
Azure Local: Disaster Recover con Azure Site Recovery
Azure Site Recovery è una soluzione avanzata per la protezione dei carichi di lavoro su macchine virtuali, consentendo la replica e il ripristino in caso di guasti o interruzioni. Questo servizio di Azure aiuta a minimizzare i tempi di inattività e a mantenere la continuità operativa dell’infrastruttura aziendale, garantendo un rapido recupero in situazioni critiche.
Azure Local è una estensione dell’ecosistema Azure che permette, tramite una infrastruttura iperconvergente, di eseguire carichi di lavoro direttamente nei data center on-premises, mantenendo al contempo l’integrazione con il cloud pubblico di Microsoft.
Nelle precedenti guide dedicate alle due tecnologie abbiamo imparato a conoscerle, ora è giunto il momento di capire come possono essere integrate garantendo una situazione di continuità operativa basata su un ambiente on-prem replicato in cloud, pronto a una eventuale emergenza.
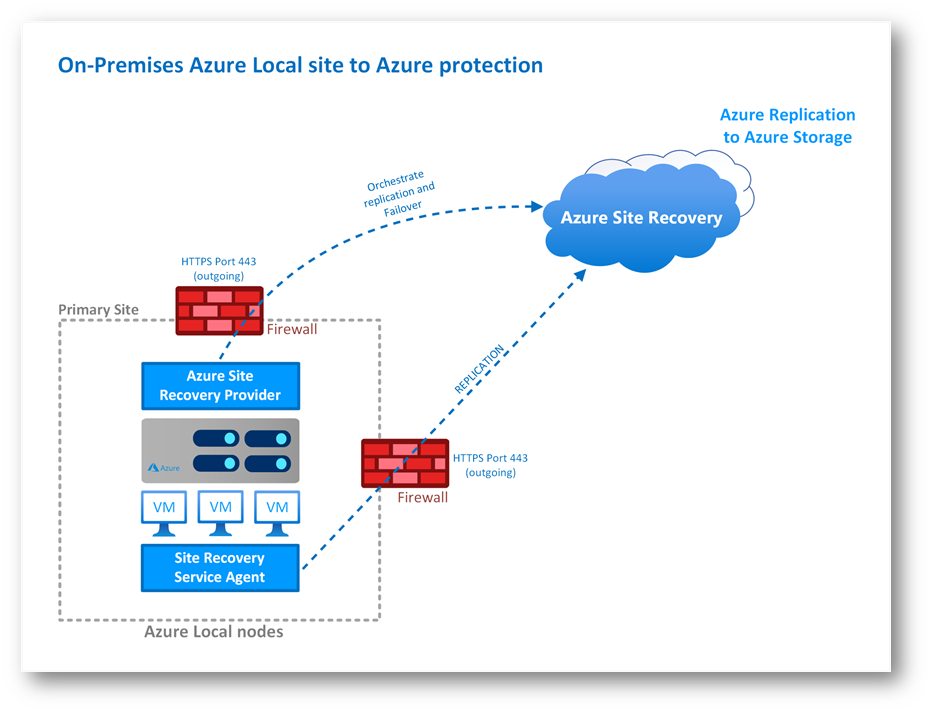
Figura 1: Architettura Azure Local to Azure
Uno degli elementi essenziali nella definizione delle strategie di Disaster Recovery è il network, è importante decidere come collegarci ai nostri servizi a fronte di una situazione di disastro.
Per quanto riguarda gli indirizzamenti pubblici possiamo dire che, chiaramente, gli IP non possono essere riportati su Azure, quindi, in base allo scenario aziendale, andrà fatta una analisi specifica.
Relativamente agli IP interni abbiamo due opzioni:
- Mantenere gli stessi IP
- Utilizzare IP differenti
Anche in questo caso la scelta dipenderà dai sistemi presenti in azienda e come sono stati implementati. Potremmo, ad esempio, avere degli applicativi con IP hard-coded che ci costringeranno a riportare gli IP delle nostre istanze senza cambiamenti rispetto al sito sorgente.
Fatte le basilari premesse relative al network possiamo procedere con la creazione del Resource Group di DR e alle relative VNET e Subnet.
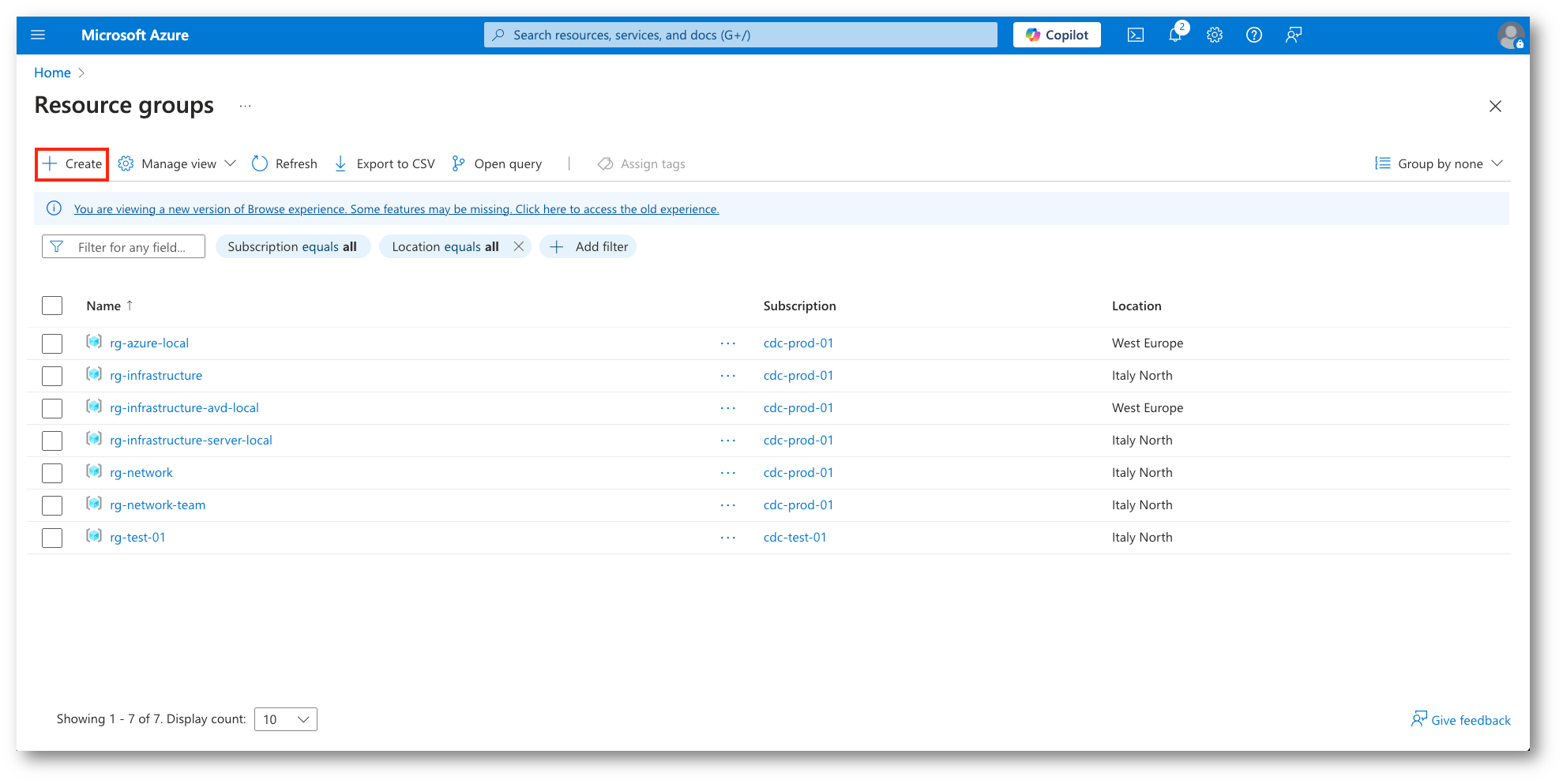
Figura 2: Creazione di un nuovo Resource Group
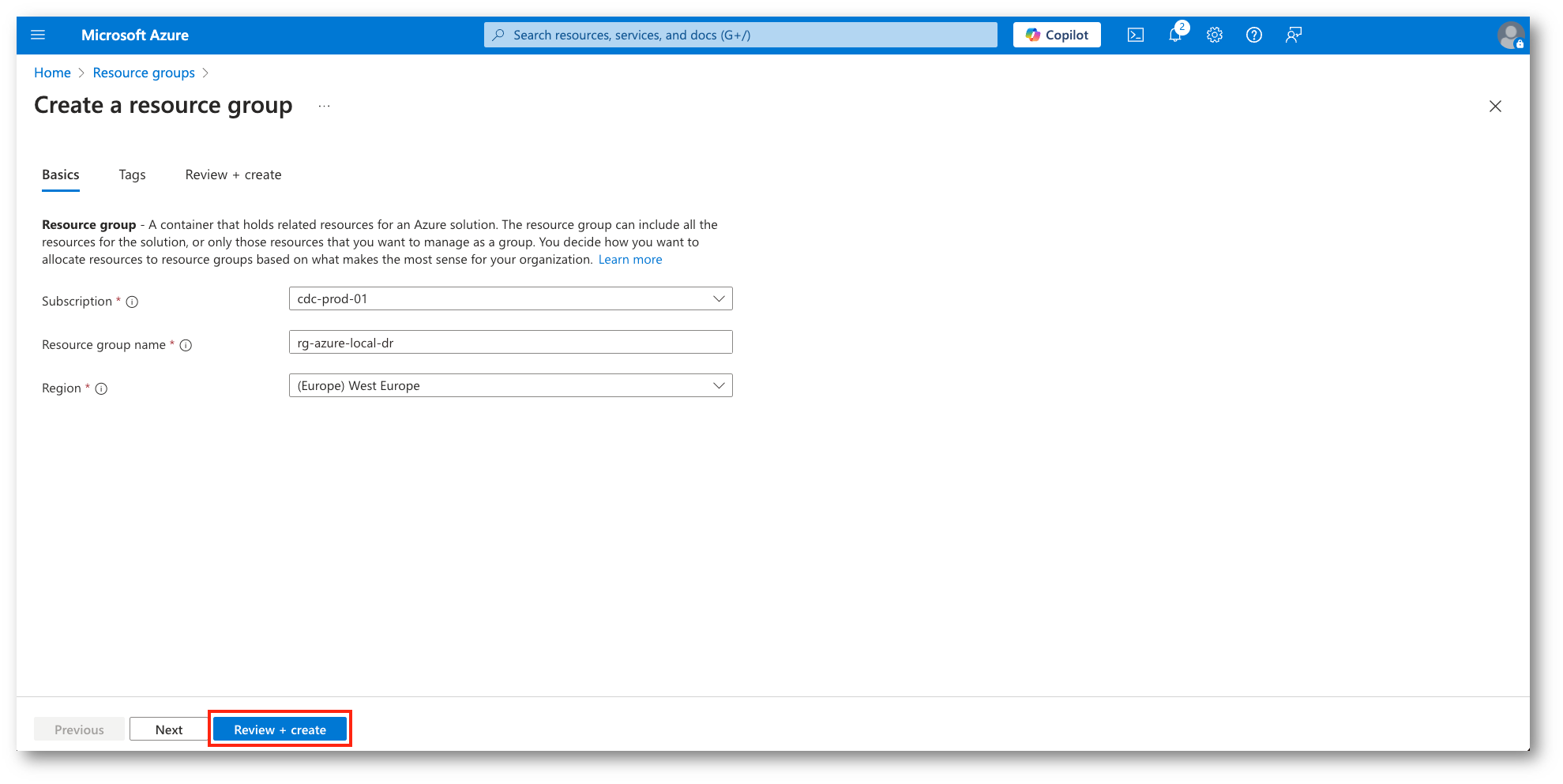
Figura 3: Nome e Regione del nuovo RG
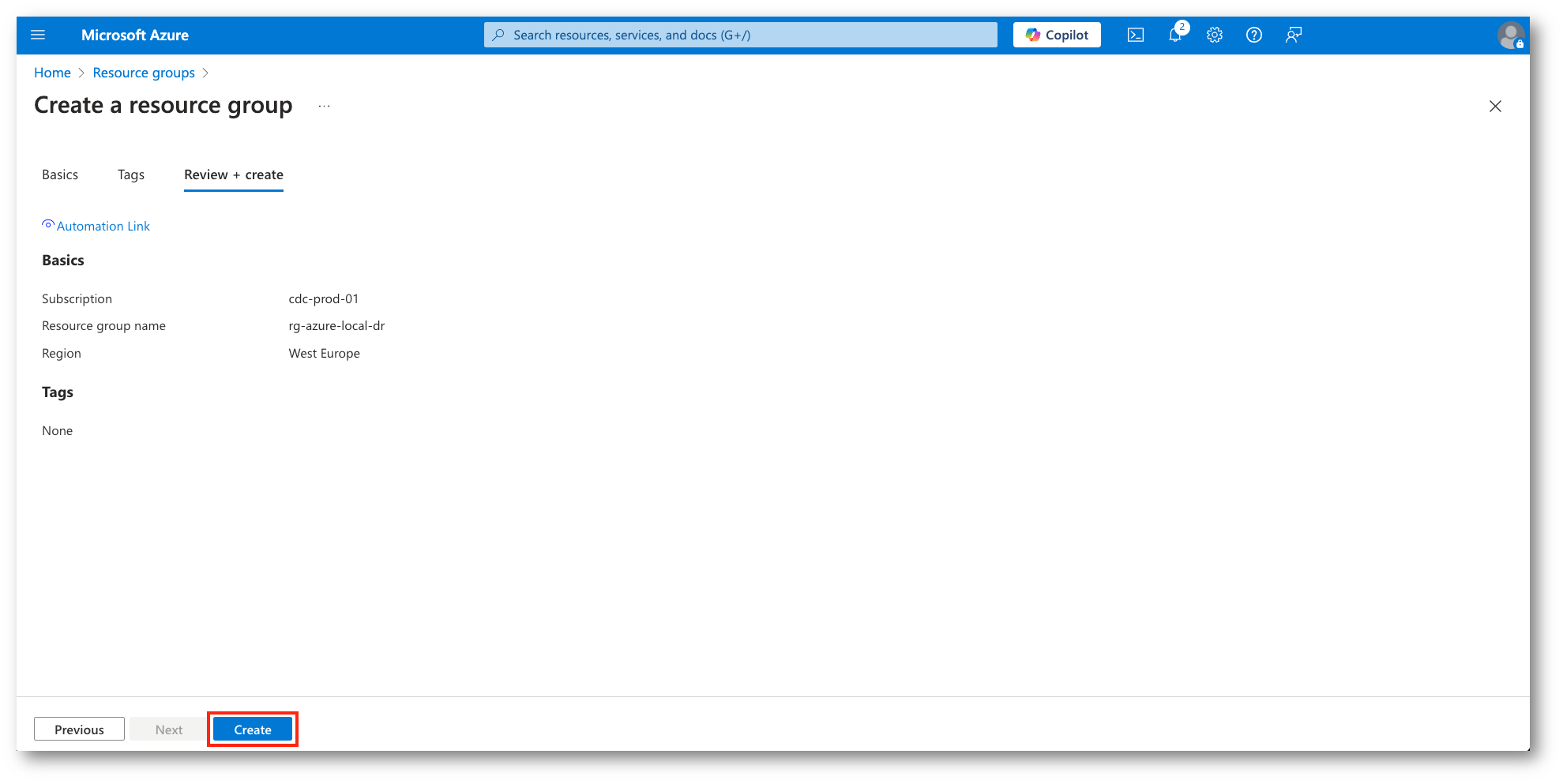
Figura 4: Conferma e creazione del RG
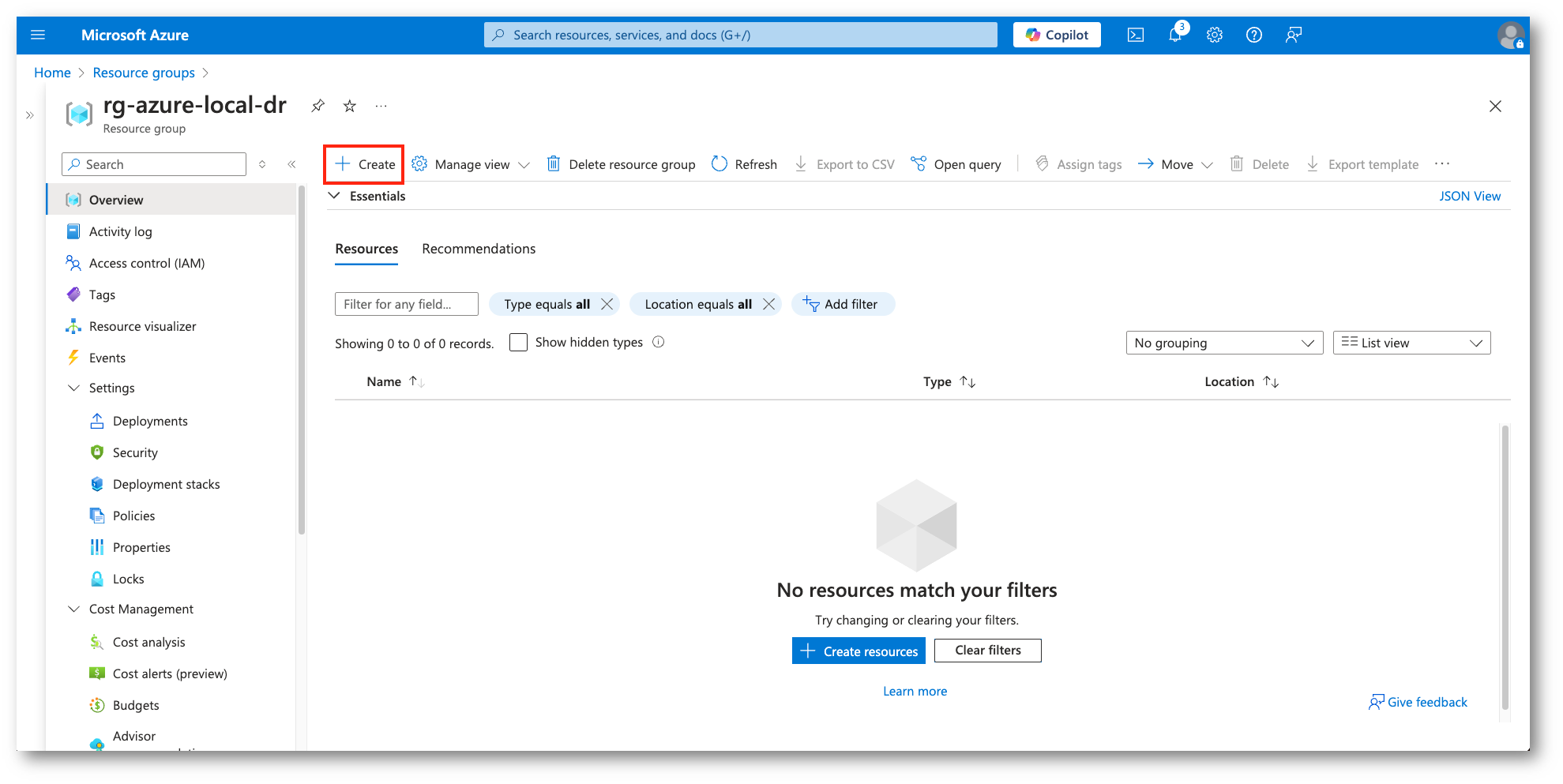
Figura 5: Creazione nuova risorsa
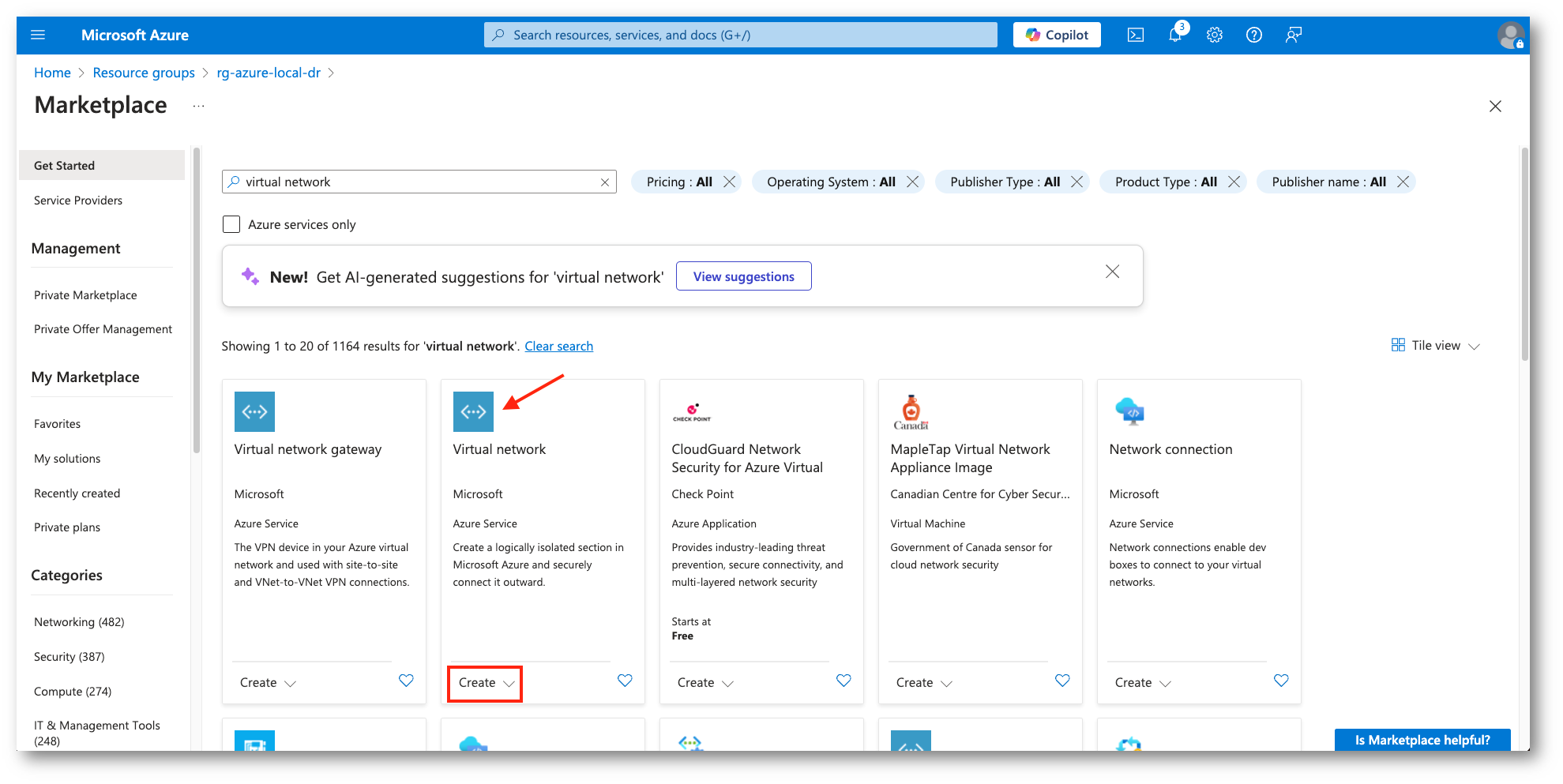
Figura 6: Creazione nuova VNET
Una volta assegnato il nome alla VNET dovremo creare un Address Space e una Subnet da associare alle istanze che replicheremo (potremo avere anche più di una Subnet).
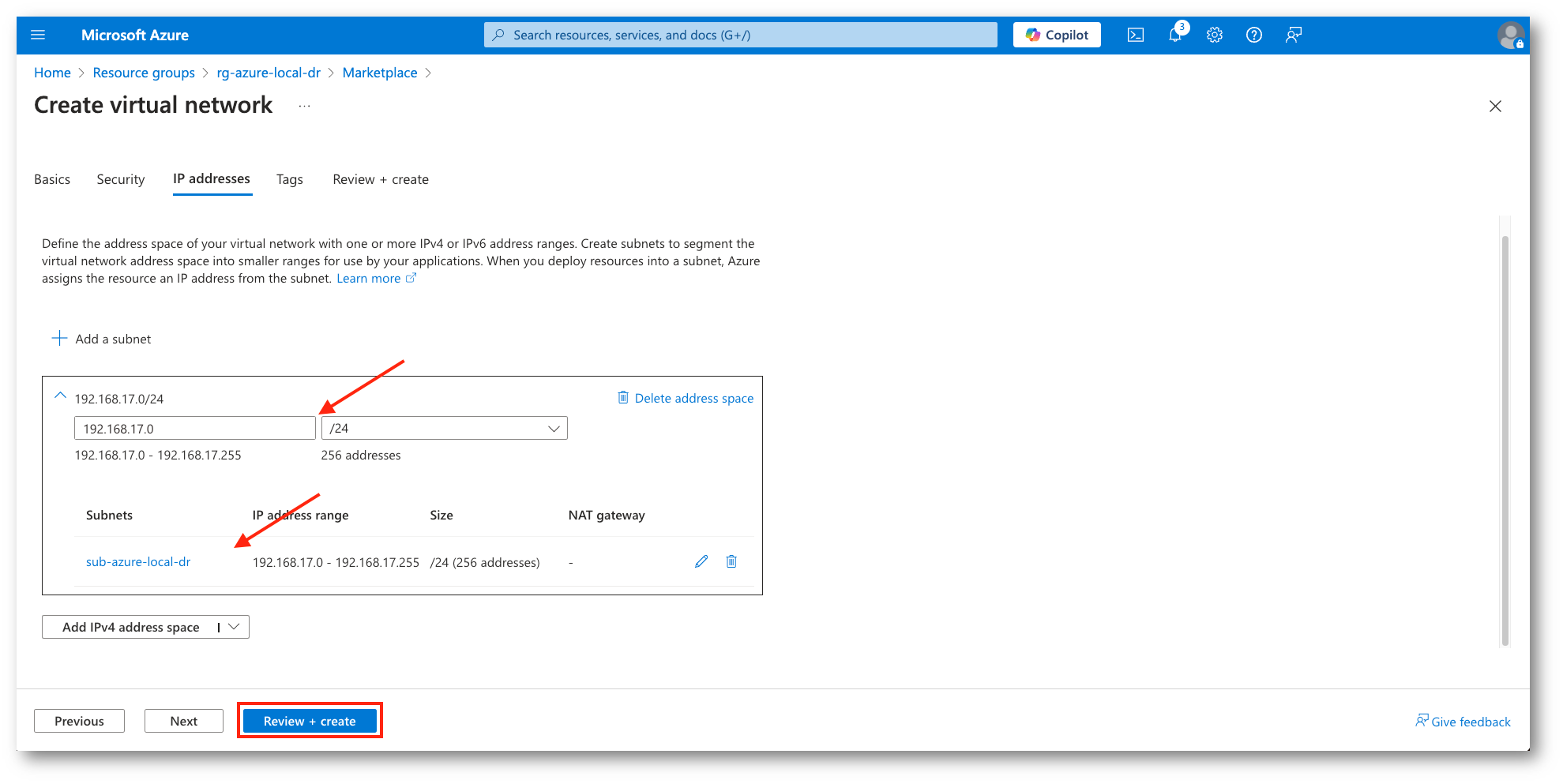
Figura 7: Creazione Virtual Network e Subnet
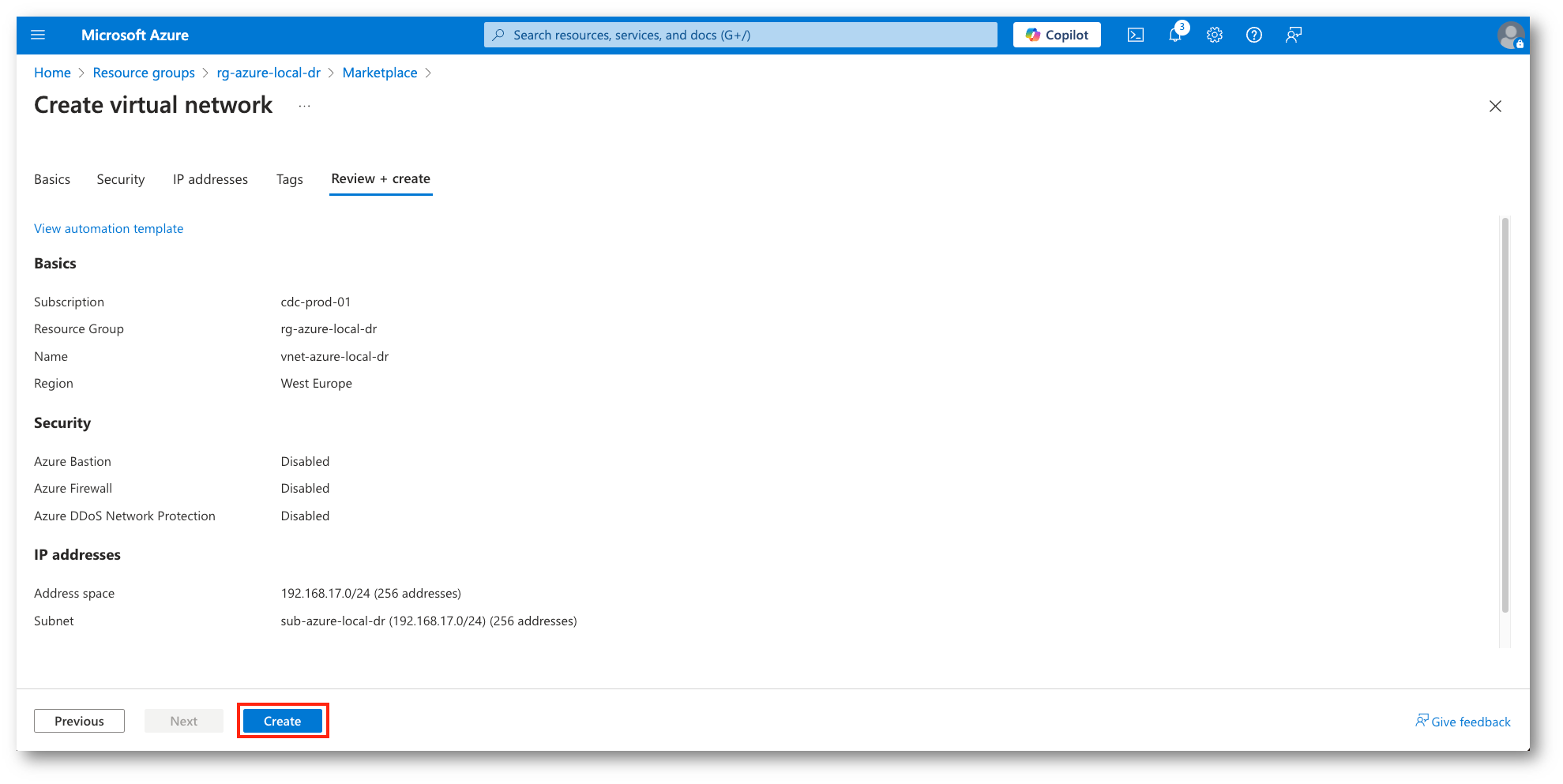
Figura 8: Conferma e creazione VNET
Configurazione replica e protezione
È giunto il momento di preparare il Cluster di Azure Local per utilizzare i servizi di Disaster Recovery di Azure.
Microsoft è riuscita a rendere le operazioni di configurazione estremamente semplici e automatizzate, durante i prossimi step verranno creati:
- Recovery Service Vault
- Sito Hyper-V (su cui si basa Azure Local)
- Replication Policy
Partendo dalla sezione preposta alla gestione di Azure Local nell’Azure Portal, possiamo iniziare.
In questo esempio è presente una sola virtual machine ma la procedura sarebbe la medesima anche in presenza di un maggior numero di istanze.
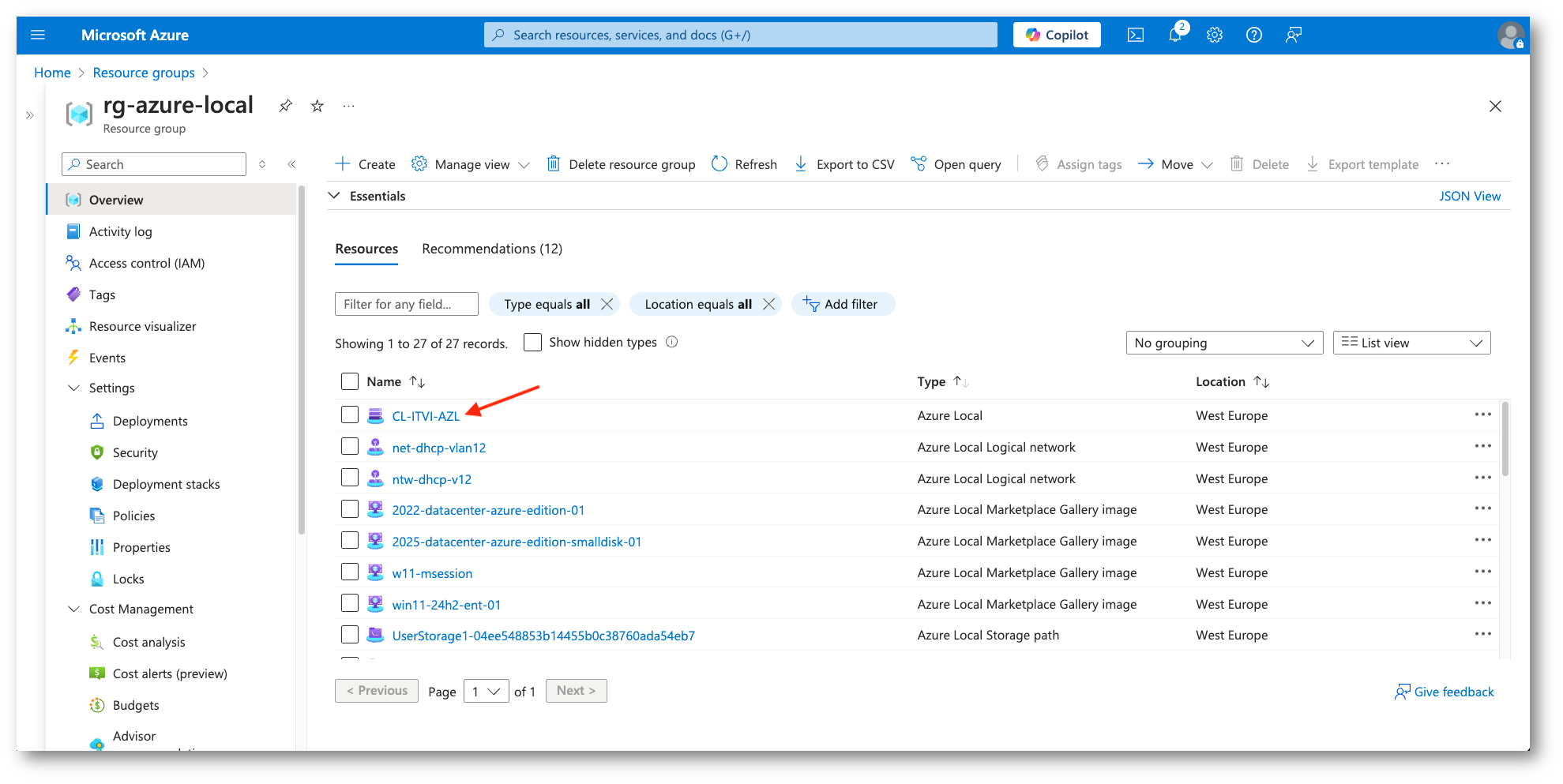
Figura 9: Selezione Cluster per cui attivare la protezione
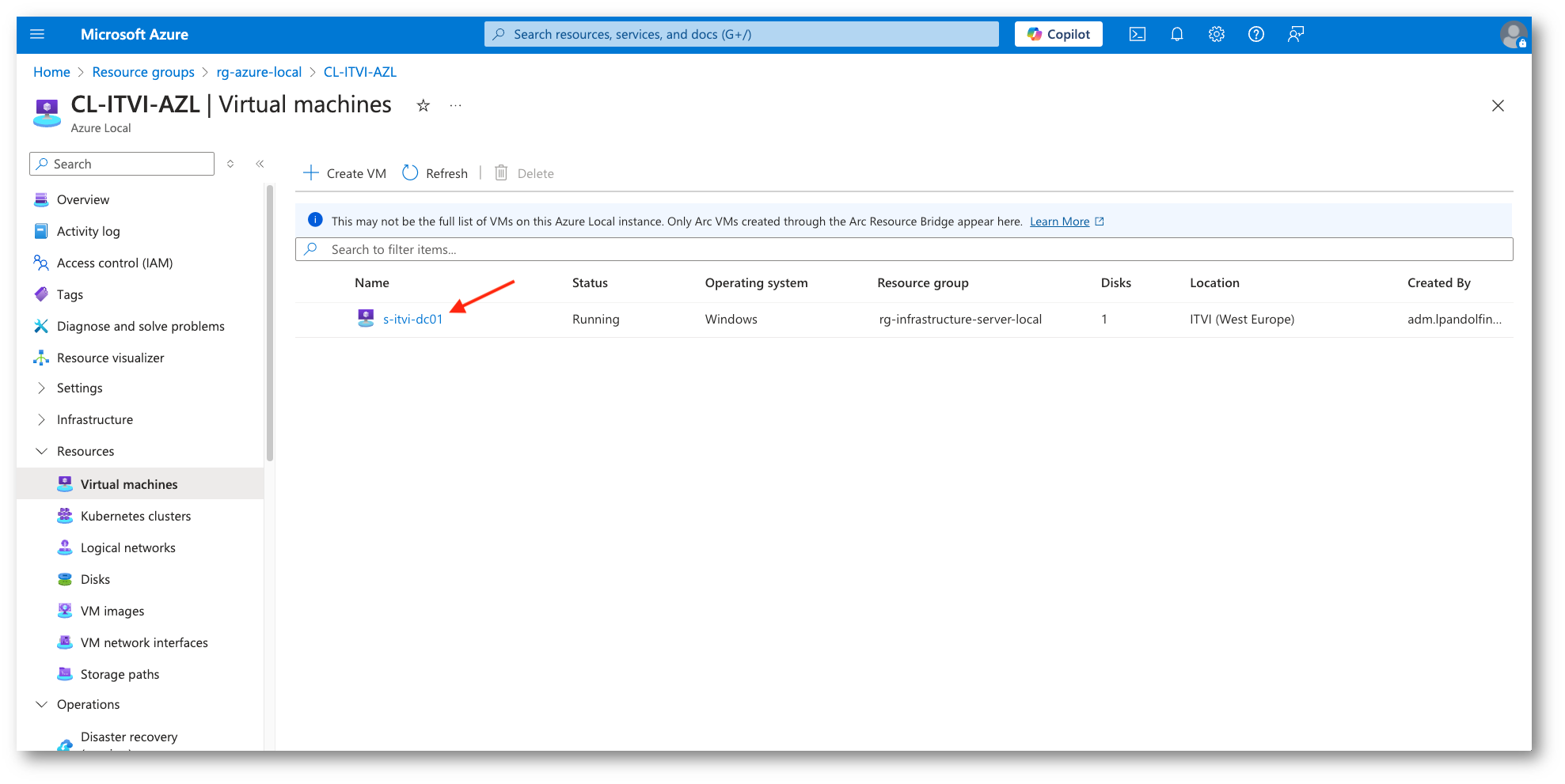
Figura 10: Virtual Machine in ambiente di laboratorio
Verificata la presenza della macchina virtuale da proteggere andiamo scorriamo il menu di sinistra per selezionare l’opzione di Disaster Recovery. Da questa sarà possibile iniziare il processo di protezione, creando tutte le risorse (menzionate sopra) necessarie.
Va sottolineato che la funzionalità, nel momento in cui sto scrivendo, è in Preview, la procedura potrebbe, quindi, subire delle modifiche.
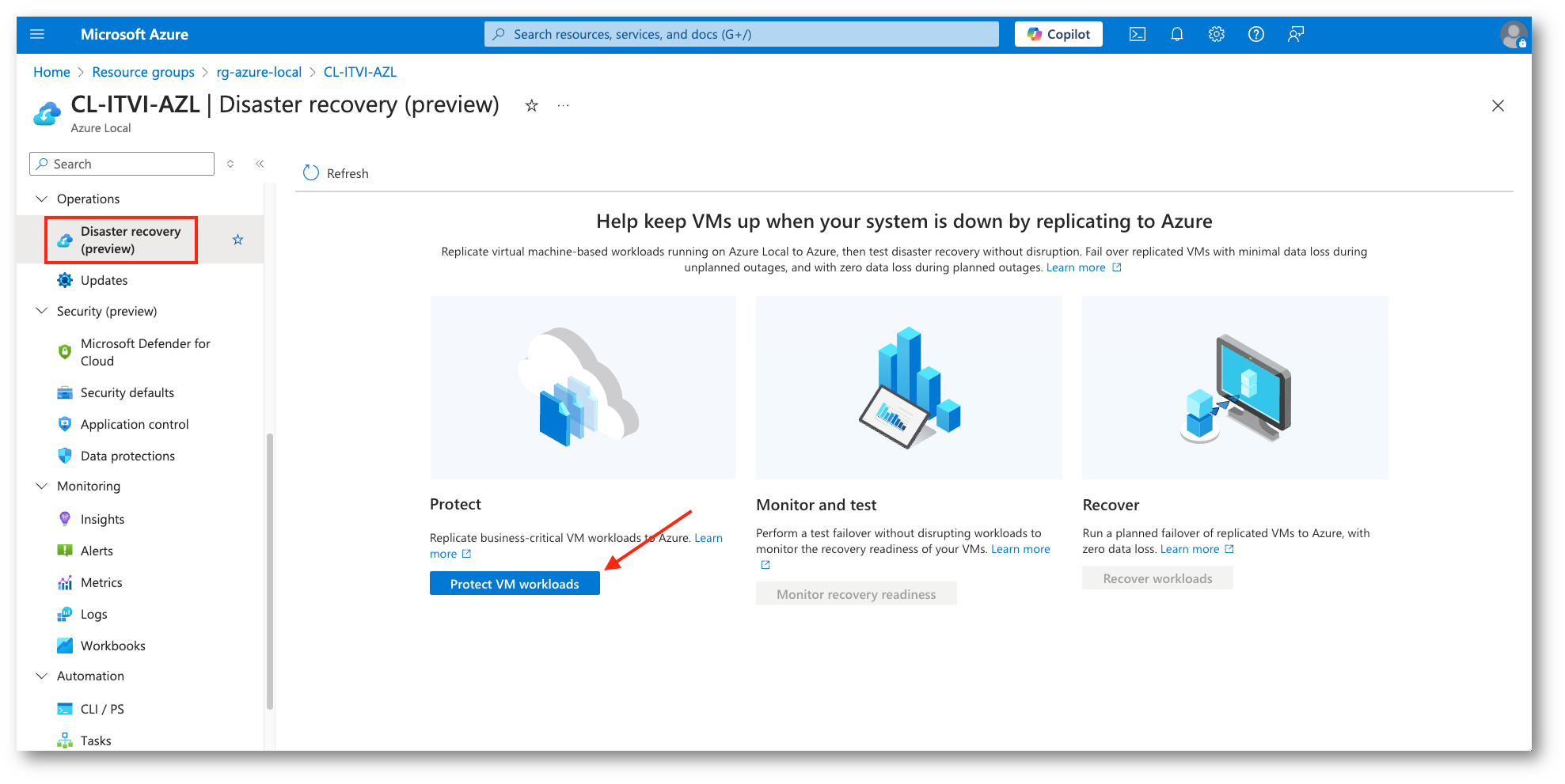
Figura 11: Protezione dei workload
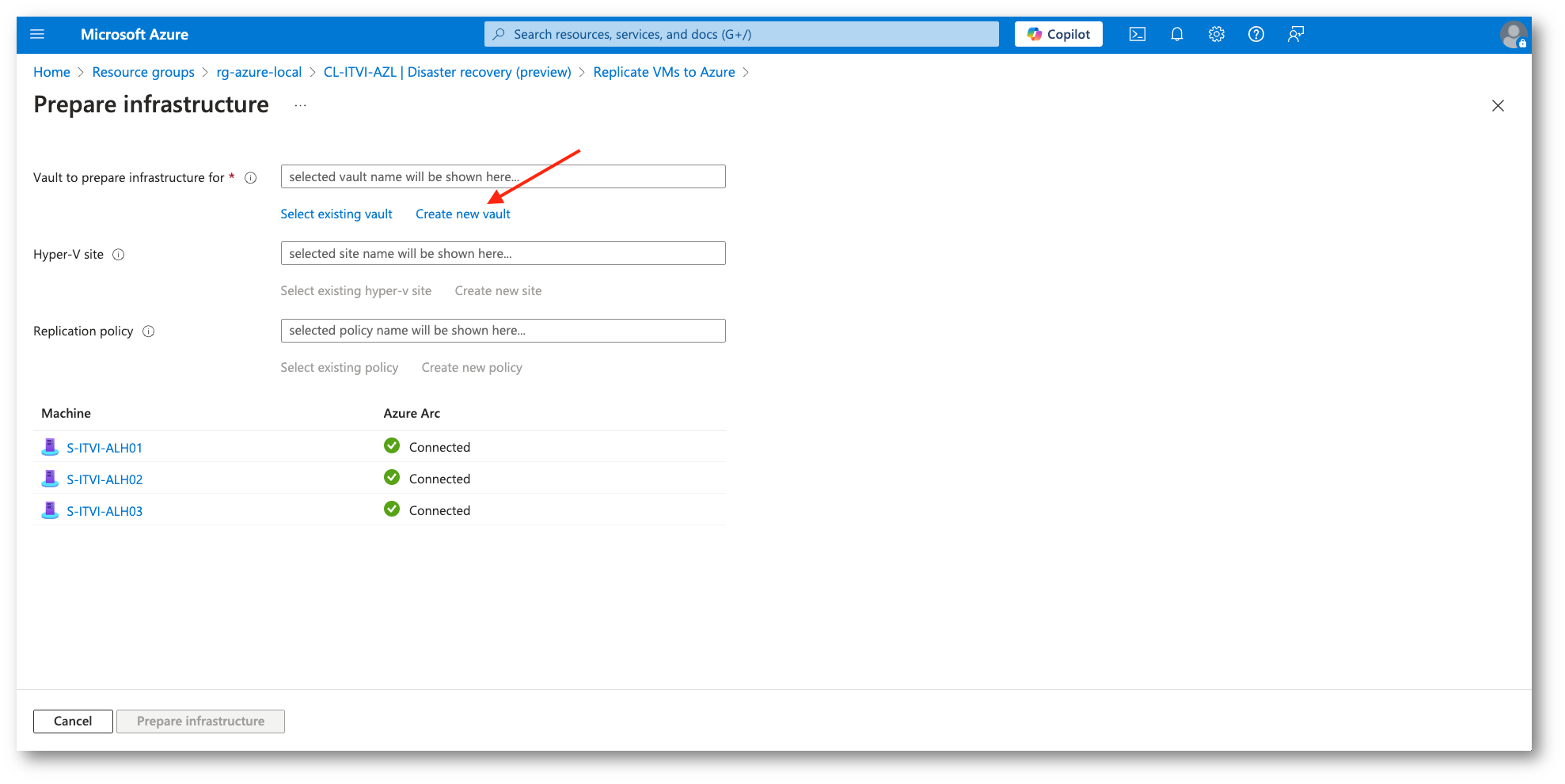
Figura 12: Creazione delle risorse necessarie
Nella creazione delle risorse utilizzeremo sempre le impostazioni di default, potreste avere necessità di configurazioni diverse che, comunque, potranno eventualmente essere modificate in un secondo momento.
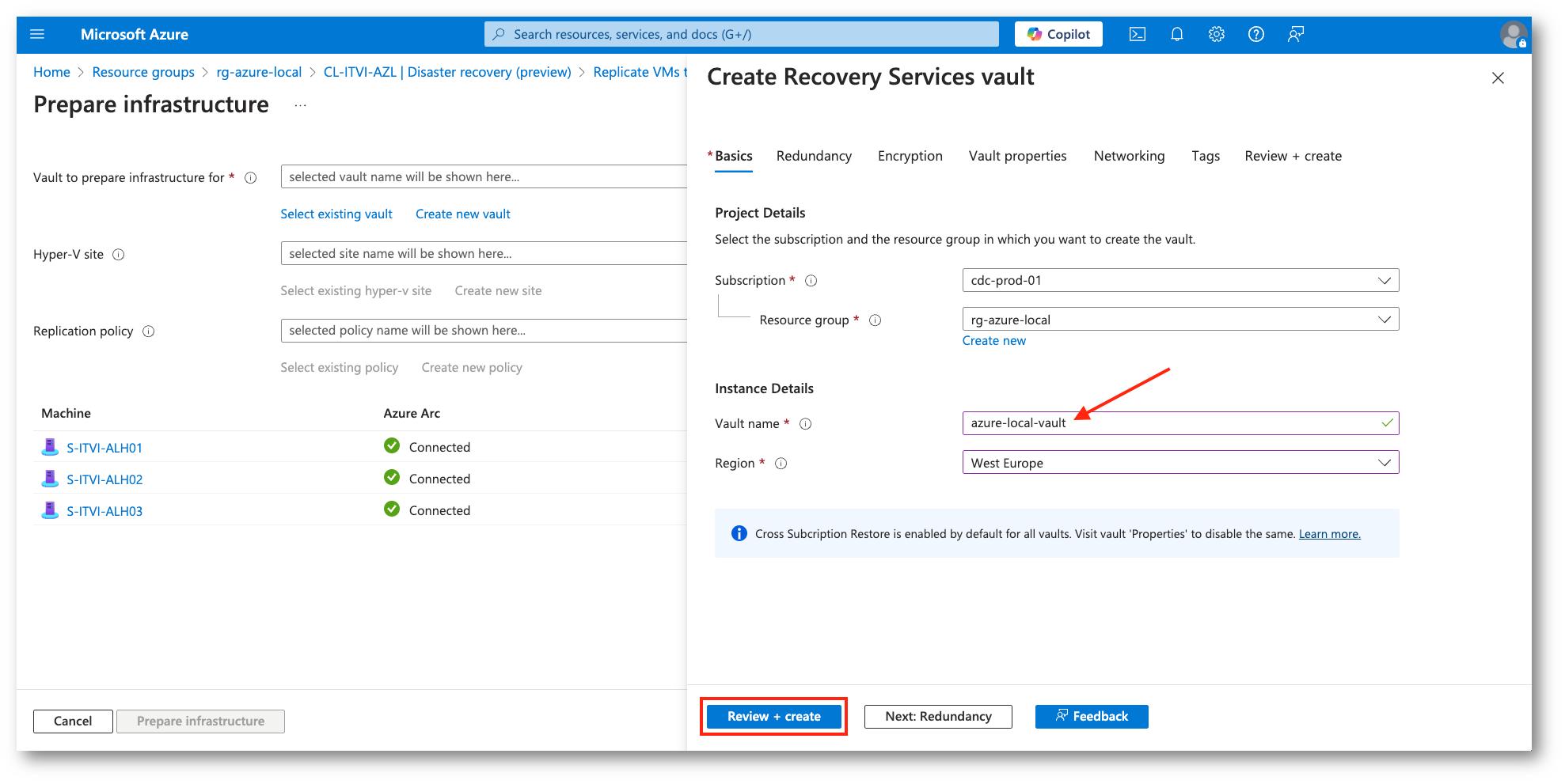
Figura 13: Parametri del Recovery Service Vault
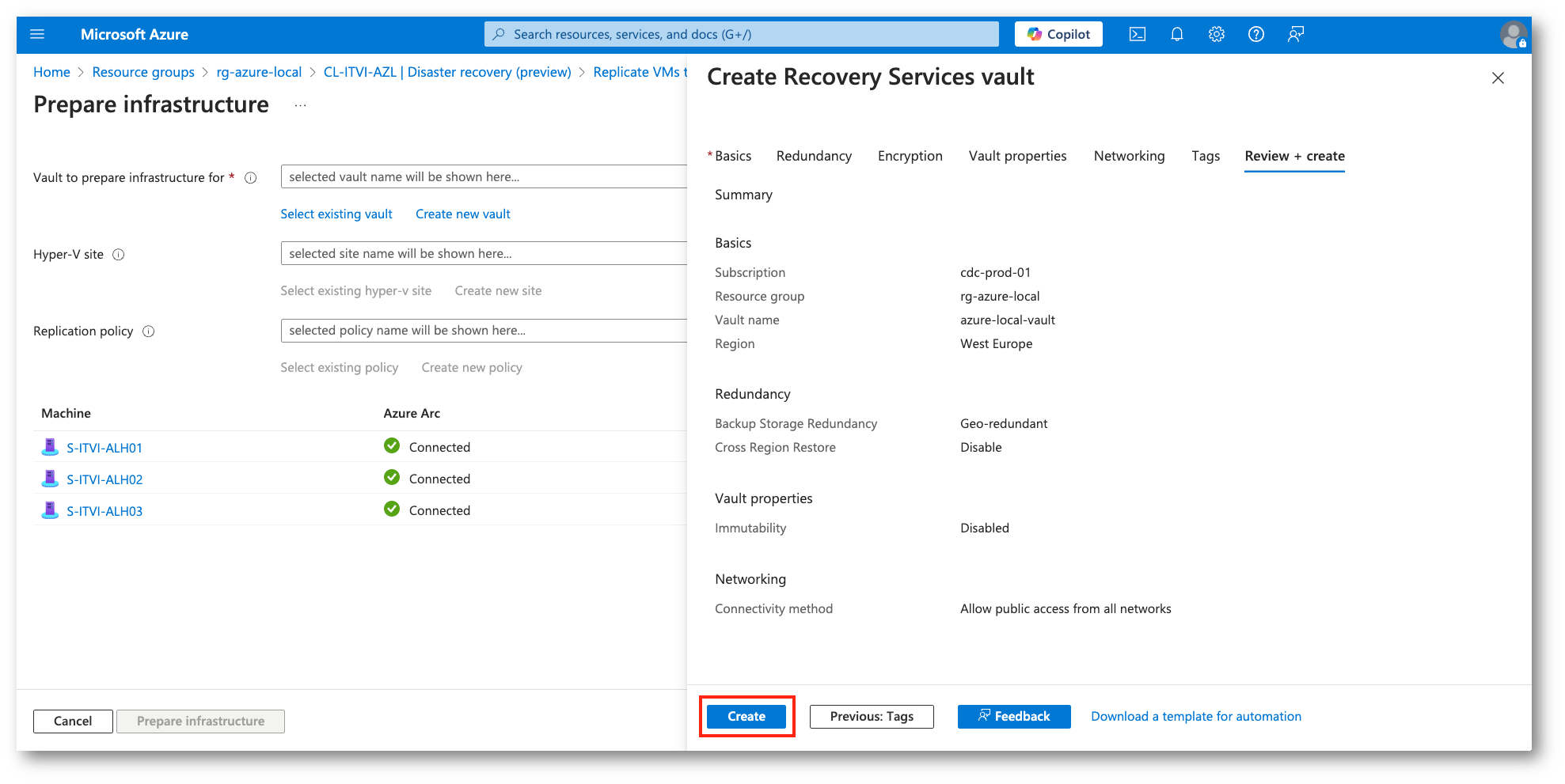
Figura 14: Creazione del Recovery Service Vault
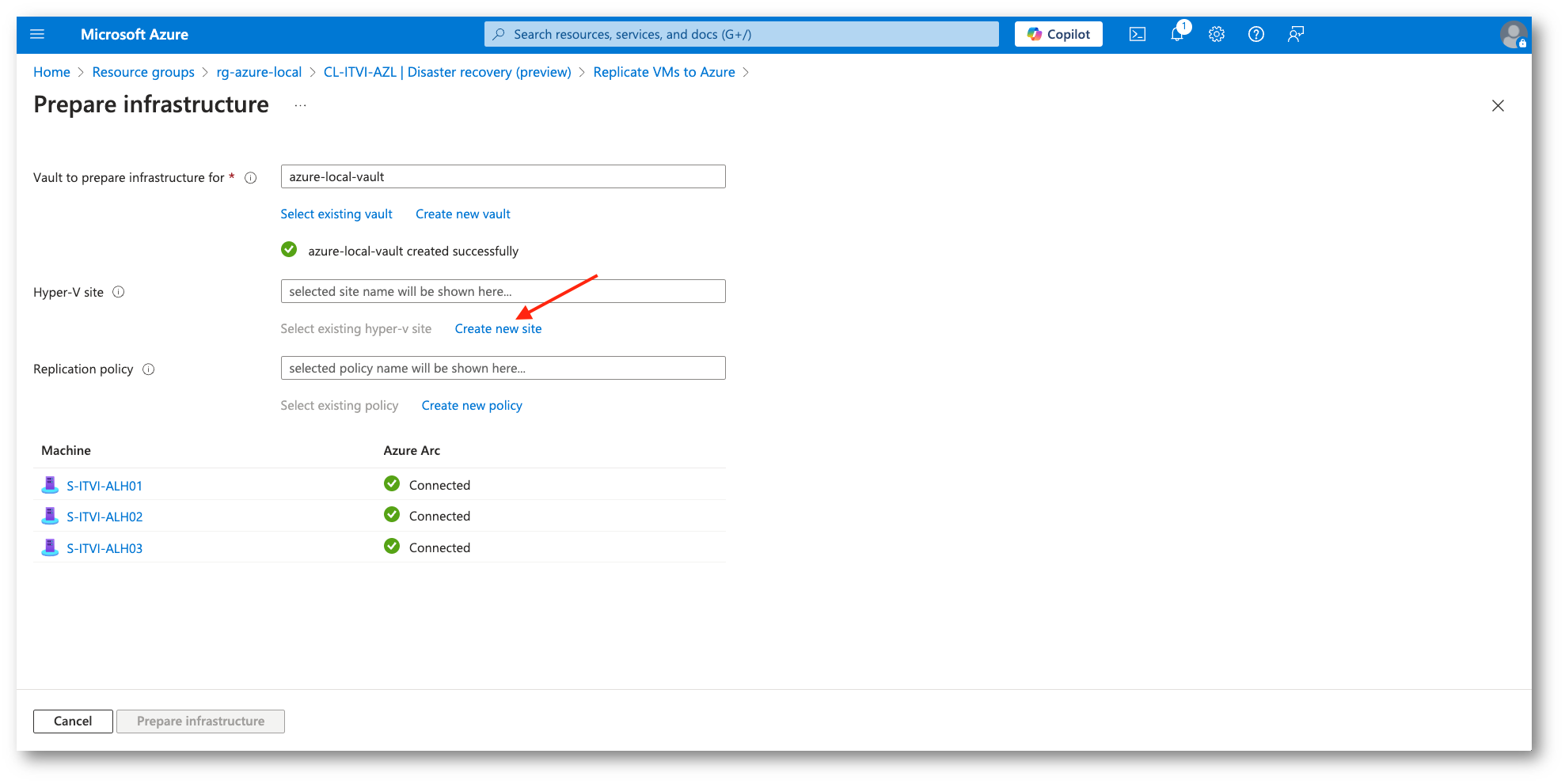
Figura 15: Creazione Hyper-V Site
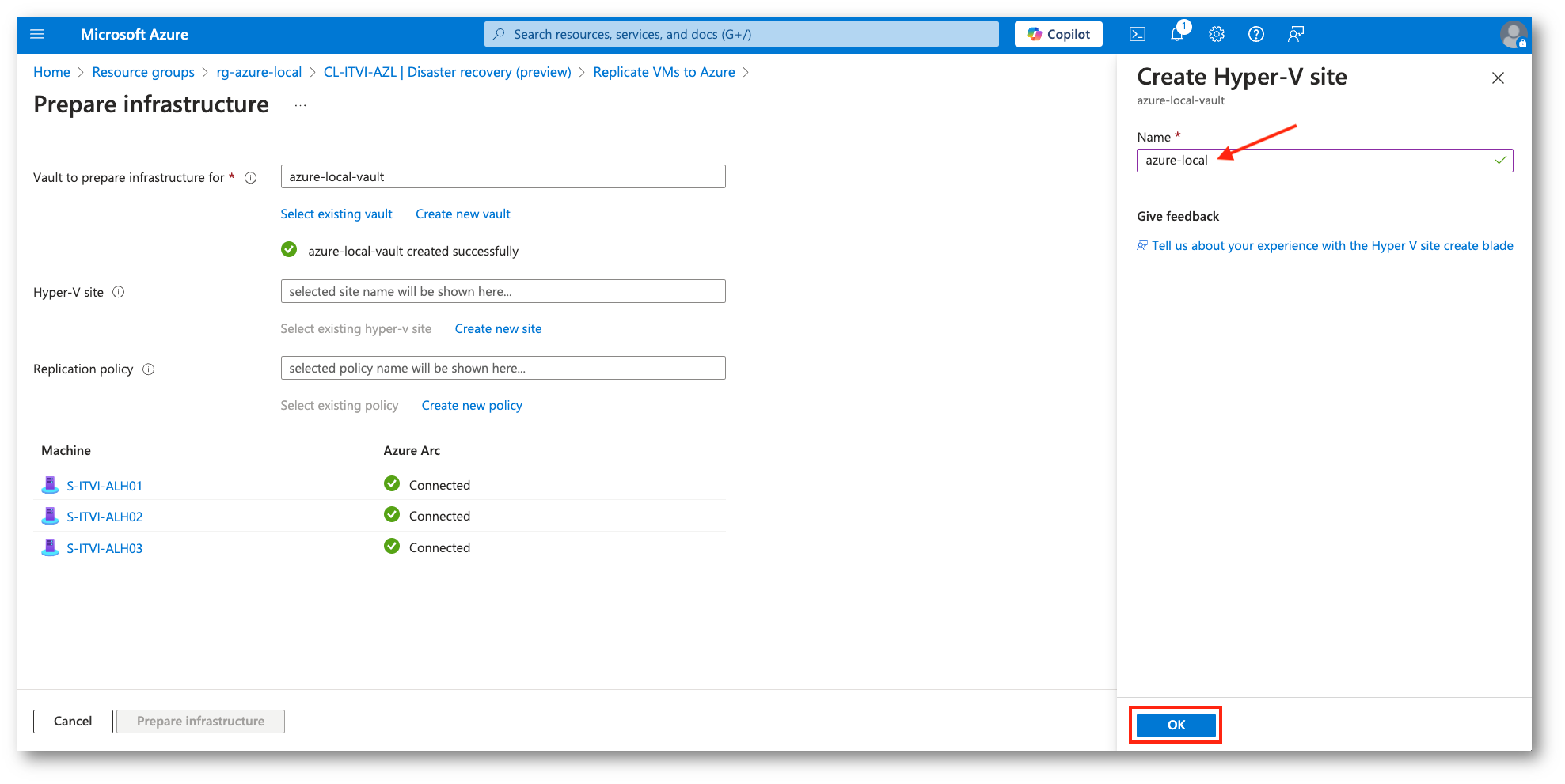
Figura 16: Assegnazione nome al sito Hyper-V
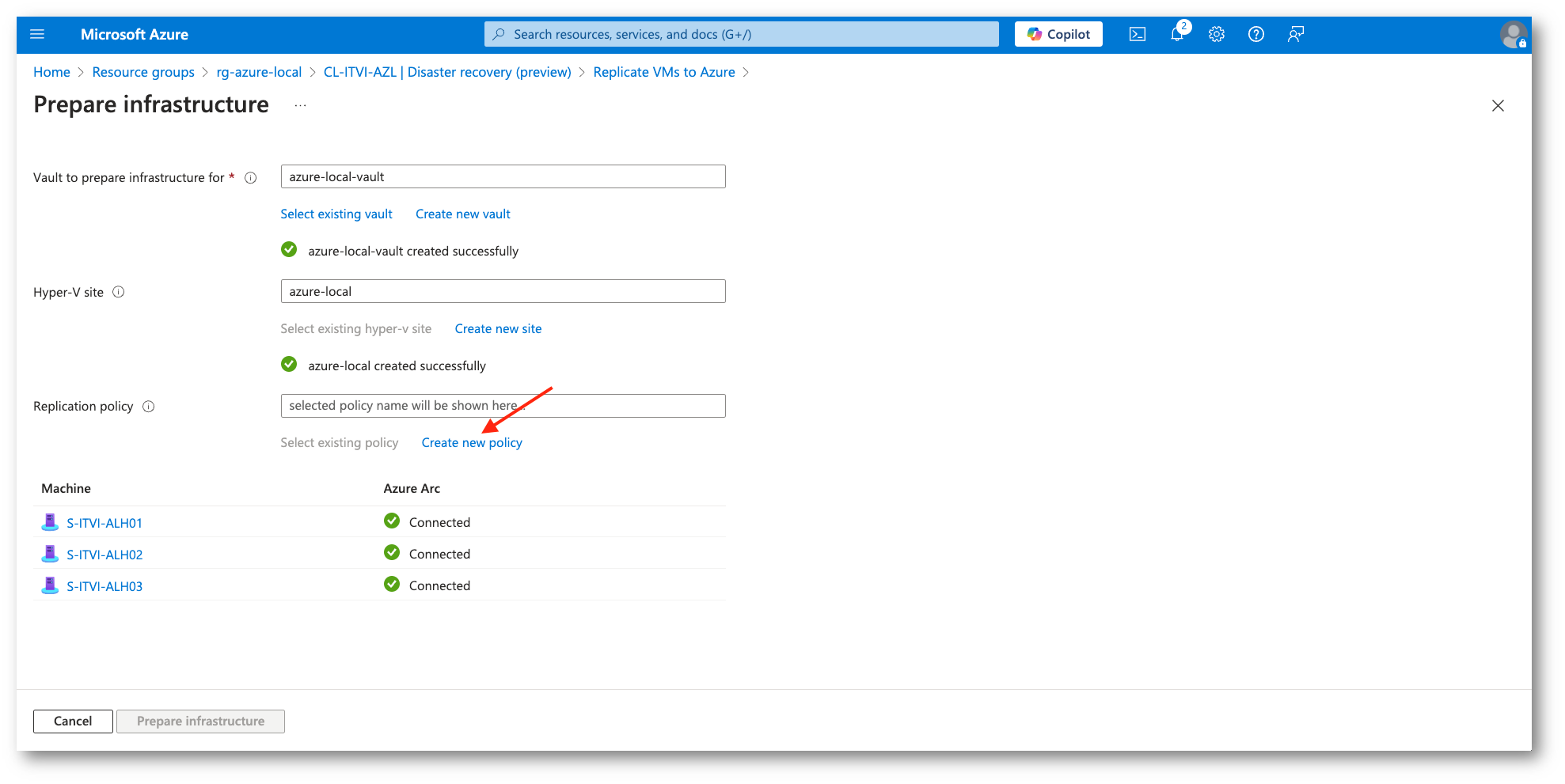
Figura 17: Creazione policy di Replica
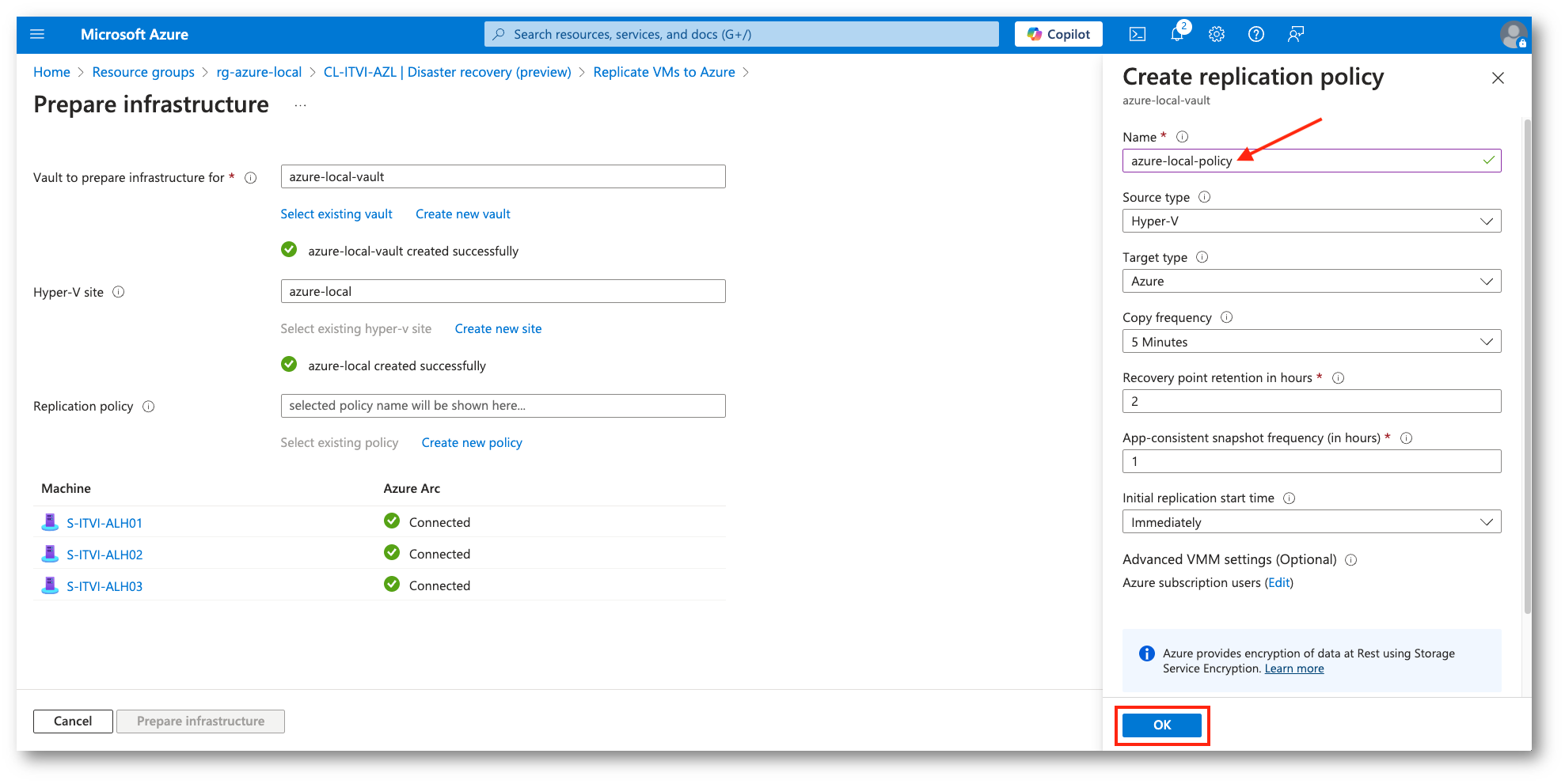
Figura 18: Impostazione delle policy di replica
Terminate creazione e configurazione delle risorse di base, verranno installati sui nodi le estensioni necessarie (ASRExtension) e gli Agent utili alle operazioni di Replica.
Solo dopo questo passaggio potremo iniziare a proteggere i nostri Workload tramite il processo di Replica.
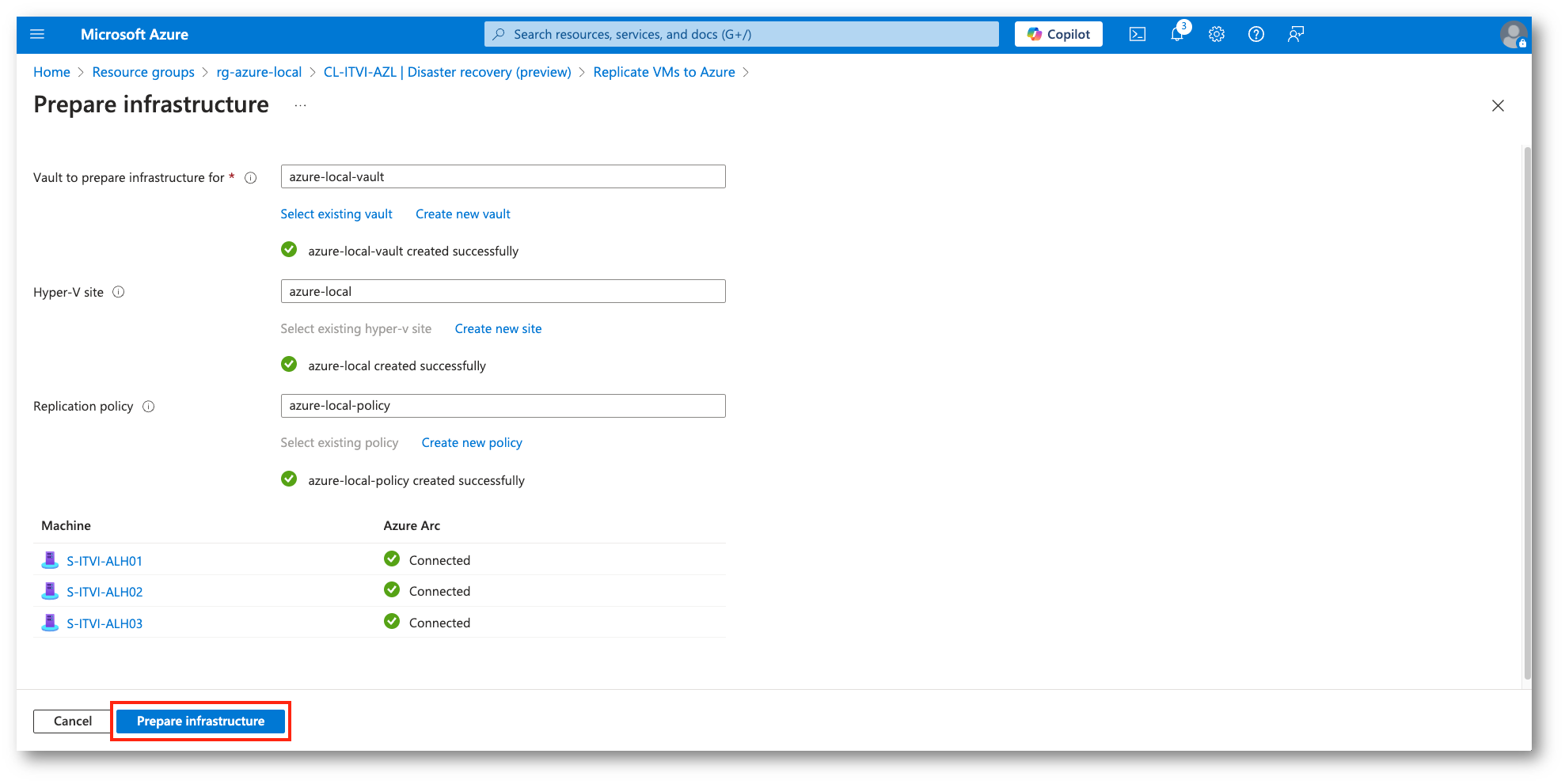
Figura 19: Preparazione della infrastruttura
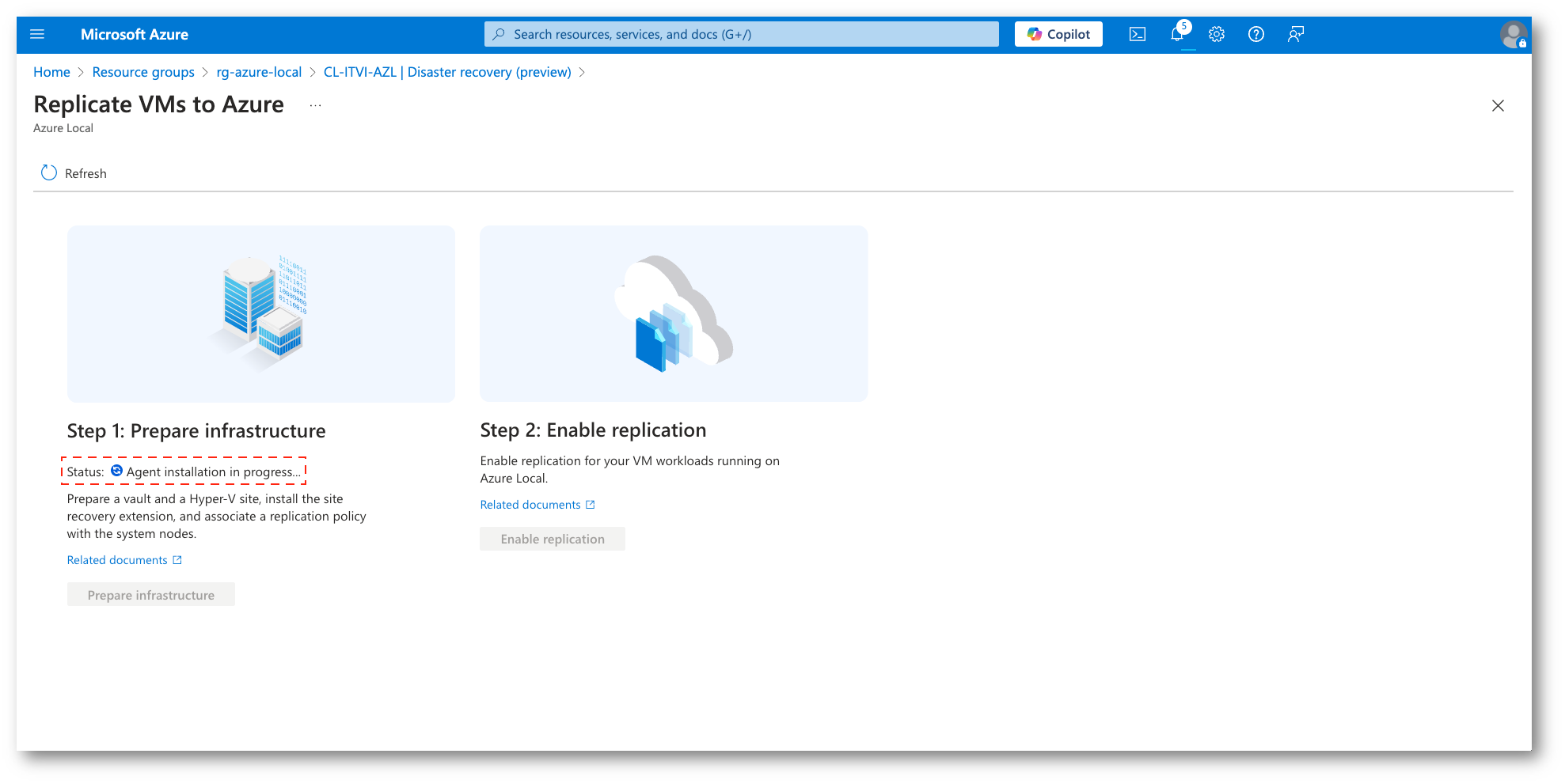
Figura 20: Installazione automatica delle estensioni necessarie
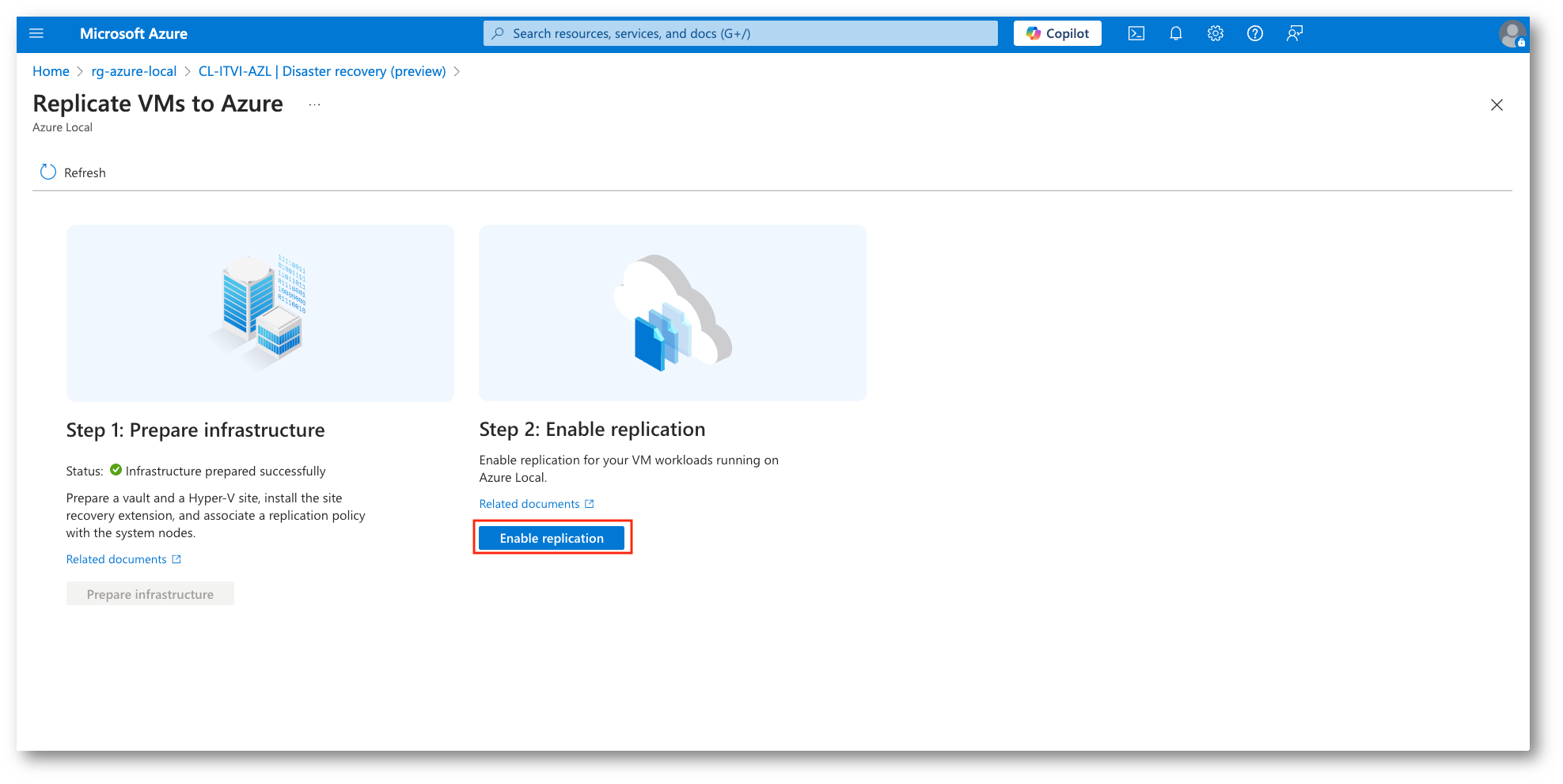
Figura 21: Abilitazione della Replica
Verremo ora portati nella sezione Replicated Items nel Vault creato in precedenza. Da qui selezioneremo Hyper-V machines to Azure (Azure Local si basa su Hyper-V), successivamente indicheremo il site Hyper-V (source location) che raccoglie i nodi fisici e il target environment.
Nella configurazione dell’ambiente di destinazione selezioneremo il Resource Group e le VNET e Subnet del sito di DR, creati all’inizio di questa guida.
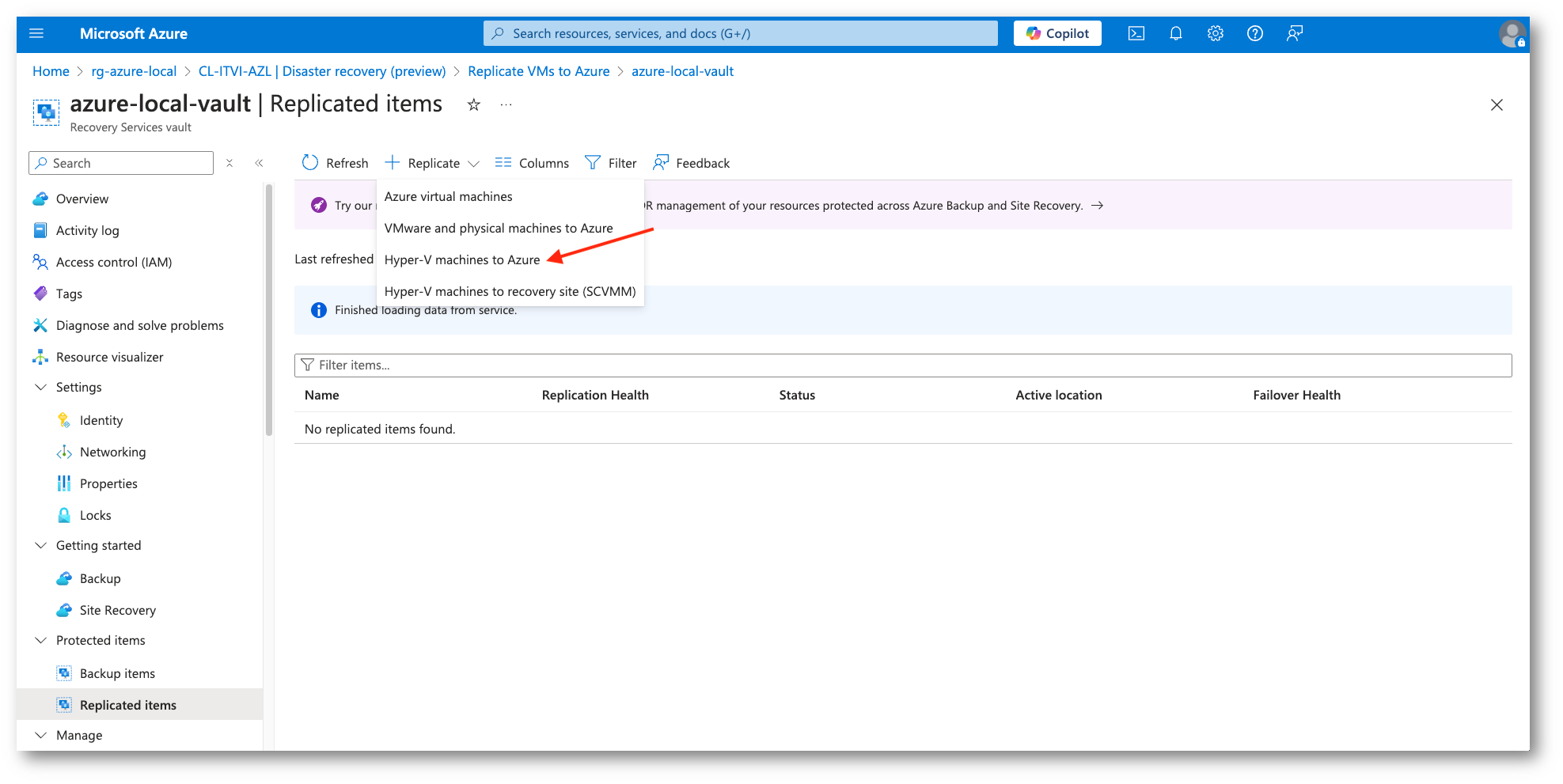
Figura 22: Selezione sorgente Hyper-V
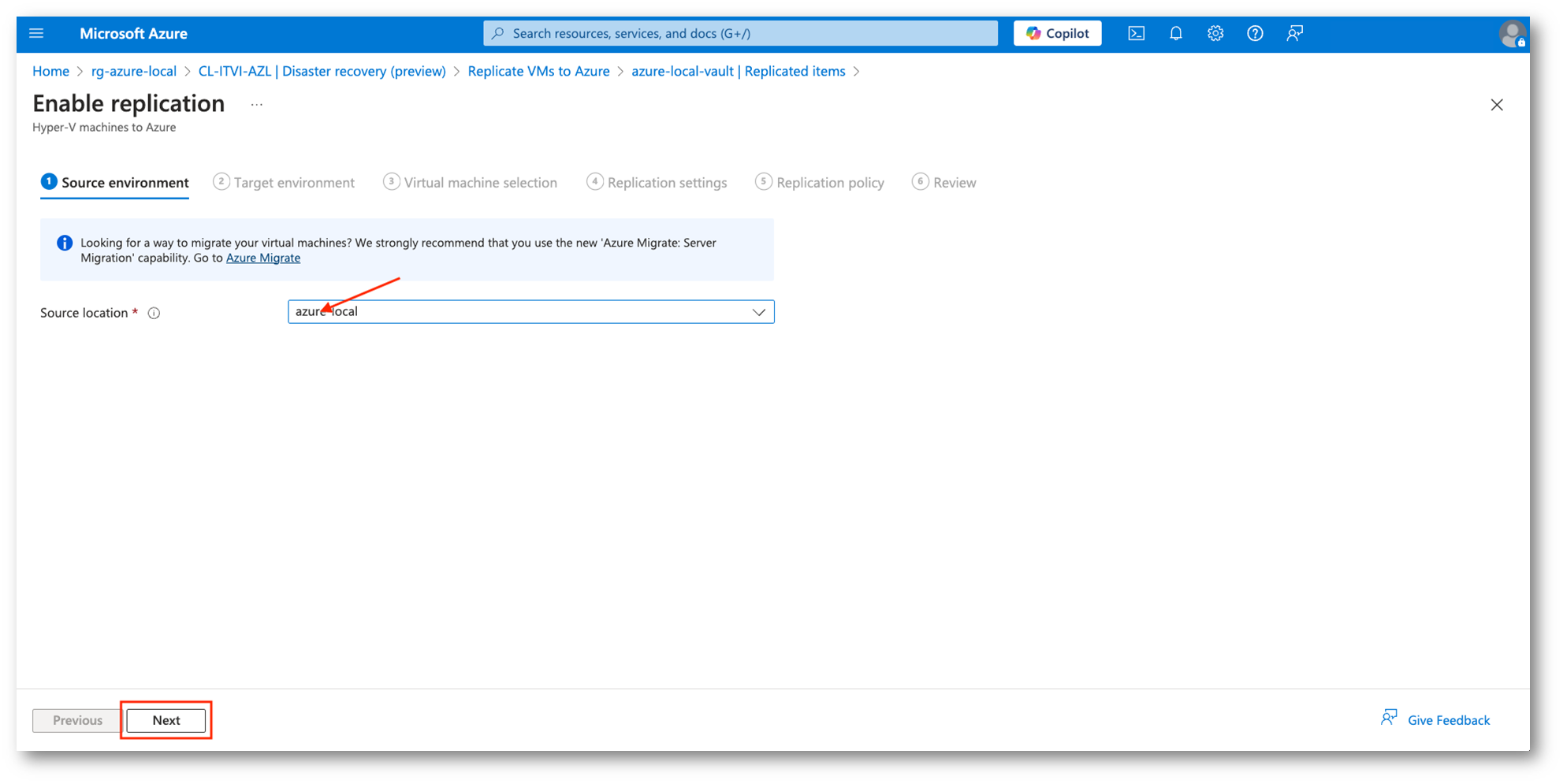
Figura 23: Indicazione dell’Hyper-V Site
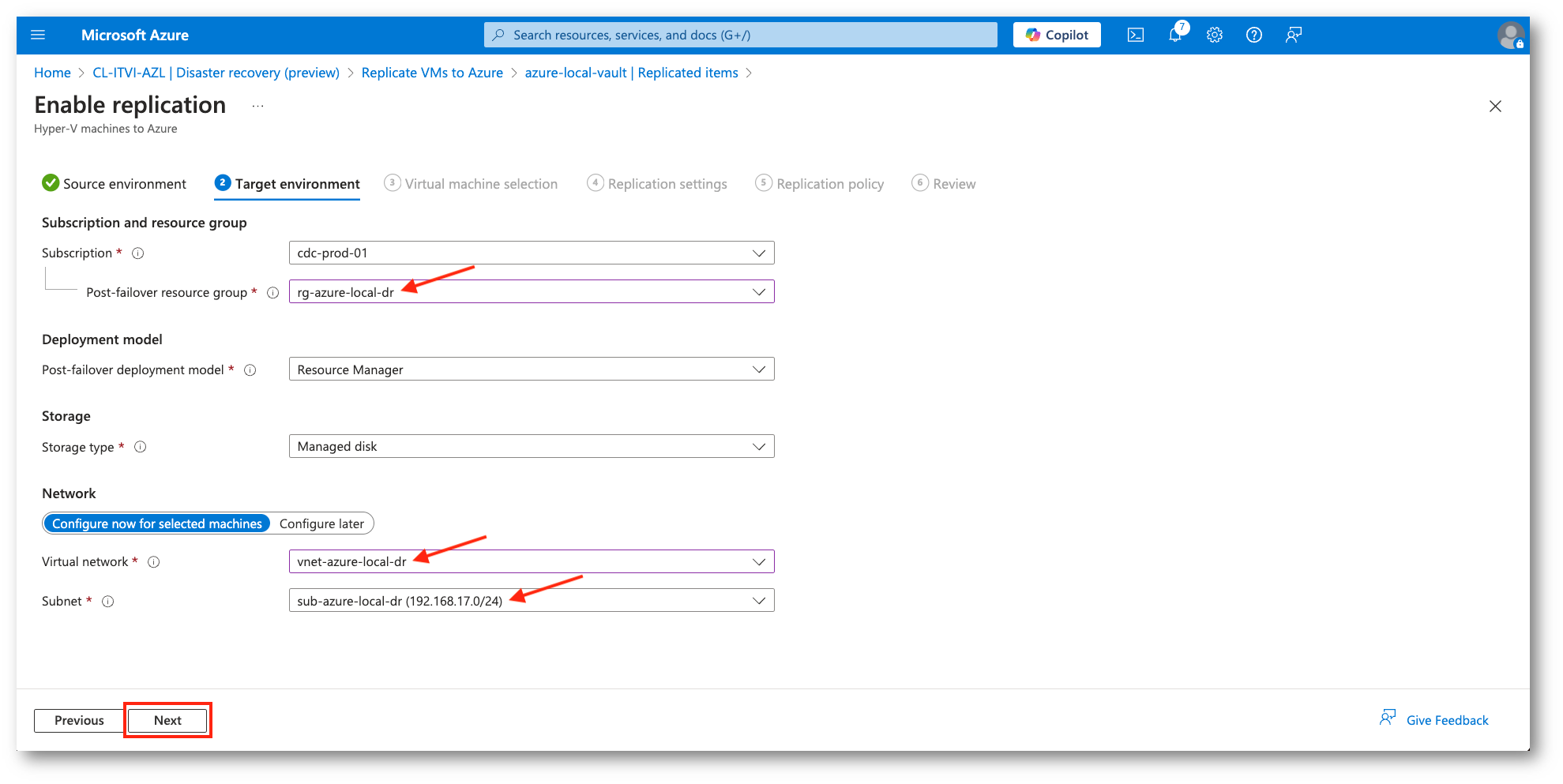
Figura 24: Impostazioni ambiente di destinazione
In questo frangente selezioneremo la sola macchina di test presente in questo laboratorio, sarà chiaramente possibile proteggere più di una VM per i vari Job di replica.
Configureremo anche il sistema operativo, i dischi e la loro tipologia che verranno riportati nell’ambiente di destinazione.
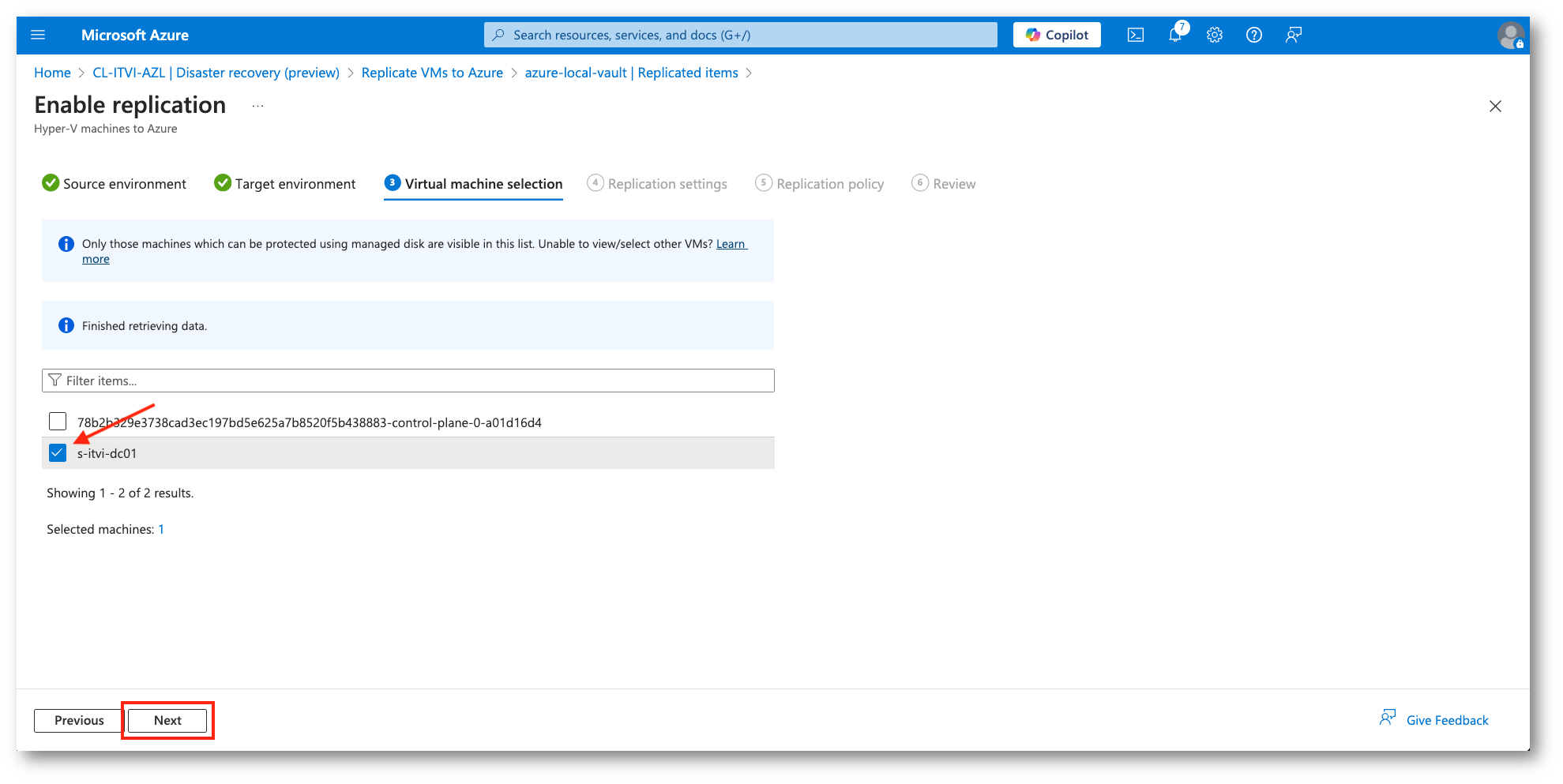
Figura 25: Selezione VM da proteggere
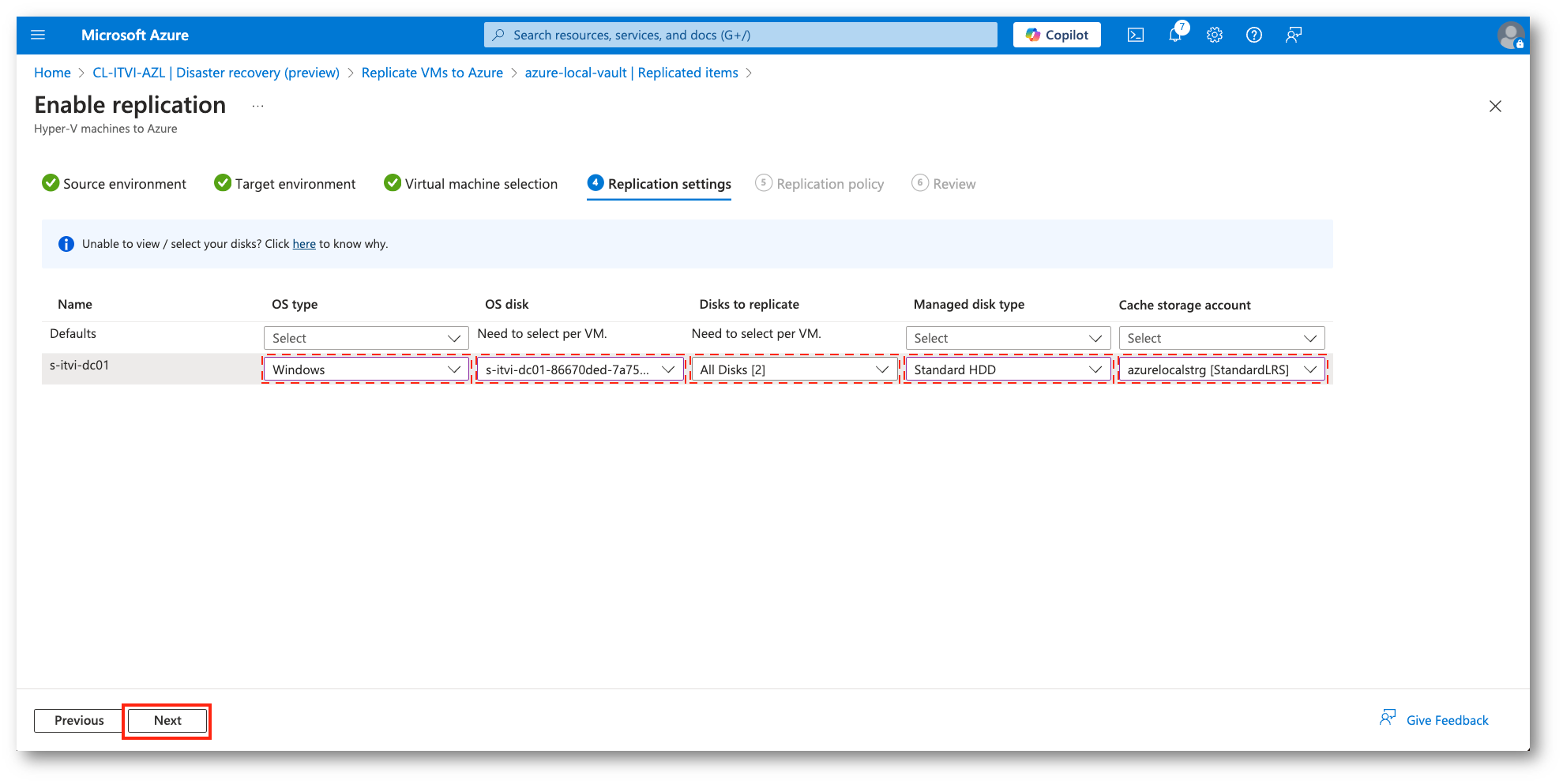
Figura 26: Parametri di configurazione della VM target
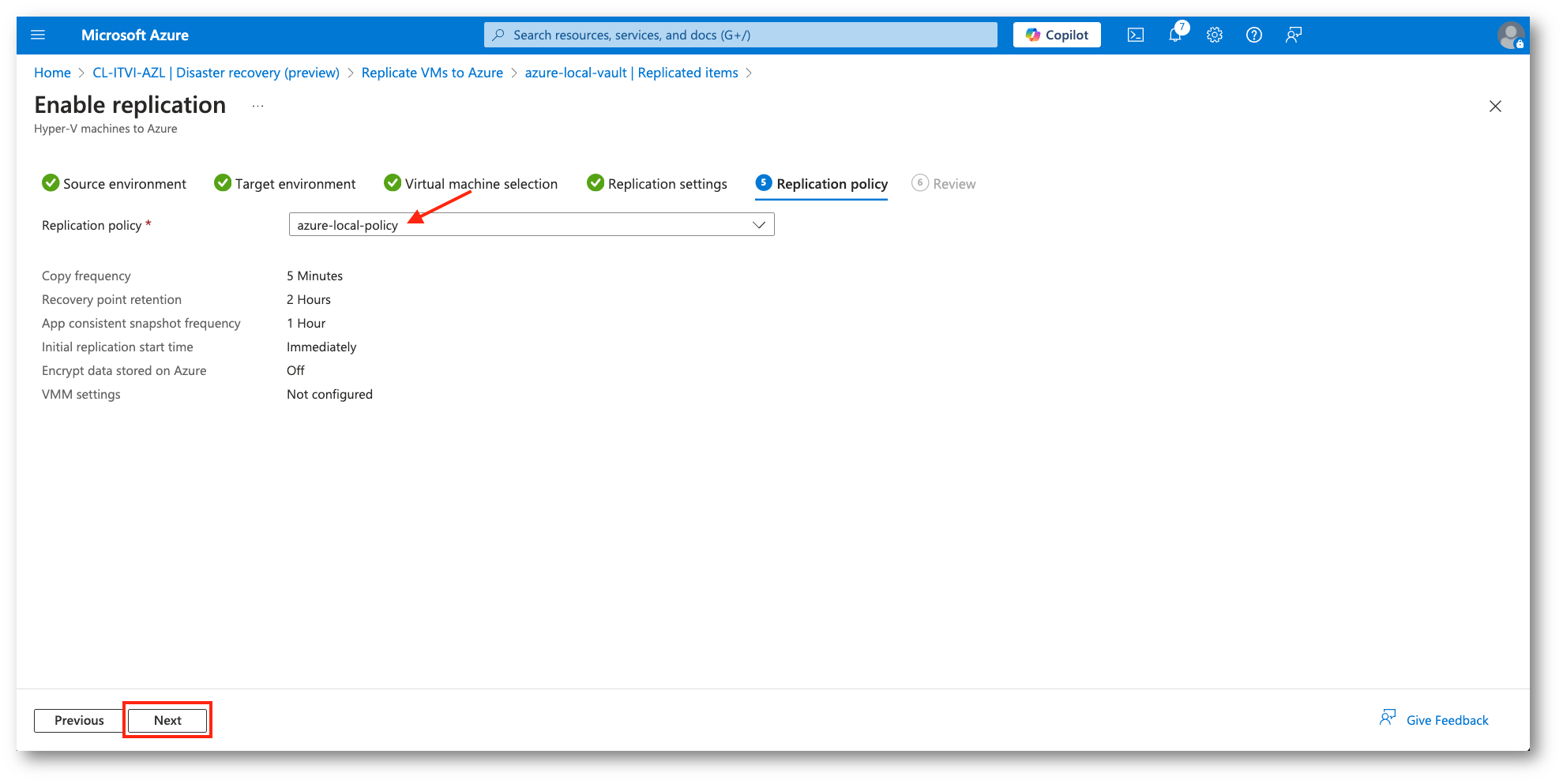
Figura 27: Selezione della Retention Policy
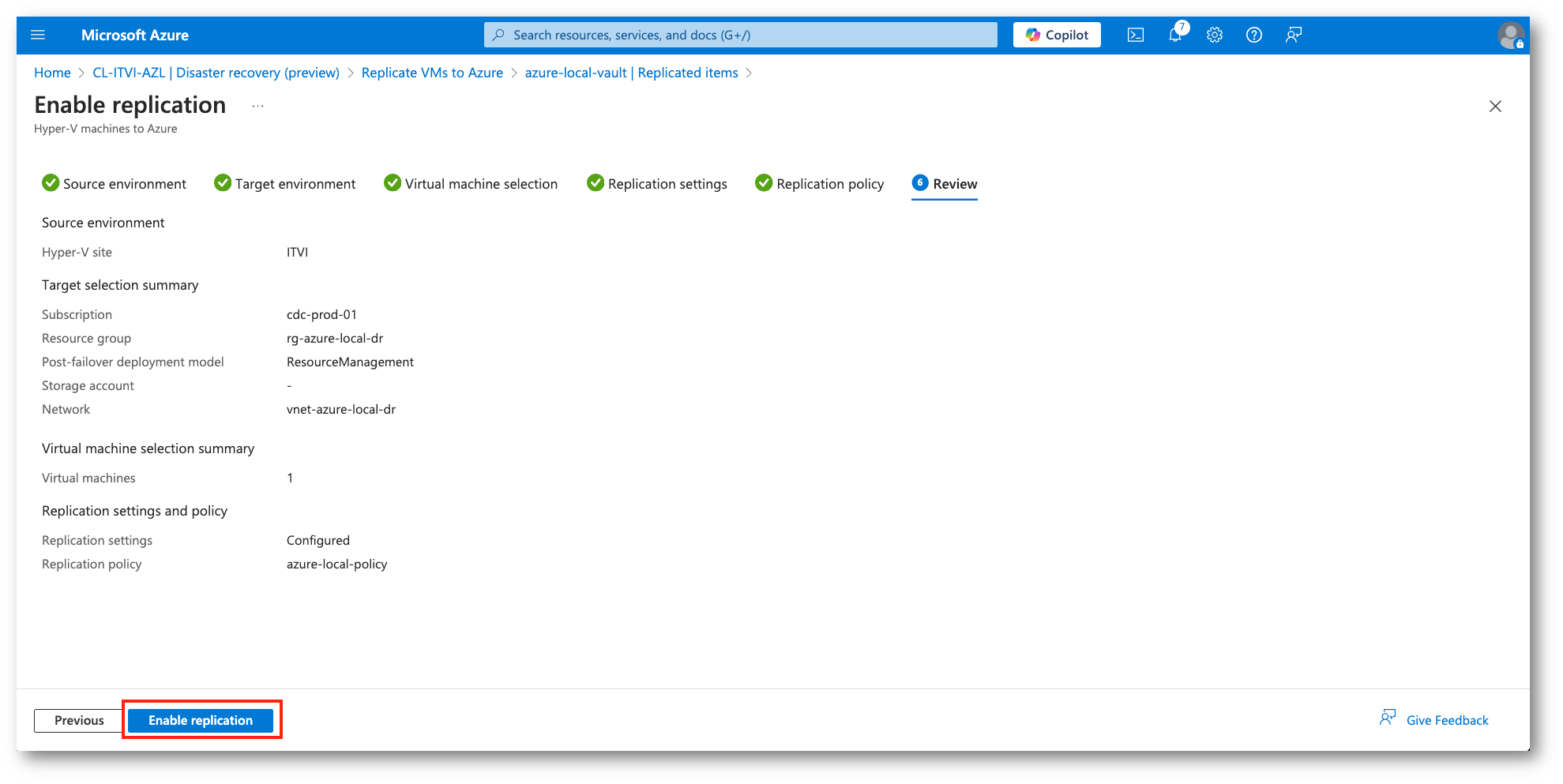
Figura 28: Avvio del processo di replica
Quando viene avviata la replica iniziale vengono create le snapshot delle virtual machine.
I dischi rigidi vengono replicati uno alla volta fino a quando non sono tutti copiati su Azure. Il processo può richiedere del tempo, a seconda delle dimensioni della macchina virtuale e della larghezza di banda della rete.
Se durante la replica iniziale si verificano modifiche ai dischi vengono registrate le variazioni nei file di log della replica di Hyper-V (.hrl). Questi file di log si trovano nella stessa cartella dei dischi e ogni disco ha un file .hrl associato che viene inviato allo storage secondario.
Una volta completata la replica iniziale, lo snapshot della macchina virtuale viene eliminato e le modifiche incrementali registrate nei log vengono sincronizzate e unite al disco principale.
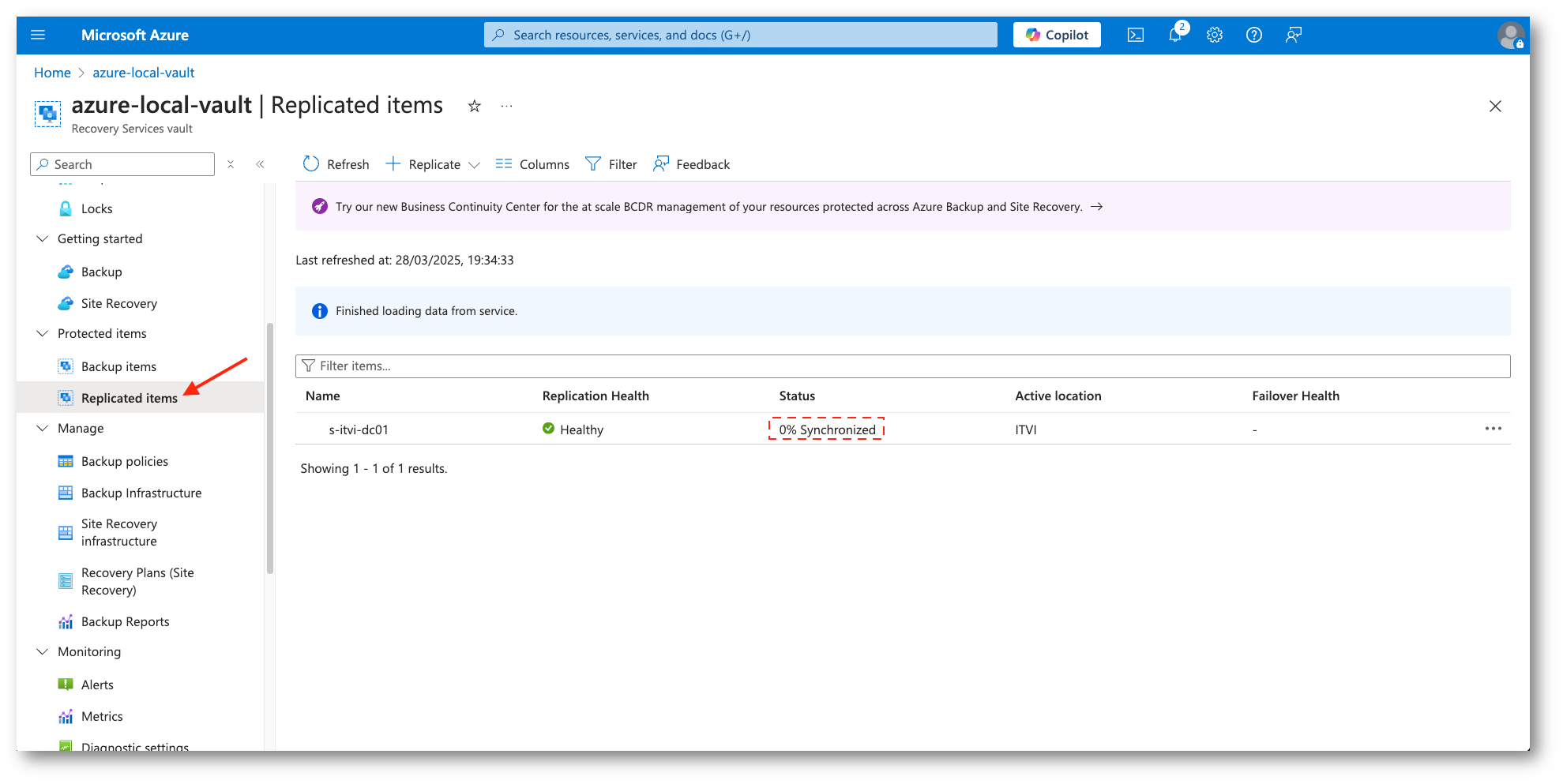
Figura 29: Inizio della sincronizzazione
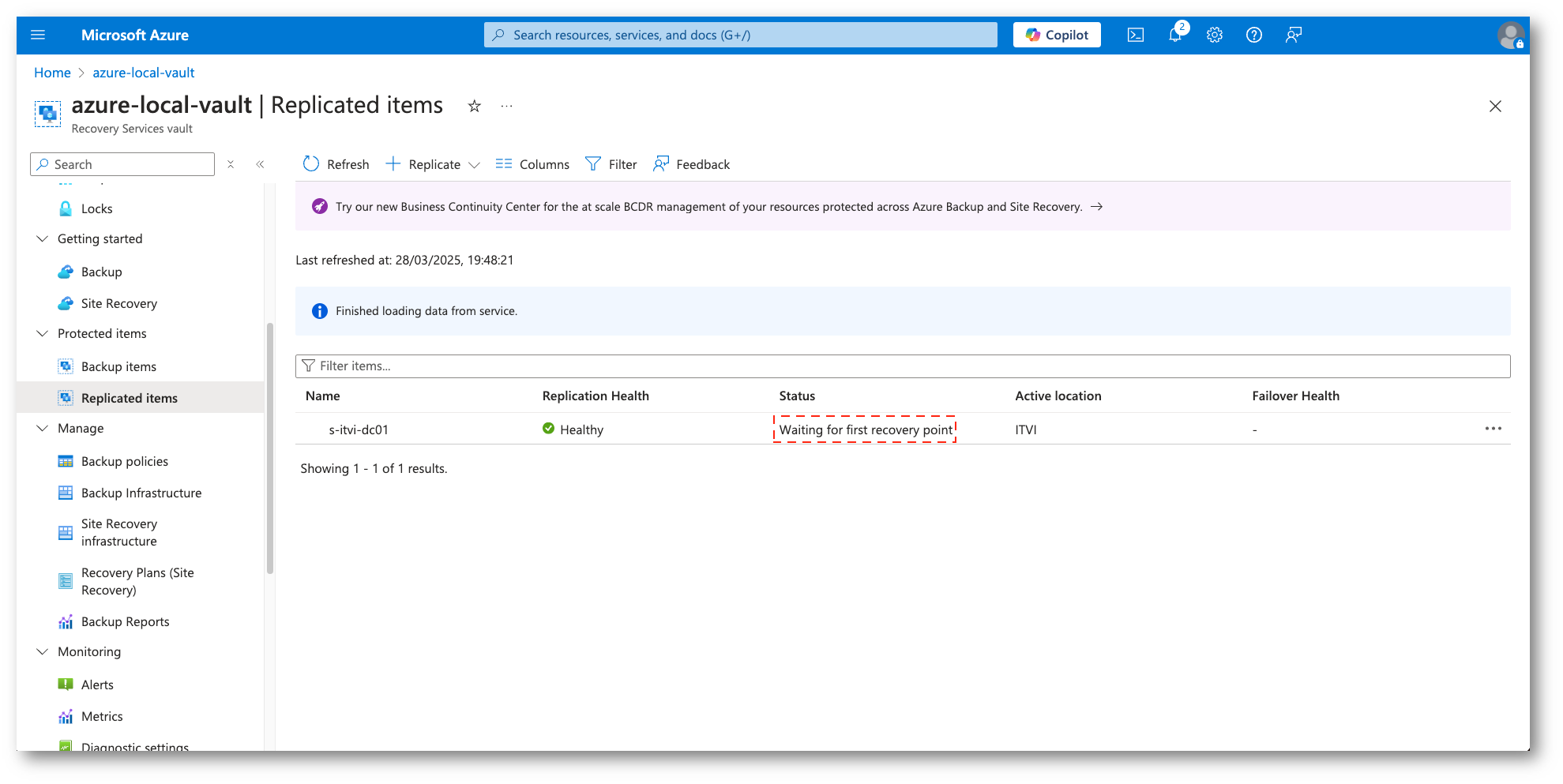
Figura 30: Replica in stato Healthy e in attesa del primo punto di ripristino
Quando vedremo la virtual machine in stato Protected sarà possibile eseguire il Failover Test, una funzionalità che permette di simulare un failover senza impattare l’ambiente di produzione.
È estremamente importante poiché serve per verificare che il piano di Disaster Recovery funzioni correttamente e che le VM possano essere avviate con successo nella regione di destinazione.
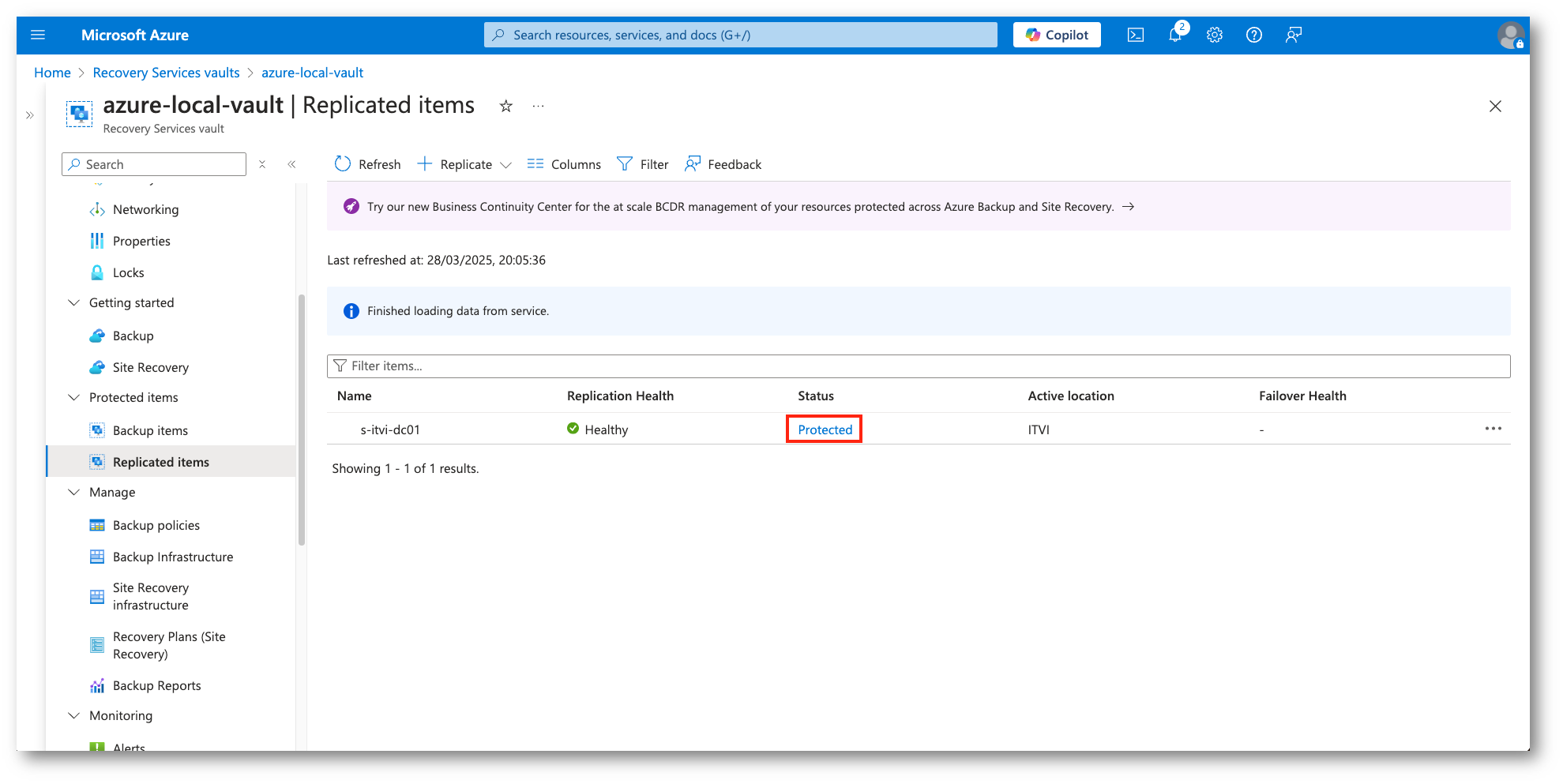
Figura 31: Il workload è in stato protected, con il primo Recovery Point creato
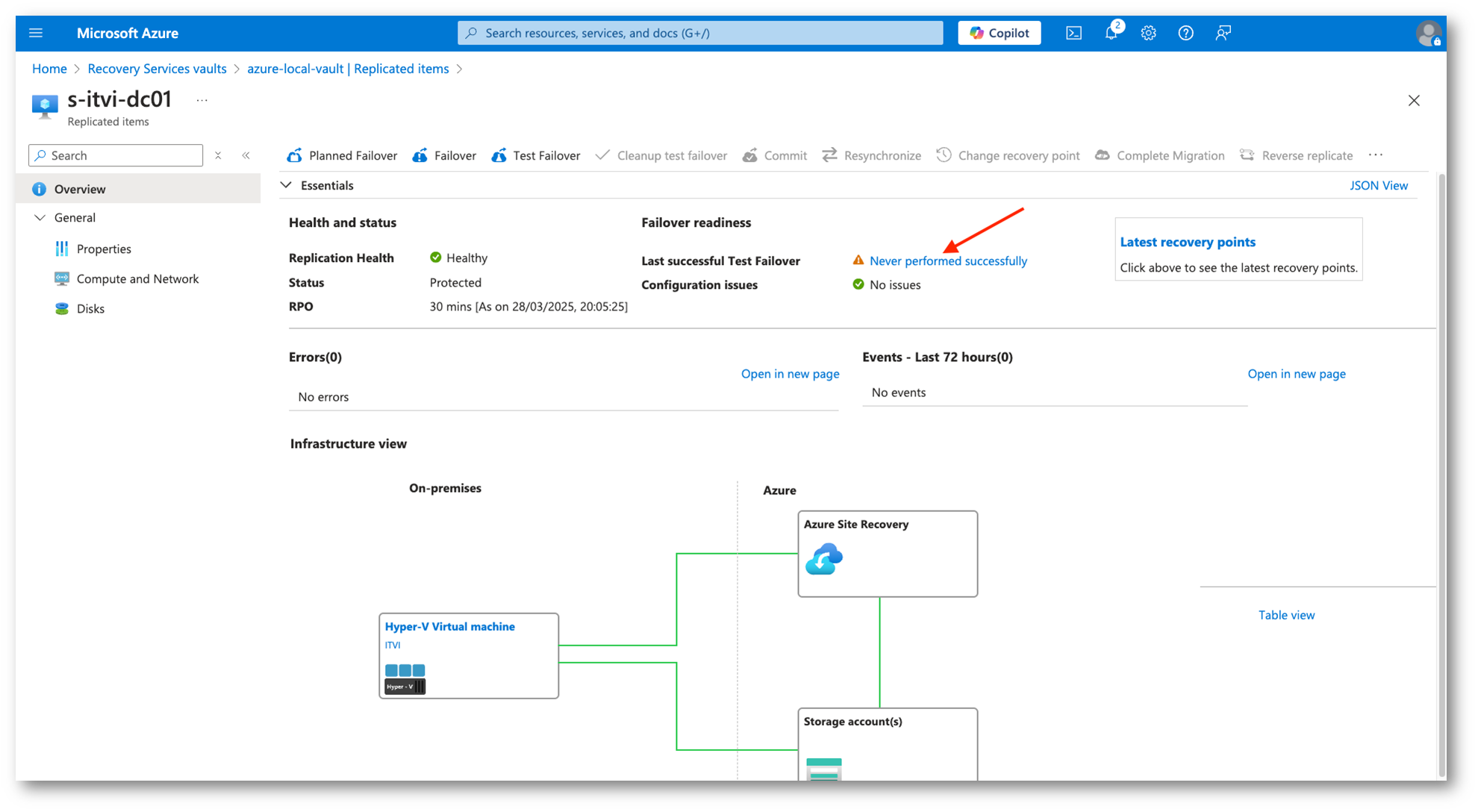
Figura 32: Situazione prima del Test Failover
Processi di Failover e Failback
Le procedure sono sostanzialmente le medesime viste nell’articolo “Azure Site Recovery: Disaster Recovery di Azure VM tra Region diverse” anche se con Azure Local e Hyper-V è possibile eseguire il failover in modalità pianificata o non pianificata:
- Failover pianificato: le macchine virtuali di origine vengono spente prima della transizione, garantendo l’assenza di perdita di dati.
- Failover non pianificato: in caso di indisponibilità del sito primario è possibile eseguire un failover non pianificato, consentendo alle macchine virtuali di essere ripristinate direttamente in Azure.
Si può scegliere di eseguire il failover di una singola macchina virtuale oppure definire piani di ripristino (recovery plans) per orchestrare più VM contemporaneamente.
Una volta avviato piano, nella prima fase del processo, verranno create le repliche delle macchine virtuali in Azure. A questo punto sarà possibile visualizzare le VM replicate nel portale di Azure ed eseguire le operazioni necessarie a renderle fruibili.
Infine, è necessario convalidare e confermare (commit) il failover, consentendo così l’accesso ai carichi di lavoro direttamente dalle macchine virtuali replicate in Azure.
Come già visto nella guida menzionata sopra, è sempre consigliabile eseguire un Test Failover per verificare che, in caso di disastro, il processo vada a buon fine.
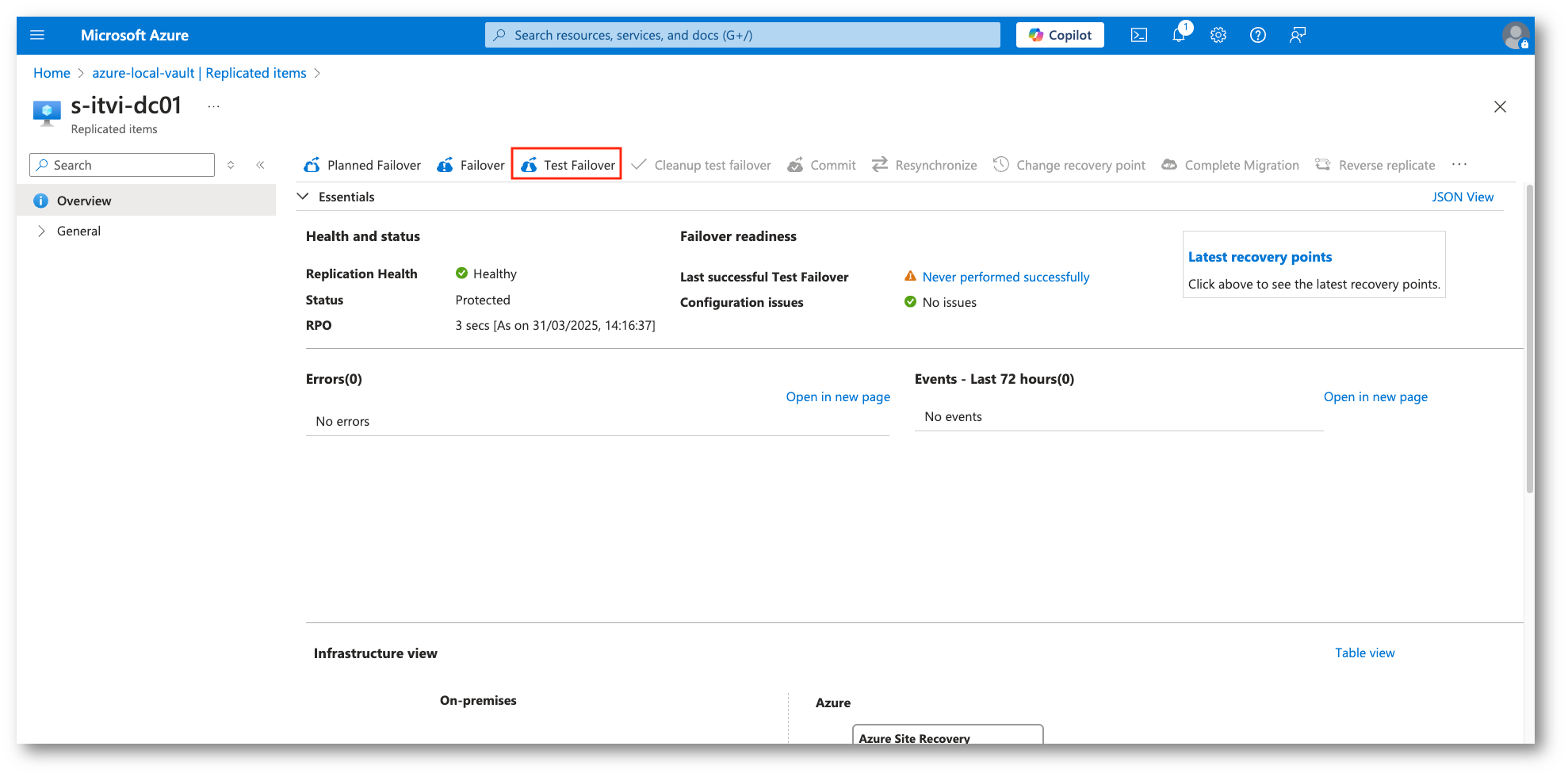
Figura 33: Processo di test del Failover
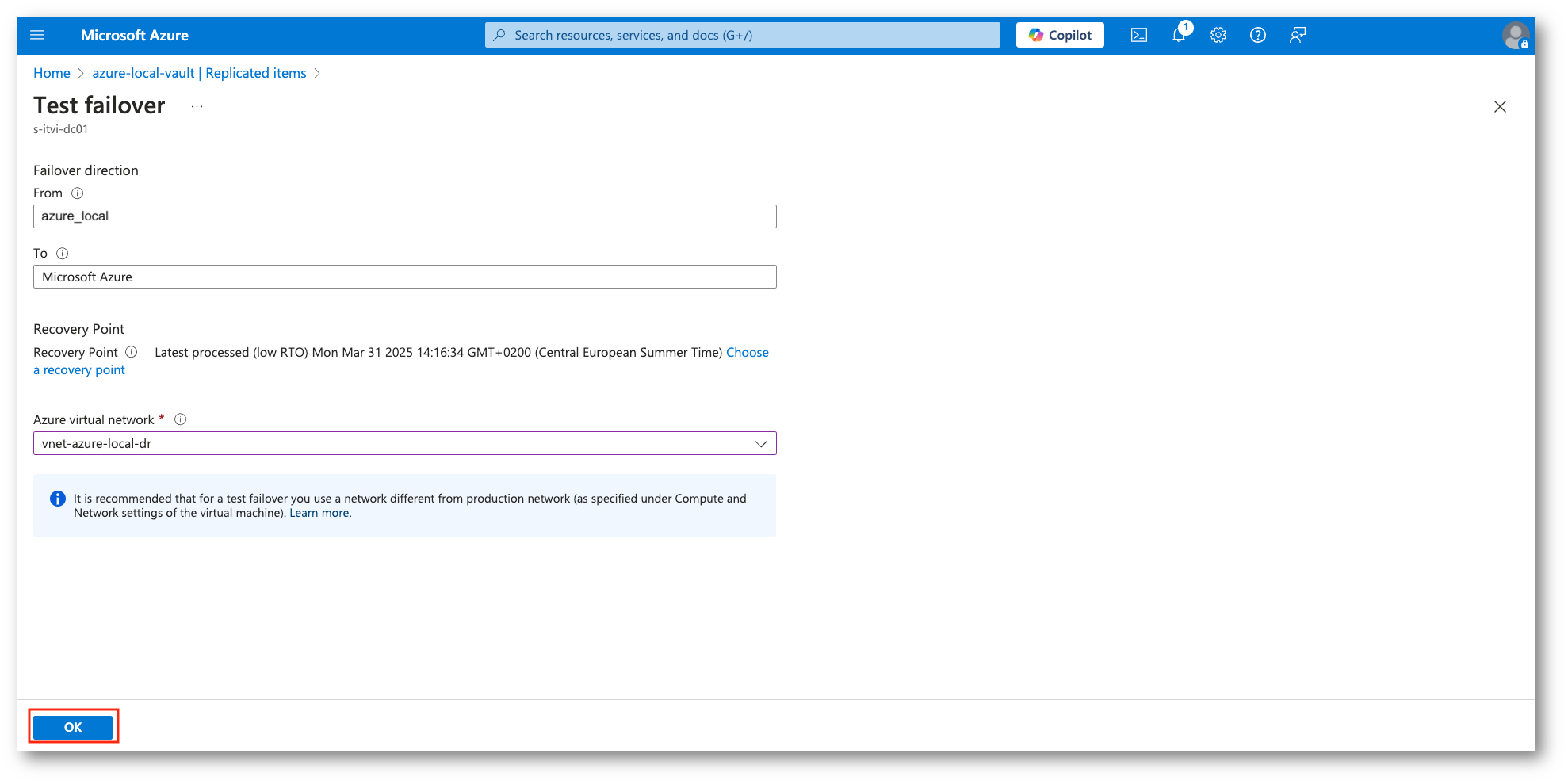
Figura 34: Selezione opzioni e conferma del test
Possiamo verificare e gestire l’istanza replicata direttamente dal Resource Group di destinazione, in cui la troveremo insieme alle sue risorse (disco, nic).
Eseguite tutte le prove necessarie, torneremo alla situazione iniziale tramite il Cleanup test failover.
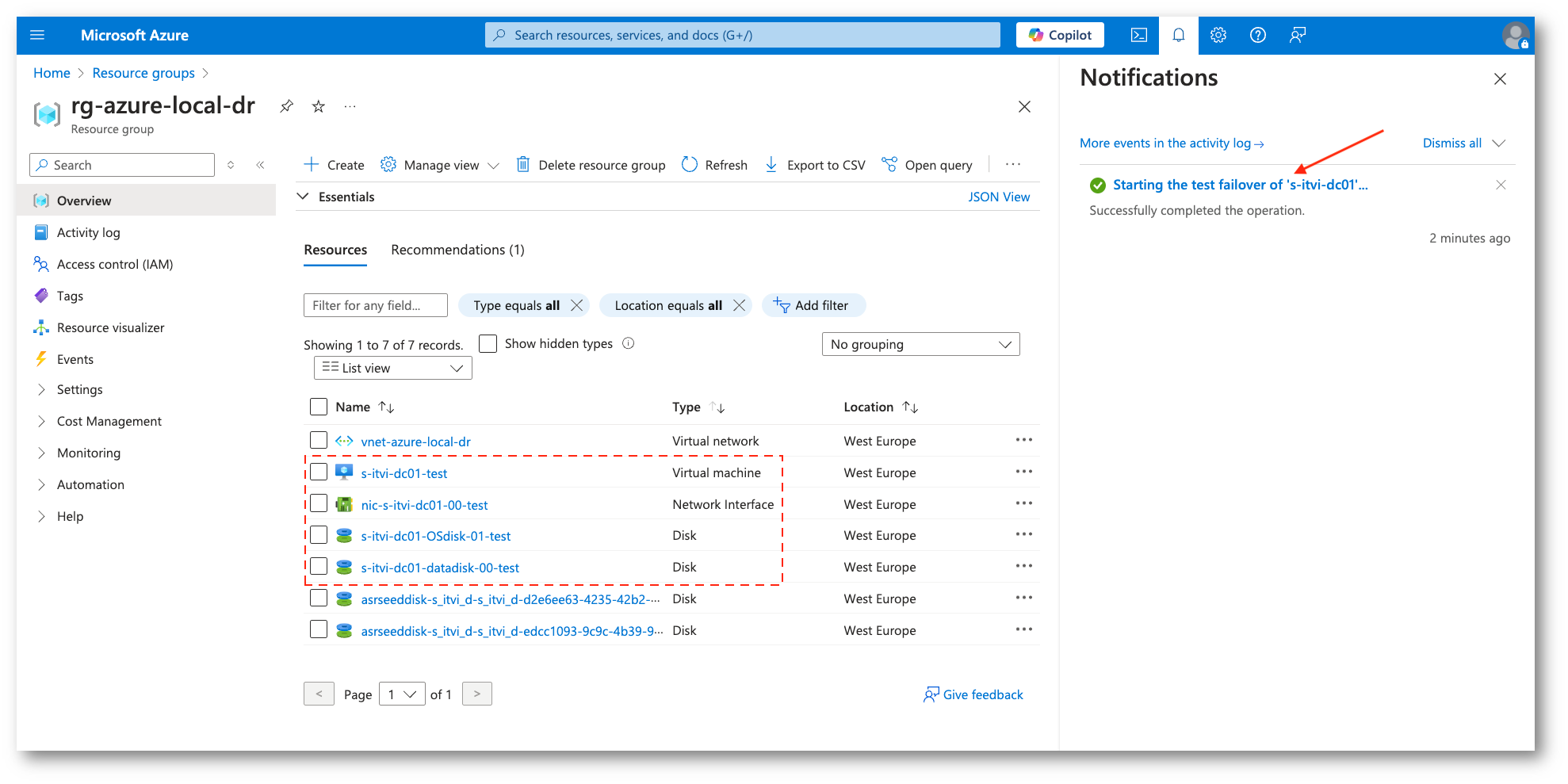
Figura 35: Risorse a fronte del test di Failover
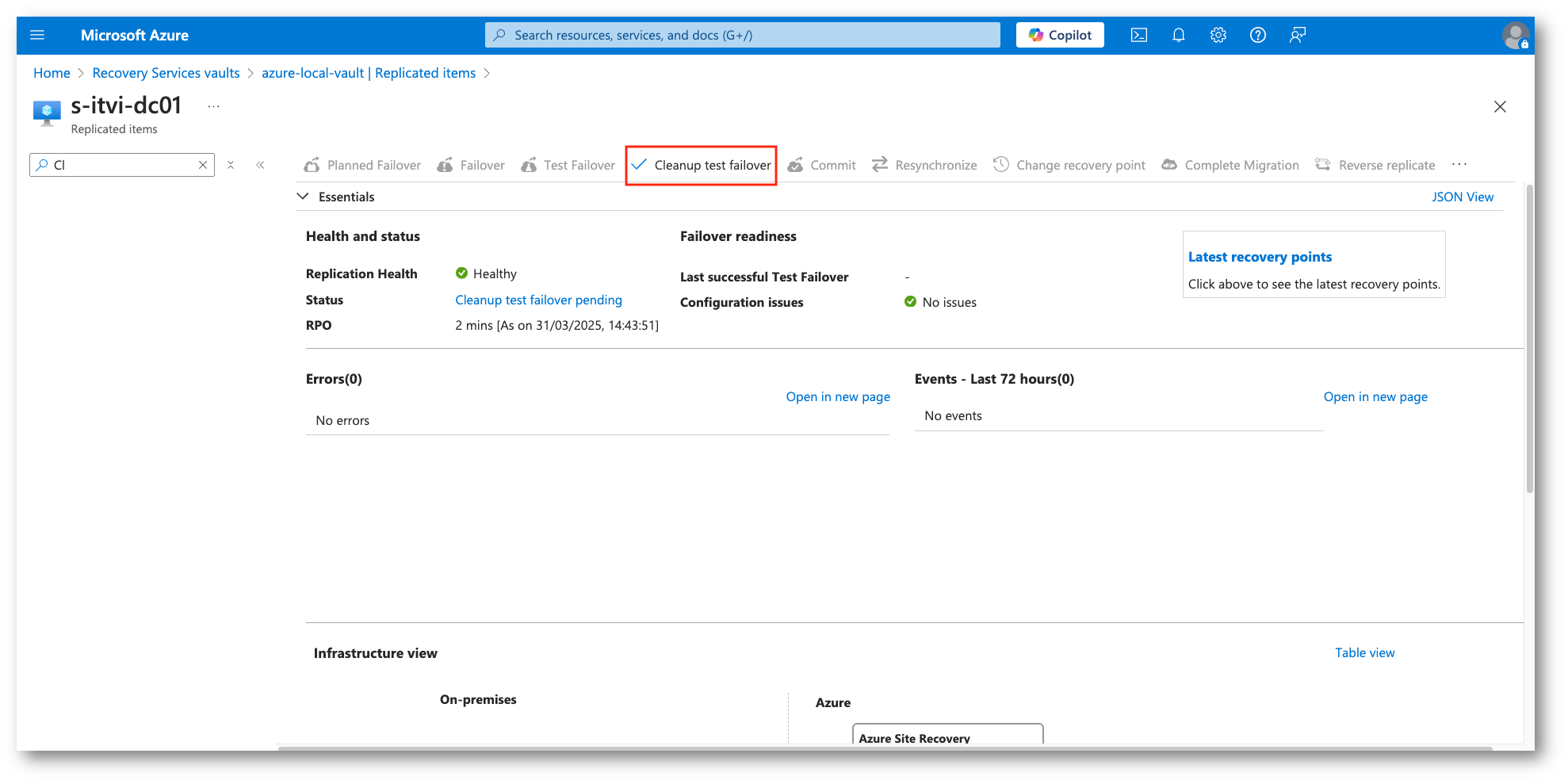
Figura 36: Cleanup del test di Failover
Eseguito il Cleanup del test saremo pronti a effettuare i veri e propri Failover, come dicevamo abbiamo due opzioni: Planned Failover e Failover (non pianificato).
Nell’immagine sono indicate le due possibilità che andranno utilizzate in base alle esigenze e le casistiche.
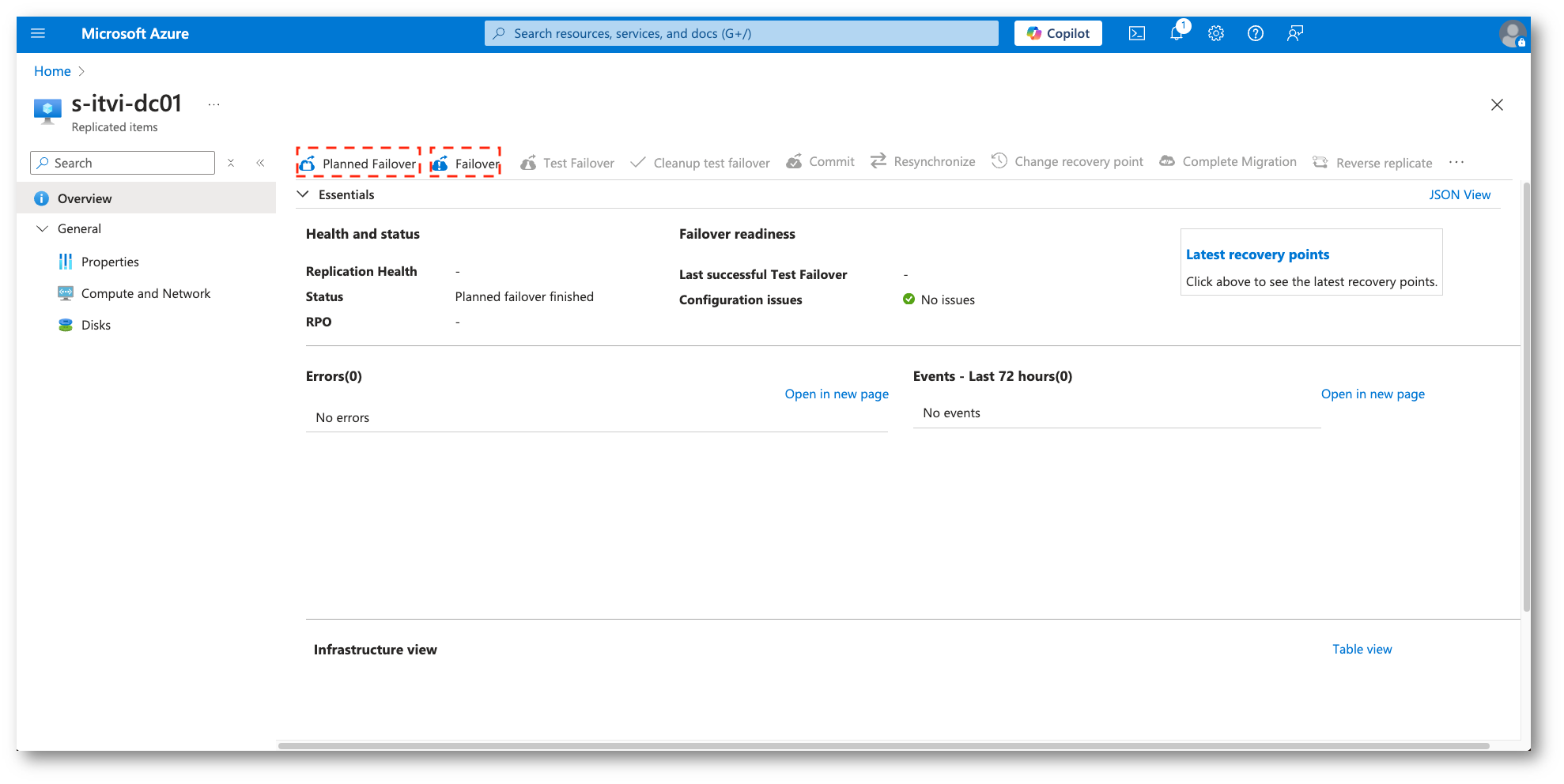
Figura 37: Inizio del processo di Failover (planned, not planned)
Dopo aver eseguito una delle due tipologie di Failover si hanno a disposizione tre opzioni, ciascuna con uno scopo specifico:
Commit:
- La replica non viene interrotta definitivamente
- Tutte le configurazioni di replica vengono mantenute, consentendo di eseguire il Failback
Completamento della Migrazione:
- Questa opzione indica che il processo di migrazione è definitivo e non si prevede di tornare alla posizione di origine
- Selezionando Completamento della migrazione, il sistema esegue automaticamente le operazioni di Commit e Disabilitazione della replica, chiudendo definitivamente il processo di replica
Cambio del punto di ripristino che permette di scegliere un recovery point differente da quello automaticamente selezionato
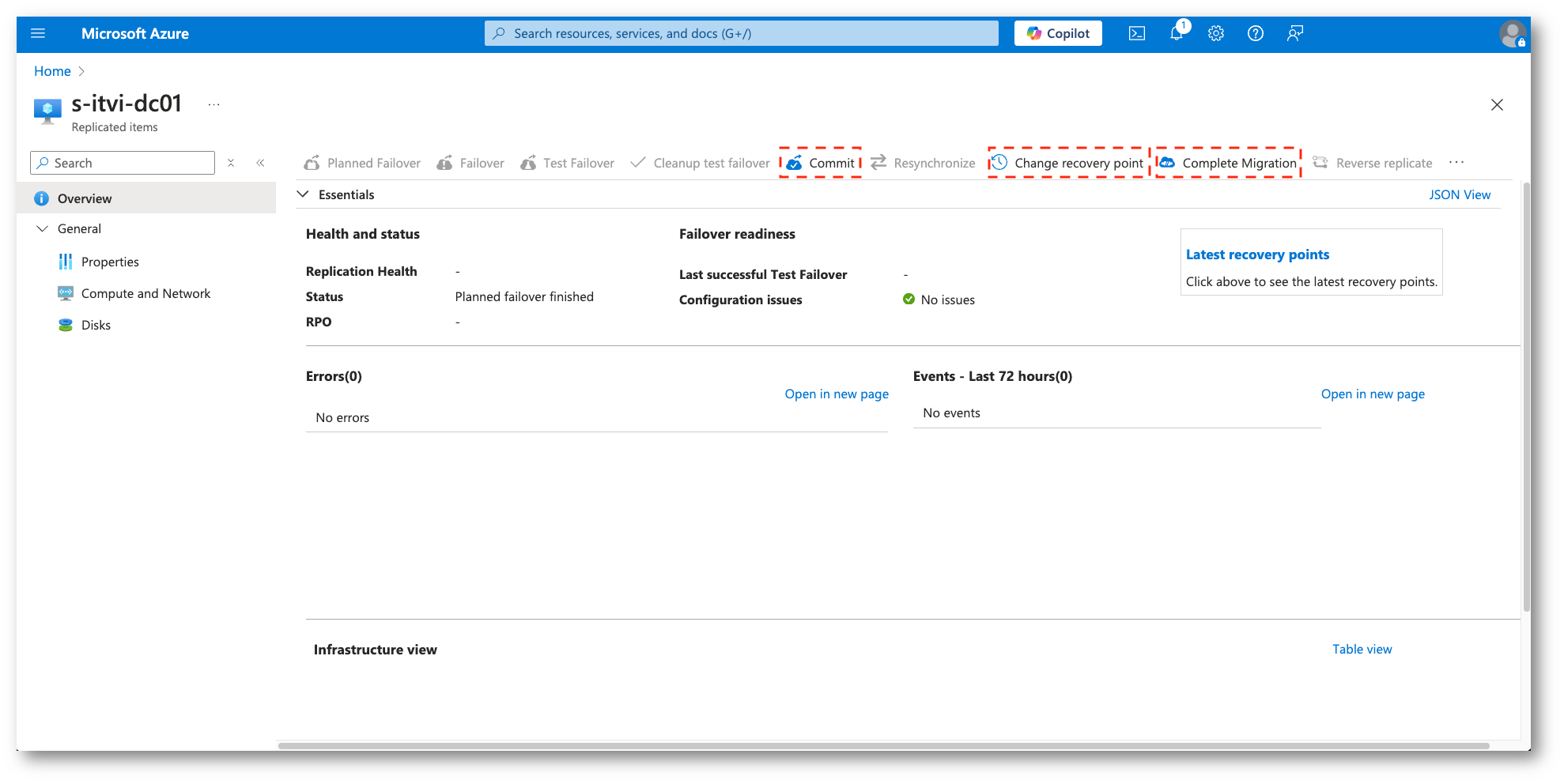
Figura 38: Opzioni per il completamento del processo di Failover
Nell’esempio sotto sceglieremo un Recovery Point diverso (App-consistent) e successivamente procederemo con il Commit, così da poter eseguire il successivo Failback, che ricordiamo essere a tutti gli effetti un Failover inverso.
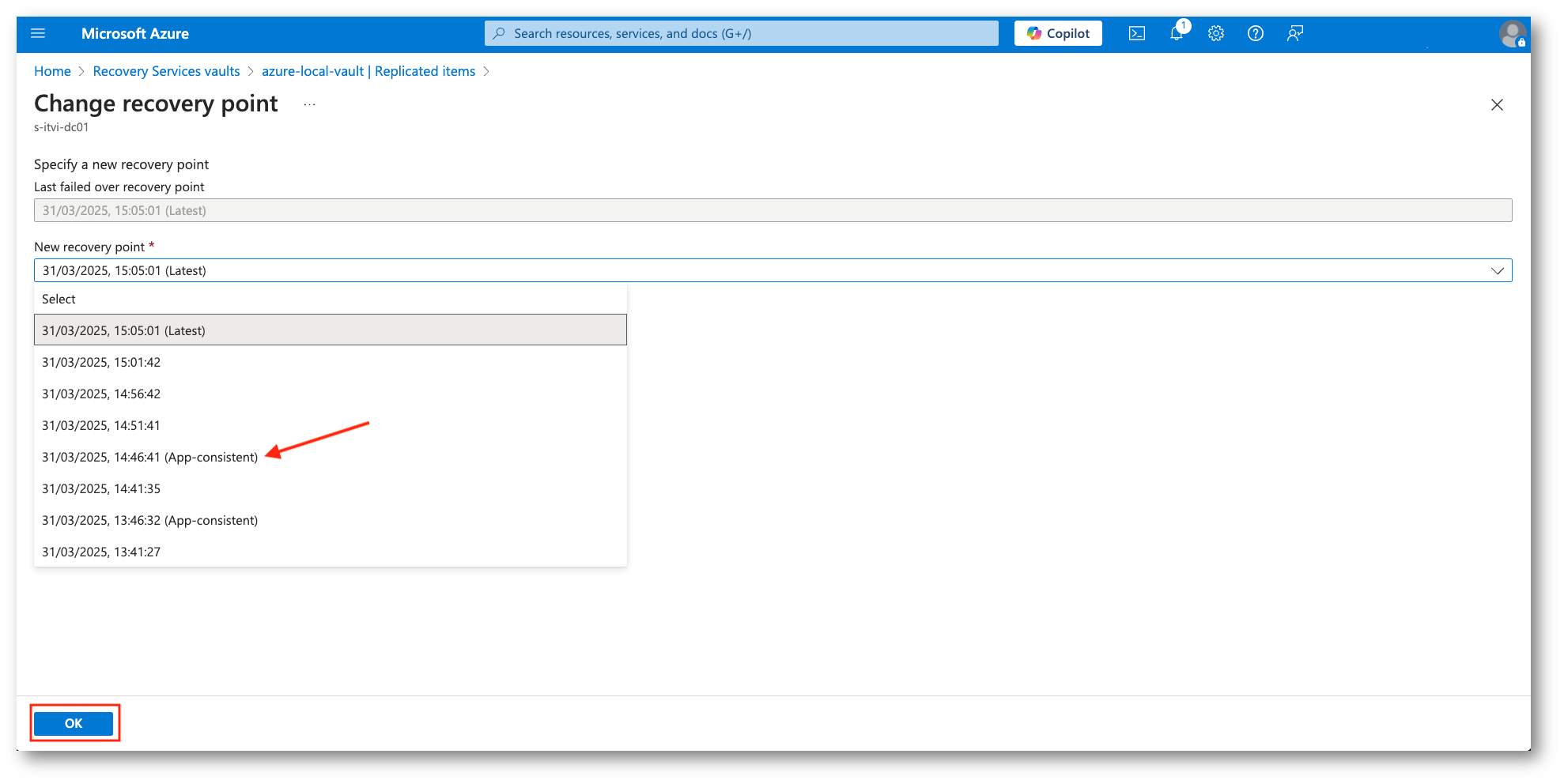
Figura 39: Scelta del Recovery Point
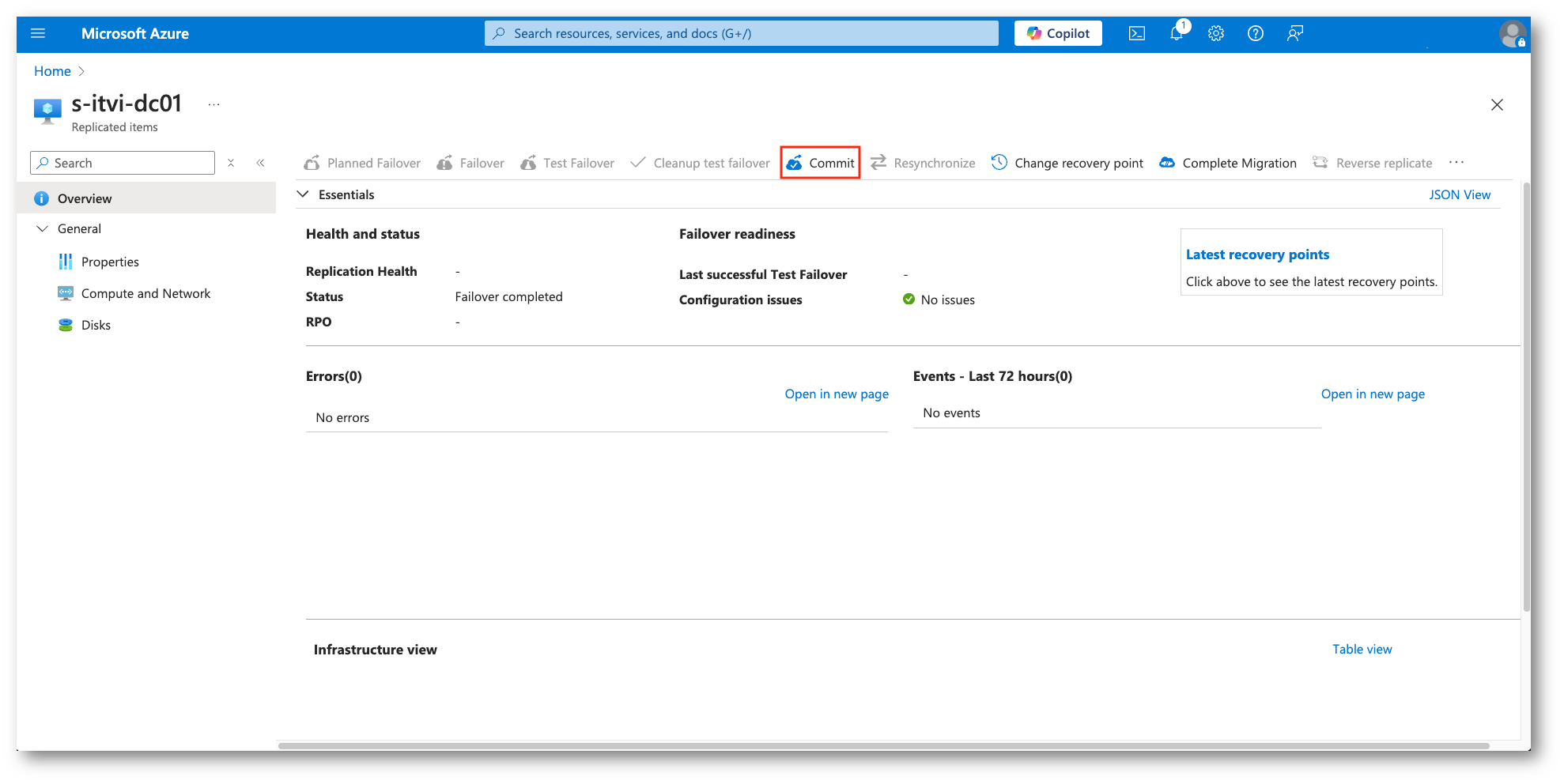
Figura 40: Commit con il nuovo Recovery Point
Il ripristino è, ovviamente, una azione pianificata dovremo, quindi, fare un Planned failover verso il sito di origine (Azure Local). In questa fase verrà eseguita una sincronizzazione che potrebbe impiegare diverso, in base alla quantità di dati modificati nel periodo di utilizzo delle istanze in Azure.
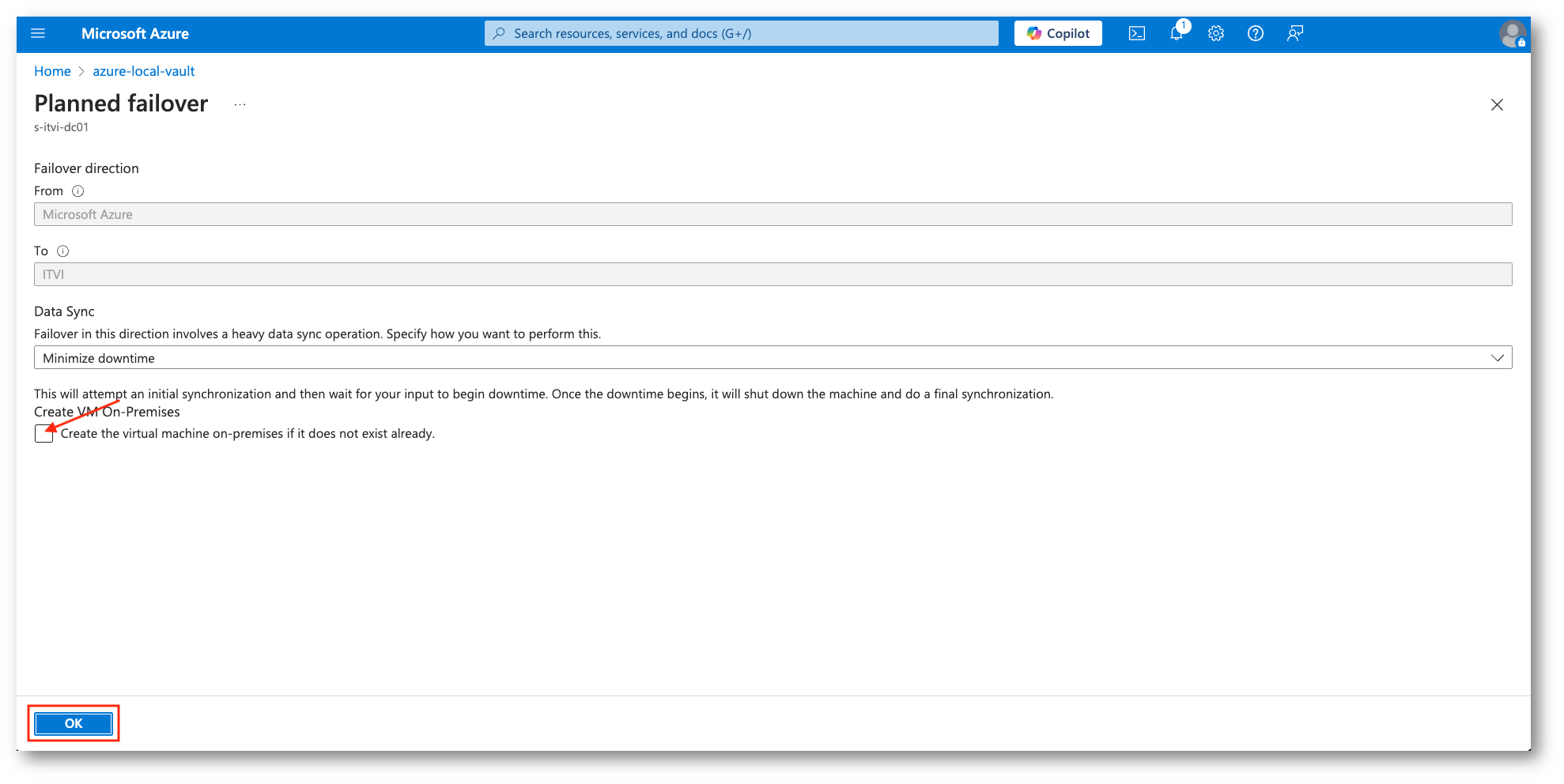
Figura 41: Failback tramite l’opzione Planned failover
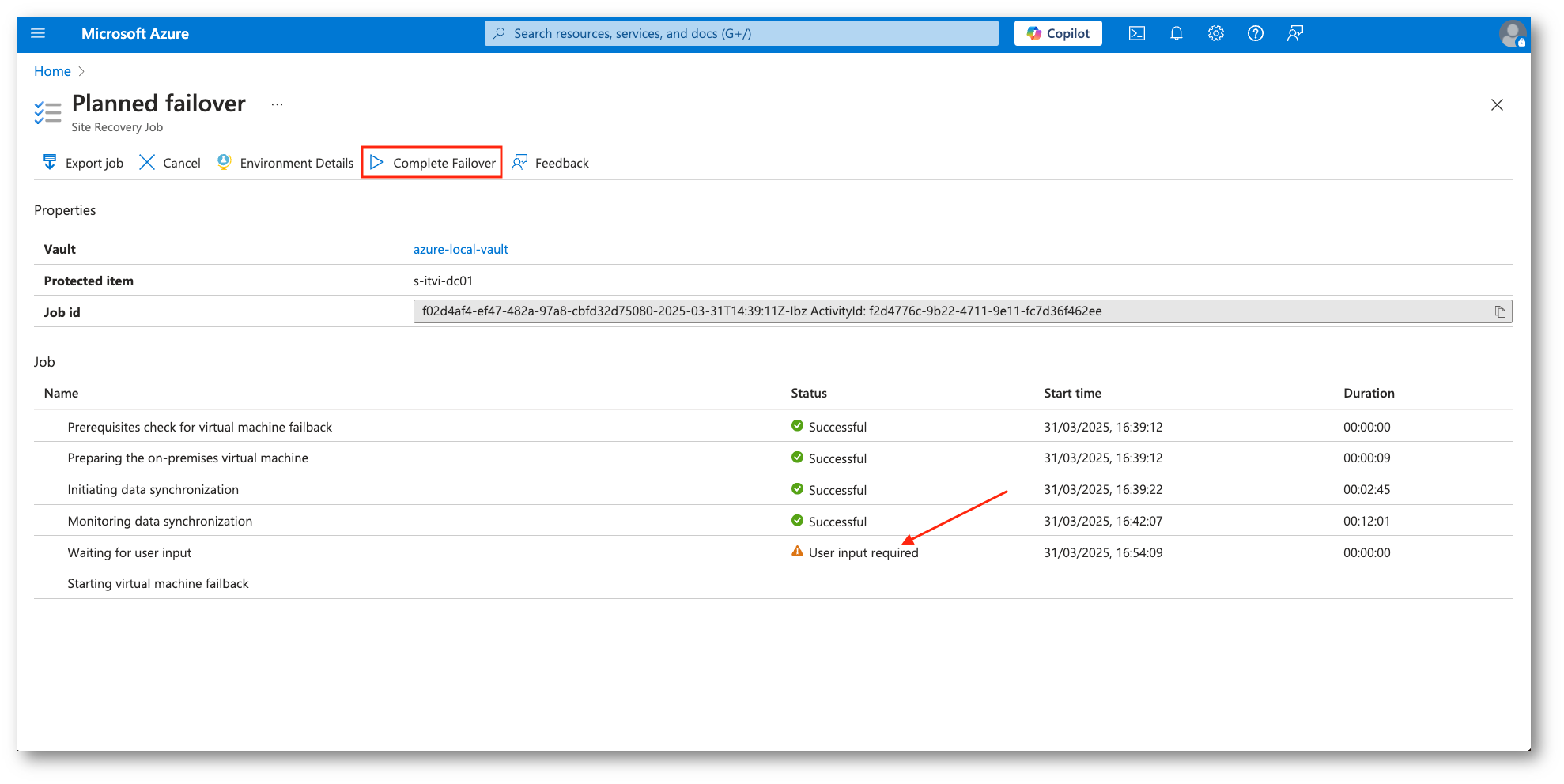
Figura 42: Completamento del Planned Failover
Conclusioni
Il Disaster Recovery delle infrastrutture On-Premises è certamente il cruccio di chiunque gestisca l’IT di una azienda, soprattutto se non vi è la possibilità di allestire altre sale server che possano garantire la continuità operativa.
La replica verso un Cloud pubblico come Azure può essere una soluzione intelligente, soprattutto in funzione del fatto che la gestione del sito di replica è in totale gestione e garantita dal provider (Microsoft).
Grazie alla grande integrazione tra le due tecnologie Azure Site Recovery diventa una scelta obbligata per chi ha deciso di investire in una soluzione di Hybrid Cloud come Azure Local.