
Cluster Shared Volume in Hyper-V: come funziona davvero l’I/O
Nel lavoro quotidiano con Hyper-V e i cluster di failover, prima o poi vi scontrate con una sigla che sembra semplice ma che nasconde parecchia complessità: CSV, Cluster Shared Volume. Spesso viene dato per scontato, abilitato quasi automaticamente durante la creazione del cluster e poi lasciato lì, a fare il suo dovere in silenzio. Ma se vi fermate un attimo a guardare cosa succede davvero “sotto il cofano”, vi rendete conto che i CSV sono uno degli elementi chiave che rendono possibile l’alta disponibilità delle macchine virtuali così come la conosciamo oggi.
Capire come funzionano i Cluster Shared Volume non è solo un esercizio teorico: vi aiuta a progettare meglio l’infrastruttura, a diagnosticare problemi di performance o di resilienza e, soprattutto, a evitare scelte architetturali sbagliate che emergono solo nei momenti peggiori, quando un nodo cade o lo storage inizia a comportarsi in modo anomalo. In questo articolo entriamo quindi nel merito dei CSV, cercando di spiegare non solo cosa sono e a cosa servono, ma anche come lavorano realmente all’interno di un cluster Hyper-V.
L’obiettivo non è ripetere la solita definizione da manuale, ma accompagnarvi passo dopo passo nella logica che sta dietro ai Cluster Shared Volume, partendo dai concetti di base fino ad arrivare ai meccanismi interni che ne regolano l’accesso, la coerenza dei dati e il comportamento in caso di fault.
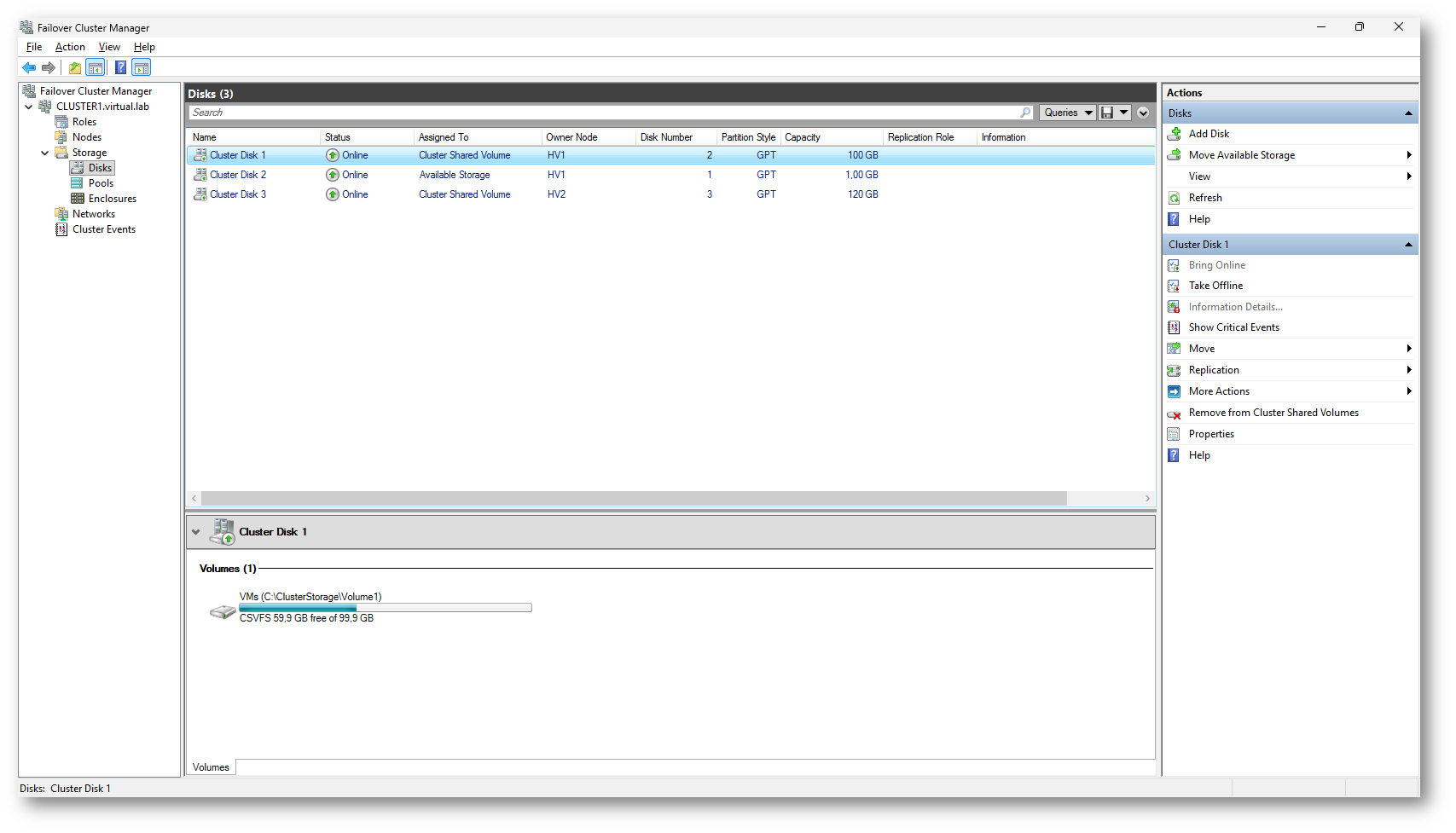
Figura 1: Failover Cluster Manager – Visualizzazione dei dischi del cluster, con volumi configurati come Cluster Shared Volume
Componenti
Quando parlate di Cluster Shared Volume è importante chiarire subito che non state semplicemente lavorando con un disco condiviso, ma con un insieme di componenti che cooperano per offrire accesso concorrente, coerenza del file system e alta disponibilità.
Il primo elemento è ovviamente il Failover Clustering, che fornisce l’intelligenza di coordinamento. CSV non è una funzionalità di Hyper-V in senso stretto, ma del cluster: Hyper-V ne è il principale consumatore, ma il meccanismo vive a un livello più basso. Sopra lo storage condiviso viene esposto un file system standard, NTFS o ReFS, accessibile in parallelo da tutti i nodi attraverso il percorso C:\ClusterStorage. Per le macchine virtuali questo accesso è del tutto trasparente.
Ogni volume CSV ha poi un coordinator node, un ruolo dinamico assegnato a uno dei nodi del cluster. Il coordinatore è responsabile delle operazioni sui metadata del file system, quindi di tutto ciò che può modificare la struttura del volume: creazione dei file, eliminazioni, estensioni, cambi di attributi. Questo non lo rende un collo di bottiglia, perché il traffico dati vero e proprio delle macchine virtuali non passa da lui in condizioni normali.
Il componente che spesso viene sottovalutato è infatti il meccanismo di I/O diretto. Quando una macchina virtuale legge o scrive all’interno di un VHDX, il nodo che la ospita comunica direttamente con lo storage condiviso, senza intermediari. Il coordinatore entra in gioco solo quando serve garantire la coerenza globale del file system. Questo modello è uno dei motivi per cui i CSV scalano bene anche in cluster di dimensioni rilevanti.
Infine, c’è la rete del cluster, che diventa fondamentale nei casi non ideali. Se un nodo perde l’accesso diretto allo storage, oppure se sono richieste operazioni che necessitano di serializzazione, il cluster può instradare temporaneamente l’I/O attraverso il coordinatore usando SMB. È un comportamento previsto e documentato, pensato per la resilienza, non per le prestazioni, ed è parte integrante del design dei CSV così come descritto dalla documentazione ufficiale.
Qui di seguito vi mostro un diagramma che mostra i componenti del CSV ed il modo in cui i dati vengono gestiti nel cluster. L’idea chiave del diagramma è questa:
- I dati viaggiano direttamente verso lo storage
- i metadata passano dal coordinatore
- la rete viene usata solo quando serve
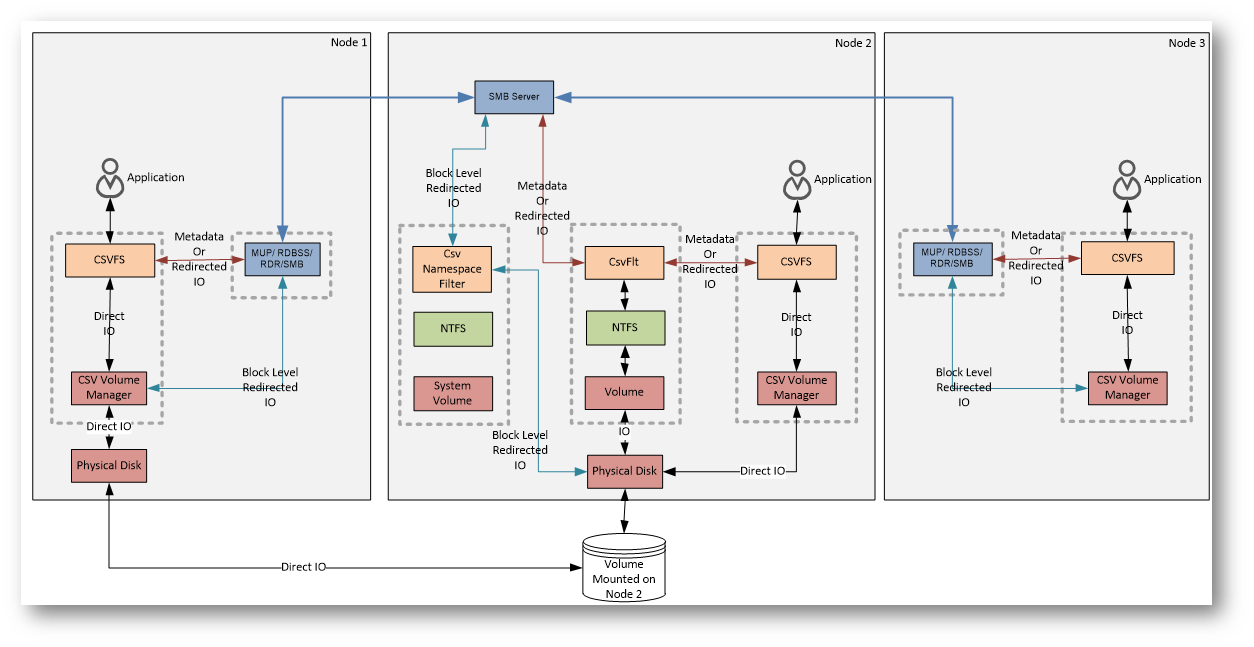
Figura 2: Componenti del CSV e diagramma sul data flow
Proviamo a leggere il diagramma “da sinistra a destra”, senza entrare troppo nei dettagli interni del kernel, ma mantenendo i concetti chiave.
Il diagramma mostra tre nodi di un cluster. Il volume CSV è fisicamente montato su un solo nodo alla volta (in questo caso il Node 2), ma tutti i nodi possono usarlo contemporaneamente.
Cosa succede nel caso normale (Direct I/O)
Quando un’applicazione (tipicamente una macchina virtuale) legge o scrive dati:
- l’I/O passa attraverso CSVFS
- scende verso il CSV Volume Manager
- arriva direttamente al disco fisico condiviso
Questo percorso è indicato come Direct I/O.
È il flusso normale, quello veloce: ogni nodo parla direttamente con lo storage, anche se il volume è “di proprietà” logica di un altro nodo.
Il ruolo del coordinator
Il nodo su cui il volume è montato (Node 2) fa anche da coordinatore.
Il suo compito non è gestire tutti i dati, ma tenere sotto controllo i metadata del file system: struttura delle directory, creazione o cancellazione dei file, estensioni dei VHDX e così via.
Quando un nodo diverso dal coordinatore deve fare un’operazione che tocca i metadata, quella richiesta non va direttamente al disco.
Metadata e Redirected I/O
In questi casi entra in gioco il percorso “laterale” che vedete nel diagramma:
- la richiesta passa da CSVFS
- viene instradata tramite lo stack SMB
- arriva al nodo coordinatore
- il coordinatore esegue l’operazione sul volume
Questo è indicato come Metadata I/O o Redirected I/O.
Non è la modalità normale di lavoro, ma è necessaria per garantire che il file system rimanga coerente per tutti i nodi.
Redirected I/O completo
Il diagramma mostra anche un altro scenario: se un nodo perde l’accesso diretto allo storage, anche l’I/O dei dati può essere reindirizzato via rete verso il coordinatore.
In quel caso tutto passa da SMB, il che permette alle VM di continuare a funzionare, ma con prestazioni inferiori.
CSV NTFS stack
Per capire cosa succede davvero quando una macchina virtuale accede a un file su un Cluster Shared Volume, conviene immaginare CSV come uno strato aggiuntivo che si inserisce sopra al file system tradizionale, senza sostituirlo. NTFS (o ReFS) continua a fare il suo lavoro, ma viene “mediato” da alcuni componenti specifici del cluster.
Dal punto di vista delle applicazioni, il volume resta un normale file system, ma le operazioni passano attraverso uno stack aggiuntivo.
Il primo livello è CSVFS, che espone il percorso C:\ClusterStorage e intercetta tutte le richieste di I/O. Qui viene stabilito se l’operazione può essere eseguita localmente oppure se deve coinvolgere il nodo coordinatore. Subito sotto agisce CsvFlt, il filtro che garantisce la coerenza del file system quando sono coinvolti i metadata.
Quando non ci sono vincoli particolari, l’I/O prosegue verso NTFS, il volume e infine il disco condiviso, seguendo il percorso diretto e più performante. Se invece l’operazione richiede coordinamento, oppure il nodo non ha accesso diretto allo storage, l’I/O viene reindirizzato via rete verso il coordinatore.
Il concetto chiave è che NTFS continua a funzionare come se il disco fosse locale. Tutta la logica di condivisione e coordinamento è gestita dallo stack CSV che si inserisce sopra il file system, rendendo possibile l’accesso concorrente senza compromettere la coerenza dei dati.
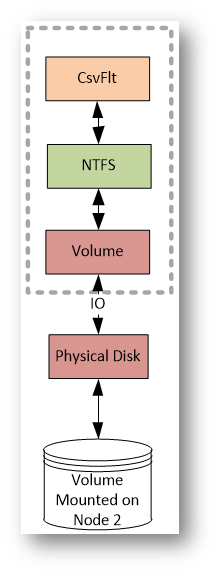
Figura 3: CSV NTFS stack
Metadata flow
I dati e i metadata seguano percorsi diversi all’interno di un Cluster Shared Volume.
In questo contesto, per operazioni di metadata si intende qualsiasi operazione che non sia una semplice lettura o scrittura di dati all’interno di un file.
Rientrano quindi nei metadata tutte le azioni che modificano la struttura o lo stato del file system, come la creazione o l’eliminazione di un file, la sua chiusura, la rinomina, il cambio di attributi, la variazione della dimensione, o qualunque operazione di controllo del file system. Anche alcune scritture, pur essendo operazioni sui dati, possono generare effetti collaterali sui metadata, ad esempio quando comportano l’estensione di un file o l’allocazione di nuovi blocchi.
La distinzione è fondamentale perché, mentre le letture e scritture “pure” seguono il percorso di I/O diretto, le operazioni di metadata richiedono sempre coordinamento, per garantire che tutti i nodi del cluster abbiano una visione coerente del volume.
Nel funzionamento normale, quando un’applicazione (tipicamente una VM) legge o scrive dati, l’I/O passa da CSVFS e viene inviato direttamente allo storage condiviso tramite il CSV Volume Manager. Questo è il Direct I/O: veloce, senza passaggi intermedi e indipendente dal nodo su cui il volume è montato.
Il flusso cambia quando l’operazione riguarda i metadata del file system, come la creazione o la modifica di un file. In questo caso la richiesta non viene eseguita localmente, ma viene inoltrata al nodo coordinatore. Il trasferimento avviene tramite SMB, che trasporta solo le informazioni necessarie alla gestione del file system, non i dati veri e propri.
Se un nodo perde l’accesso diretto allo storage, anche l’I/O dei dati può essere temporaneamente reindirizzato via SMB verso il coordinatore. È una modalità di emergenza che mantiene operative le VM, ma con prestazioni inferiori. Tutto chiaro finora?
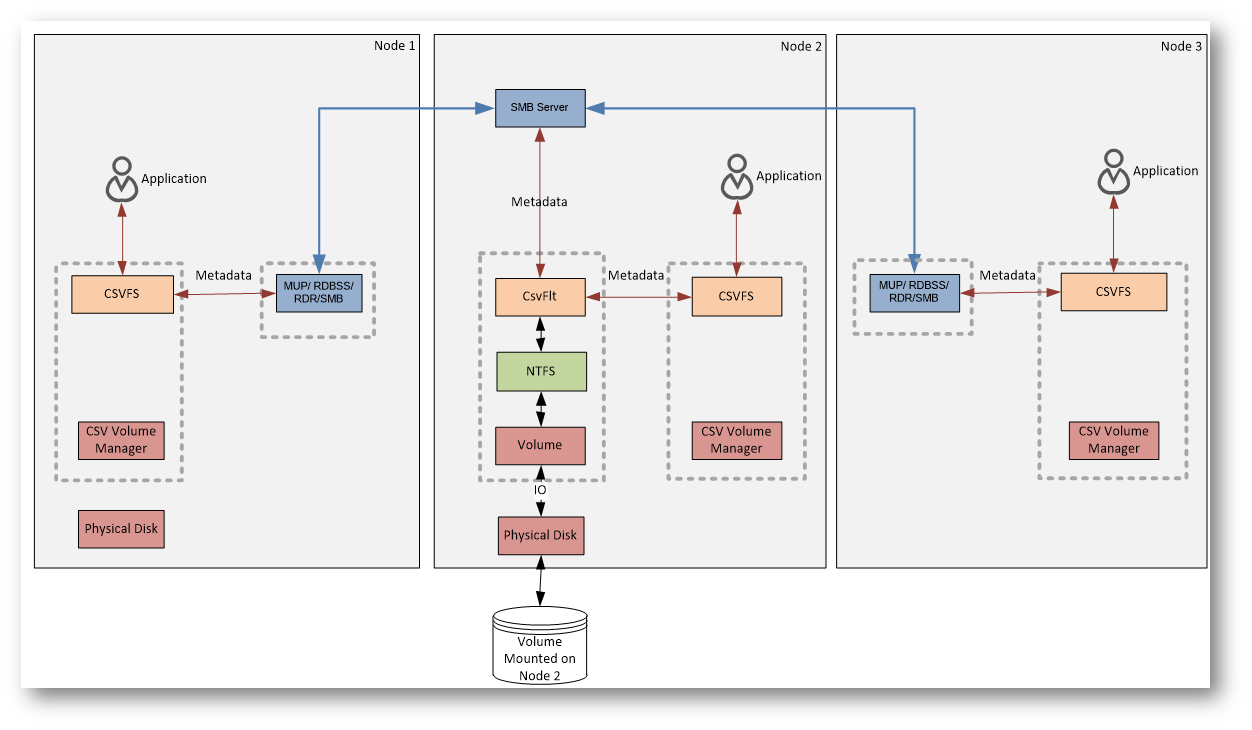
Figura 4: Metadata flow
Le operazioni di metadata vengono sempre gestite da NTFS, indipendentemente dal nodo che le origina. Quello che cambia è il percorso seguito per arrivarci.
Sul nodo coordinatore, CsvFs inoltra le richieste di metadata direttamente al volume NTFS locale, senza passaggi intermedi. È il percorso più semplice e avviene tutto all’interno dello stesso host.
Sugli altri nodi del cluster, invece, CsvFs non può parlare direttamente con NTFS. In questo caso le operazioni di metadata vengono incapsulate e inviate via SMB al nodo coordinatore, che le esegue sul volume e garantisce la coerenza del file system.
In pratica, NTFS resta sempre l’unico punto di verità, ma solo il coordinatore vi accede localmente; tutti gli altri nodi passano dalla rete per qualunque operazione che non sia una semplice lettura o scrittura di dati.
Direct I/O Flow
Nel flusso di Direct I/O, le operazioni di lettura e scrittura dei dati seguono il percorso più diretto possibile verso lo storage condiviso, senza coinvolgere il nodo coordinatore. È il comportamento normale e prevalente in un ambiente CSV.
La richiesta parte dall’applicazione, passa attraverso CSVFS e viene inoltrata al CSV Volume Manager, che consente al nodo di accedere direttamente al disco fisico condiviso. In questo scenario, ogni nodo comunica in autonomia con lo storage, anche se il volume è logicamente associato a un altro nodo del cluster.
Il punto fondamentale è che il traffico dati non passa mai dalla rete del cluster. Non viene utilizzato SMB e non c’è alcuna intermediazione da parte del coordinatore. Questo approccio riduce la latenza e permette di mantenere prestazioni molto simili a quelle di un volume locale.
Il coordinatore resta coinvolto solo in modo indiretto, per la gestione dei metadata quando necessario, ma il flusso di Direct I/O rimane sempre separato e rappresenta il percorso principale utilizzato dalle macchine virtuali durante il normale funzionamento del cluster.
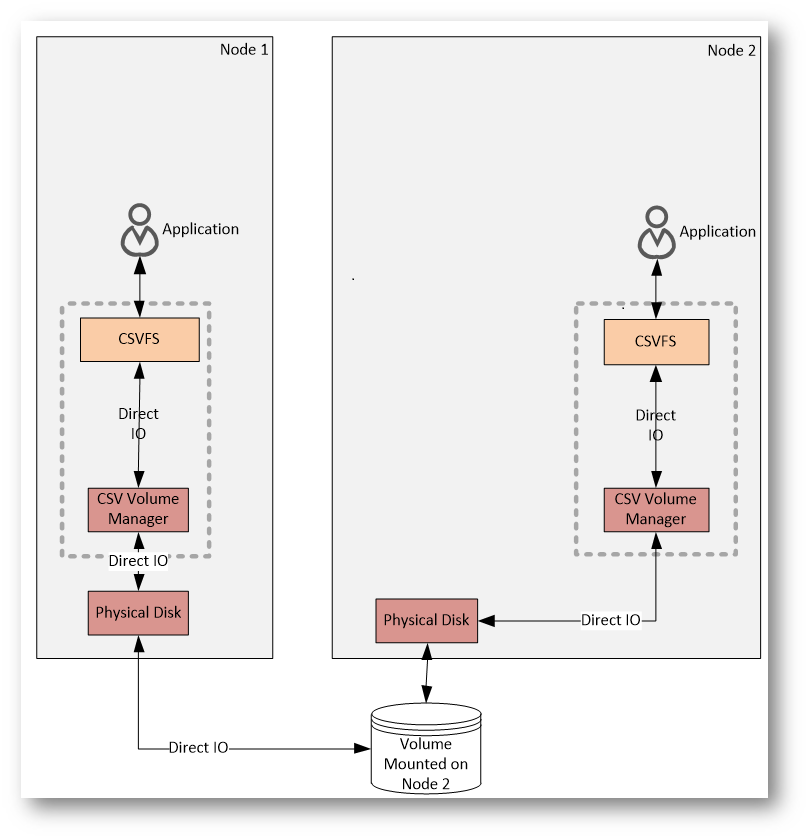
Figura 5: Direct I/O Flow
File System Redirected I/O Flow
Il File System Redirected I/O viene utilizzato quando un nodo non coordinatore deve eseguire un’operazione sui metadata del volume CSV.
La richiesta viene intercettata da CSVFS e inoltrata via SMB al nodo coordinatore, che è l’unico ad accedere direttamente a NTFS. Il coordinatore esegue l’operazione sul file system e restituisce il risultato al nodo richiedente.
Questo flusso riguarda solo i metadata, non i dati, ed è necessario per mantenere una visione coerente del file system tra tutti i nodi del cluster.
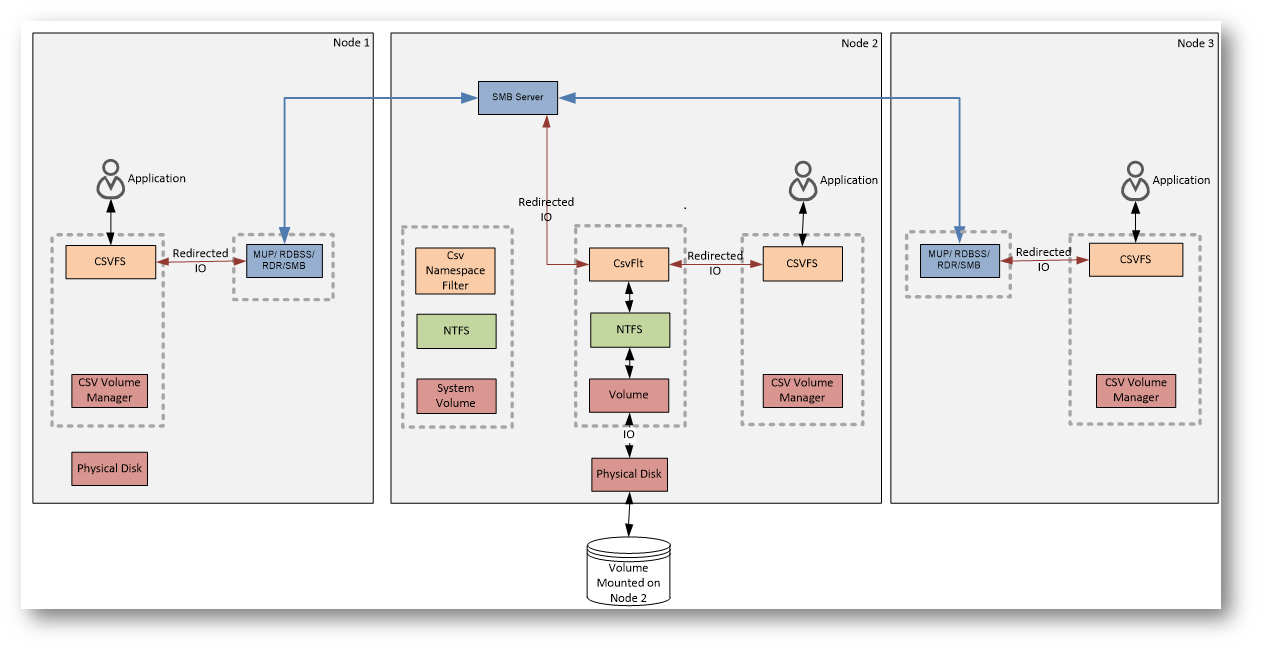
Figura 6: File System Redirected I/O Flow
Block Level Redirected I/O Flow
Il Block Level Redirected I/O si verifica quando un nodo perde l’accesso diretto allo storage del volume CSV.
In questa condizione, anche le operazioni di lettura e scrittura dei dati non possono più seguire il percorso di Direct I/O. Le richieste vengono quindi reindirizzate via SMB verso il nodo coordinatore, che accede allo storage per conto degli altri nodi.
È una modalità di emergenza pensata per garantire continuità operativa. Le macchine virtuali restano attive, ma le prestazioni risultano inferiori perché tutto l’I/O dati passa attraverso la rete del cluster e il coordinatore.
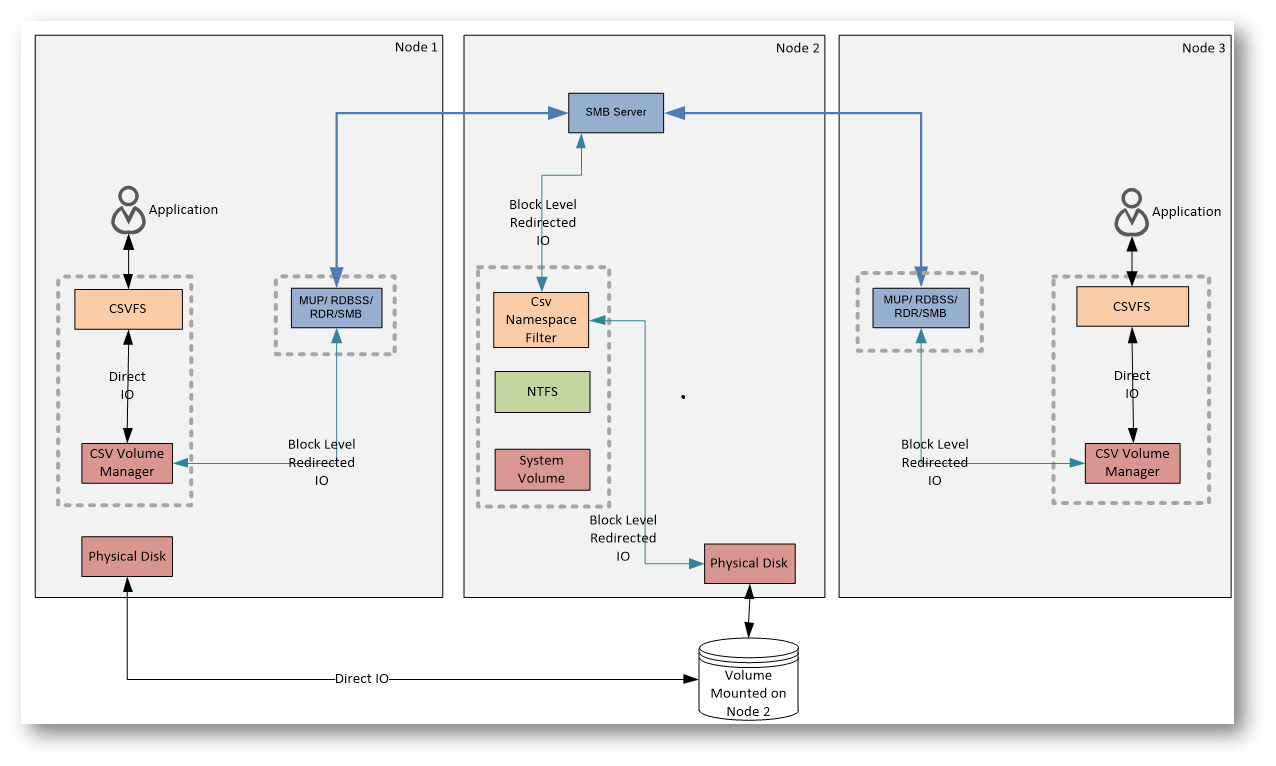
Figura 7: Block Level Redirected I/O Flow
Nel Block Level Redirected I/O lo stack CSV e quello NTFS del coordinatore non vengono utilizzati. Questo perché l’I/O a livello di blocco bypassa completamente il file system e lo stack del volume, andando direttamente al disco, in modo analogo al Direct I/O.
Sul nodo coordinatore CsvFs non entra mai in gioco per questo tipo di traffico: il coordinatore ha accesso diretto al disco e non ha motivo di usare il percorso reindirizzato. I nodi non coordinatori, invece, usano il Block Level Redirected I/O quando non possono accedere fisicamente allo storage, come nel caso di un nodo che ha perso la connettività.
Anche un nodo che “vede” il disco può finire in questa modalità. Succede, ad esempio, se l’I/O diretto fallisce a causa di problemi sull’adapter o sulla rete storage: in quel caso CsvVbus tenta il Direct I/O e, al primo errore, inoltra l’I/O al coordinatore. Un altro scenario tipico è Storage Spaces in modalità mirror, dove i nodi dati inviano sempre l’I/O a blocchi al coordinatore invece di usare il Direct I/O.
L’I/O reindirizzato arriva sul coordinatore tramite CsvNsFlt, un filtro che invia le richieste direttamente al disco, sopra NTFS e sopra lo stack del volume. Questo traffico è invisibile al file system e agli altri filtri.
CSV Cache
Esiste anche una funzionalità spesso poco considerata ma potenzialmente molto utile: la CSV Cache. Si tratta di una cache in memoria, basata su RAM, utilizzata per ottimizzare le operazioni di lettura provenienti dai volumi CSV. In pratica, una porzione della memoria degli host viene riservata per mantenere in cache i blocchi letti più di frequente, riducendo il numero di accessi diretti allo storage condiviso.
La CSV Cache lavora esclusivamente in write-through, quindi non interviene sulle scritture e non introduce rischi di inconsistenza dei dati. Il suo beneficio si manifesta soprattutto in scenari con carichi di lavoro intensivi in lettura, come ambienti VDI o macchine virtuali che accedono spesso agli stessi dati. È importante però dimensionarla con attenzione: la memoria assegnata alla cache viene sottratta a quella disponibile per le VM, quindi va valutata nel contesto complessivo delle risorse del cluster.
Inserita correttamente, la CSV Cache può contribuire a migliorare le prestazioni percepite senza modificare il flusso di I/O dei CSV, che rimane invariato dal punto di vista architetturale.
Quando abilitarla (e quando evitarla)
La CSV Cache dà il meglio di sé quando il carico di lavoro è prevalentemente in lettura e ripetitivo. È particolarmente indicata in ambienti VDI, in infrastrutture con molte macchine virtuali simili tra loro o in scenari in cui le VM accedono spesso agli stessi file o agli stessi blocchi di dati. In questi casi, la riduzione degli accessi allo storage può portare benefici concreti in termini di latenza e carico complessivo.
Al contrario, la CSV Cache è poco utile quando i workload sono intensivi in scrittura, perché le scritture non vengono mai messe in cache. Va inoltre evitata su host con memoria limitata o già fortemente utilizzata dalle macchine virtuali: riservare RAM alla cache in questi contesti rischia di peggiorare le prestazioni invece di migliorarle.
Per implementare la CSV Cache tramite Windows Admin Center, collegatevi innanzitutto al cluster e aprite la sezione Settings dal pannello degli strumenti. All’interno delle impostazioni di Storage trovate la voce dedicata alla In-memory cache, da cui potete abilitare la funzionalità e definire la quantità massima di memoria da riservare alla cache. Una volta applicate le modifiche, la configurazione viene distribuita automaticamente su tutti i nodi del cluster.
È importante tenere presente che il valore impostato rappresenta la quantità di RAM riservata per singolo nodo. Questo significa che la memoria dedicata alla CSV Cache non sarà più disponibile per le macchine virtuali, e va quindi dimensionata con attenzione in base alle risorse complessive dell’host e al tipo di carico di lavoro eseguito.
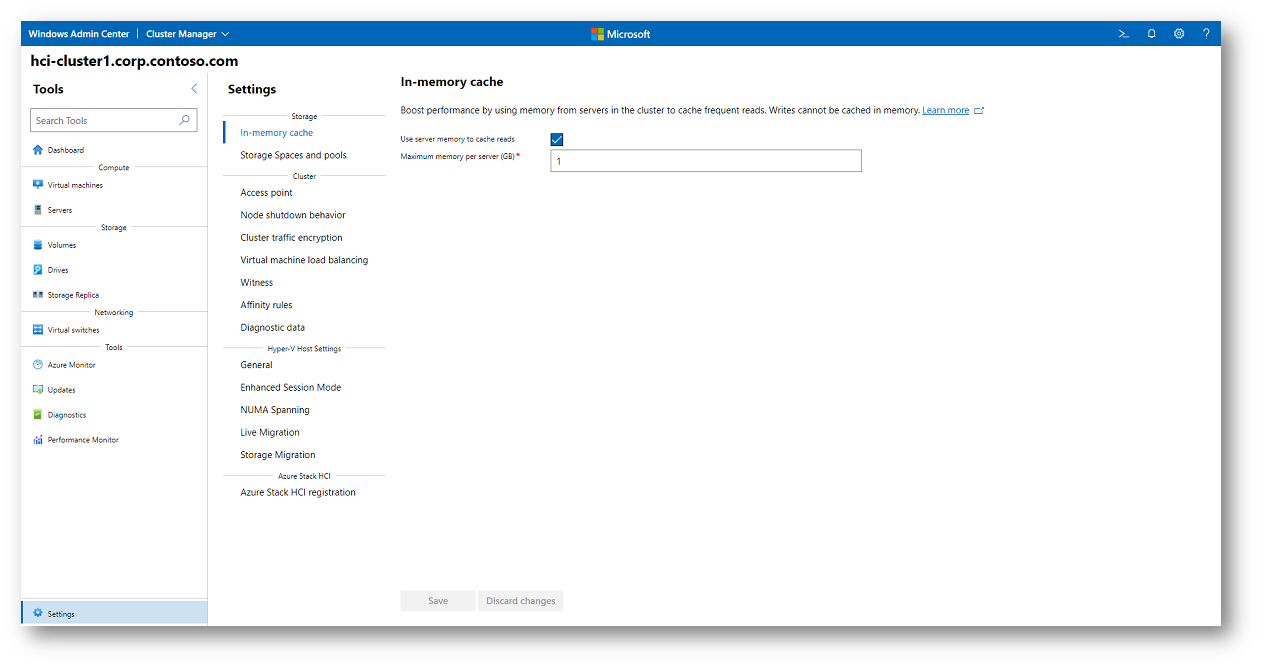
Figura 8: Abilitazione della CSV In-memory cache
Per implementare la CSV Cache con PowerShell dovete intervenire a livello di cluster, perché la cache viene dimensionata con un valore che si applica a tutti i nodi. Il parametro chiave è BlockCacheSize, espresso in MB per nodo: impostandolo, riservate quella quantità di RAM su ciascun host del cluster e, di fatto, abilitate la cache.
Ecco l’essenziale: prima verificate il valore attuale, poi assegnate quello desiderato (ad esempio 2 GB per nodo).
|
1 2 3 4 5 6 |
# Valore attuale (MB per nodo) (Get-Cluster).BlockCacheSize # Esempio: 2 GB per nodo (Get-Cluster).BlockCacheSize = 2048 |
In alcuni ambienti può essere utile controllare anche che la cache sia attiva sul singolo CSV. In quel caso potete leggere (ed eventualmente impostare) il parametro CsvEnableBlockCache sul volume interessato.
|
1 2 3 4 5 6 |
# Verifica del parametro sui CSV Get-ClusterSharedVolume | Get-ClusterParameter CsvEnableBlockCache # Esempio: abilita la cache su uno specifico CSV Get-ClusterSharedVolume "Cluster Disk 1" | Set-ClusterParameter CsvEnableBlockCache 1 |
Il punto pratico da tenere a mente è lo stesso della configurazione via interfaccia: state riservando memoria per nodo; quindi, ogni MB assegnato alla cache è RAM sottratta alle VM. Per questo ha senso farlo solo quando avete workload con molte letture ripetute e sufficiente margine di memoria sugli host.
Conclusioni
I Cluster Shared Volume funzionano separando in modo netto dati, metadata e percorsi di accesso, scegliendo di volta in volta il flusso più adatto alla situazione. In condizioni normali, il Direct I/O garantisce prestazioni elevate grazie all’accesso diretto allo storage. Quando serve coerenza del file system, entrano in gioco i flussi di redirected I/O a livello di file system. Nei casi più critici, il Block Level Redirected I/O assicura continuità operativa anche in assenza di connettività diretta al disco.
Comprendere questi meccanismi permette di interpretare correttamente il comportamento del cluster, evitare diagnosi errate e progettare infrastrutture Hyper-V più solide, consapevoli di cosa succede davvero quando qualcosa non va come previsto.