
Introduzione alle soluzioni di data integration in Microsoft Azure
L’integrazione dei dati (Data Integration) è un processo nel campo dell’informatica e della gestione delle informazioni che consiste nel combinare dati provenienti da diverse fonti per fornire una visione unificata. Questo processo è fondamentale in diversi scenari aziendali, come la business intelligence, l’analisi dei dati e la migrazione dei dati.
L’integrazione dei dati è particolarmente importante in un’era in cui le organizzazioni si affidano a diverse fonti di dati per guidare le decisioni aziendali e ottenere vantaggi competitivi, consentendo di unire dati eterogenei in maniera efficiente e migliorando la qualità e l’utilità delle informazioni disponibili.
L’aspetto fondamentale dell’integrazione dei dati è la raccolta di dati da fonti multiple, che possono includere database relazionali, file, documenti, servizi web e altre fonti di dati. Una volta raccolti, i dati spesso necessitano di essere “puliti” per correggere le discrepanze e garantire la coerenza, che può includere la standardizzazione di formati, la correzione di errori e l’eliminazione di duplicati.
Successivamente i dati possono essere trasformati o convertiti in un formato comune per facilitarne l’analisi e l’elaborazione. Questo include operazioni come la mappatura di schemi, la conversione di tipi di dati e la normalizzazione.
I dati integrati possono essere memorizzati in un data warehouse, un data lake o in altri sistemi di archiviazione per analisi successive. Questo permette a utenti e applicazioni di accedere e condividere facilmente dati in modo coerente.
Una volta integrati, i dati possono essere utilizzati per generare report, analisi di business, previsioni e per supportare decisioni basate sui dati. È fondamentale mantenere la sicurezza e la conformità dei dati durante il processo di integrazione, garantendo che le normative sui dati siano rispettate.
Azure offre una gamma di servizi di integrazione dei dati per supportare vari scenari aziendali. Questi servizi forniscono una piattaforma completa che le aziende possono utilizzare per integrare applicazioni aziendali e fonti di dati. La combinazione di questi servizi offre una soluzione scalabile e basata sul cloud per l’integrazione aziendale, con la capacità di gestire grandi volumi di transazioni, migliorare la qualità del servizio e ridurre il costo.
In questo articolo voglio parlarvi di:
- Azure Data Factory: Un servizio ETL (Extract, Transform, Load) basato sul cloud per l’integrazione e la trasformazione di grandi dataset provenienti da varie fonti, come sistemi di file, database e storage di Azure. Offre un’interfaccia utente senza codice per l’autorizzazione intuitiva e monitoraggio. Permette di connettere a sorgenti dati eterogenee e spostare i dati in diversi ambienti, sia in cloud che on-premises, e offre capacità di trasformazione dei dati mediante compute services come Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics e Azure Machine Learning.
- Azure Data Lake: È una soluzione di storage altamente scalabile e sicura per big data analytics. Permette di raccogliere dati di qualsiasi tipo e dimensione, velocità o varietà per eseguire analisi operative e di esplorazione su di essi. Azure Data Lake è compatibile con HDFS ed è integrato con Azure HDInsight.
- Azure Databricks: Una piattaforma di analisi basata su Apache Spark, ottimizzata per il cloud di Azure. Fornisce ambienti di notebook, Spark jobs e flussi di lavoro per elaborare dati, oltre a collaborazione integrata e integrazione con altri servizi Azure come Azure Data Lake Storage.
- Azure Synapse Analytics: Precedentemente noto come Azure SQL Data Warehouse, è un servizio analitico illimitato che unisce data warehousing aziendale e Big Data analytics. Permette di eseguire query sui dati utilizzando l’on-demand o provisioning risorse per ottenere prestazioni elevate, e fornisce integrazione con strumenti di machine learning e business intelligence.
- Azure Stream Analytics: È un servizio di analisi di flussi dati in tempo reale che consente di sviluppare e distribuire soluzioni di analisi complesse con query SQL. È possibile trasformare e analizzare i flussi di dati in tempo reale da dispositivi IoT, applicazioni e altri flussi di dati.
Linee guida per scegliere il servizio giusto
- Ho bisogno di orchestrare flussi da molte fonti? → Azure Data Factory
- Devo elaborare grandi volumi con trasformazioni complesse? → Azure Databricks
- Mi serve un ambiente unificato per analisi avanzate e data warehousing? → Azure Synapse Analytics
- Elaboro eventi in tempo reale o IoT? → Azure Stream Analytics
- Mi serve uno storage scalabile per big data? → Azure Data Lake
Vediamo nel dettaglio come poter utilizzare al meglio ognuno dei servizi che vi ho presentato.
Azure Data Factory (ADF) – servizio di integrazione dei dati basato sul cloud
Azure Data Factory consente di creare, gestire e orchestrare processi di trasferimento e trasformazione dei dati (ETL o ELT) in grande scala. ADF è progettato per consentire agli sviluppatori di costruire soluzioni complesse di integrazione dei dati che possono spostare e trasformare dati da una varietà di sorgenti dati verso vari data store per processi di analisi e reporting.
Azure Data Factory serve a:
- Integrare dati da diverse fonti: Collega dati da diverse sorgenti, come database, file system, feed di dati, servizi cloud e qualsiasi formato di dati strutturati e non strutturati.
- Elaborare e trasformare dati: Utilizza servizi di compute come Azure HDInsight (Hadoop e Spark), Azure Databricks e Azure SQL Database per elaborare e trasformare i dati.
- Automatizzare flussi di lavoro di dati: Offre la possibilità di pianificare e orchestrare flussi di lavoro di elaborazione dati complessi utilizzando un’interfaccia visiva o definizioni JSON.
- Monitorare e gestire processi di ETL/ELT: Fornisce strumenti per monitorare le prestazioni, l’integrità e la riuscita dei flussi di lavoro di integrazione dei dati.
Come posso utilizzare Azure Data Factory?
Supponiamo che una società di telecomunicazioni voglia analizzare i log delle chiamate per migliorare la qualità del servizio clienti. Con Azure Data Factory, possono orchestrare il processo di trasferimento dei dati dai sistemi interni al cloud per l’analisi.
Inizialmente creano una Data Factory nel portale di Azure e stabiliscono un “linked service” per connettersi al database interno dove sono memorizzati i log delle chiamate. Dopo aver stabilito la connessione, procedono con la configurazione di un’attività di copia all’interno di una pipeline di Data Factory, che trasferirà i dati in un ambiente di Azure SQL Database o in un Azure Data Lake Storage Gen2, a seconda della preferenza e della necessità di ulteriori trasformazioni dei dati.
Una volta configurata l’attività, definiscono la frequenza di esecuzione della pipeline, che potrebbe essere impostata per eseguire il trasferimento dei dati ogni notte, minimizzando l’impatto sulle operazioni giornaliere.
Quando i dati arrivano nel cloud, vengono utilizzate altre pipeline per trasformare e pulire i dati, preparandoli per l’analisi. Questo potrebbe includere l’eliminazione di record duplicati, la correzione di formati incoerenti e l’arricchimento dei dati con ulteriori informazioni.
Con i dati puliti e trasformati, la società può quindi applicare modelli di machine learning per identificare modelli di chiamate, come i picchi di traffico o i problemi tecnici ricorrenti, utilizzando Azure Machine Learning o altre piattaforme analitiche.
In tutto questo processo, Azure Data Factory agisce come un coordinatore centrale, gestendo il trasferimento e la trasformazione dei dati con precisione e efficienza, monitorando l’esecuzione delle attività e registrando eventi che possono essere rivisti per migliorare continuamente il flusso di dati.
Nella figura sotto viene mostrato come eseguire il caricamento incrementale in una pipeline di estrazione, caricamento e trasformazione (ELT). Si usa Azure Data Factory per automatizzare la pipeline ELT e la pipeline sposta in modo incrementale i dati OLTP più recenti da un database SQL Server locale in Azure Synapse. I dati transazionali vengono trasformati in un modello tabulare per l’analisi.
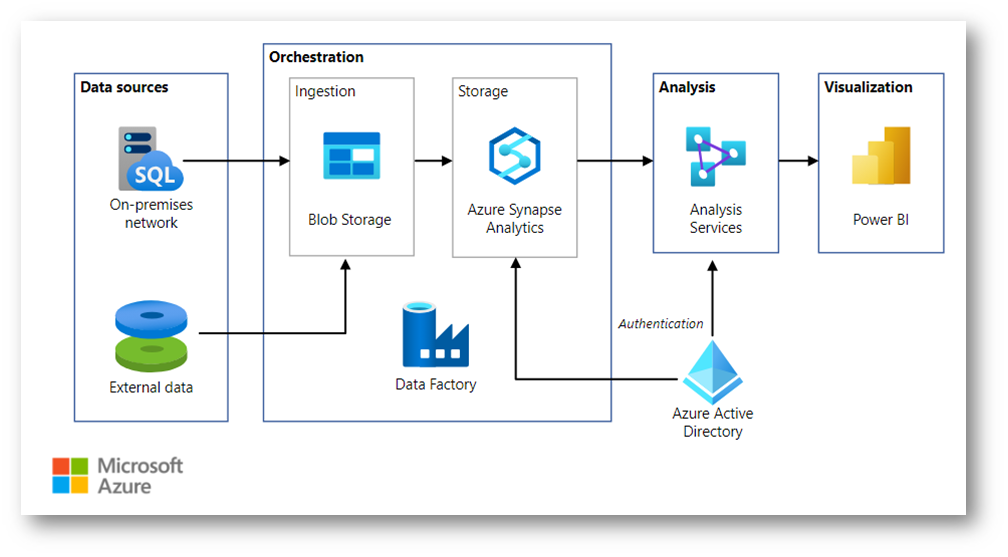
Figura 1: Utilizzo di Azure Data Factory
Azure Data Lake – soluzione di storage altamente scalabile per big data analytics
Azure Data Lake consente di raccogliere, archiviare e analizzare grandi quantità di dati strutturati e non strutturati. Questo servizio di storage è ottimizzato per l’analisi di dati in batch e in tempo reale, offrendo un’ampia piattaforma di capacità e un’architettura che facilita il calcolo distribuito su larga scala.
Azure Data Lake è progettato per:
- Storage massivo di dati: Fornisce uno storage sicuro e scalabile per dati di qualsiasi dimensione, velocità e varietà, da petabyte a exabyte.
- Analisi di Big Data: Permette di eseguire analisi su dati di grandi dimensioni utilizzando servizi come Azure Databricks, Azure HDInsight e Azure Data Factory.
- Elaborazione flessibile: Supporta diversi framework di elaborazione, come Hadoop, Spark, Hive, LLAP, Kafka e Storm.
- Gestione dei dati semplificata: Offre una gestione dei dati semplificata con metadati, sicurezza e scalabilità gestiti.
- Integrazione con servizi Azure: Si integra con altri servizi Azure per l’analisi e la visualizzazione dei dati, come Azure Synapse Analytics, Power BI e Azure Machine Learning.
- Sicurezza e conformità: Fornisce funzionalità avanzate di sicurezza, governance e audit per proteggere i dati e gestire la conformità.
Come posso utilizzare Azure Data Lake?
Immaginiamo di gestire una catena di negozi al dettaglio e di voler ottimizzare le scorte basandoci sulle tendenze di acquisto dei clienti. Utilizzando Azure Data Lake, possiamo raccogliere e analizzare grandi volumi di dati sulle transazioni di vendita per prevedere la domanda futura.
Innanzitutto, creiamo un account Azure Data Lake Storage Gen2 attraverso l’Azure Portal, che servirà come nostro repository centrale per i dati di vendita. Successivamente, carichiamo i dati storici delle transazioni nel Data Lake, attingendo dai sistemi POS dei vari negozi e magari utilizzando Azure Data Factory per automatizzare questo flusso di dati.
Una volta che i dati sono nel Data Lake, avviamo un processo di elaborazione con Azure Databricks per eseguire analisi predittive. In questo ambiente, possiamo sfruttare la potenza di Apache Spark per analizzare i modelli di acquisto e prevedere la domanda di specifici prodotti. Questo ci permetterà di ottimizzare l’inventario in base alle previsioni, riducendo così gli sprechi e migliorando la soddisfazione del cliente.
Per rendere i risultati facilmente accessibili ai responsabili dei negozi e ai dirigenti, integreremo i dati elaborati con Power BI, creando dashboard interattive che mostrano le previsioni della domanda e le raccomandazioni per l’approvvigionamento dell’inventario. Queste dashboard permettono di prendere decisioni informate in modo rapido e agile, adattando le scorte ai bisogni attuali e futuri dei clienti.
Attraverso questo esempio, Azure Data Lake si rivela essere una risorsa strategica per l’azienda, consentendo non solo di centralizzare e gestire grandi quantità di dati, ma anche di estrarre valore attraverso l’analisi avanzata e la visualizzazione intuitiva.
Nella figura sotto viene illustrata una pipeline di dati che integra grandi quantità di dati da più origini in una piattaforma di analisi unificata in Azure. Questo scenario specifico è basato su una soluzione di vendite e marketing, ma gli schemi progettuali sono pertinenti a diversi settori che richiedono l’analisi avanzata di grandi set di dati, ad esempio e-commerce, vendite al dettaglio e settore sanitario.
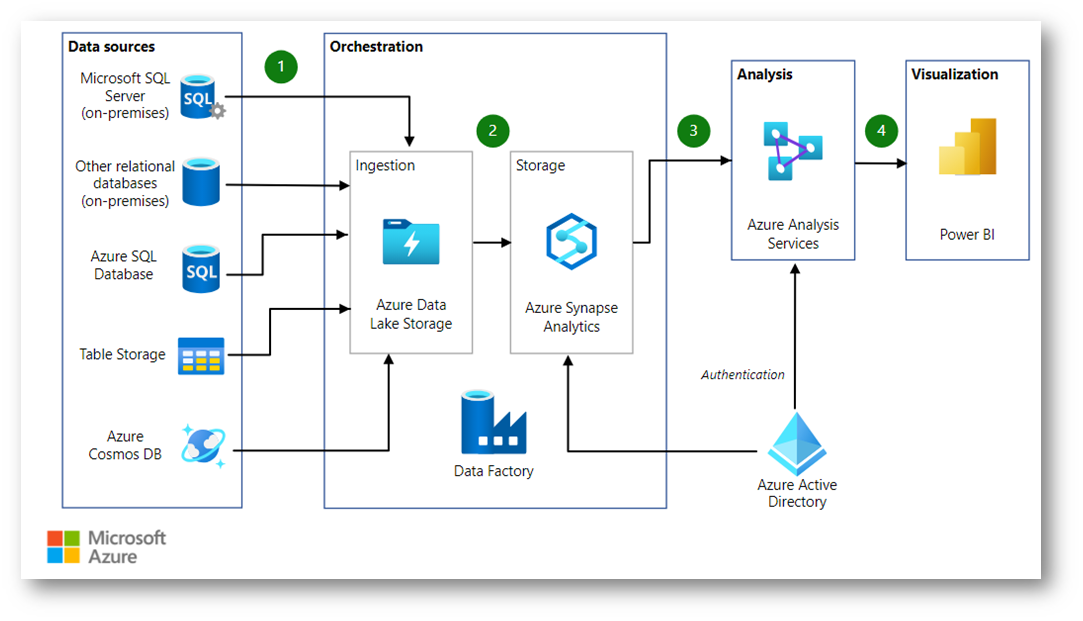
Figura 2: Utilizzo di Azure Data Lake
Differenze tra Azure Data Lake e Azure Blob storage
Questa è una domanda che molto spesso mi viene fatta a lezione: Che differenze ci sono tra Azure Data Lake e Azure Blob storage? Azure Data Lake Storage e Azure Blob Storage sono entrambi servizi di storage su cloud offerti da Azure, ma sono ottimizzati per scenari di utilizzo leggermente diversi.
Azure Data Lake Storage è una soluzione di storage basata su file system che è ottimizzata per analisi di big data e operazioni analitiche. È integrato con servizi di analisi di Azure come Azure Databricks, Azure HDInsight e Azure Synapse Analytics ed è progettato per operazioni ad alte prestazioni su grandi set di dati. Supporta operazioni di file system semantico come move/rename di directory, che sono essenziali per le operazioni di data lake e analytics. Inoltre, offre una gestione fine dei permessi a livello di file e directory.
Azure Blob Storage, d’altro canto, è ottimizzato per lo storage di grandi quantità di dati non strutturati o binari, come immagini, file audio, video e altri tipi di dati blob. Sebbene Blob Storage possa essere utilizzato per l’analisi dei dati e sia compatibile con l’interfaccia HDFS tramite Azure Data Lake Storage Gen2, è più comunemente usato per scenari come l’hosting di file per il download, lo streaming di contenuti multimediali, l’archiviazione di backup e di dati per disastri, e come endpoint di dati per applicazioni basate su cloud.
Quindi la differenza chiave tra i due servizi è il focus di Azure Data Lake Storage sull’analisi dei dati.
Azure Databricks – piattaforma di analisi unificata
Azure Databricks fornisce un ambiente per l’elaborazione dei dati, l’analisi e l’apprendimento automatico (Machine Learning) su larga scala. È progettato per semplificare il lavoro di data scientists, ingegneri dei dati e analisti, integrandosi strettamente con altri servizi di Azure per la gestione e la distribuzione dell’infrastruttura cloud. Questa integrazione consente agli utenti di lavorare con i loro dati senza doverli spostare in sistemi di archiviazione proprietari.
Con Azure Databricks è possibile collegare fonti di dati diverse a una singola piattaforma per processi come la programmazione e la gestione dei flussi di lavoro di elaborazione dei dati, la generazione di dashboard e visualizzazioni, la gestione della sicurezza e del recupero di emergenza e la scoperta e l’annotazione dei dati. Inoltre, supporta la modellazione Machine Learning, il tracciamento e il servizio dei modelli e la creazione di soluzioni di intelligenza artificiale generativa.
Come posso utilizzare Azure Databricks?
Immaginiamo che un’azienda farmaceutica desideri analizzare grandi volumi di dati provenienti da studi clinici per accelerare lo sviluppo di nuovi farmaci. Con Azure Databricks l’azienda può configurare rapidamente un ambiente di analisi per elaborare e analizzare questi dati.
Dopo aver creato un’istanza di Azure Databricks e aver creato un workspace, l’azienda lancia un cluster Spark, configurandolo per rispondere alle esigenze specifiche del carico di lavoro, come la capacità di memoria o la potenza di calcolo. Nell’ambiente Databricks, si crea un cluster Spark che sarà il motore di elaborazione dei dati. Questo può essere configurato per scalare automaticamente in base alle esigenze e può essere impostato per terminarsi automaticamente quando è inattivo, per risparmiare risorse.
Utilizzando i notebook di Databricks, l’interfaccia basata sul web di Databricks che consente di scrivere codice e visualizzazioni in vari linguaggi come Python, Scala, SQL e R, i data scientist dell’azienda possono scrivere e condividere codice in Python, Scala o SQL per eseguire analisi complesse. Possono, per esempio, importare i dati dei trial clinici, pulirli e trasformarli attraverso processi di ETL (Extract, Transform, Load), utilizzando le librerie di Apache Spark integrate per gestire efficientemente il preprocessing.
Una volta che i dati sono pronti, i ricercatori possono applicare modelli di machine learning per identificare correlazioni o per prevedere risultati di studi clinici, sfruttando le integrazioni di Databricks con MLflow (una piattaforma open source per la gestione del ciclo di vita di Machine Learning) per tracciare esperimenti, gestire il ciclo di vita dei modelli e servire modelli predittivi.
I risultati possono essere visualizzati e condivisi attraverso dashboard interattivi, permettendo agli stakeholder di vedere insight significativi e guidare decisioni basate sui dati. La collaborazione e la condivisione del lavoro all’interno del team sono semplificate grazie all’ambiente integrato che Databricks fornisce.
In questo esempio, Azure Databricks semplifica la gestione dell’infrastruttura per i data scientist, permettendo loro di concentrarsi sull’estrazione di valore dai dati piuttosto che sulla configurazione e manutenzione dell’ambiente di calcolo.
Nella figura sotto viene mostrata un’architettura dei dati moderna. Azure Databricks costituisce il nucleo della soluzione. Questa piattaforma funziona perfettamente con altri servizi, ad esempio Azure Data Lake Storage Gen2, Azure Data Factory, Azure Synapse Analytics e Power BI.
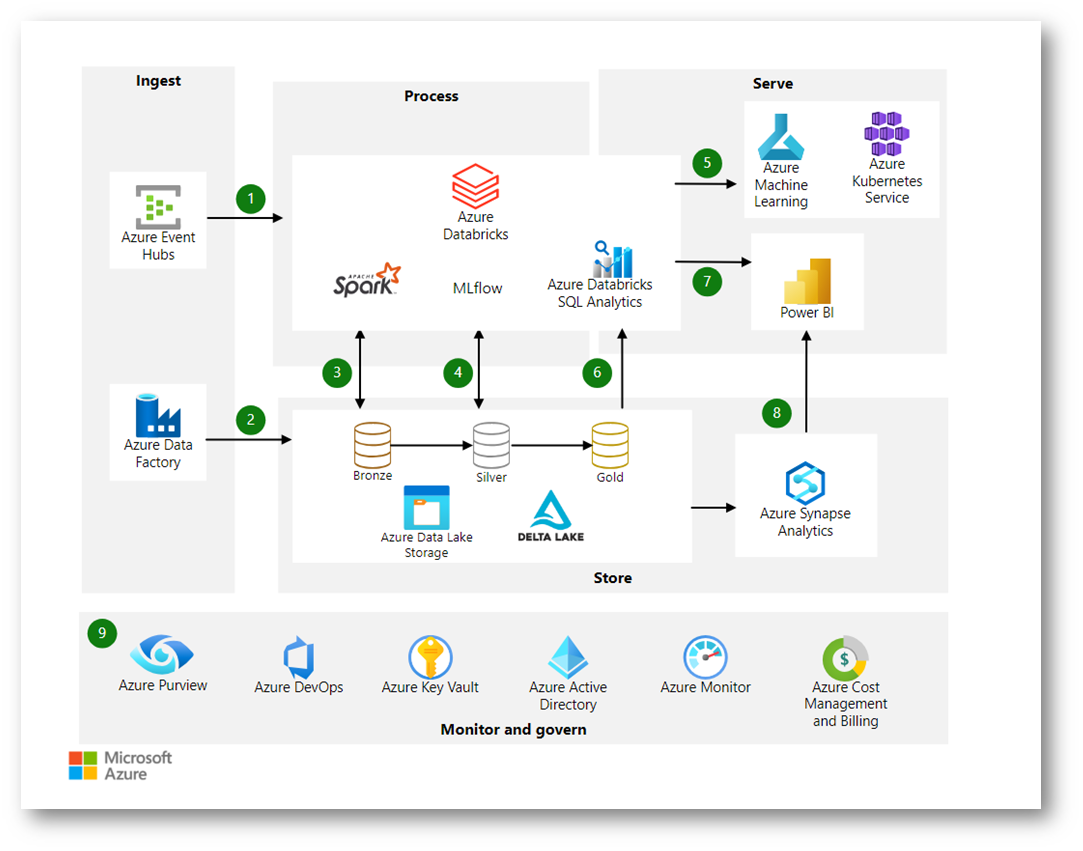
Figura 3: Architettura di analisi moderna con Azure Databricks
Azure Synapse Analytics – realizzazione di soluzioni di data warehousing e big data analytics
Azure Synapse Analytics è una piattaforma analitica integrata che fornisce strumenti avanzati per l’elaborazione e l’analisi dei dati su larga scala, unendo in un unico servizio le funzionalità di data warehousing avanzato e big data analytics. È stato concepito per accelerare il processo che porta dall’acquisizione del dato grezzo fino alla sua trasformazione in informazioni utili, facilitando così il processo decisionale basato sui dati.
La piattaforma si rivolge a diverse figure professionali come ingegneri dei dati, data scientist, analisti di business e sviluppatori, consentendo loro di collaborare su progetti di dati complessi. Azure Synapse permette di gestire e analizzare facilmente grandi volumi di dati, sfruttando sia capacità di query SQL distribuite su grandi set di dati, sia la potenza di Apache Spark per l’elaborazione di dati non strutturati e di big data.
Con la sua capacità di gestire la sicurezza e la privacy dei dati, Azure Synapse Analytics fornisce anche un ambiente sicuro in cui gestire queste analisi, assicurando la conformità con le normative vigenti e la protezione delle informazioni sensibili dei clienti.
Azure SQL Data Warehouse è stato rinominato in Azure Synapse Analytics per riflettere le sue capacità ampliate che vanno oltre il data warehousing tradizionale. Il cambio di nome segnala la trasformazione del servizio in una piattaforma che combina l’analisi dei big data con il data warehousing aziendale, consentendo di ottenere intuizioni da tutti i dati sia con risorse su richiesta serverless sia con risorse prenotate. Questo passaggio mira a unificare le esperienze di acquisizione, preparazione, gestione e fornitura di dati per esigenze immediate di business intelligence e machine learning, offrendo un approccio più comprensivo e integrato all’analisi dei dati.
Come posso utilizzare Azure Synapse Analytics?
Immaginiamo che un’azienda nel settore della vendita al dettaglio desideri migliorare l’efficienza della propria catena di approvvigionamento e delle vendite. Utilizzando Azure Synapse Analytics, l’azienda può inizializzare una piattaforma analitica per raccogliere dati provenienti da punti vendita, magazzini e piattaforme online.
L’azienda potrebbe quindi creare un ambiente di lavoro Synapse Studio per gestire il processo di elaborazione dati. Qui gli ingegneri dei dati potrebbero utilizzare un ambiente visivo senza codice per gestire i flussi di dati, mentre gli amministratori del database potrebbero automatizzare l’ottimizzazione delle query.
Con i dati raccolti, i data scientist dell’azienda potrebbero sviluppare modelli di machine learning per identificare i modelli di consumo e prevedere le tendenze future. Gli analisti aziendali, a loro volta, potrebbero accedere in modo sicuro ai set di dati e utilizzare Power BI per costruire dashboard in pochi minuti, tutto all’interno dello stesso servizio analitico.
Infine, l’azienda potrebbe utilizzare Azure Synapse Link per automatizzare il trasferimento dei dati dai database operativi senza processi ETL lunghi e laboriosi, ottenendo una visione end-to-end del proprio business. Questo permette di democratizzare (mi piace molto questa parola) l’accesso ai dati e portare il potere dell’analisi a ogni team connesso ai dati.
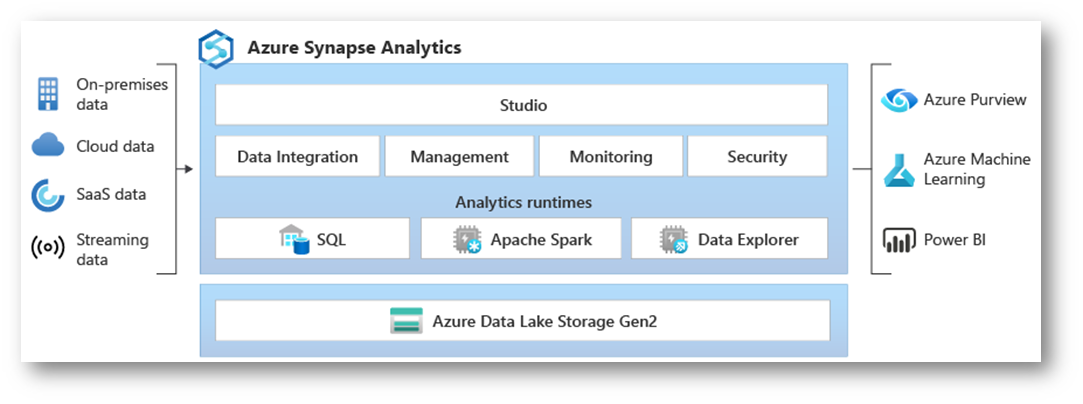
Figura 4: Azure Synapse Analytics
Differenze tra Azure Data Factory e Azure Synapse Analytics
Capita spesso che alcuni servizi di Azure facciano più o meno le stesse operazioni. Quindi la domanda nasce spontanea: Che differenze ci sono tra Azure Data Factory e Azure Synapse Analytics?
Azure Data Factory e Azure Synapse Analytics sono entrambi servizi di integrazione dei dati di Azure, ma sono ottimizzati per scopi leggermente diversi.
Azure Data Factory è principalmente un servizio di integrazione dei dati che consente di creare, pianificare e orchestrare flussi di lavoro di trasferimento dei dati (ETL o ELT) su larga scala. Come ho già scritto, è specializzato nell’automatizzazione dei flussi di lavoro per il trasferimento dei dati tra sorgenti diverse, nonché nella loro trasformazione e nel loro caricamento in un data warehouse o in un data lake.
Azure Synapse Analytics, d’altra parte, è una piattaforma di analisi integrata che combina l’elaborazione dei big data con il data warehousing aziendale. Offre capacità di data exploration, machine learning e gestione dei dati su vasta scala, oltre a funzionalità di business intelligence. Synapse può utilizzare i servizi di Azure Data Factory all’interno della sua piattaforma, ma estende le sue funzionalità per includere l’analisi dei dati e l’AI.
In pratica, potreste usare Azure Data Factory per preparare e trasferire i dati in Synapse, dove poi potreste eseguire analisi avanzate, query su vasta scala e applicare modelli di machine learning. Forte no?
E tra Azure Synapse Analytics e Azure databricks?
Azure Synapse Analytics e Azure Databricks sono entrambe delle piattaforme analitiche basate su cloud di Azure che offrono capacità di analisi dei dati, ma sono progettate per scopi diversi e hanno diverse ottimizzazioni.
Azure Synapse Analytics, come ho già scritto prima, è una piattaforma di analisi unificata che combina il data warehousing e l’analisi dei big data. È integrato profondamente con servizi Azure come Power BI e Azure Machine Learning e offre un ambiente per query SQL distribuite, elaborazione di big data con Apache Spark e servizi di esplorazione dei dati, nonché un’esperienza utente unificata per la gestione dei dati end-to-end.
Azure Databricks, invece, è una piattaforma basata su Apache Spark progettata principalmente per la data science e l’ingegneria dei dati. È ottimizzata per il machine learning e l’analisi collaborativa e offre una rapida configurazione di ambienti di calcolo distribuito, con una forte enfasi sull’analisi interattiva e sui processi iterativi.
In termini di utilizzo pratico, Synapse tende ad essere preferito per la gestione e l’analisi di dati a livello aziendale, inclusi i carichi di lavoro di data warehousing, mentre Databricks è spesso scelto per progetti di data science e analisi di dati complessi che richiedono capacità di elaborazione intensiva e algoritmi di machine learning avanzati.
Azure Stream Analytics – servizio di analisi in tempo reale
Azure Stream Analytics è un servizio di analisi che consente agli utenti di sviluppare ed eseguire analisi in tempo reale su molteplici flussi di dati. Questi dati possono provenire da una varietà di fonti, come dispositivi IoT, sensori, siti web, social media e altre applicazioni. Il servizio è progettato per processare grandi volumi di dati in streaming con latenze inferiori al millisecondo (wow!).
Il servizio utilizza un linguaggio di query simile a SQL con estensioni specifiche per l’elaborazione di eventi in streaming e arricchito con il supporto per la logica temporale, permettendo di identificare modelli e relazioni nei dati e di scatenare azioni come l’emissione di allarmi, l’alimentazione di strumenti di reporting o il salvataggio di dati trasformati per usi futuri.
Azure Stream Analytics è integrabile con altri servizi Azure per l’ingestione di dati in streaming, come Azure Event Hubs e Azure IoT Hub, oltre a poter collegare dati storici da Azure Blob storage. I dati trasformati e analizzati possono essere inviati a una varietà di destinazioni, come database SQL, laghi di dati, Power BI per visualizzazioni in tempo reale e molti altri.
È ottimizzato per la facilità d’uso e per la produttività degli sviluppatori e offre anche un editor senza codice per facilitare lo sviluppo di job di analisi in streaming. Essendo un servizio completamente gestito, gli utenti non devono preoccuparsi della gestione dell’infrastruttura sottostante. Il servizio è scalabile e flessibile, permettendo agli utenti di pagare solo per le unità di streaming consumate e di scalare su o giù i job in base alle esigenze del business. Azure Stream Analytics può anche essere eseguito direttamente su dispositivi IoT per analisi con latenza ultra-bassa attraverso Azure IoT Edge.
Azure Stream Analytics è ideale per un’ampia gamma di scenari di utilizzo, come il monitoraggio in tempo reale, la manutenzione predittiva, l’analisi del flusso di click dei clienti e molto altro, sostenendo carichi di lavoro critici e garantendo affidabilità, sicurezza e conformità a livello aziendale.
Come posso utilizzare Azure Stream Analytics?
Supponiamo che un’azienda di trasporti voglia monitorare la condizione dei suoi veicoli in tempo reale per prevenire guasti e ottimizzare la manutenzione. Con Azure Stream Analytics, l’azienda può raccogliere dati telemetrici dai sensori dei veicoli in movimento, come la temperatura del motore, la velocità, l’usura dei freni e la pressione degli pneumatici.
Utilizzando Azure Stream Analytics, l’azienda configura un job di streaming per processare questi dati in tempo reale. I dati telemetrici vengono inviati continuamente a Stream Analytics tramite Azure Event Hubs. Il job di streaming esegue query su questi flussi di dati, utilizzando il linguaggio di query di Stream Analytics per identificare anomalie come un aumento inaspettato della temperatura del motore o una pressione anormalmente bassa dei pneumatici.
Quando viene rilevata un’anomalia, Azure Stream Analytics può scatenare allarmi automatici che avvisano il personale di manutenzione. Contemporaneamente, i dati possono essere inoltrati a un database o a un’applicazione di analisi per una valutazione più approfondita e per storicizzare l’informazione. Inoltre, i risultati dell’analisi in tempo reale possono essere visualizzati su un dashboard di Power BI, fornendo alla direzione e agli operatori una vista immediata dello stato della flotta e delle prestazioni dei veicoli.
In questo modo, Azure Stream Analytics aiuta l’azienda a mantenere la sua flotta efficiente e ridurre i tempi di fermo non pianificato, trasformando i dati in streaming in intuizioni operative che possono guidare decisioni rapide e informate.
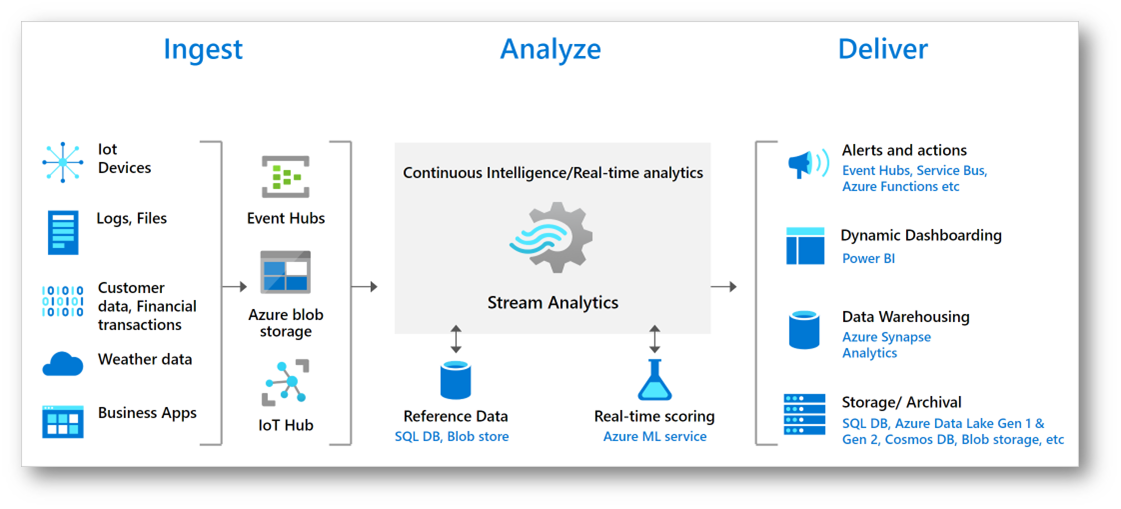
Figura 5: Azure Stream Analytics
Appendice – Che cos’è Apache Spark e a cosa serve
Cos’è Apache Spark
Più volte in questo articolo è stato citato Apache Spark. Apache Spark è un framework open-source progettato per l’elaborazione distribuita di grandi quantità di dati (Big Data). È nato come evoluzione del paradigma MapReduce di Hadoop, con l’obiettivo di migliorare performance, semplicità d’uso e flessibilità.
Spark permette di suddividere un carico di lavoro su più nodi (cluster) ed eseguire operazioni di calcolo in parallelo in modo efficiente.
È noto per le sue alte prestazioni, che derivano principalmente dall’elaborazione in memoria (in-memory) e dalla capacità di gestire carichi di lavoro complessi come l’elaborazione batch, lo streaming di dati, il machine learning e l’analisi di grafi.
In pratica, Spark fornisce un “motore di calcolo distribuito” capace di eseguire analisi, trasformazioni e processi complessi su dataset di grandi dimensioni che non potrebbero essere gestiti da un singolo server.
Per cosa viene utilizzato Spark
Spark viene tipicamente impiegato in contesti che richiedono:
- Elaborazione massiva di dati – trasformazioni su dataset molto grandi (Big Data).
- Analisi batch o near-real-time – reportistica, aggregazioni, ETL massivi.
- Machine Learning scalabile – tramite la libreria MLlib.
- Stream processing – elaborazione di flussi di dati in tempo reale.
- Data preparation – pulizia e trasformazione dei dati per data warehouse e data lake.
Conclusioni
I servizi di integrazione dei dati di Azure offrono una suite completa e potente per gestire, trasformare e analizzare grandi volumi di dati in diversi scenari aziendali.
Azure Data Factory è un servizio essenziale per l’integrazione dei dati che consente di orchestrare e automatizzare complessi flussi di lavoro di ETL/ELT. È particolarmente adatto per la preparazione e il trasferimento dei dati tra varie sorgenti e destinazioni.
Azure Data Lake fornisce una soluzione scalabile di storage di dati su Azure, ottimizzata per l’analisi di big data. Integra capacità di storage massivo con accesso ai servizi di analisi, essendo un punto di forza per le aziende che richiedono un rapido accesso ai dati per l’analisi.
Azure Databricks è una piattaforma basata su Apache Spark che facilita l’analisi dei big data e l’apprendimento automatico. Con i suoi ambienti di notebook interattivi e l’integrazione con altri servizi Azure, è lo strumento ideale per la collaborazione e la data science.
Azure Synapse Analytics estende le capacità del data warehouse tradizionale unendo l’analisi dei big data e il data warehousing in una piattaforma di analisi unificata. Fornisce potenti strumenti analitici e di gestione dei dati, integrandosi strettamente con servizi come Power BI e Azure Machine Learning.
Azure Stream Analytics è specializzato nell’analisi di flussi di dati in tempo reale, permettendo di raccogliere, processare e visualizzare dati streaming per insight immediati e azioni tempestive. È un servizio chiave per scenari come il monitoraggio in tempo reale e l’analisi predittiva.
Insieme, questi servizi coprono l’intero spettro del viaggio dei dati: dalla loro cattura e integrazione con Azure Data Factory, allo storage e analisi avanzata con Azure Data Lake e Azure Databricks, fino alla gestione dei dati end-to-end e insight aziendali con Azure Synapse Analytics e l’analisi di flussi di dati in tempo reale con Azure Stream Analytics. Questa suite completa permette alle aziende di sfruttare i dati per guidare la trasformazione digitale e prendere decisioni basate sui dati in modo più efficace.