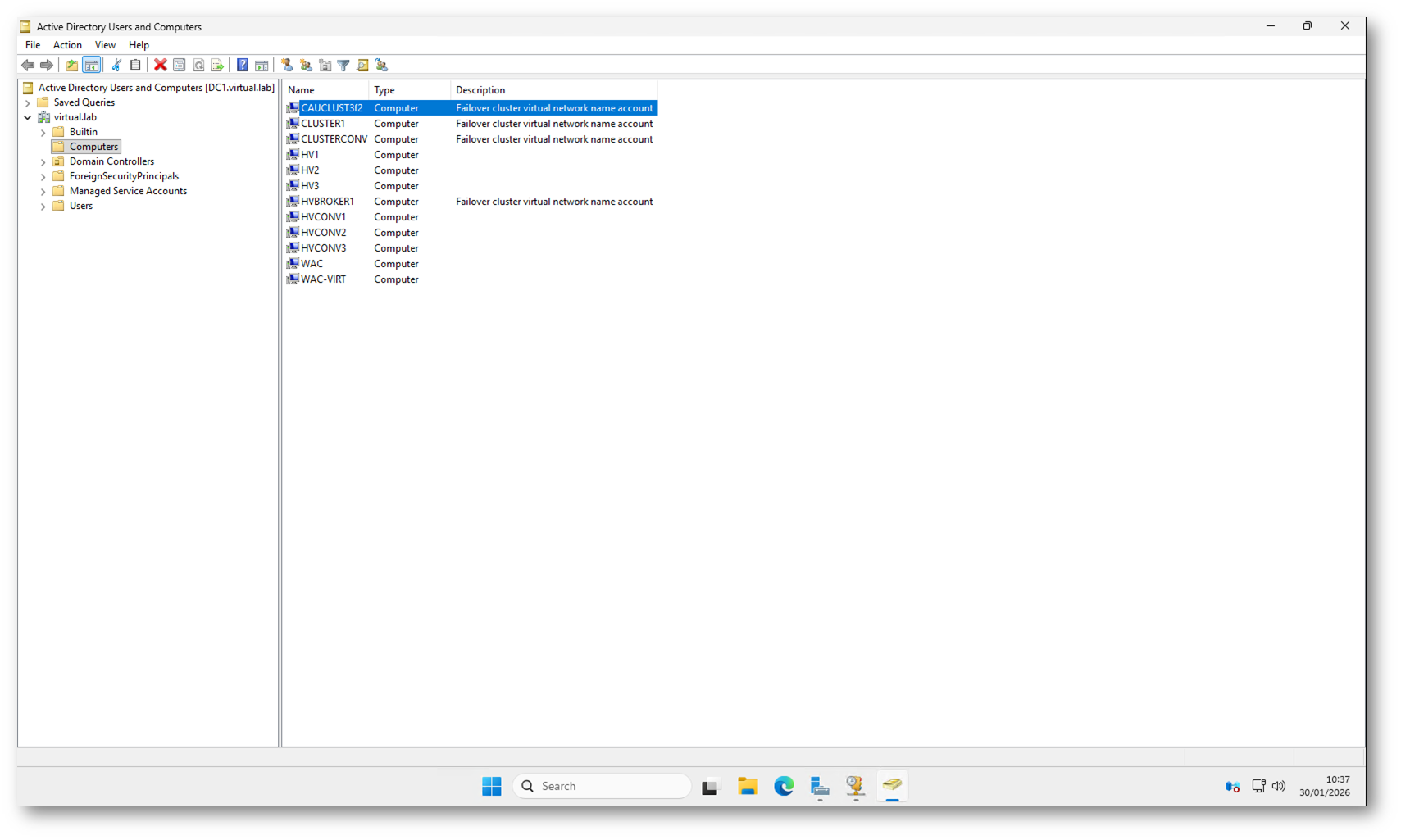
Figura 10: Computer Object del ruolo Cluster-Aware Updating creato automaticamente in Active Directory
Preview updates
Selezionando Preview updates for this cluster potete verificare in anticipo quali aggiornamenti verrebbero applicati ai nodi se partisse un Updating Run in quel momento. È un passaggio utile per capire cosa CAU sta per installare, senza avviare alcuna operazione reale sul cluster.
Nella finestra Preview Updates scegliete il plug-in da utilizzare. Nella maggior parte degli scenari si usa Microsoft.WindowsUpdatePlugin, che interroga la stessa sorgente configurata sui nodi (Windows Update, WSUS o Microsoft Update). Avviando la generazione della preview, CAU raccoglie l’elenco degli aggiornamenti applicabili a ciascun nodo.
Il risultato è solo indicativo: la lista può cambiare nel tempo e non include eventuali aggiornamenti che diventerebbero applicabili solo dopo l’installazione dei primi. Proprio per questo la preview serve come verifica preventiva, non come fotografia definitiva di ciò che verrà installato.
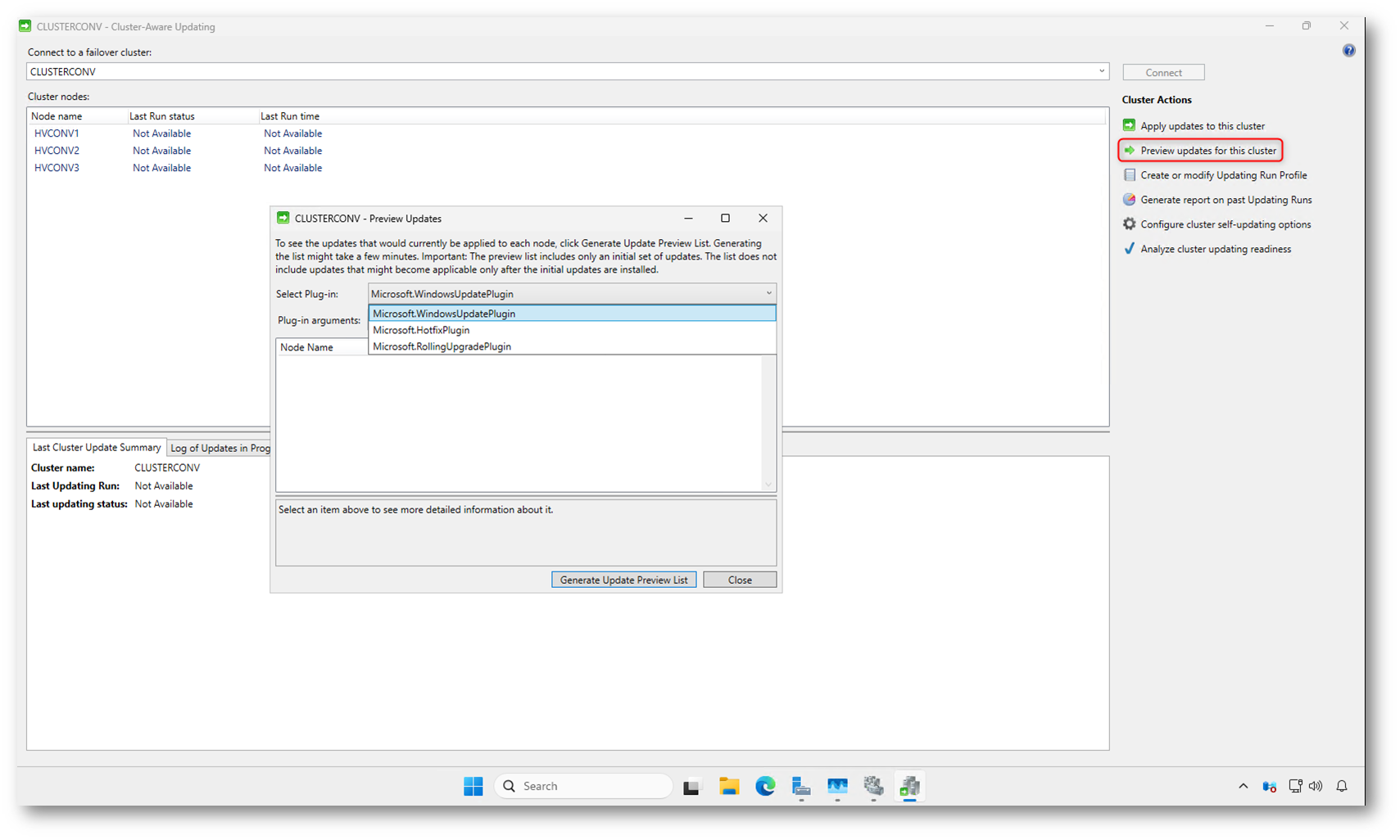
Figura 11: Anteprima degli aggiornamenti applicabili al cluster tramite “Preview updates for this cluster”
Dopo aver generato la preview, nella finestra Preview Updates viene mostrato l’elenco degli aggiornamenti attualmente applicabili a ciascun nodo del cluster. Gli update sono raggruppati per nodo e includono sia aggiornamenti di sicurezza sia componenti come le definizioni di sicurezza e gli strumenti di rimozione malware.
Questa vista vi permette di verificare rapidamente che i nodi vedano lo stesso set di aggiornamenti e che la sorgente di update sia correttamente allineata. Eventuali differenze tra i nodi sono un chiaro segnale di configurazioni non uniformi, ad esempio a livello di WSUS o di stato del sistema.
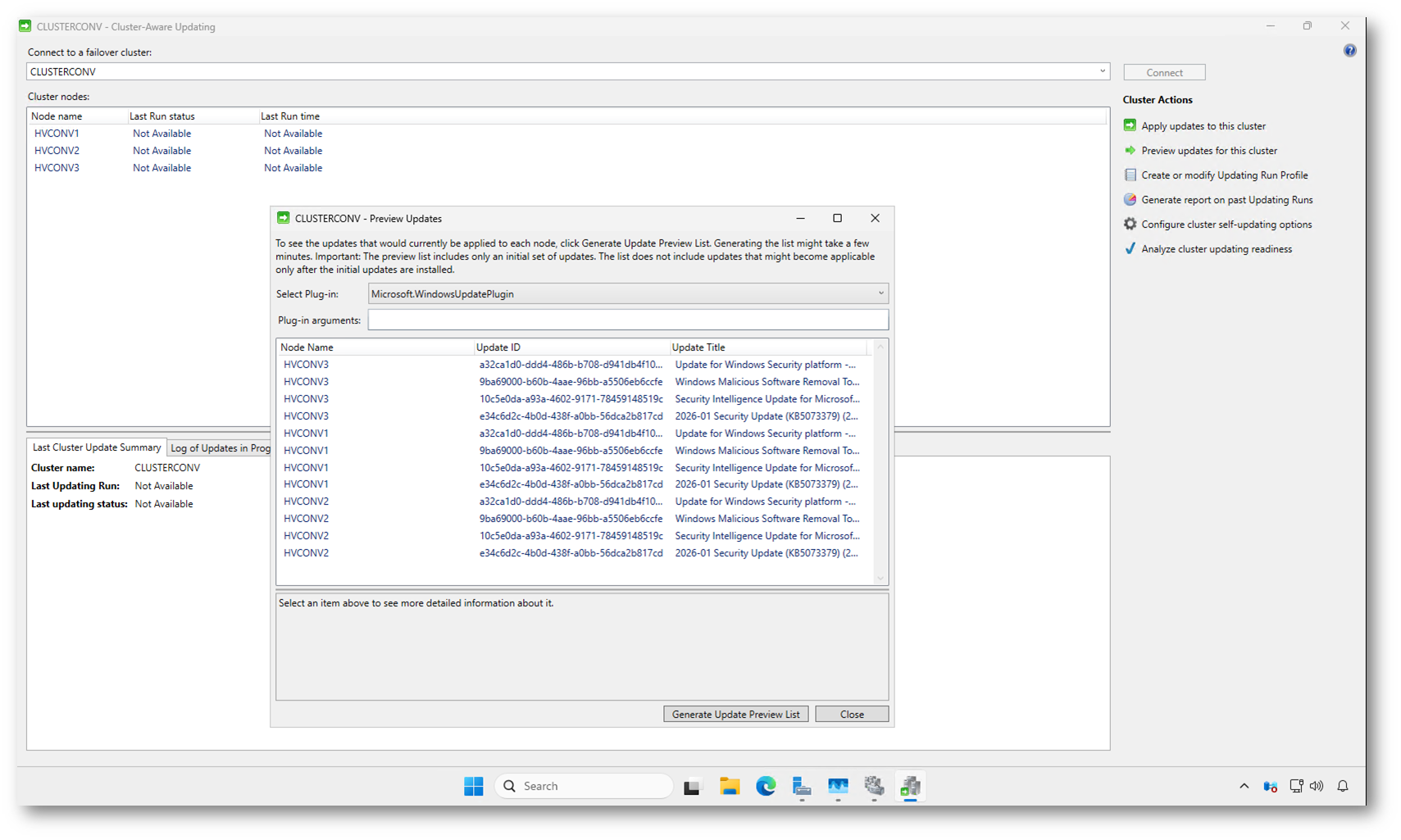
Figura 12: Elenco degli aggiornamenti applicabili ai nodi del cluster nella schermata “Preview Updates”
Applicazione degli aggiornamenti
Selezionando Apply updates to this cluster avviate manualmente un Updating Run immediato, senza attendere la pianificazione configurata per la modalità self-updating. Questa opzione è utile per un primo test o per applicare aggiornamenti urgenti fuori ciclo.
Nella schermata Getting Started del wizard viene chiarito che l’aggiornamento utilizzerà le stesse impostazioni definite per il self-updating. Proseguendo, CAU prende il controllo del cluster e inizia ad aggiornare i nodi uno alla volta: i ruoli vengono spostati, il nodo viene messo in pausa, aggiornato, riavviato se necessario e poi reintegrato nel cluster prima di passare al nodo successivo.
Durante l’esecuzione potete seguire l’avanzamento dalla sezione Log of Updates in Progress, mentre al termine lo storico rimane disponibile nella console per eventuali verifiche.
Figura 13: Avvio manuale di un Updating Run tramite “Apply updates to this cluster”
Nella schermata Confirmation del wizard di aggiornamento manuale viene riepilogata l’operazione che state per avviare. Qui è visibile anche il comando PowerShell che CAU eseguirà internamente, utile per capire cosa succede “dietro le quinte” o per replicare l’operazione via script.
Facendo clic su Update parte immediatamente l’Updating Run.
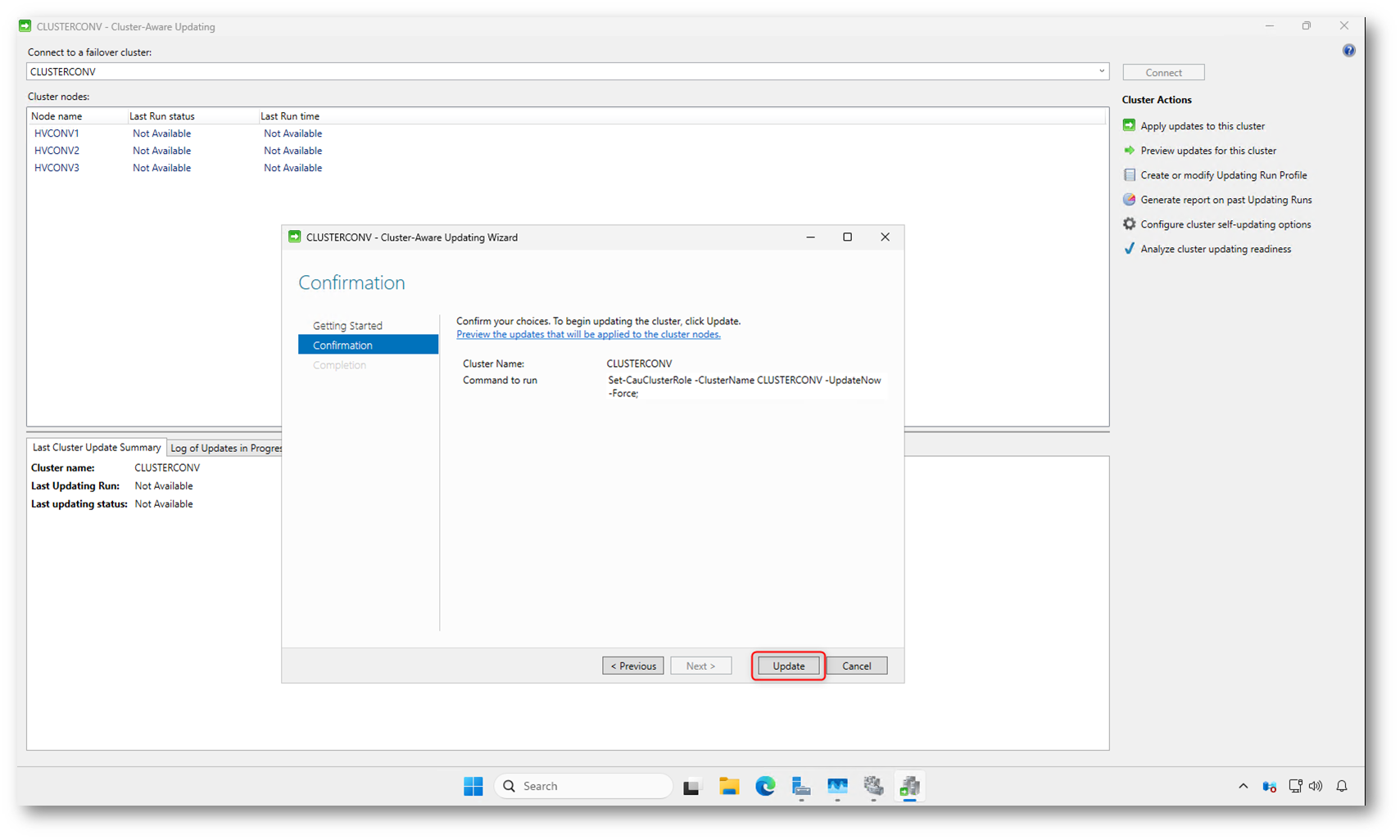
Figura 14: Conferma e avvio di un Updating Run manuale tramite il pulsante “Update”
Nella schermata Completion viene confermato che l’Updating Run è stato avviato correttamente in modalità self-updating e che l’operazione prosegue in background. Da questo momento potete chiudere il wizard senza interrompere il processo.
Nella console principale di Cluster-Aware Updating vedete lo stato dei nodi che passano progressivamente da Waiting alle varie fasi di aggiornamento. CAU lavora su un nodo alla volta: i ruoli vengono spostati, il nodo viene messo in pausa, aggiornato e riavviato se necessario, per poi rientrare nel cluster prima di passare al nodo successivo.
L’avanzamento dettagliato è consultabile nella sezione Log of Updates in Progress, mentre al termine dell’operazione il risultato rimane disponibile nello storico degli Updating Run.
Figura 15: Aggiornamento del cluster avviato in background e monitoraggio dello stato dei nodi
Figura 16: Aggiornamento del cluster avviato
Durante l’esecuzione dell’Updating Run la console di Cluster-Aware Updating mostra in tempo reale lo stato di ciascun nodo. Nella sezione Cluster nodes potete vedere quale nodo è in attesa e quale sta effettivamente eseguendo le operazioni, ad esempio download, installazione o riavvio.
Il nodo che in quel momento coordina l’aggiornamento assume il ruolo di Update Coordinator, informazione visibile anche nel log sottostante. Gli altri nodi restano in stato Waiting finché non arriva il loro turno, evitando aggiornamenti paralleli che potrebbero impattare sulla disponibilità del cluster.
Se necessario, l’Updating Run può essere interrotto tramite l’azione Cancel Updating Run. L’annullamento ferma il processo sul nodo corrente, lasciando invariati quelli non ancora aggiornati.
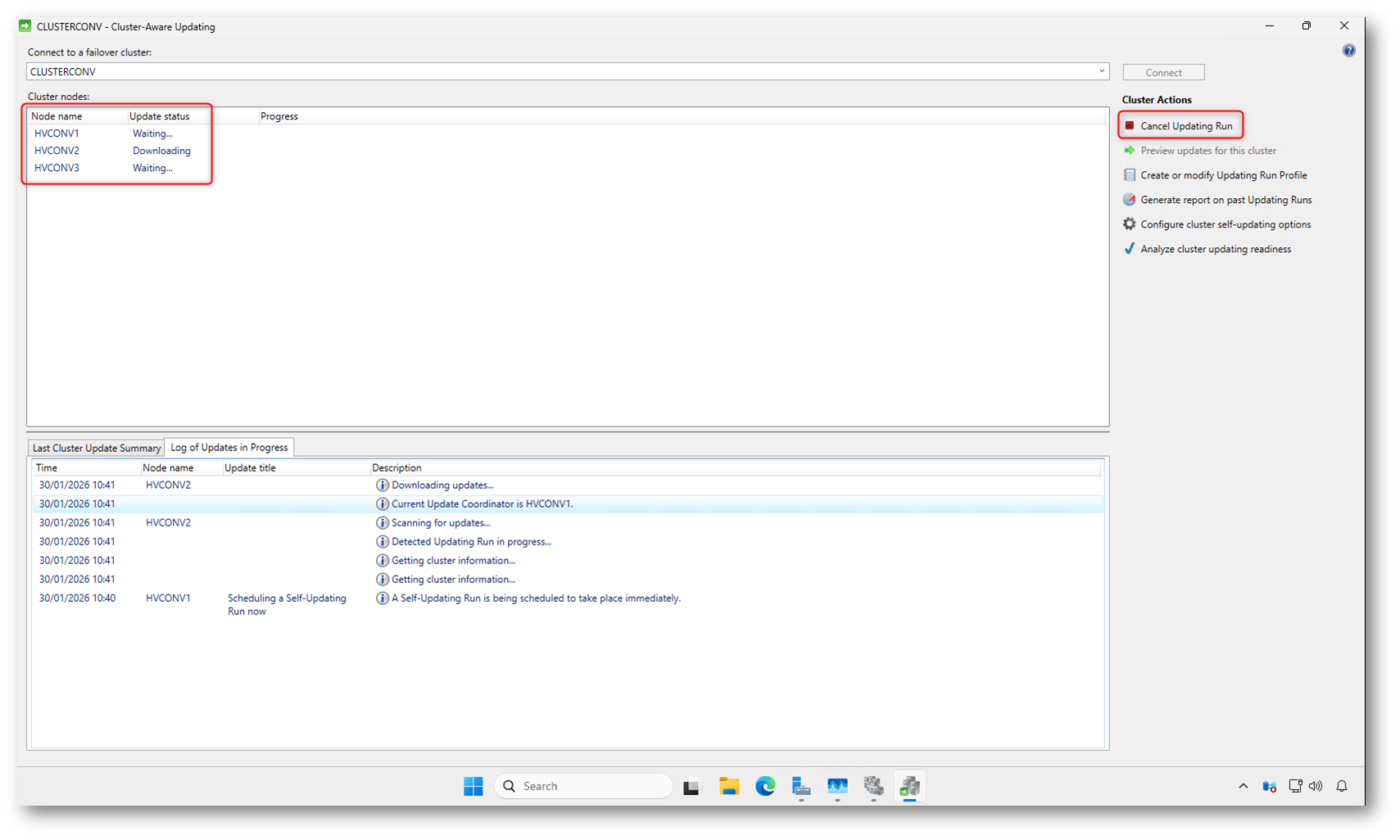
Figura 17: Monitoraggio in tempo reale dello stato dei nodi e del log durante un Updating Run
Durante l’Updating Run, CAU gestisce automaticamente la maintenance mode dei nodi. Quando arriva il turno di un nodo, questo viene messo in manutenzione: i ruoli clusterizzati vengono spostati sugli altri nodi disponibili e il nodo non riceve più nuovi carichi di lavoro.
In questa fase il nodo può scaricare e installare gli aggiornamenti ed essere riavviato senza impattare sui servizi esposti dal cluster. Nel log vedete chiaramente le varie fasi, come Scanning, Downloading e Installing updates, tutte eseguite mentre il nodo è isolato dal punto di vista operativo.
Una volta completato l’aggiornamento, CAU fa uscire il nodo dalla maintenance mode, come indicato dallo stato Leaving maintenance mode. A questo punto il nodo rientra a pieno titolo nel cluster ed è nuovamente disponibile per ospitare ruoli e carichi di lavoro, prima che CAU passi al nodo successivo.
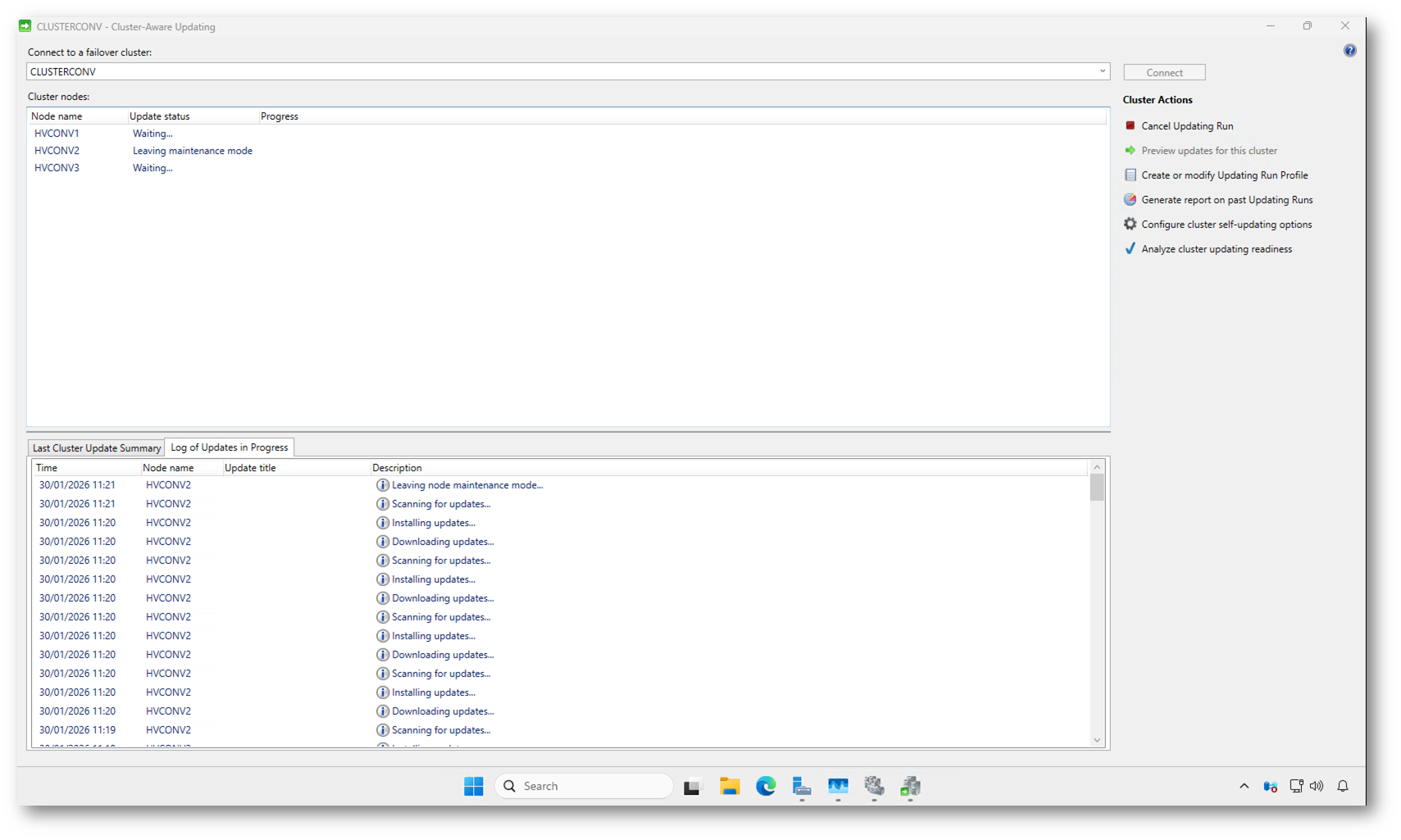
Figura 18: Gestione automatica della maintenance mode dei nodi durante un Updating Run
Ogni nodo viene aggiornato in sequenza. Nella vista Cluster nodes potete vedere chiaramente quando un nodo termina il proprio ciclo e passa allo stato Succeeded, mentre il nodo successivo entra in fase di aggiornamento.
Nel caso mostrato, HVCONV2 ha completato correttamente l’aggiornamento ed è rientrato nel cluster, mentre HVCONV1 sta scaricando gli aggiornamenti e HVCONV3 è ancora in attesa del proprio turno. Questo comportamento garantisce che il cluster mantenga sempre un numero sufficiente di nodi attivi per ospitare i carichi di lavoro.
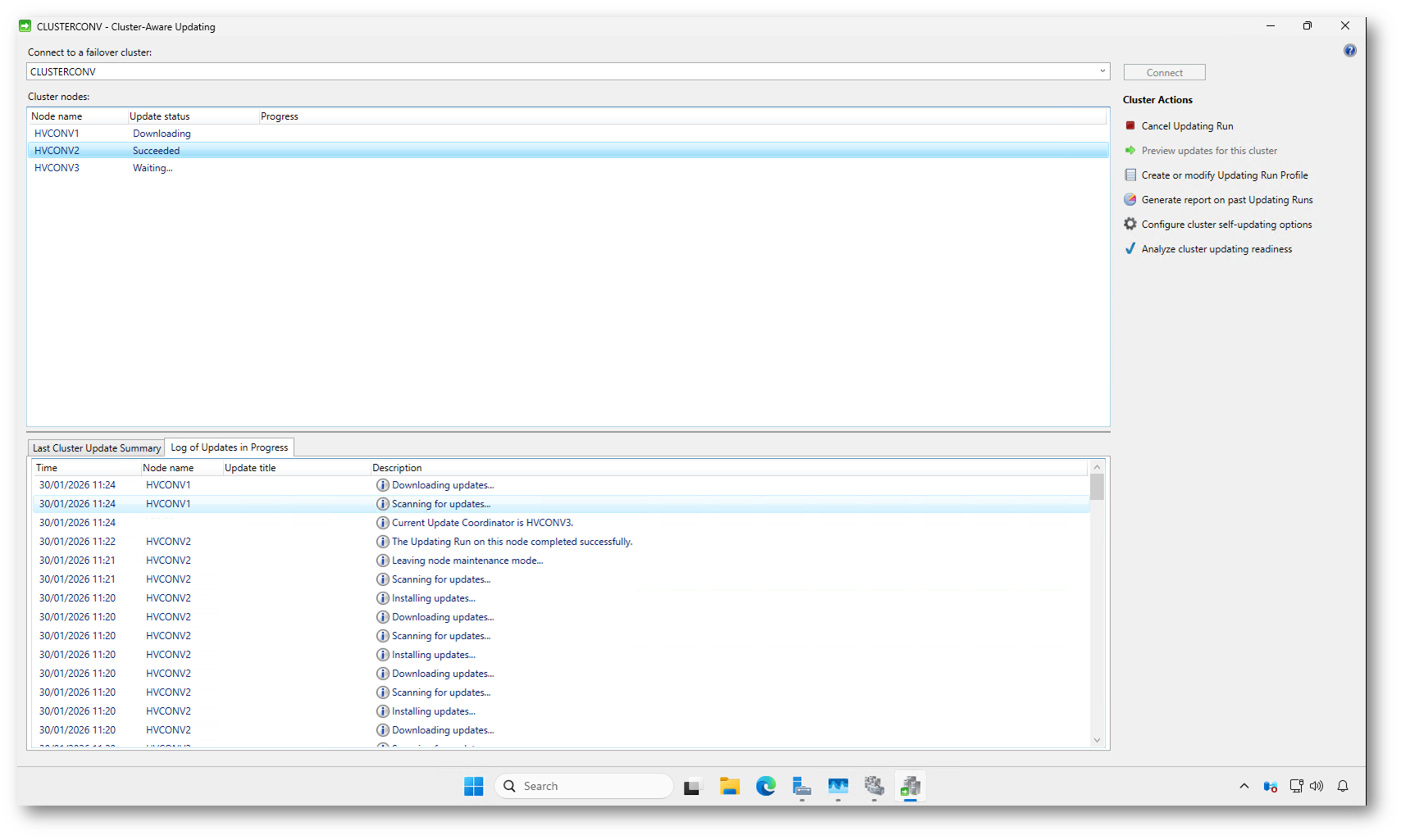
Figura 19: Completamento dell’aggiornamento di un nodo e avanzamento dell’Updating Run sugli altri nodi
Nel Failover Cluster Manager, il nodo che viene aggiornato appare nello stato Paused. Questo è l’effetto visibile della maintenance mode applicata da CAU.
Quando un nodo entra in stato Paused, il cluster non gli assegna nuovi ruoli e i carichi di lavoro vengono spostati sugli altri nodi disponibili. Il nodo resta comunque parte del cluster, ma viene isolato dal punto di vista operativo per consentire l’installazione degli aggiornamenti e gli eventuali riavvii in sicurezza.
Una volta completato l’aggiornamento, CAU rimuove automaticamente la pausa e il nodo torna nello stato Up, rendendolo nuovamente disponibile per ospitare ruoli e risorse clusterizzate. Questo passaggio è completamente automatico e non richiede interventi manuali.
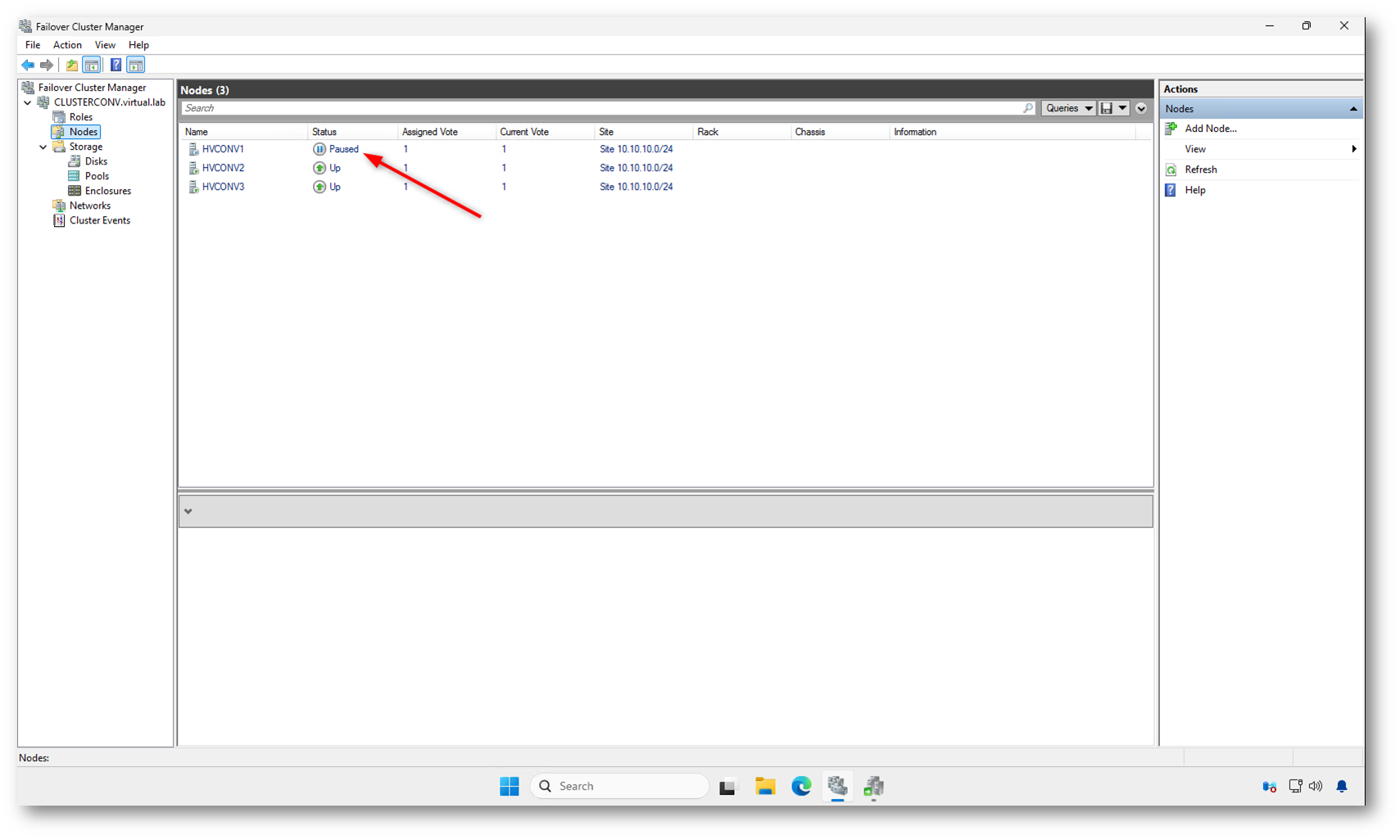
Figura 20: Nodo in stato “Paused” nel Failover Cluster Manager durante la maintenance mode gestita da Cluster-Aware Updating
Al termine dell’Updating Run, tutti i nodi del cluster risultano nello stato Succeeded e il riepilogo indica un’esecuzione completata con successo. Questo conferma che ogni nodo è stato aggiornato, riavviato se necessario e correttamente reintegrato nel cluster.
Da questo momento il cluster è pienamente operativo e pronto per il prossimo ciclo, manuale o pianificato, senza ulteriori interventi.
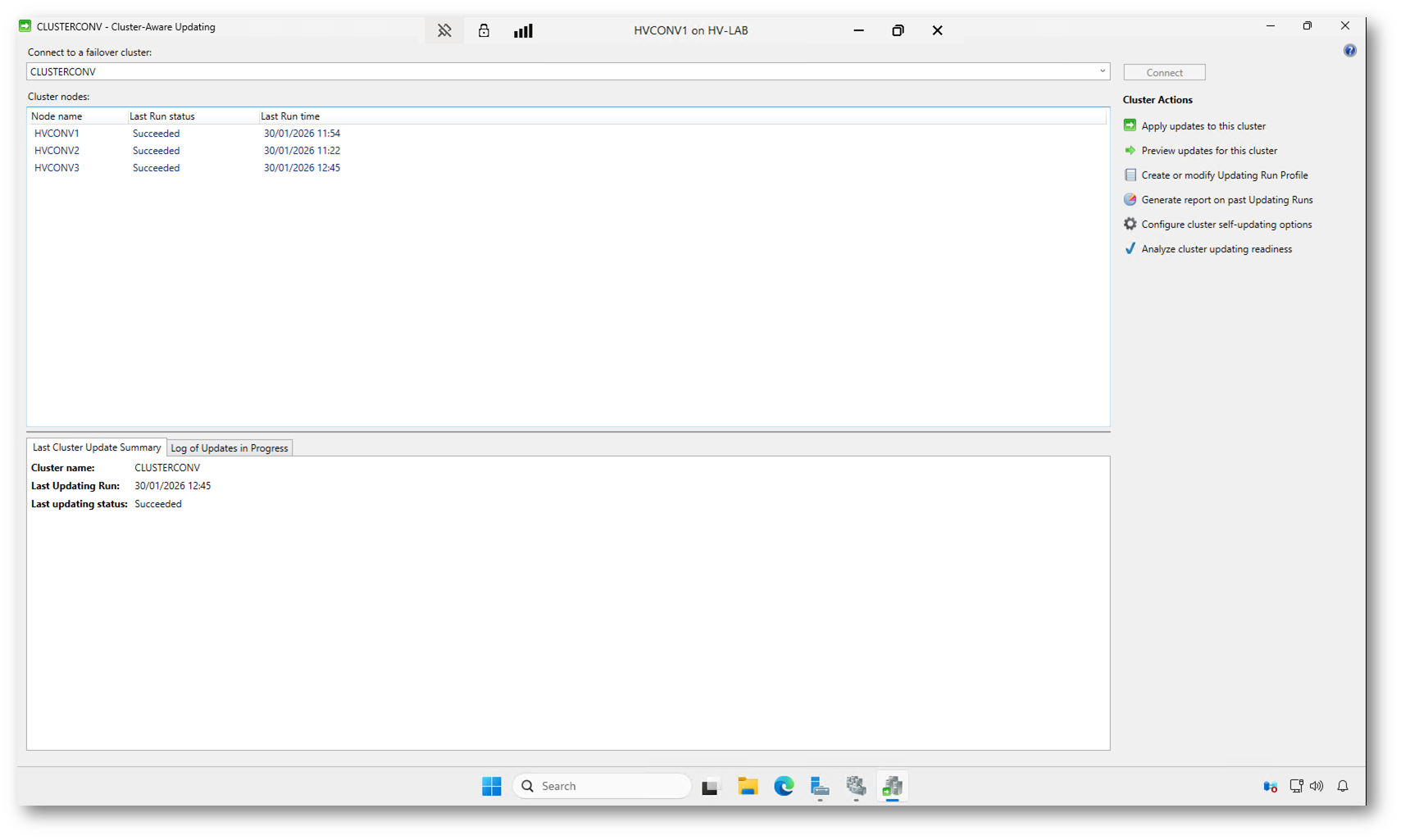
Figura 21: Aggiornamento completato
Aggiornamento del cluster tramite Windows Admin Center
In alternativa alla console Cluster-Aware Updating o a Failover Cluster Manager, potete gestire l’aggiornamento dei nodi anche tramite Windows Admin Center. Questa modalità è particolarmente comoda perché vi permette di operare da un’interfaccia web centralizzata, verificare lo stato del cluster e avviare il processo di aggiornamento senza accedere direttamente ai singoli server.
Dopo aver effettuato l’accesso a Windows Admin Center, selezionate il cluster da amministrare e aprite la sezione Updates dal menu degli strumenti disponibili. Da questa schermata potete controllare la disponibilità degli aggiornamenti per i nodi del cluster e verificare se l’ambiente è pronto per l’esecuzione dell’Updating Run.
Quando aprite la sezione Updates, Windows Admin Center deve interrogare il cluster e i singoli nodi per verificare lo stato del sistema, recuperare gli aggiornamenti disponibili e preparare l’esecuzione dell’Updating Run. In questo scenario la connessione non avviene solo tra il browser e Windows Admin Center, ma coinvolge più passaggi di autenticazione: Windows Admin Center si collega al cluster e, da lì, deve accedere anche ai nodi del cluster tramite PowerShell Remoting.
Questo comportamento viene definito PowerShell double hop. Il primo “hop” è la connessione verso il sistema gestito da Windows Admin Center; il secondo “hop” è la connessione remota dal sistema gestito verso un altro nodo o servizio del dominio. Per motivi di sicurezza, Windows non inoltra automaticamente le credenziali dell’utente a un secondo sistema remoto. Per questo motivo Windows Admin Center richiede esplicitamente un account amministrativo da utilizzare per completare le operazioni sui nodi del cluster.
Inserite quindi credenziali con privilegi amministrativi adeguati sul cluster e sui nodi interessati. In questo modo Windows Admin Center può eseguire correttamente i controlli preliminari, leggere lo stato degli aggiornamenti, orchestrare lo spostamento dei ruoli e avviare l’installazione degli update sui diversi nodi.
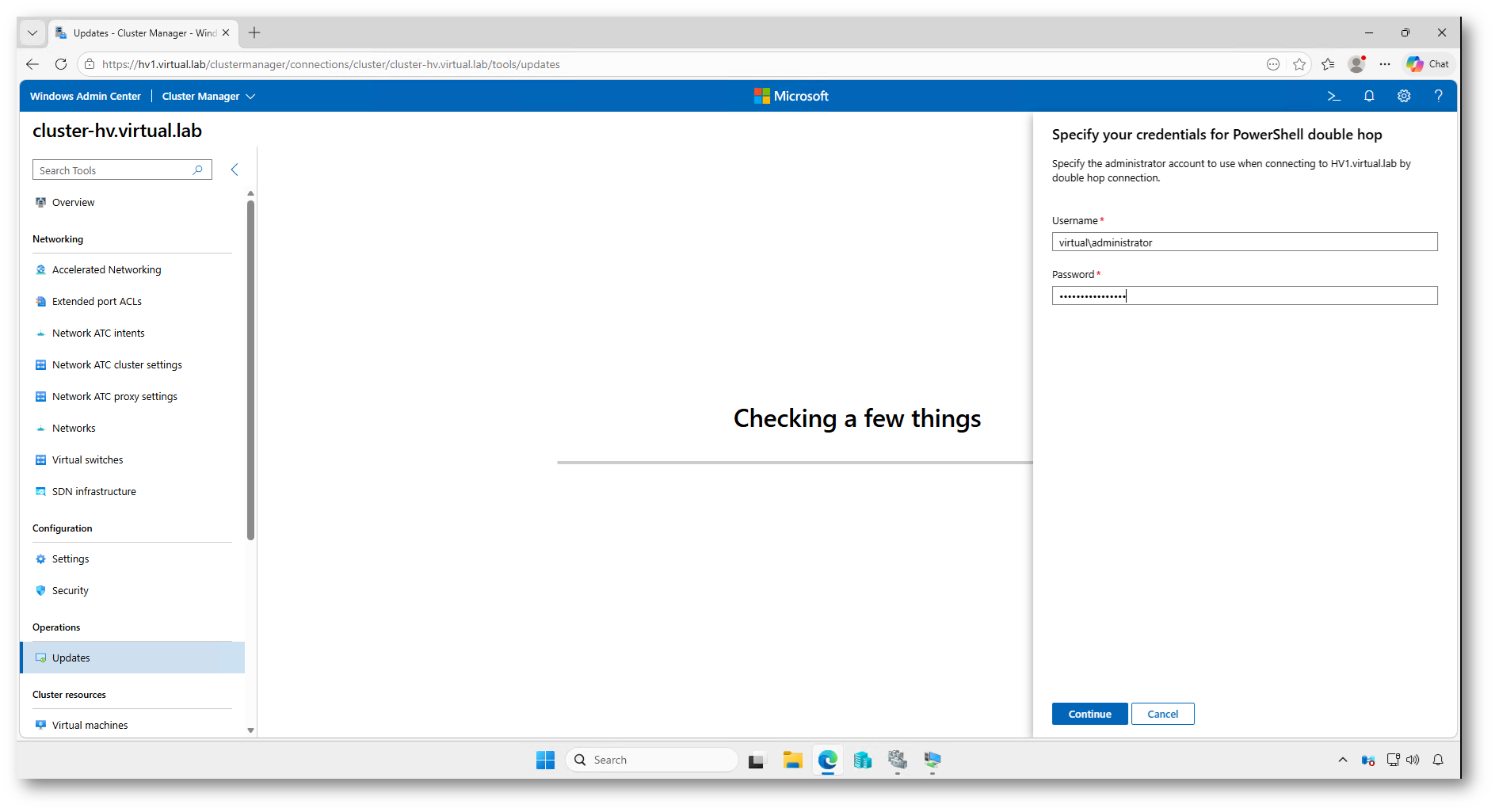
Figura 22: Inserimento delle credenziali amministrative per consentire a Windows Admin Center di eseguire le operazioni tramite PowerShell double hop
Se il ruolo Cluster-Aware Updating non è ancora configurato, Windows Admin Center vi chiede di aggiungerlo al cluster. Fate clic su Add Cluster-Aware-Updating role per abilitare la gestione degli aggiornamenti orchestrata sui nodi del cluster.
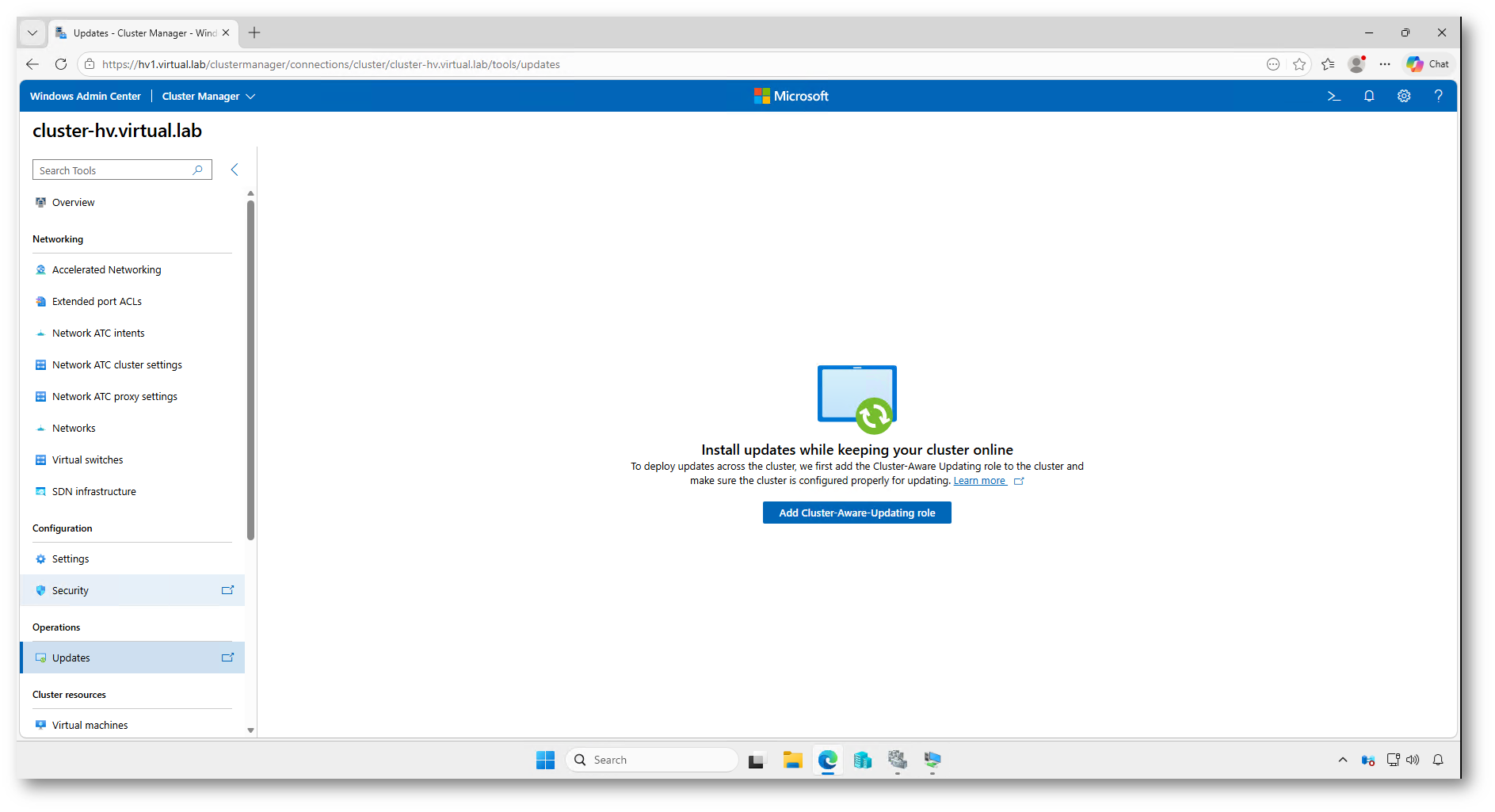
Figura 23: Aggiunta del ruolo Cluster-Aware Updating al cluster da Windows Admin Center
Dopo l’aggiunta del ruolo CAU, Windows Admin Center controlla la presenza di aggiornamenti disponibili per i nodi del cluster. Attendete il completamento della verifica prima di procedere con l’installazione.
Figura 24: Verifica degli aggiornamenti disponibili per il cluster da Windows Admin Center
Windows Admin Center mostra l’elenco degli aggiornamenti disponibili per ciascun nodo, ma non consente di selezionare singolarmente quali update installare durante l’esecuzione da interfaccia grafica. Facendo clic su Install, avviate l’installazione degli aggiornamenti rilevati per i nodi del cluster. Se volete controllare quali patch vengano applicate, dovete gestirne l’approvazione a monte, ad esempio tramite WSUS o tramite le policy di Windows Update configurate sui server.
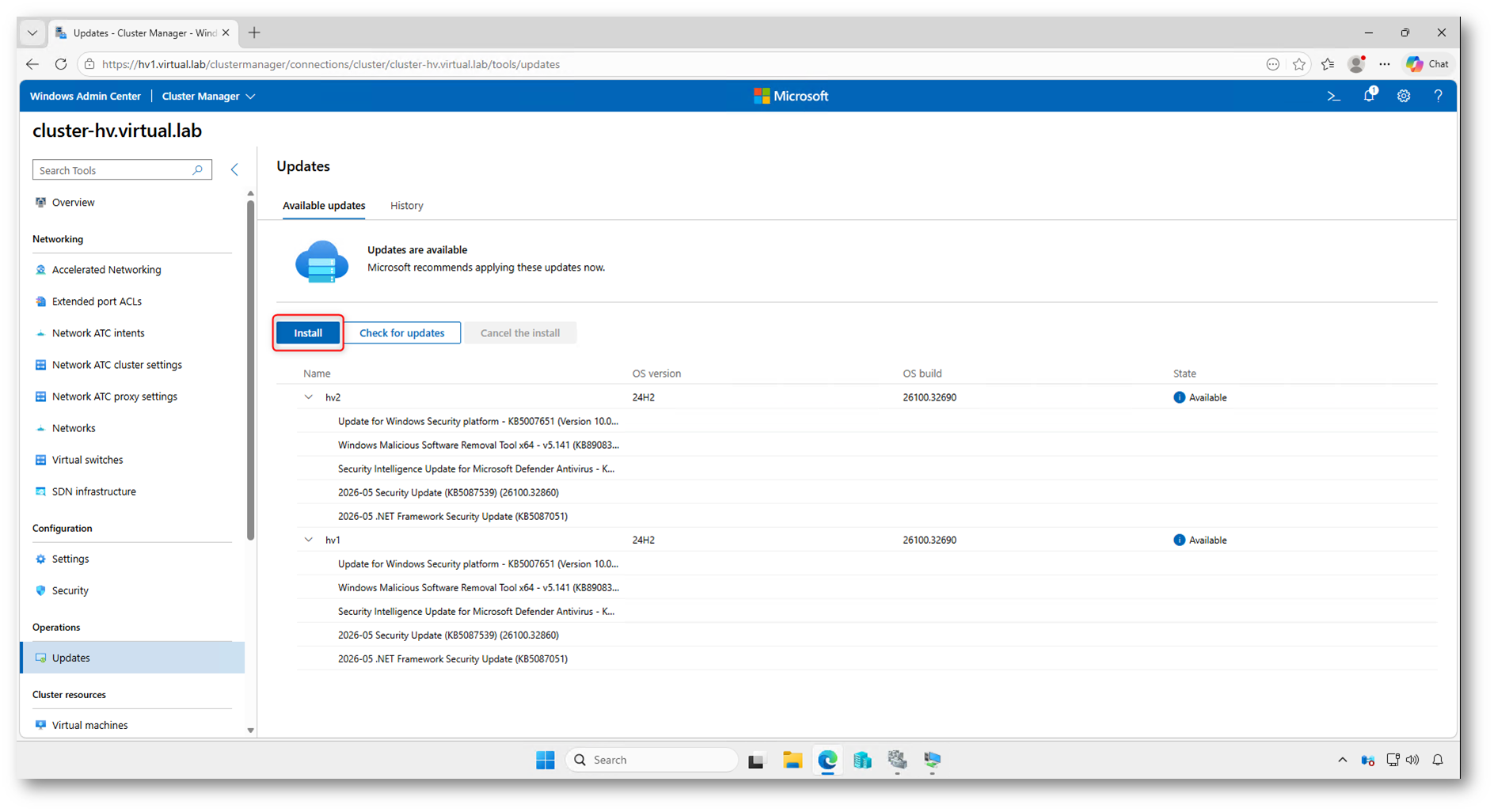
Figura 25: Elenco degli aggiornamenti disponibili per i nodi del cluster
Prima di avviare l’installazione, Windows Admin Center mostra il riepilogo degli aggiornamenti rilevati per ogni nodo. In questa schermata potete solo verificare l’elenco: non è possibile selezionare singolarmente gli aggiornamenti da installare. Fate clic su Install per avviare l’aggiornamento orchestrato del cluster.
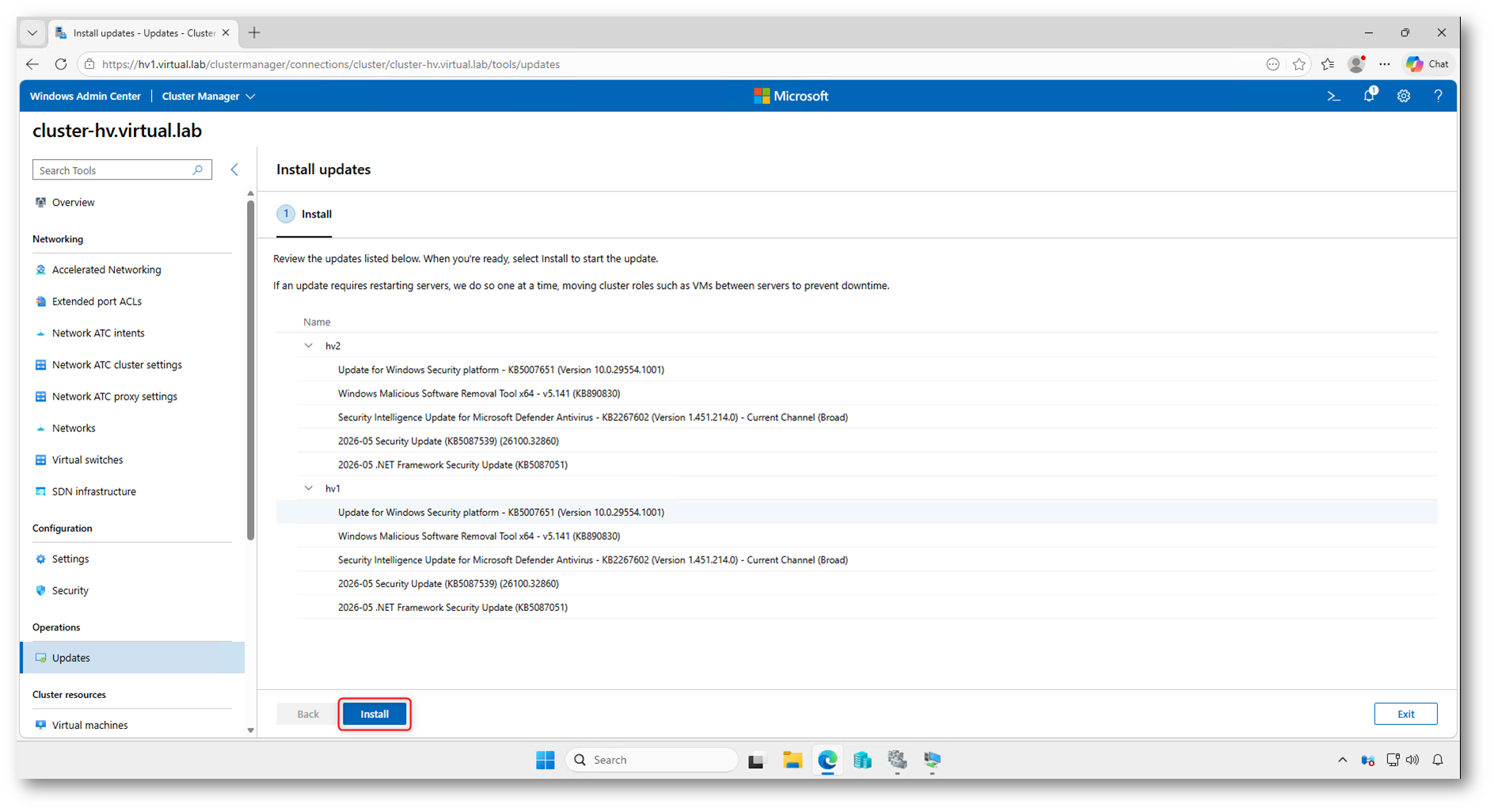
Figura 26: Conferma degli aggiornamenti da installare sui nodi del cluster
Dopo la conferma, Windows Admin Center avvia l’Update Run. Da questo momento il processo viene gestito automaticamente: i nodi vengono aggiornati in sequenza e, se necessario, riavviati uno alla volta.
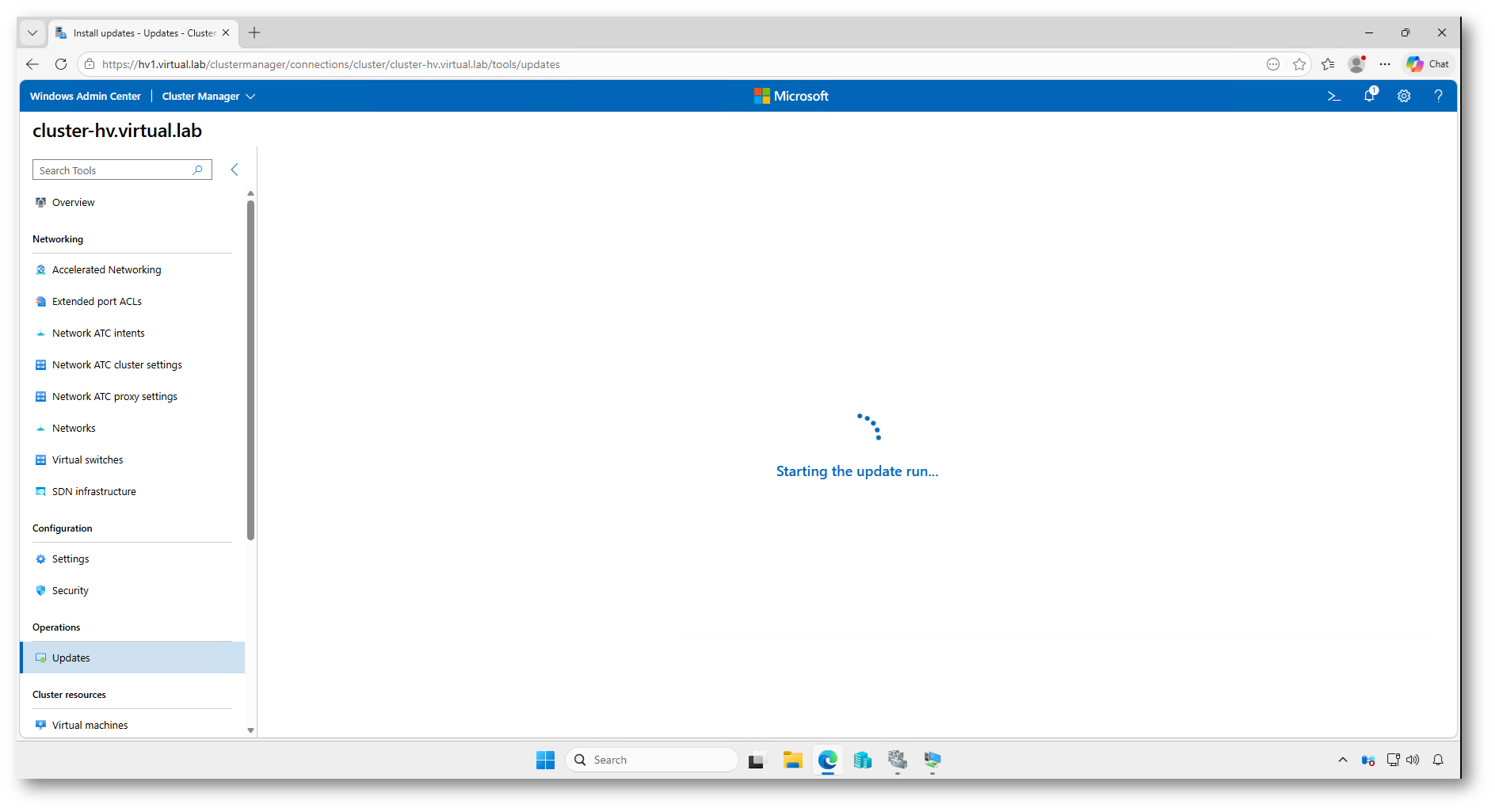
Figura 27: Avvio dell’Update Run tramite Windows Admin Center
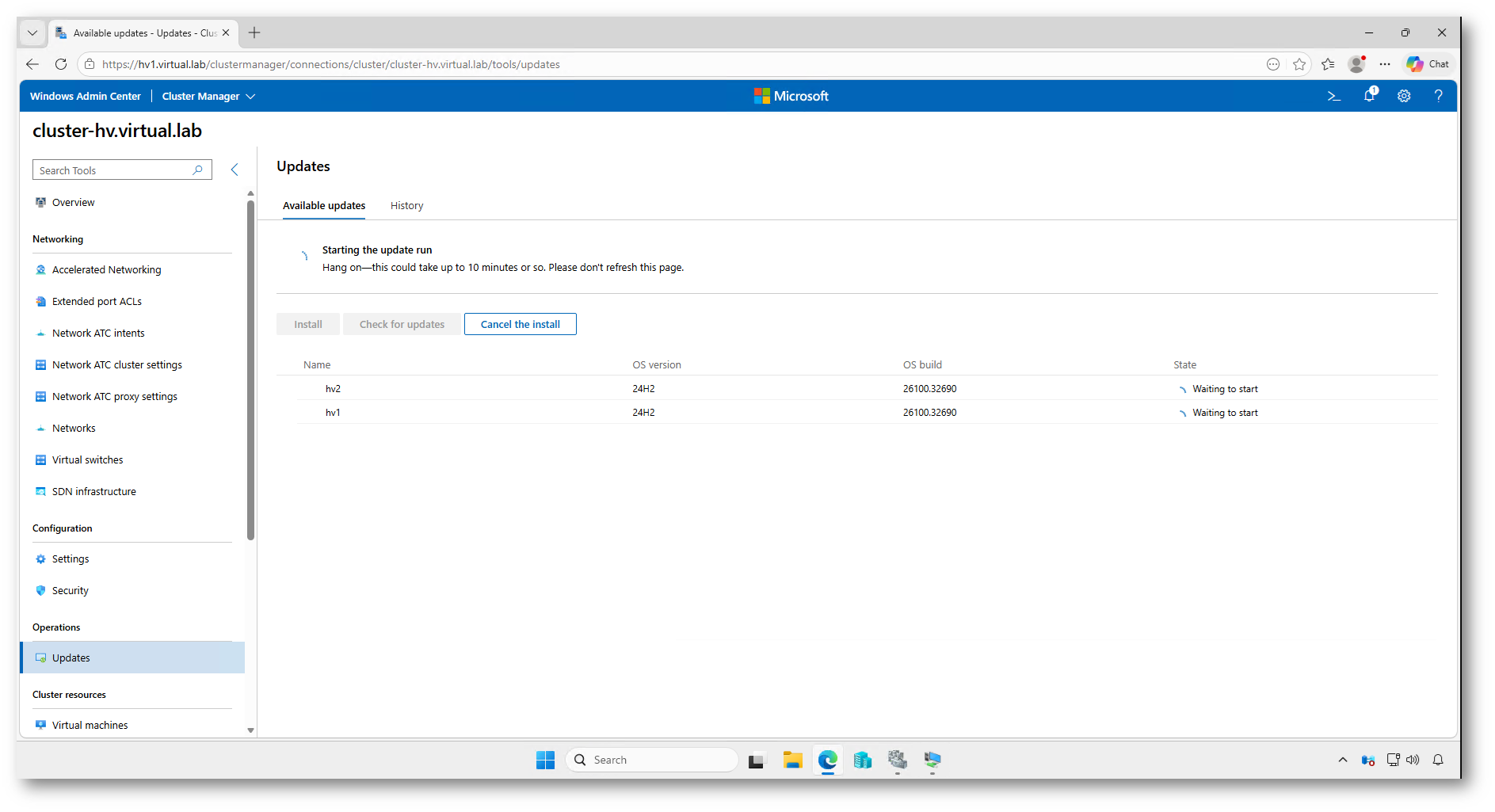
Figura 28: Avvio dell’Update Run e stato iniziale dei nodi del cluster
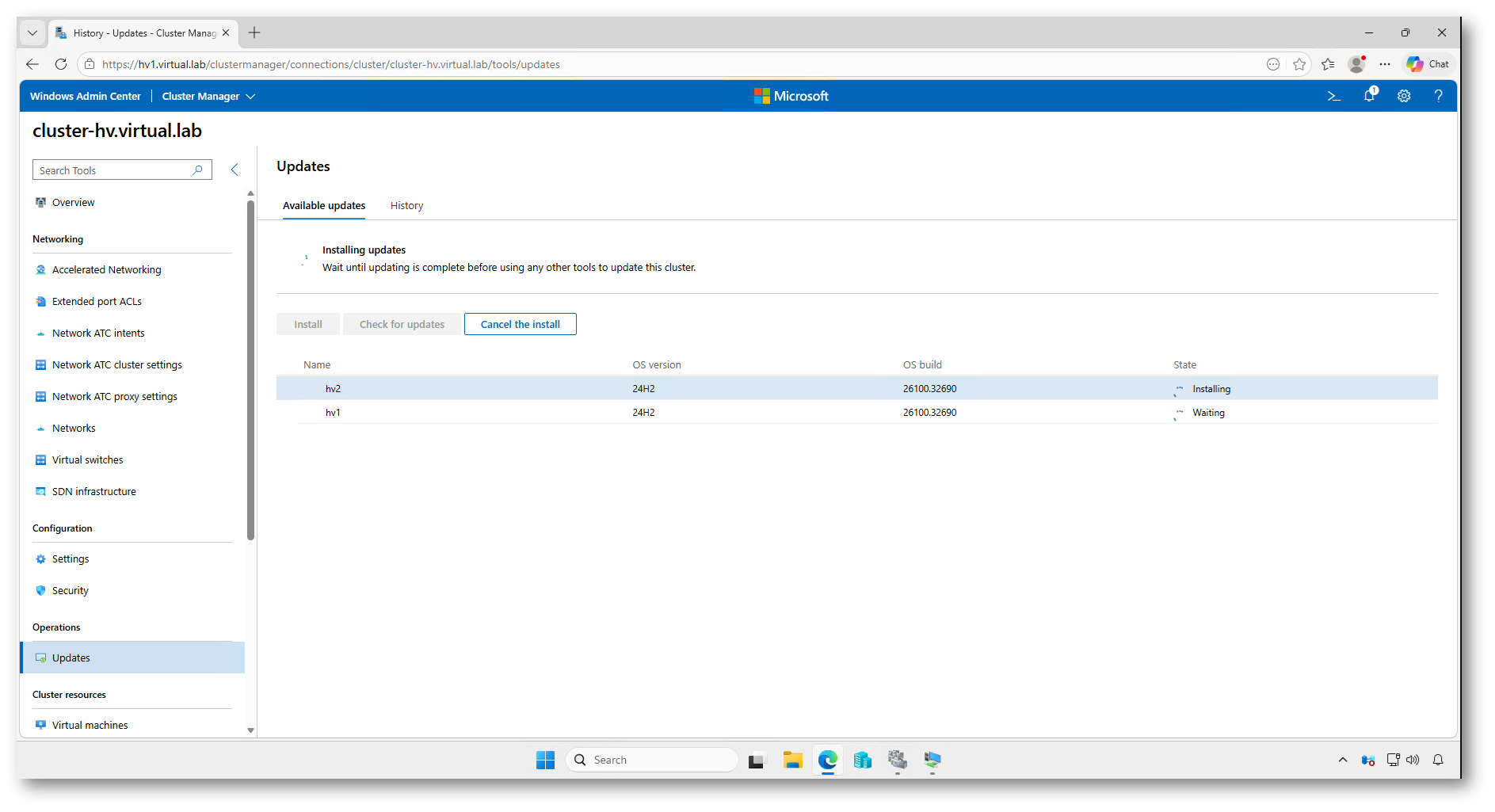
Figura 29: Installazione degli aggiornamenti sul primo nodo del cluster
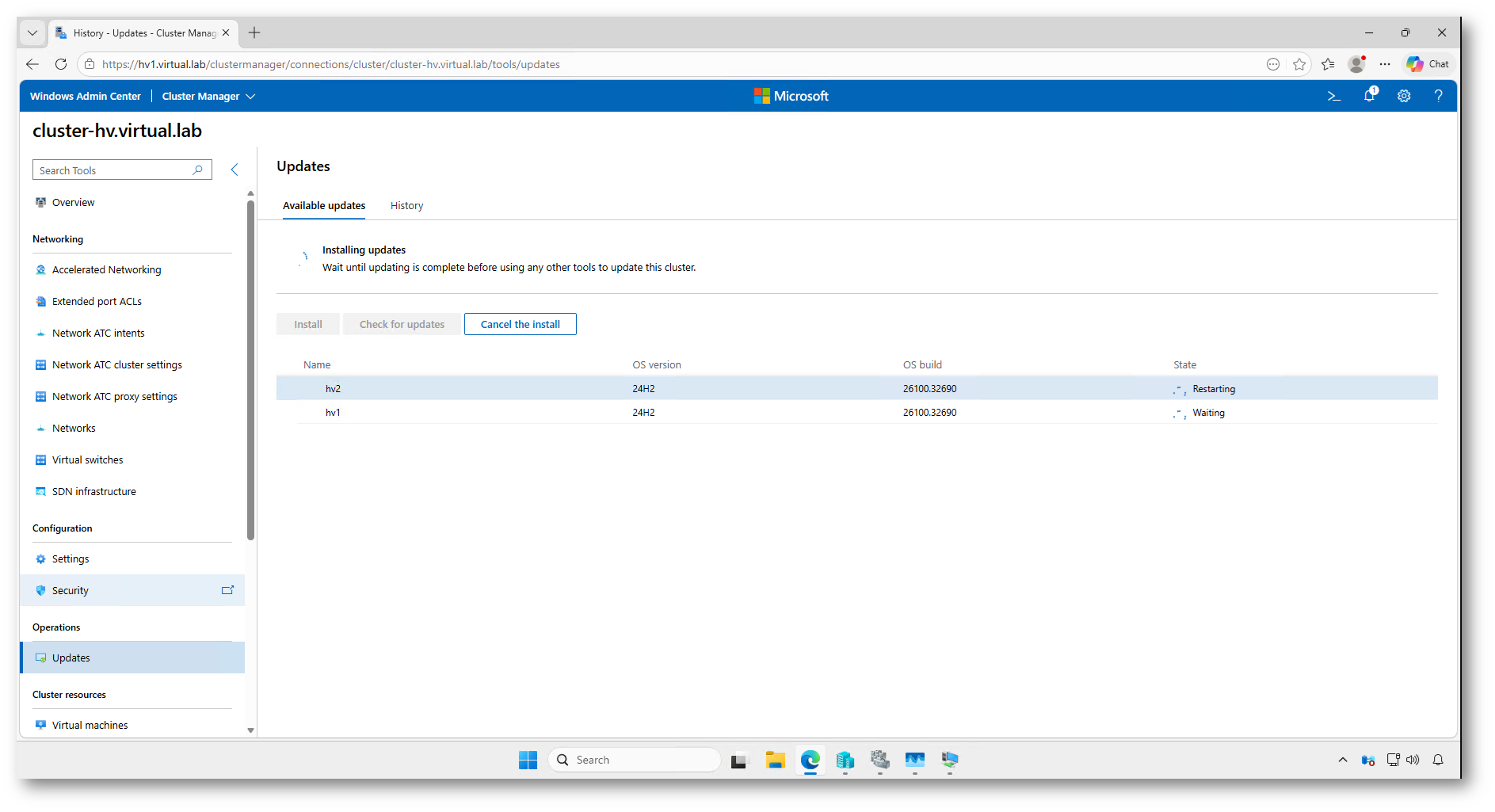
Figura 30: Riavvio del nodo aggiornato
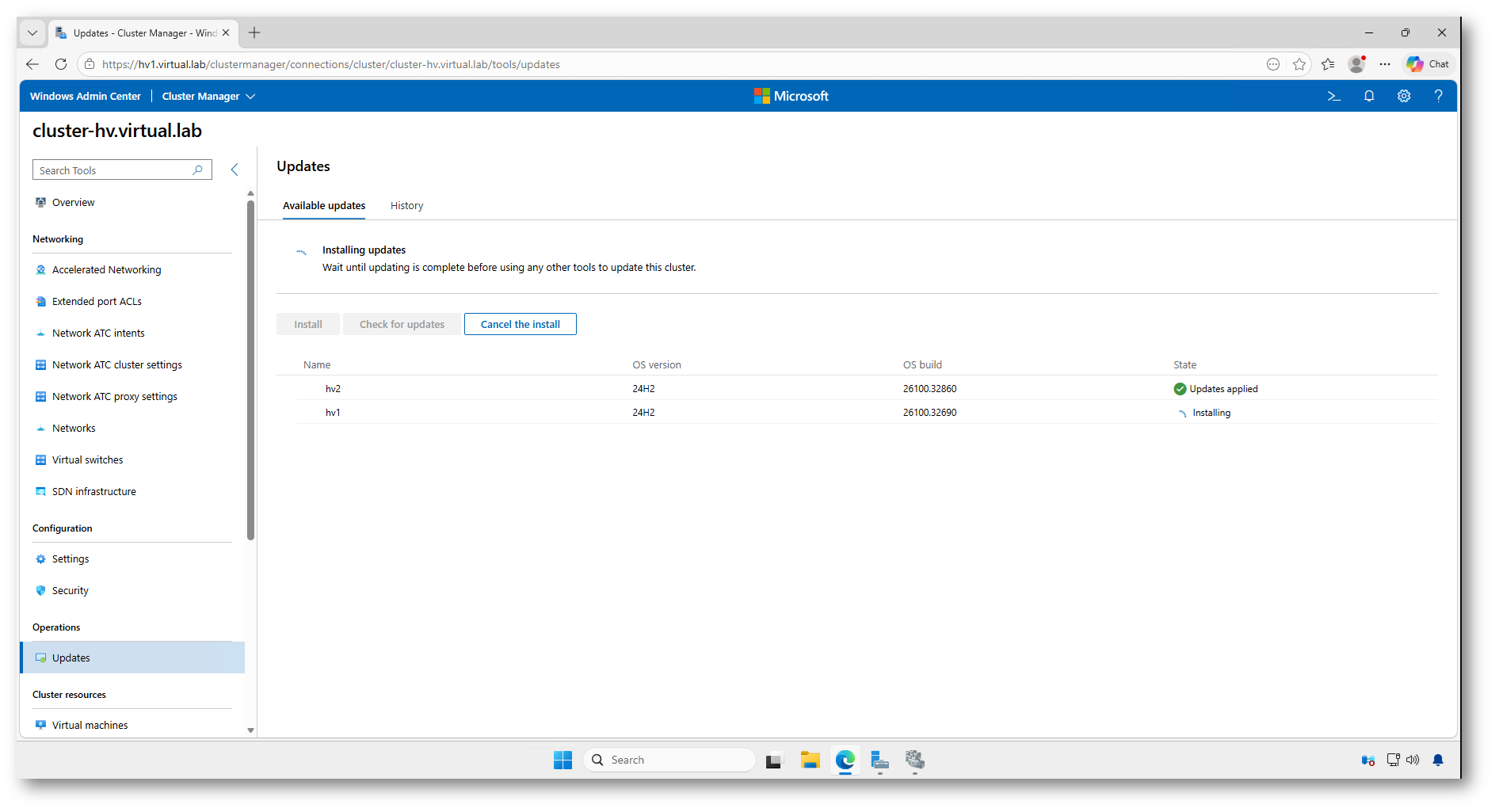
Figura 31: Completamento dell’aggiornamento sul primo nodo e installazione sul nodo successivo
Al termine dell’Update Run, Windows Admin Center indica che il cluster è aggiornato con gli aggiornamenti qualitativi disponibili. Potete eseguire un nuovo controllo con Check for updates o verificare eventuali aggiornamenti hardware tramite il collegamento dedicato.
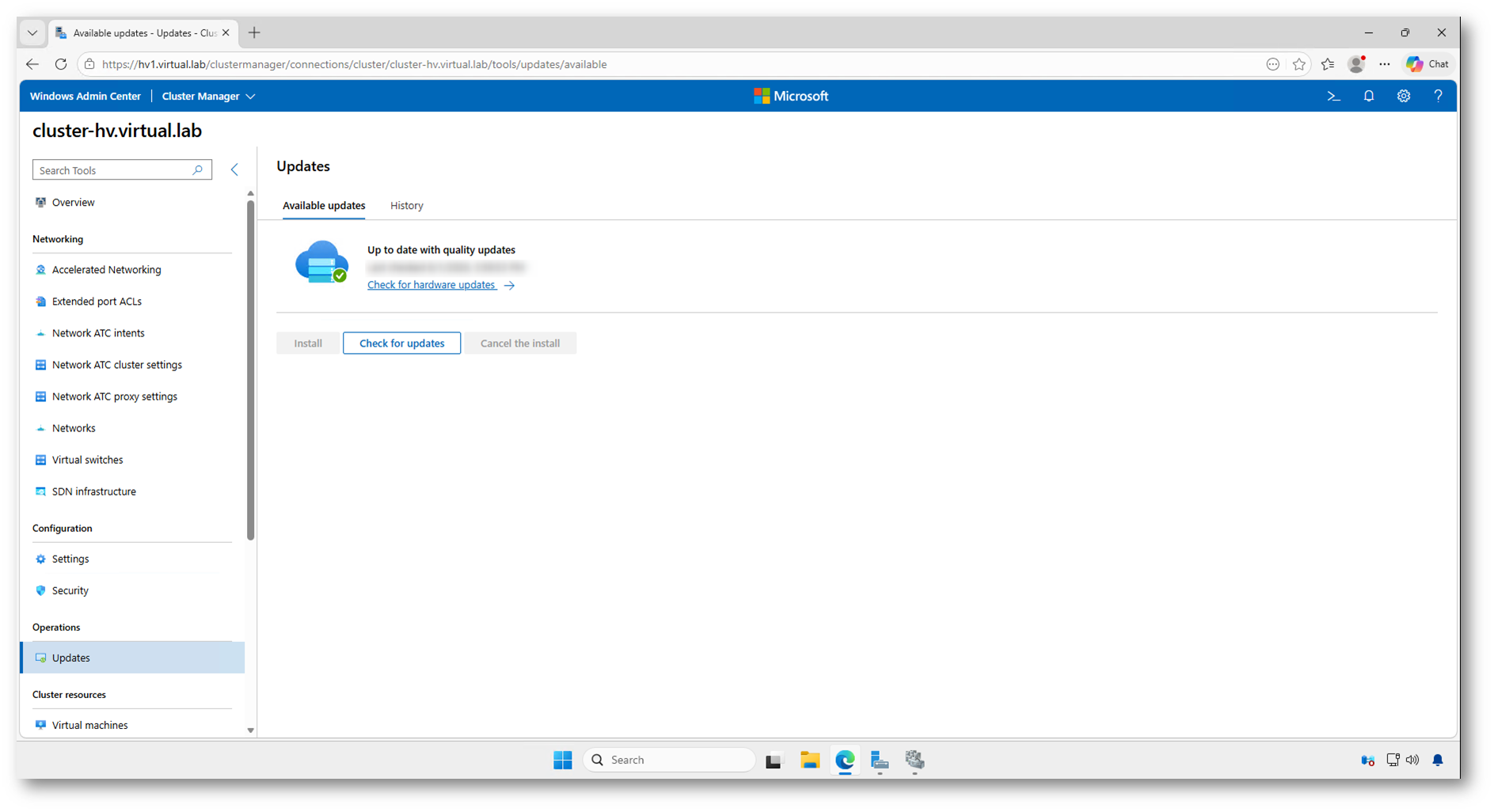
Figura 32: Verifica del completamento degli aggiornamenti del cluster
Conclusioni
Cluster-Aware Updating permette di gestire gli aggiornamenti dei Failover Cluster in modo strutturato e affidabile, riducendo drasticamente il rischio di downtime e gli interventi manuali. La gestione automatica della maintenance mode, lo spostamento controllato dei ruoli e l’aggiornamento sequenziale dei nodi rendono il processo prevedibile e adatto anche ad ambienti di produzione.
Una volta configurata la modalità self-updating, il cluster diventa autonomo: gli aggiornamenti vengono applicati secondo la pianificazione definita, con piena visibilità sullo stato e sullo storico delle esecuzioni. La possibilità di eseguire preview e Updating Run manuali consente comunque di mantenere il controllo quando serve.
In infrastrutture basate su Hyper-V o su workload critici, Cluster-Aware Updating non è solo una comodità, ma uno strumento fondamentale per mantenere i sistemi aggiornati senza compromettere la continuità del servizio.