
Microsoft Purview: Information Protection on SQL Database
Nel contesto aziendale di questo periodo, caratterizzato da una crescita esponenziale dei dati e da normative sempre più stringenti in materia di sicurezza e conformità, la capacità di individuare, classificare e proteggere le informazioni sensibili diventa una priorità strategica per le organizzazioni. Microsoft Purview Information Protection si propone come una soluzione completa per la governance e la protezione dei dati, consentendo di gestire in modo centralizzato le informazioni ovunque esse risiedano, inclusi i database SQL on-premises e nel cloud.
La famiglia Microsoft Purview mette a disposizione un insieme integrato di funzionalità che permettono alle aziende di ottenere piena visibilità sui propri dati e di ridurre i rischi legati a un utilizzo improprio o a violazioni di sicurezza. In particolare, Purview consente di:
- Conoscere i dati, attraverso l’individuazione e la classificazione automatica delle informazioni sensibili;
- Proteggere i dati, applicando etichette di riservatezza e controlli coerenti lungo l’intero ciclo di vita del dato;
- Impedire la perdita di dati, grazie a criteri e policy di Data Loss Prevention (DLP) che riducono l’esposizione a rischi interni ed esterni.
In questo articolo analizzeremo come implementare le funzionalità di Microsoft Purview Information Protection sui database SQL, evidenziando benefici, scenari di utilizzo per una gestione efficace e sicura delle informazioni.
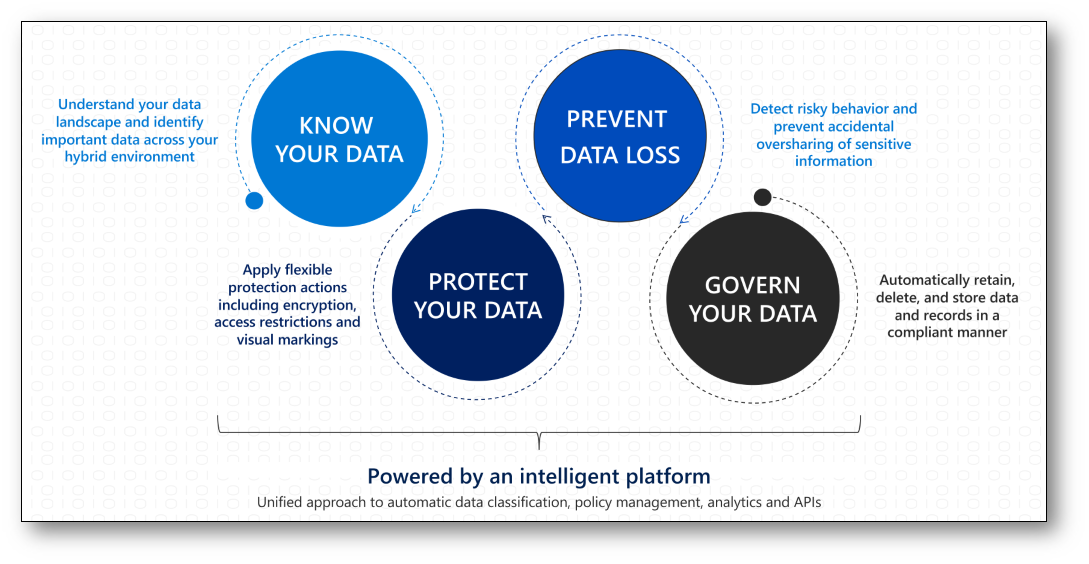
Figura 1: Schema di riferimento di Microsoft Purview
All’interno della community abbiamo parlato spesso di Microsoft Purview e a tal proposito vi riporto il link per la categoria di articoli molto ben dettagliati sui vari workload Microsoft Purview – ICT Power.
Data Discovery & Classification offre funzionalità per il rilevamento, la classificazione, l’etichettatura e il reporting dei dati sensibili all’interno dei database.
Questa operazione può essere eseguita tramite T-SQL o usando SQL Server Managament Studio (SSMS). L’individuazione e la classificazione dei dati più sensibili, come i dati aziendali, finanziari, medici e così via può avere un ruolo fondamentale nella protezione delle informazioni delle organizzazioni.
Può servire come infrastruttura per:
- Contribuire a soddisfare gli standard per la privacy dei dati
- Monitoraggio dell’accesso a database/colonne contenenti dati altamente sensibili
NB: Specifico che Data Discovery & Classification è una funzionalità supportata per SQL Server 2012 o versioni successivi e può essere usata in SSMS 17.5 o versioni successive.
Perché dovrei usare questa funzionalità e che problema risolve?
Nelle architetture dati tradizionali la sicurezza è spesso concentrata sul perimetro: si protegge il database, il server o l’accesso applicativo, dando per scontato che una volta superata quella barriera il dato sia implicitamente “al sicuro”. Questo approccio oggi non è più sufficiente. I dati vengono interrogati da più applicazioni, esportati, analizzati, integrati con servizi cloud e, soprattutto, soggetti a normative che richiedono una conoscenza puntuale di quali informazioni vengono trattate e dove risiedono.
La funzionalità di protezione e classificazione delle colonne nasce proprio per risolvere questo problema: sposta il focus dalla protezione dell’infrastruttura alla protezione del dato, consentendo di governarlo in modo consapevole e coerente lungo tutto il suo ciclo di vita. Classificare una colonna significa rendere esplicito il valore e la sensibilità dell’informazione che contiene, trasformando un dato “anonimo” in un asset riconoscibile, tracciabile e governabile.
Dal punto di vista operativo, questo permette all’organizzazione di sapere esattamente quali colonne contengono dati personali, finanziari o comunque critici, evitando che tali informazioni restino nascoste all’interno di tabelle apparentemente innocue. Dal punto di vista della compliance, la classificazione a livello di colonna fornisce una base solida per rispondere a requisiti normativi come il GDPR.
Quindi, di fatto, questa funzionalità risolve il problema della scarsa visibilità sui dati sensibili e consente alle organizzazioni di adottare un modello di protezione orientato al dato, più efficace, scalabile e allineato alle esigenze di sicurezza e conformità moderne.
Panoramica della funzionalità
Data Discovery & Classification costituisce un nuovo paradigma di protezione delle informazioni per Database SQL, Istanza gestita SQL di Azure e Azure Synapse finalizzato alla protezione dei dati e non solo del database.
Attualmente sono supportate le seguenti funzionalità:
- Discovery & recommendations: Il motore di classificazione esegue l’analisi del database e identifica le colonne che contengono dati potenzialmente sensibili. In seguito, offre un modo semplice per verificare e applicare le raccomandazioni di classificazione appropriati, nonché per classificare manualmente le colonne
- Labeling: è possibile contrassegnare le colonne con etichette di classificazione di riservatezza in modo permanente
- Visibility: è possibile visualizzare lo stato di classificazione del database in un report dettagliato che può essere stampato o esportato a scopo di controllo e conformità
All’interno del presente articolo vi darò evidenza di come poter utilizzare Data Security Classification con SSMS e con Microsoft Purview, così da fornirvi un’idea più ampia per la classificazione e protezione dei vostri dati.
Quali strumenti utilizzo per darvi evidenza di queste funzionalità?
Qui di seguito vi do evidenza delle macchine che ho utilizzato per questa guida e delle loro configurazioni, inclusi i software installati.
Figura 2: Windows Server 2022 “ITBGDC01” in cui è installato un SQL per la demo
Figura 3: SQL Server 2022 e SSMS 22 Installato sulla macchina per la Demo
Figura 4: Database presente sulla macchina demo che verrà utilizzato per Data Discovery & Classification
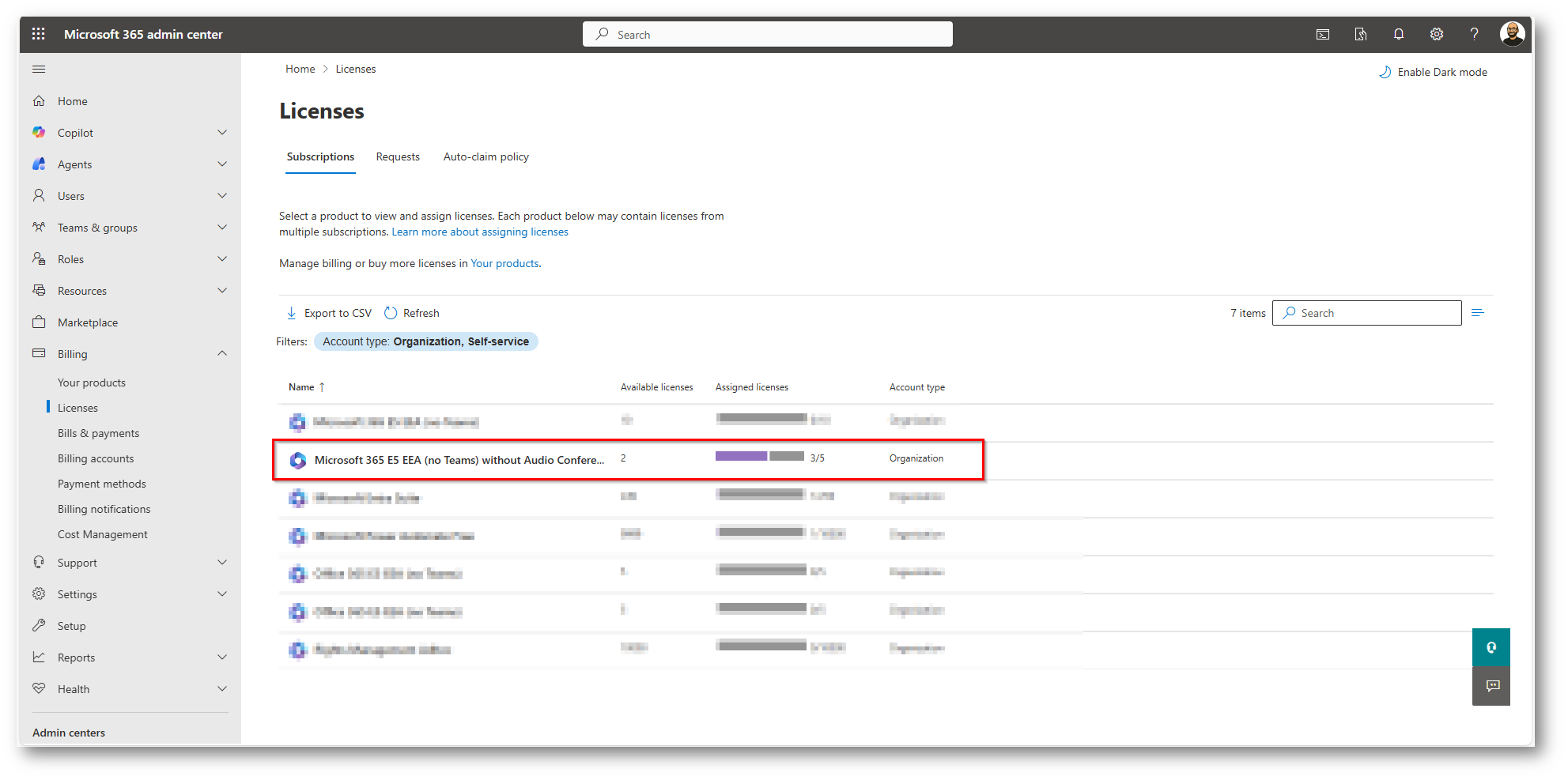
Figura 5: Licenza assegnata al mio utente per l’uso della classificazione tramite Microsoft Purview
Quali licenze sono necessarie?
Come sempre è fondamentale riportare il sito Home | M365 Maps quando si parla di Licensing, per la componente di Information Protection si rende necessario essere in possesso di una delle seguenti licenze, nel momento in cui usate la classificazione tramite Microsoft Purview:
- Microsoft 365 E5
- Microsoft 365 E3
- Office 365 E3
- Microsoft 365 Business Premium
- Microsoft 365 E3 with the Purview Suite
- Microsoft 365 E5 Information Protection and Governance
Data Discovery & Classification tramite SQL Server Management Studio
La classificazione include due attributi di metadati:
- Etichette: gli attributi di classificazione principali, usati per definire il livello di riservatezza dei dati archiviati nella colonna
- Tipi di informazioni: offrono maggiore granularità del tipo di dati archiviati nella colonna
Di seguito vengono riportati i passaggi per la classificazione di un database di SQL Server:
Come primo passaggio aprire SQL Server Management Studio (SSMS)
Figura 6: Apertura SQL Server Management Studio
Figura 7: Connessione al Database tramite SQL Server Management Studio
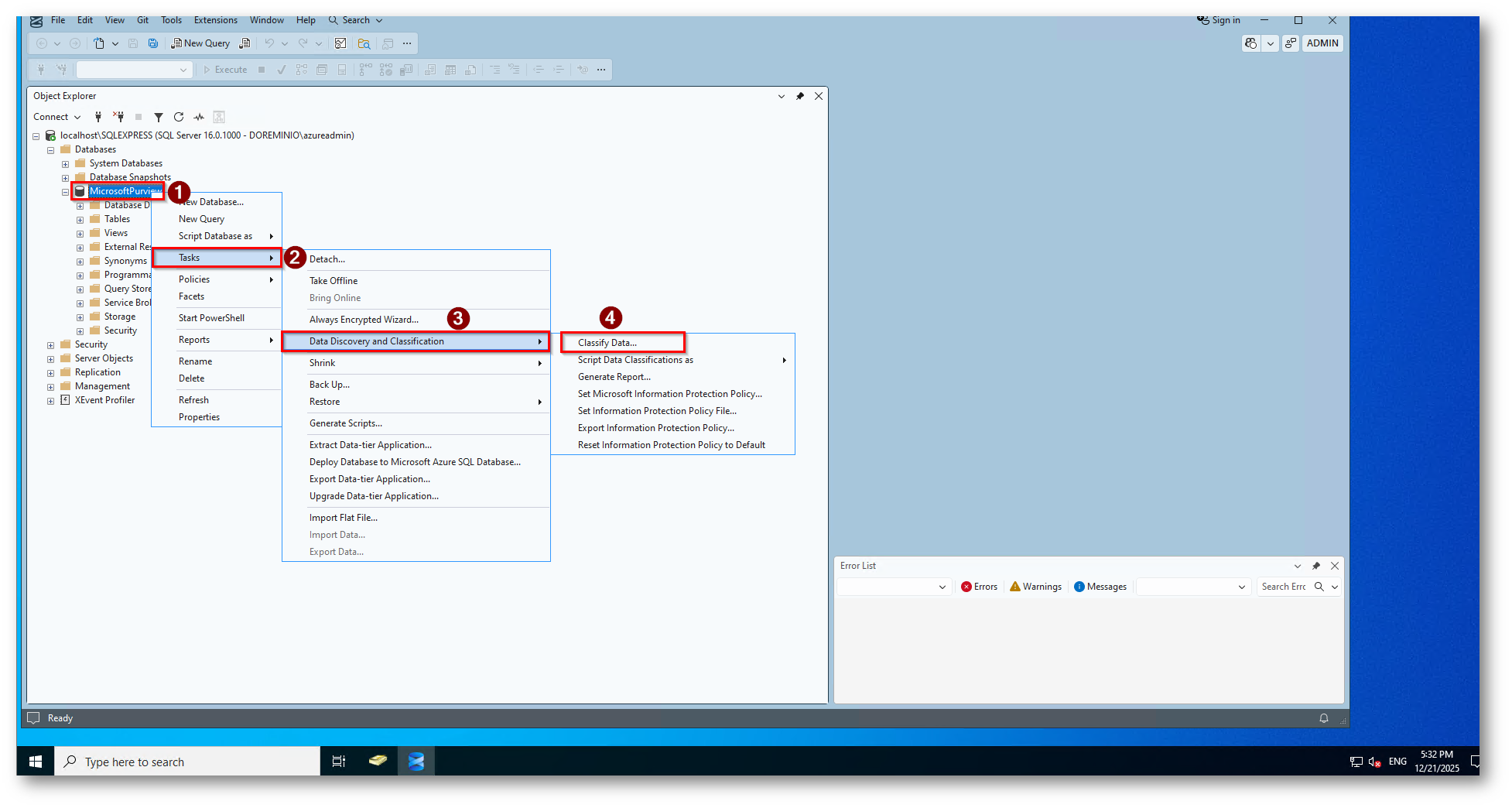
Figura 8: Click destro sul database Task, Data Discovery e Classify Data
A questo punto si attiva il motore di classificazione, che segue l’analisi del database per identificare, solo in base ai nomi, le colonne contenti dati potenzialmente sensibili e fornisce un elenco di classificazioni delle colonne consigliate.
Per visualizzare l’elenco delle classificazioni delle colonne consigliate, selezionare l’avviso di notifica:
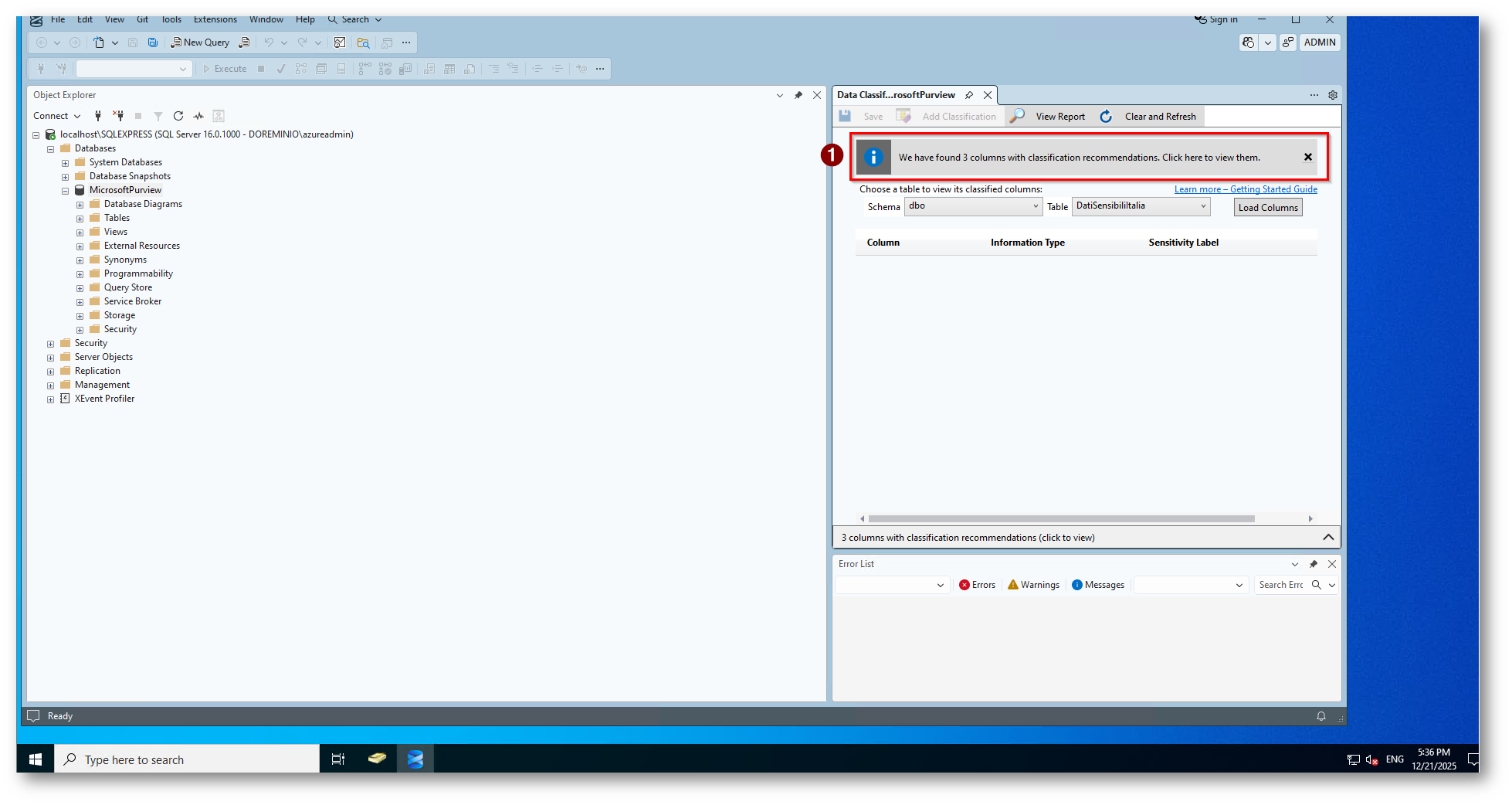
Figura 9: Notifica della data classification
A questo punto potete esaminare l’elenco dei consigli:
- Per “accettare” un consiglio per una colonna specifica, selezionare la casella di controllo nella colonna di sinistra.
- È possibile inoltre modificare l’etichetta di riservatezza e il tipo di informazioni consigliate usando le caselle a discesa
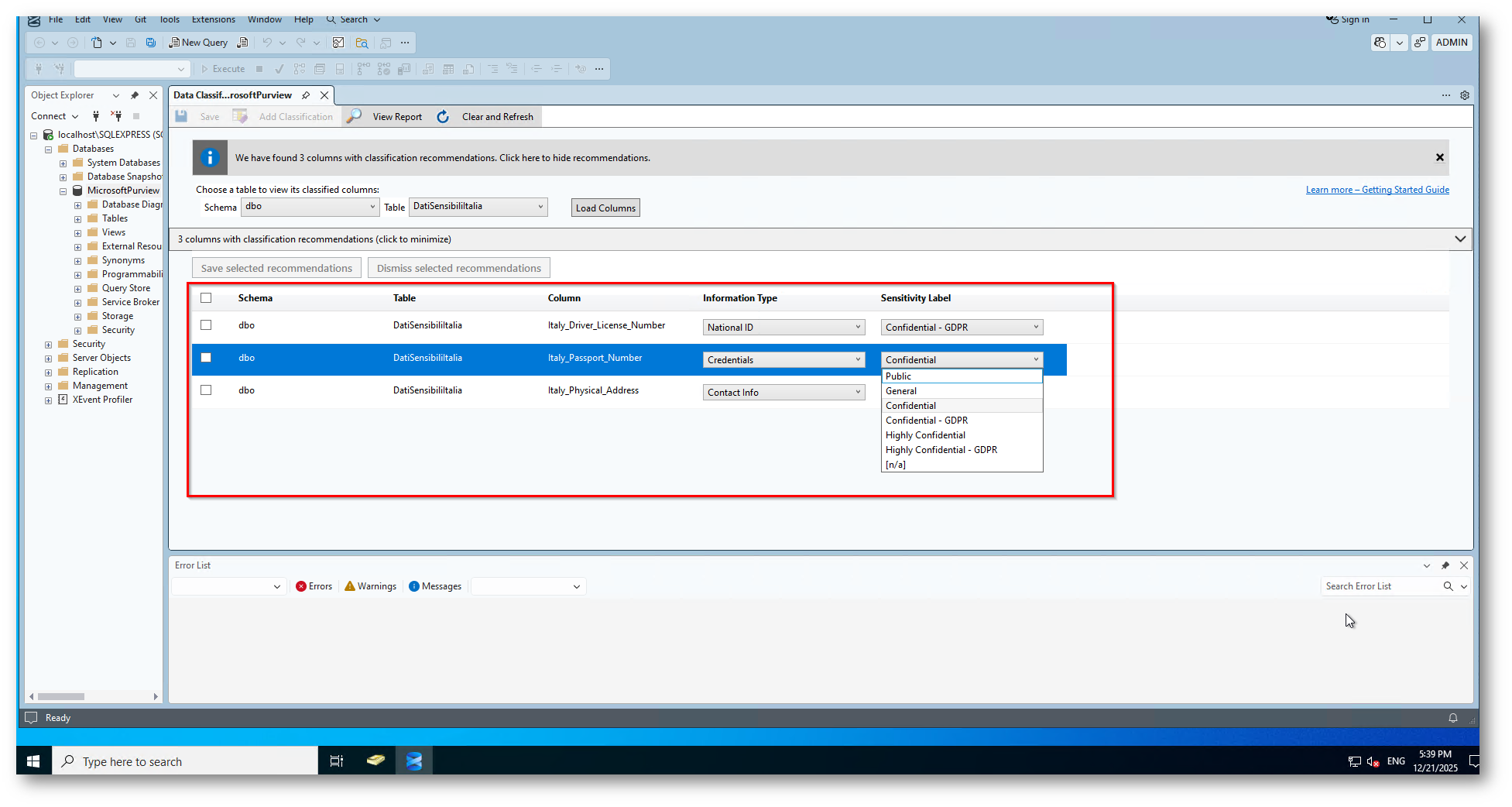
Figura 10: Colonne del database trovati dalla Data Classification
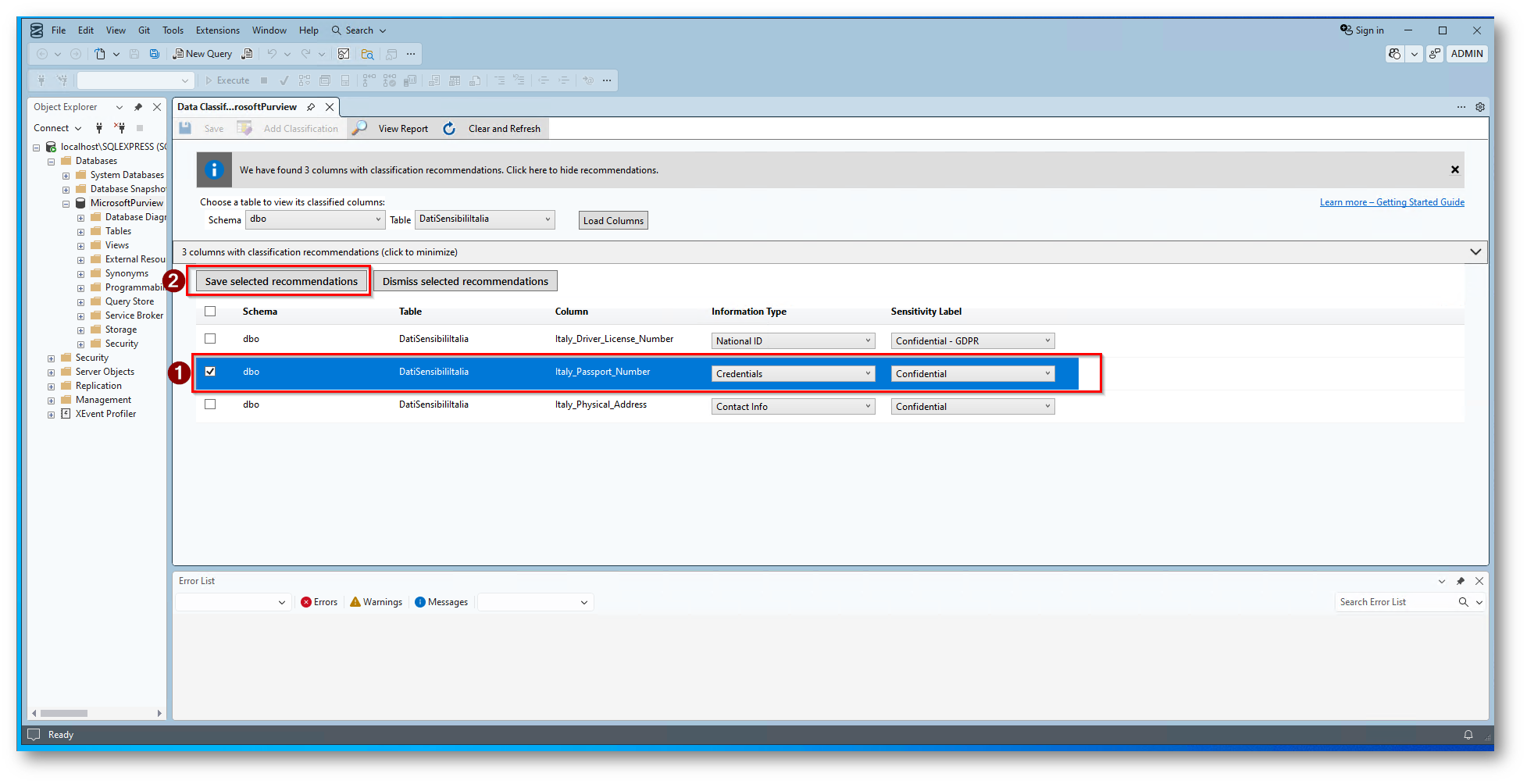
Figura 11: Salvataggio della raccomandazione che il sistema ci fornisce
NB: Questa tipologia di classificazione viene in automatico disabilitata quando utilizzate la classificazione tramite Microsoft Purview
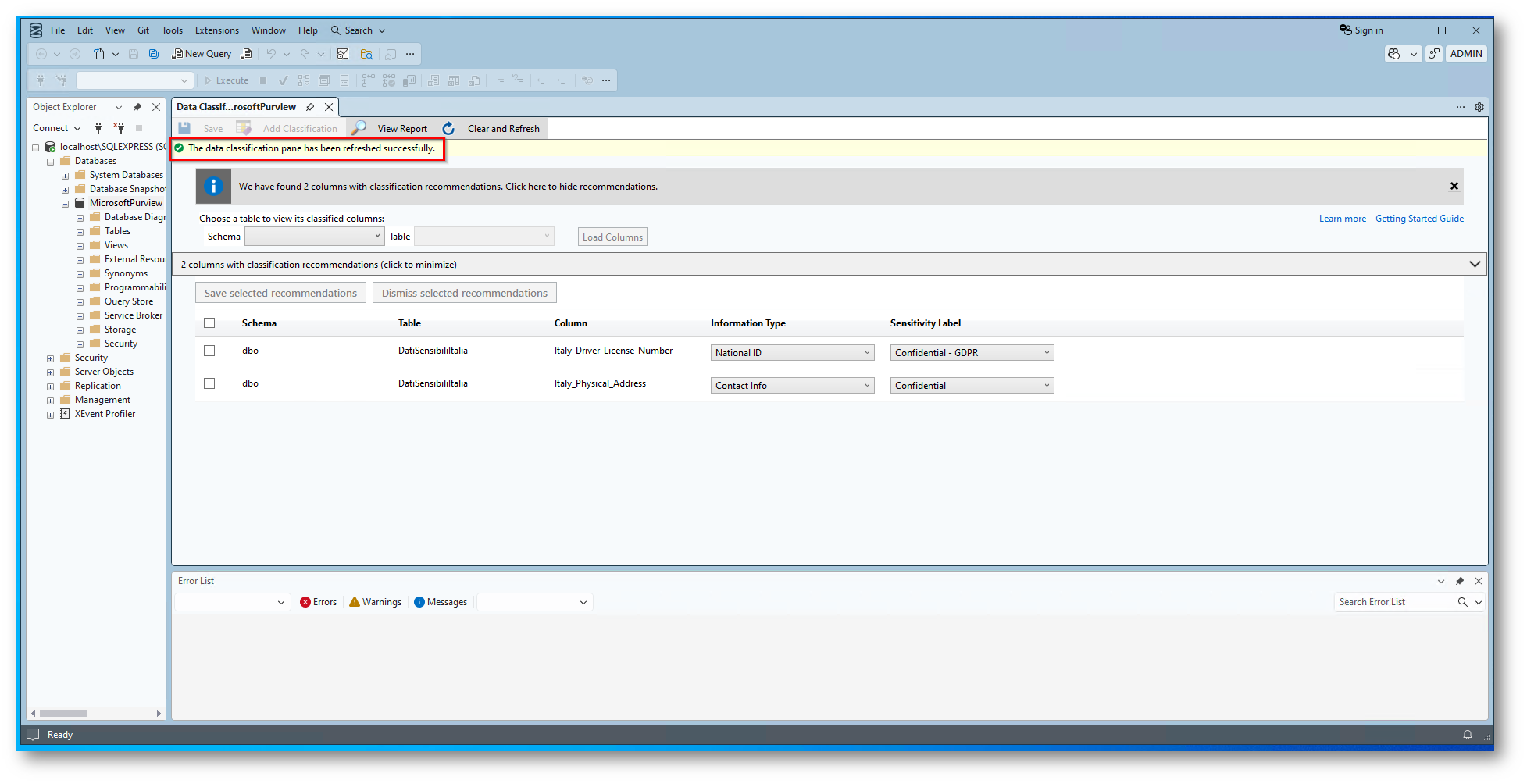
Figura 12: Una volta salvata la raccomandazione non la visualizziamo più
Potete anche procedere ad aggiungere una classificazione manuale
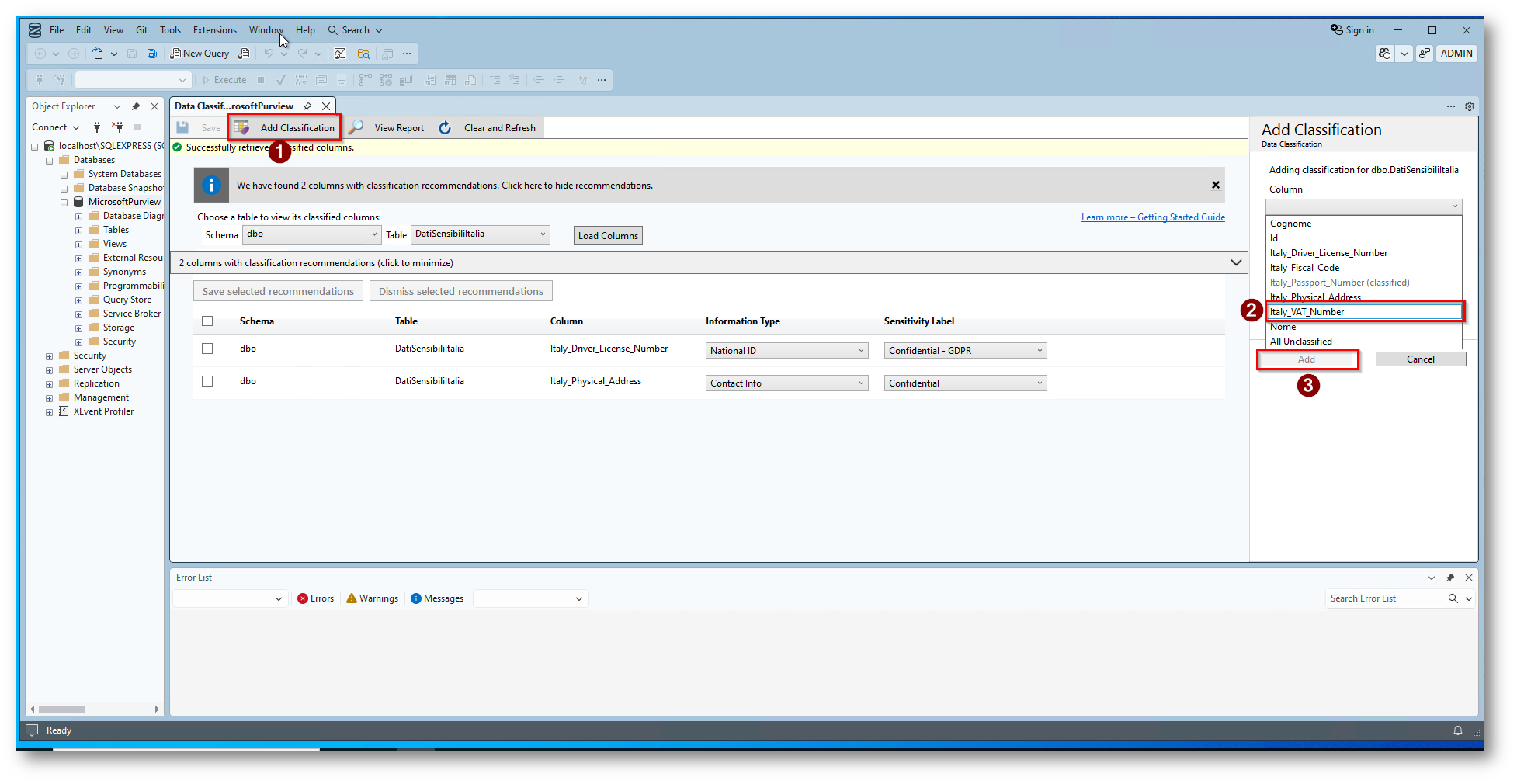
Figura 13: Aggiunta di una classificazione manuale
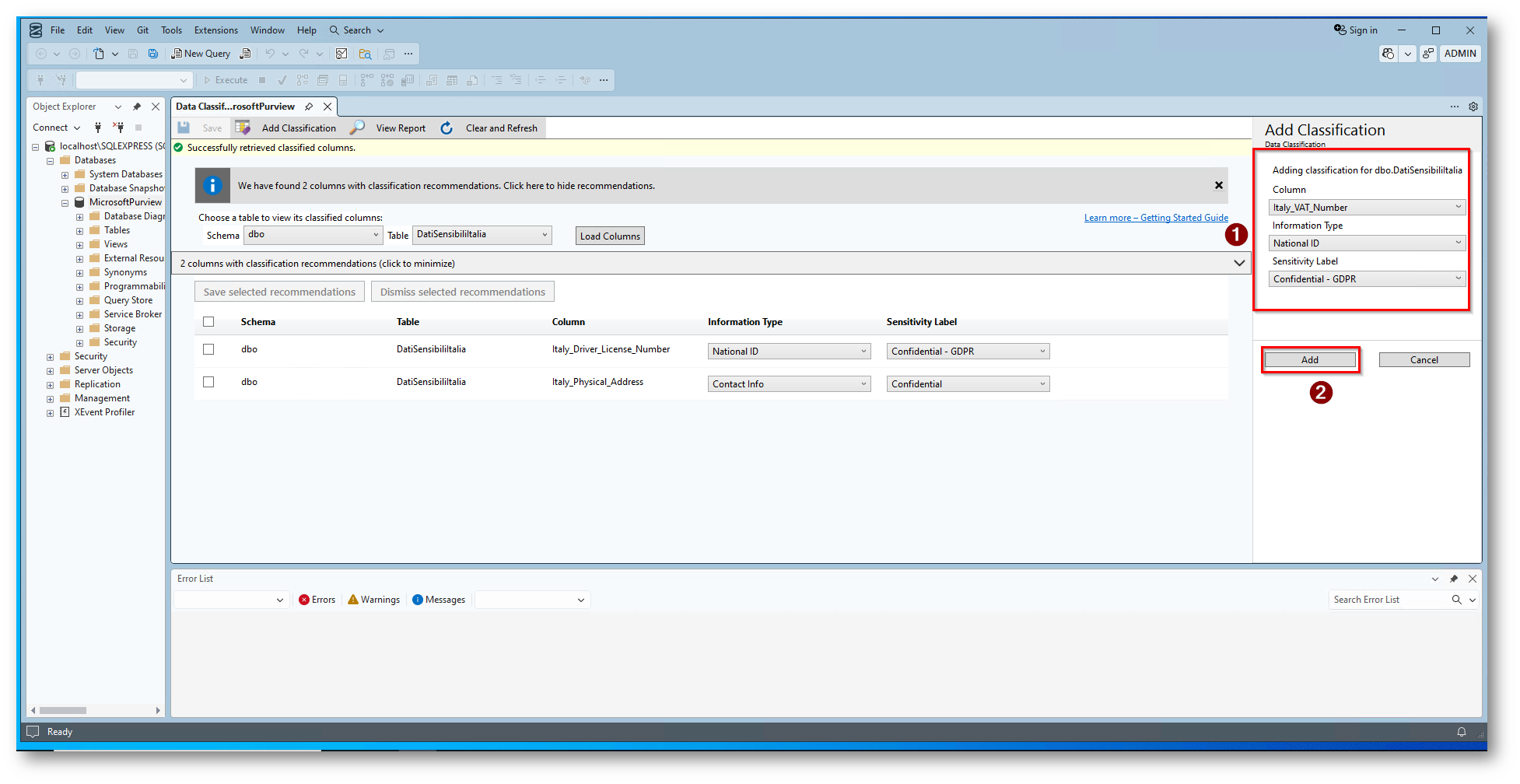
Figura 14: Seleziono la colonna “Italy_VAT_Number” come National ID
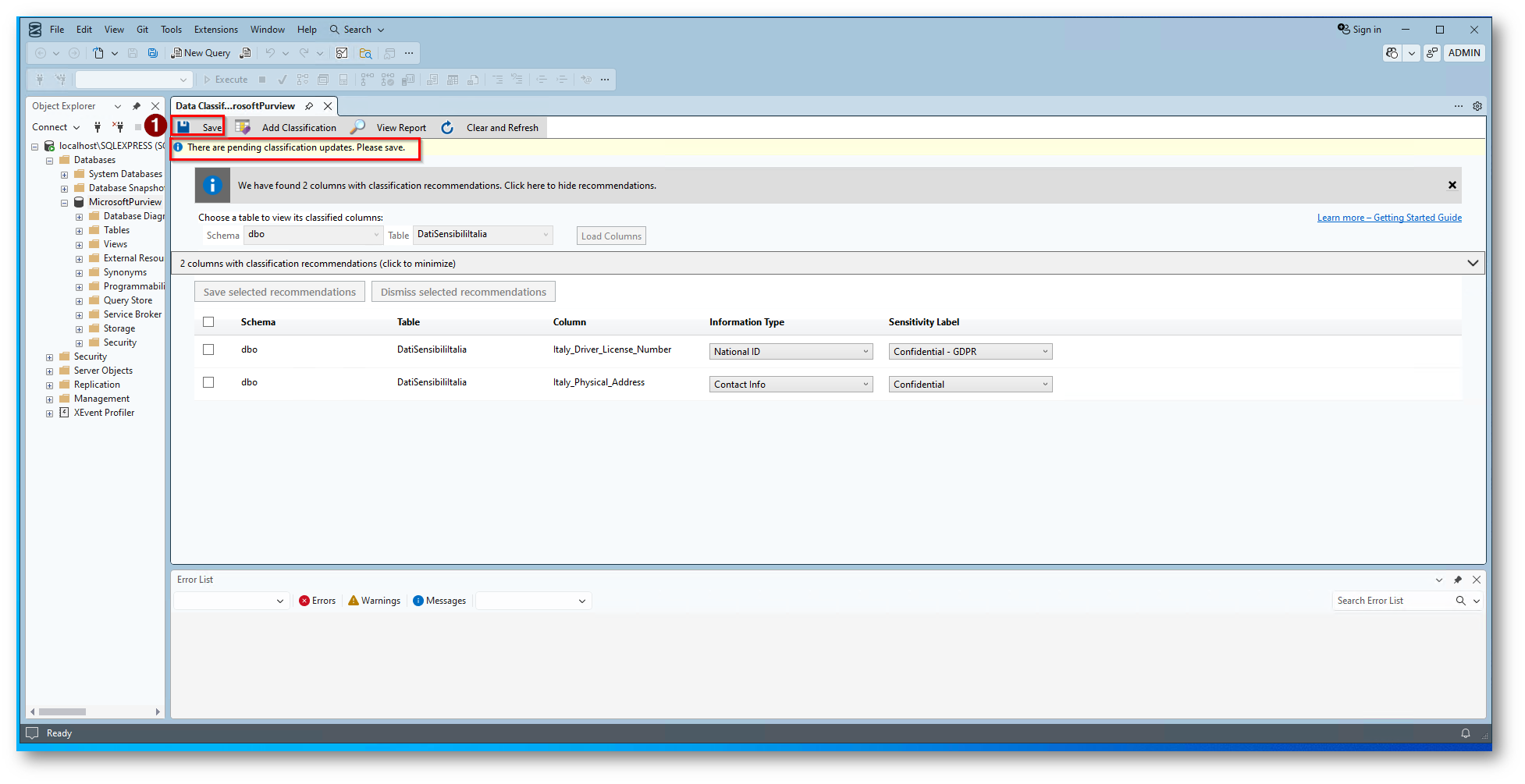
Figura 15: Salvataggio della configurazione
Abbiamo anche la possibilità di avere un report
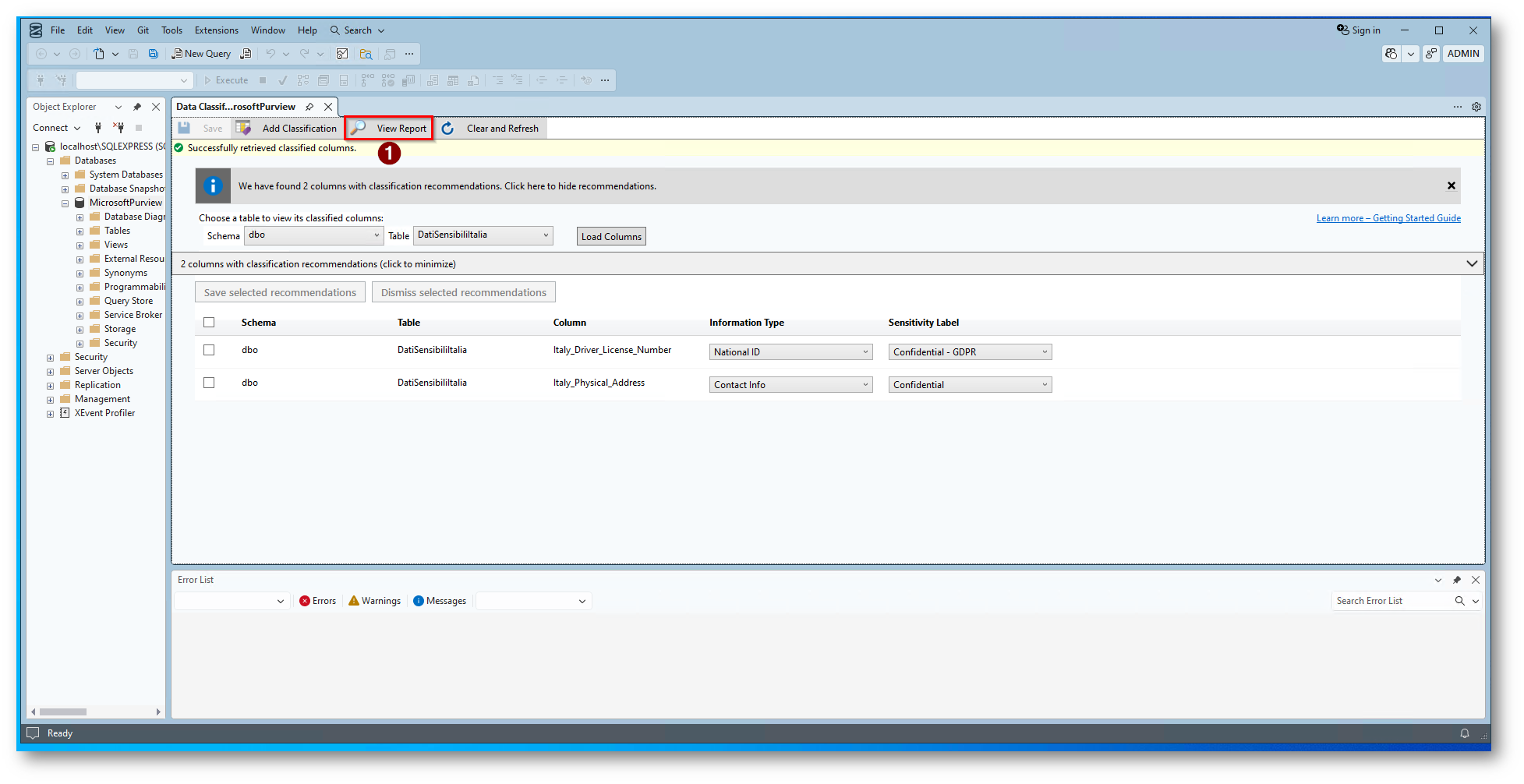
Figura 16: Visualizzazione Report
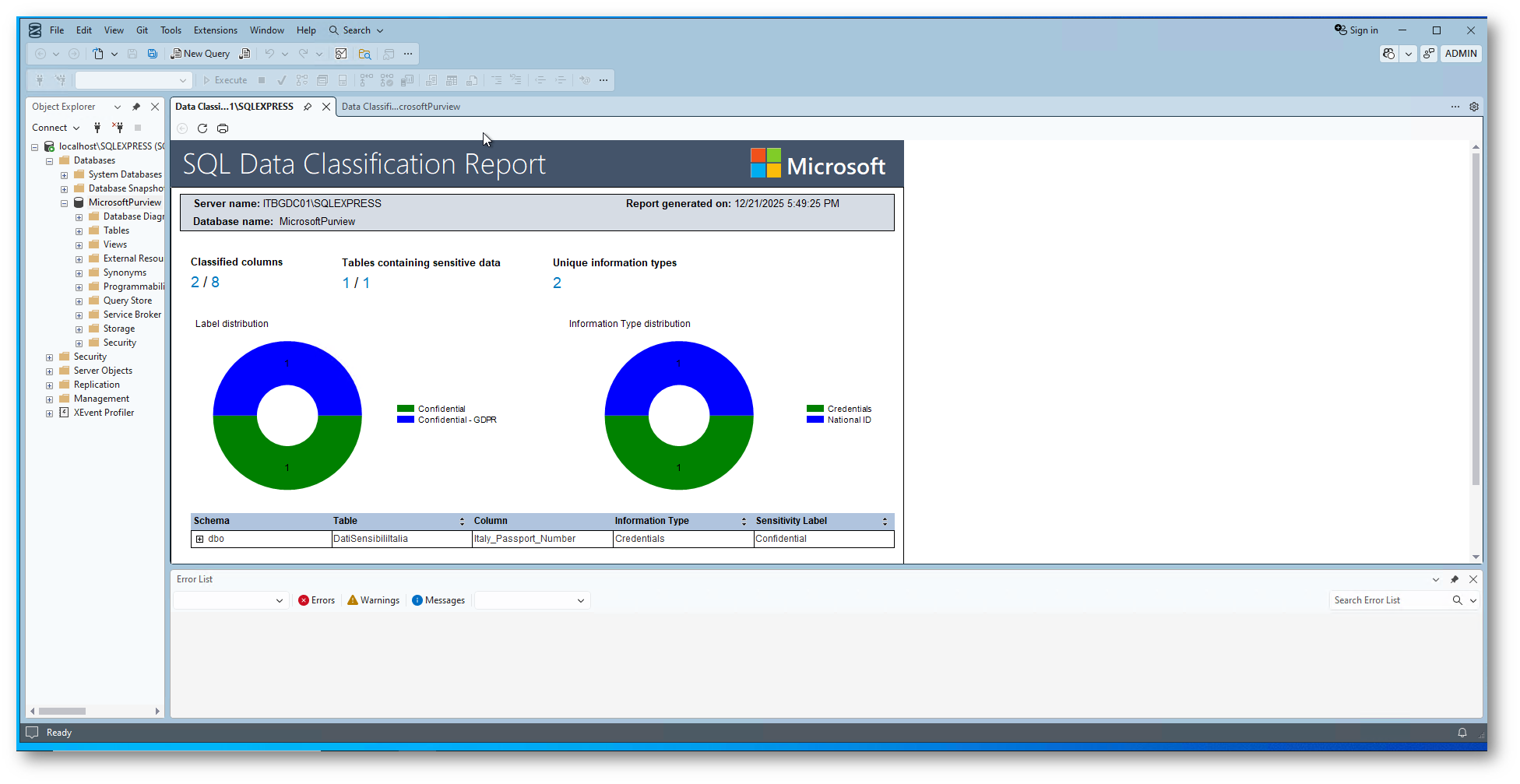
Figura 17: Report generato
Classificazione attraverso Microsoft Purview e SQL Server
Procediamo a creare una Sensitivity Label in Microsoft Purview per classificare la nostra tabella in SQL Server
Accediamo a Microsoft Purview
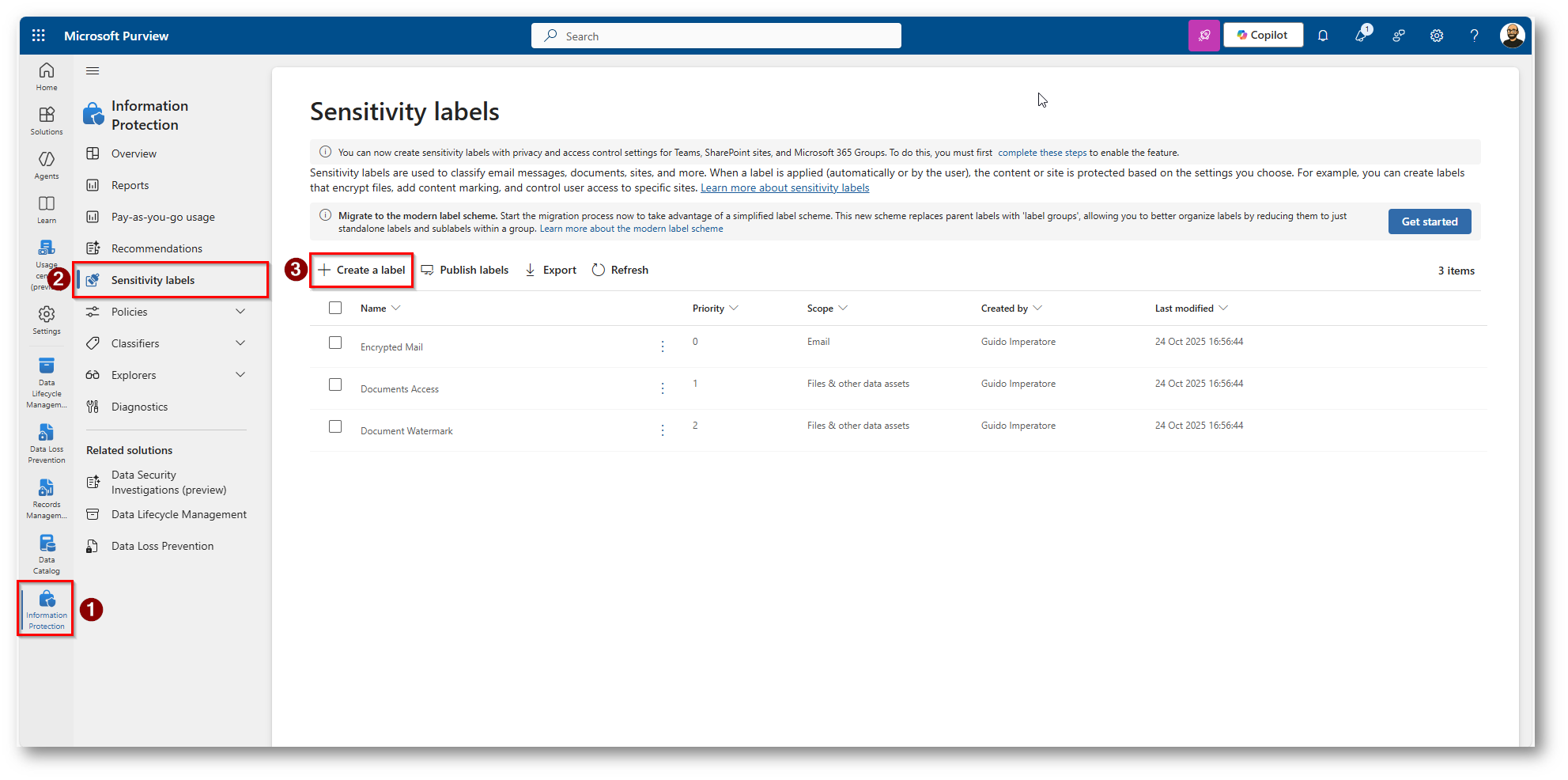
Figura 18: Creiamo una Label
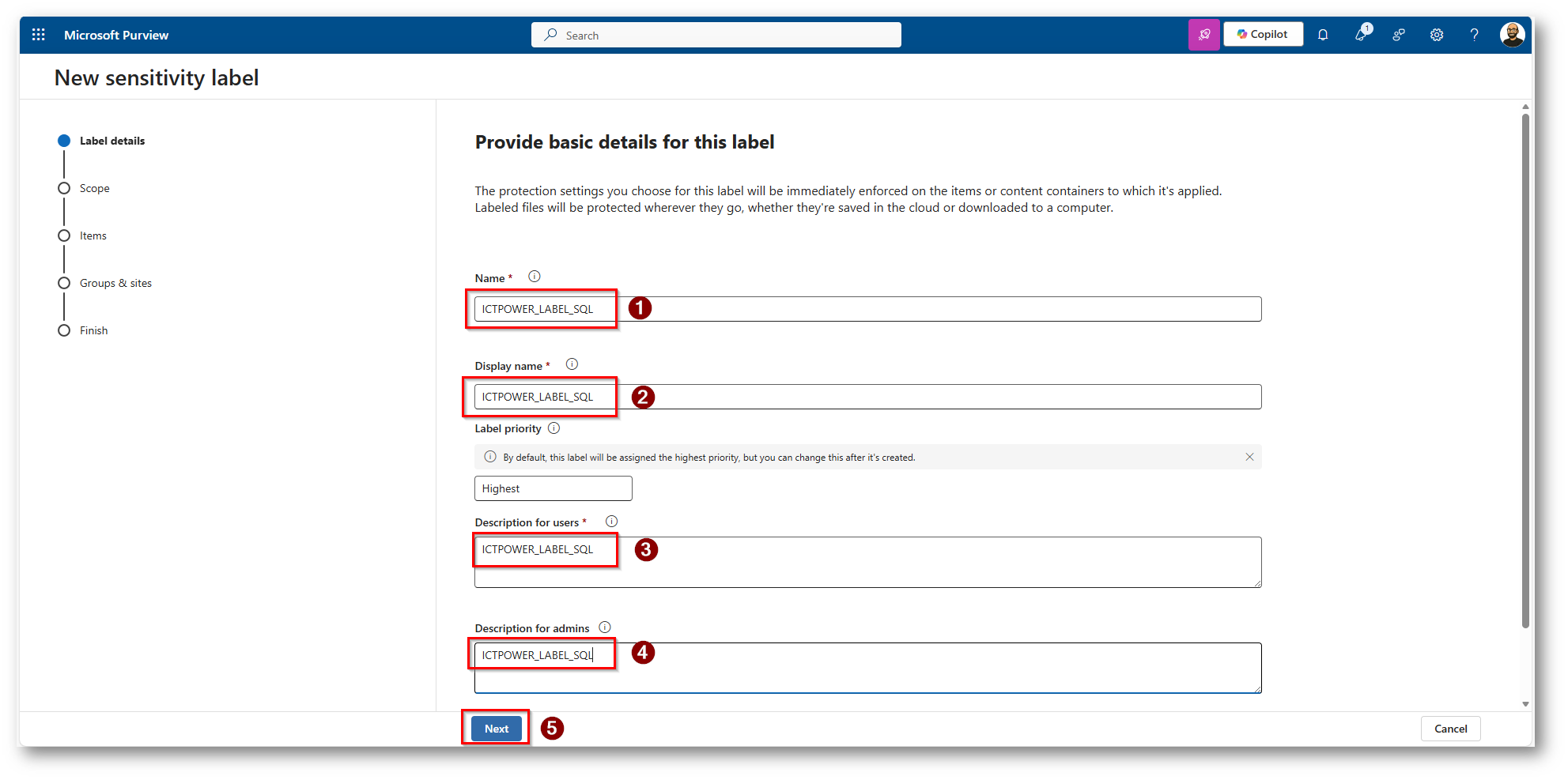
Figura 19: Scegliamo un nome, un display name, e una descrizione che siano parlanti per la Label
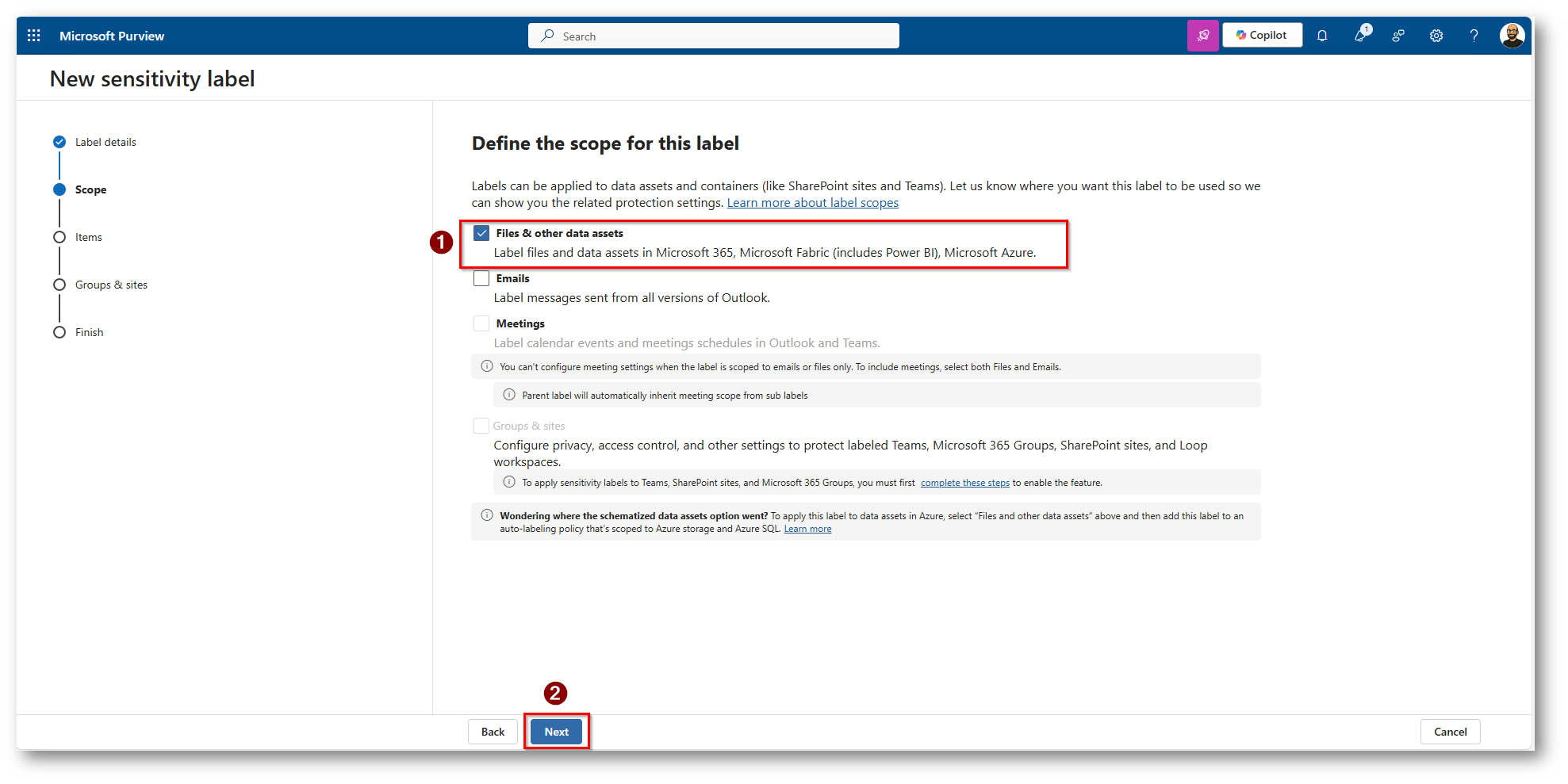
Figura 20: Selezioniamo File & Other Data Assets e proseguiamo con la configurazione
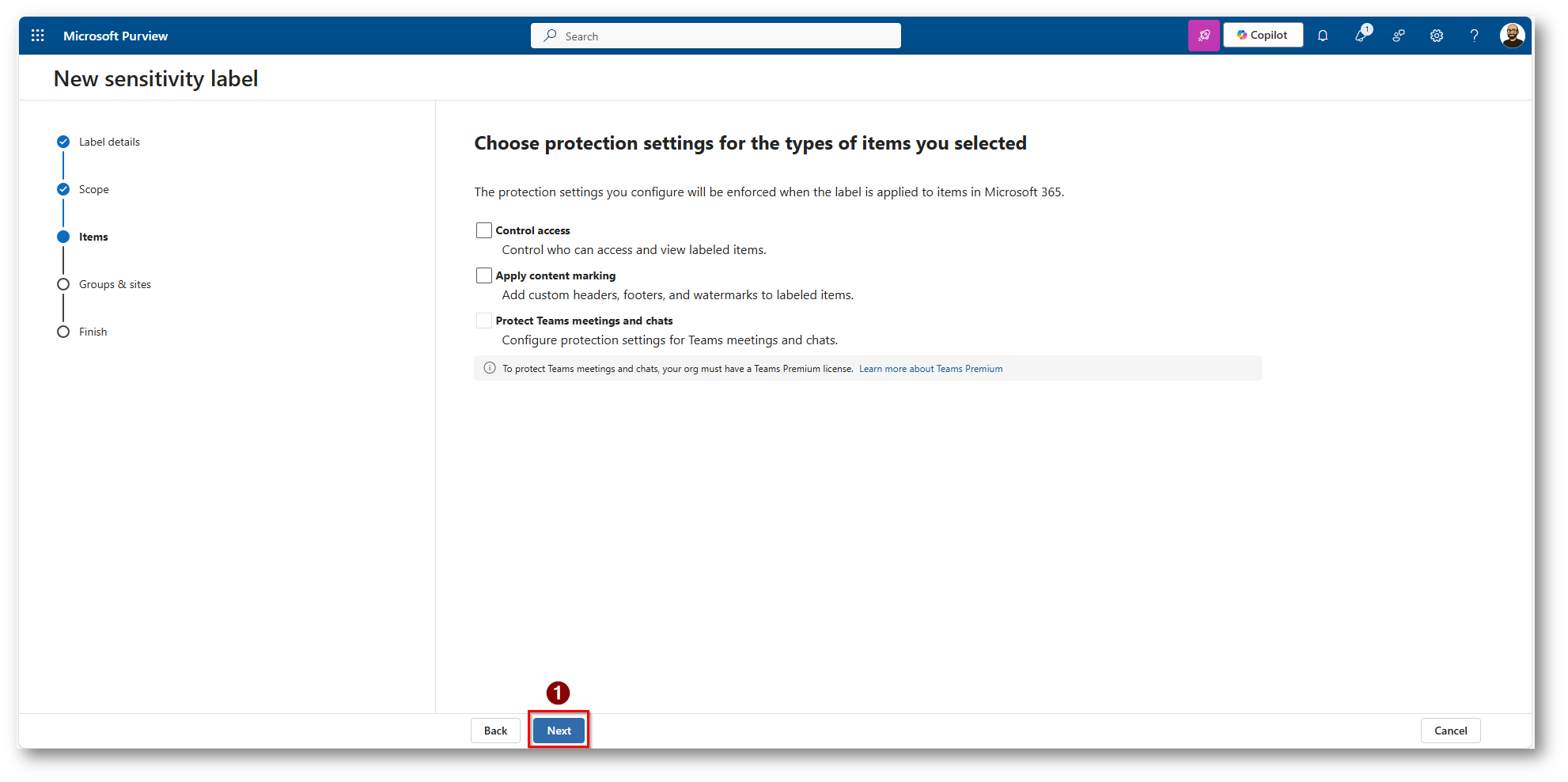
Figura 21: Scegliamo di non applicare nulla, in quanto ci interessa al momento solo applicare la Label a SQL, ma potremmo applicare un qualsiasi controllo di protezione che vogliamo
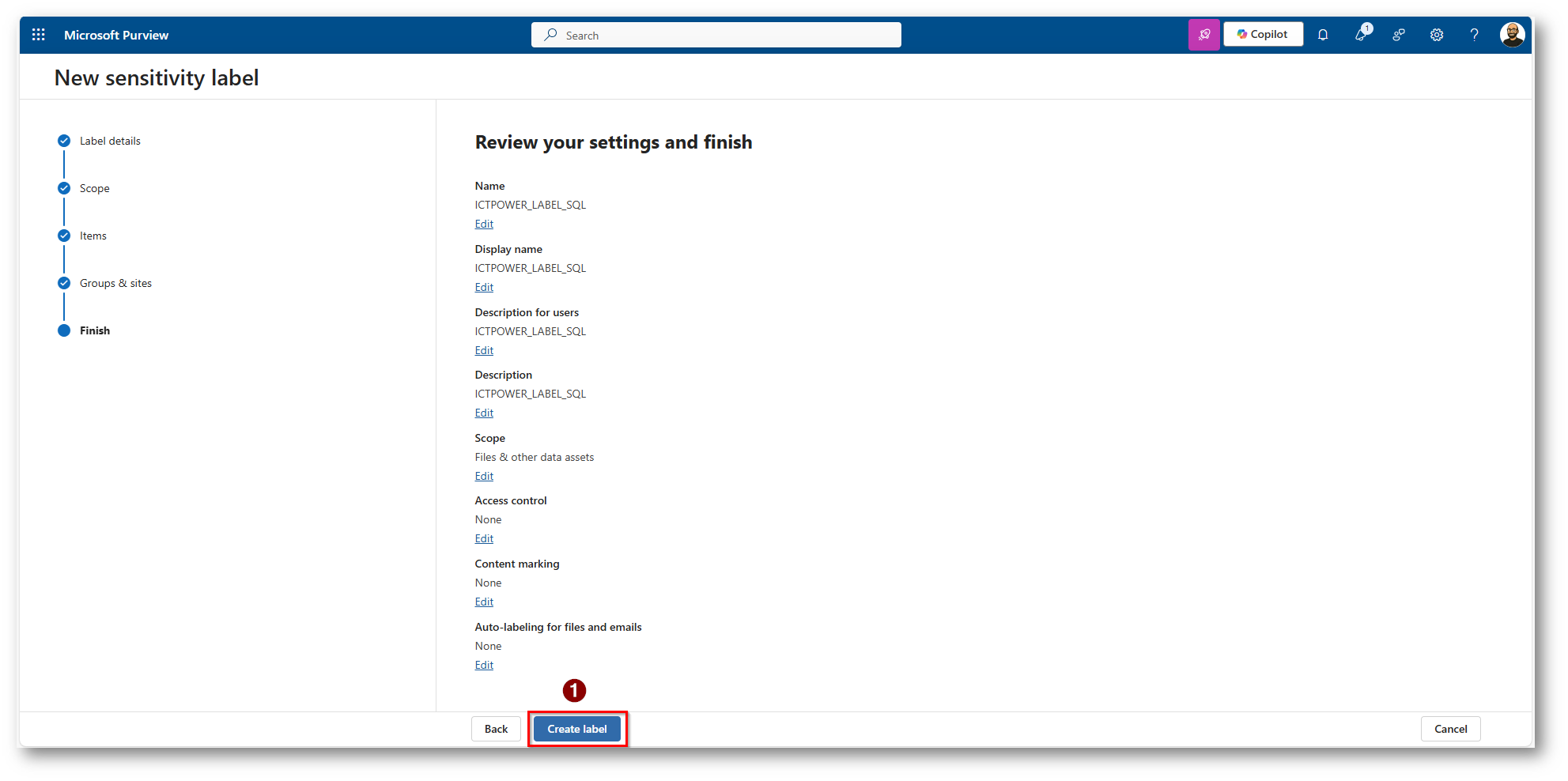
Figura 22: Salvataggio della Label
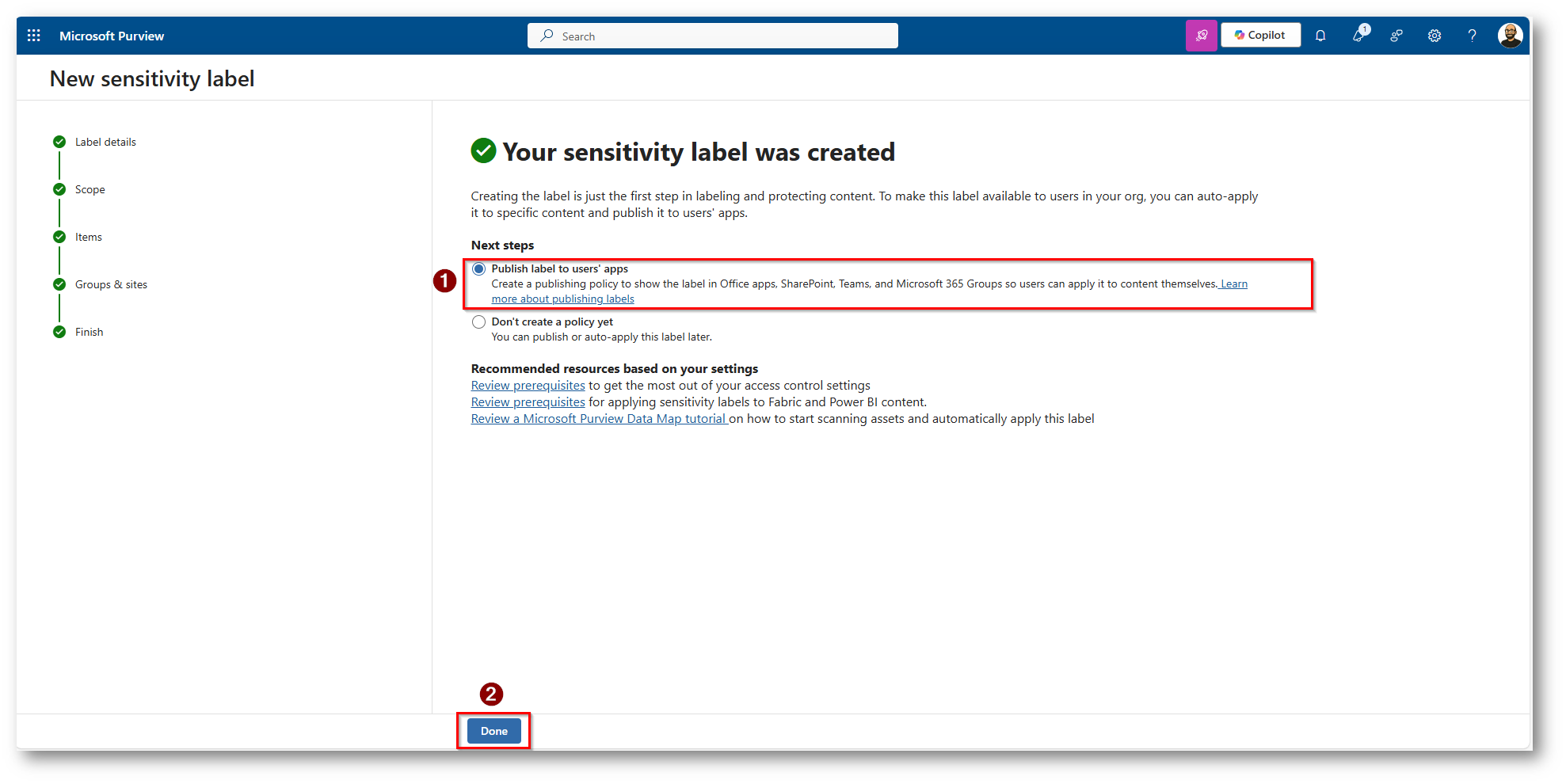
Figura 23: Scegliamo di Pubblicare la label con una Policy
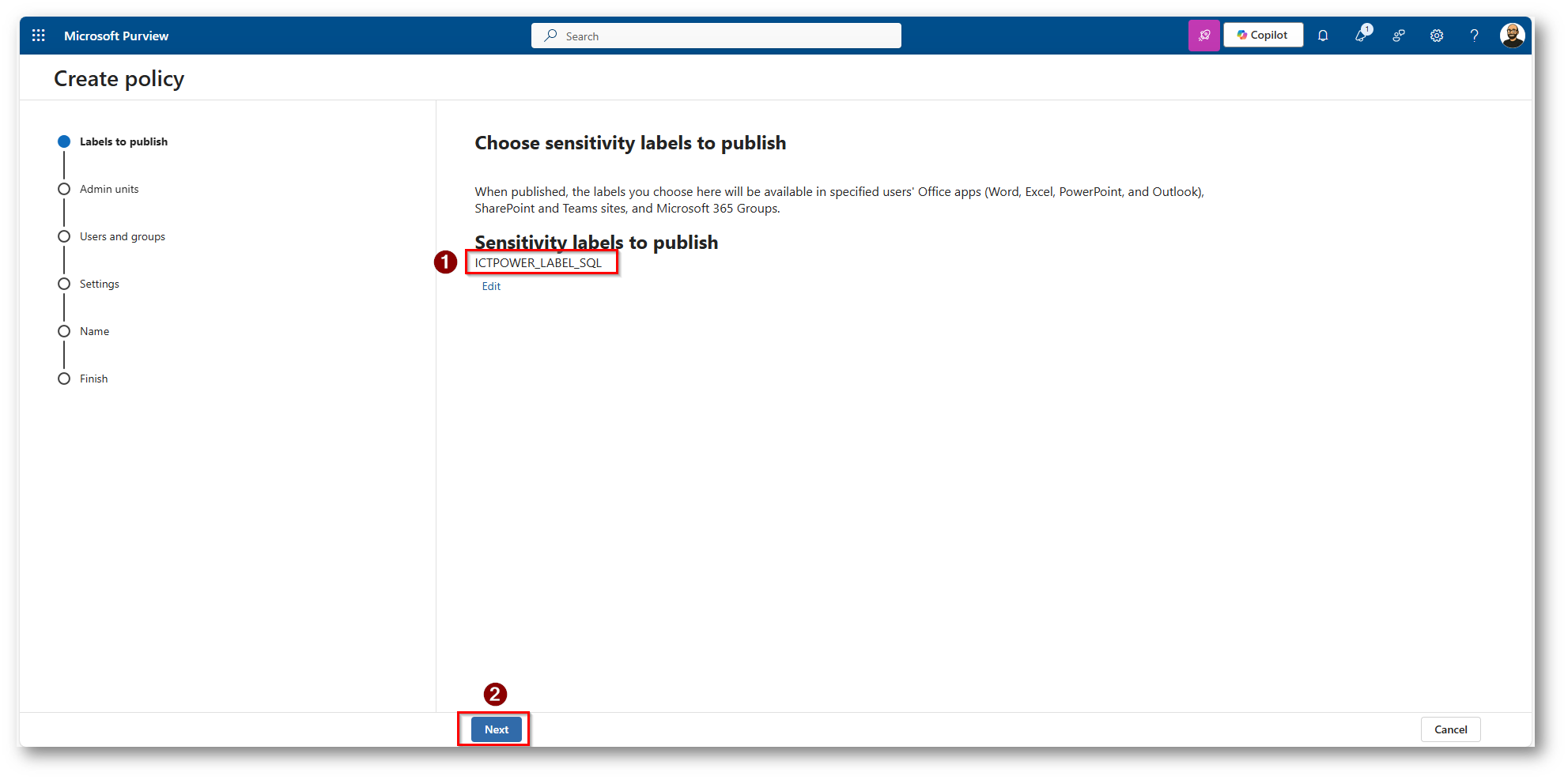
Figura 24: Selezioniamo di pubblicare la Label appena creata
Figura 25: Applichiamo la policy a tutta la directory
Figura 26: Scegliamo di applicare la policy a tutti gli utenti
Figura 27: Per tutti i workload selezionati non applichiamo una Label di Default
Figura 28: Scegliamo nome e descrizione parlante e proseguiamo con la configurazione
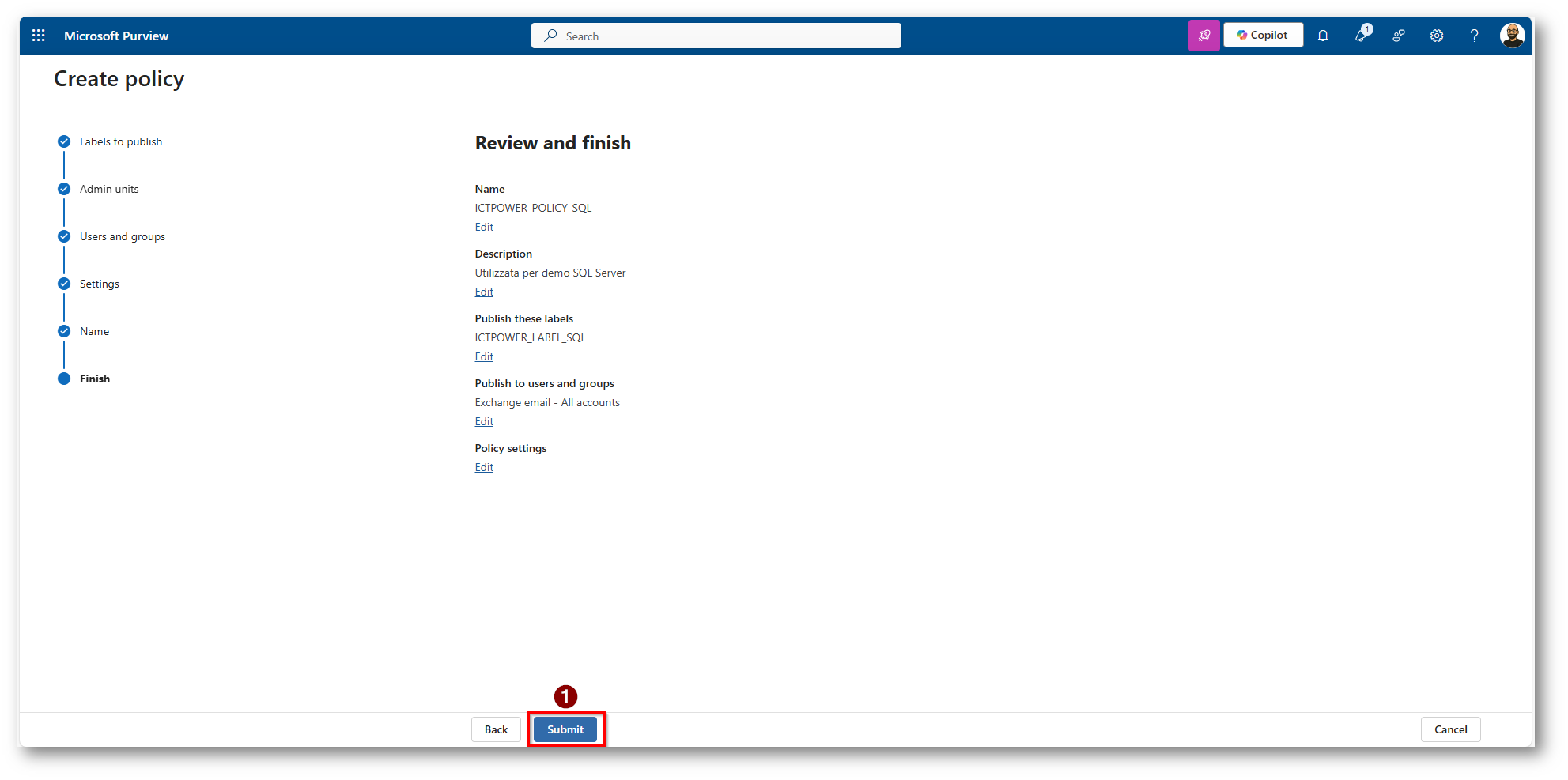
Figura 29: Pubblichiamo la Label
Ora saranno necessarie fino a 24h prima che la policy sia applicata all’utente, nel mio caso invece in circa 30 minuti la policy risultava già correttamente assegnata.
Ritorniamo quindi al nostro server SQL e apriamo SQL Server Management Studio
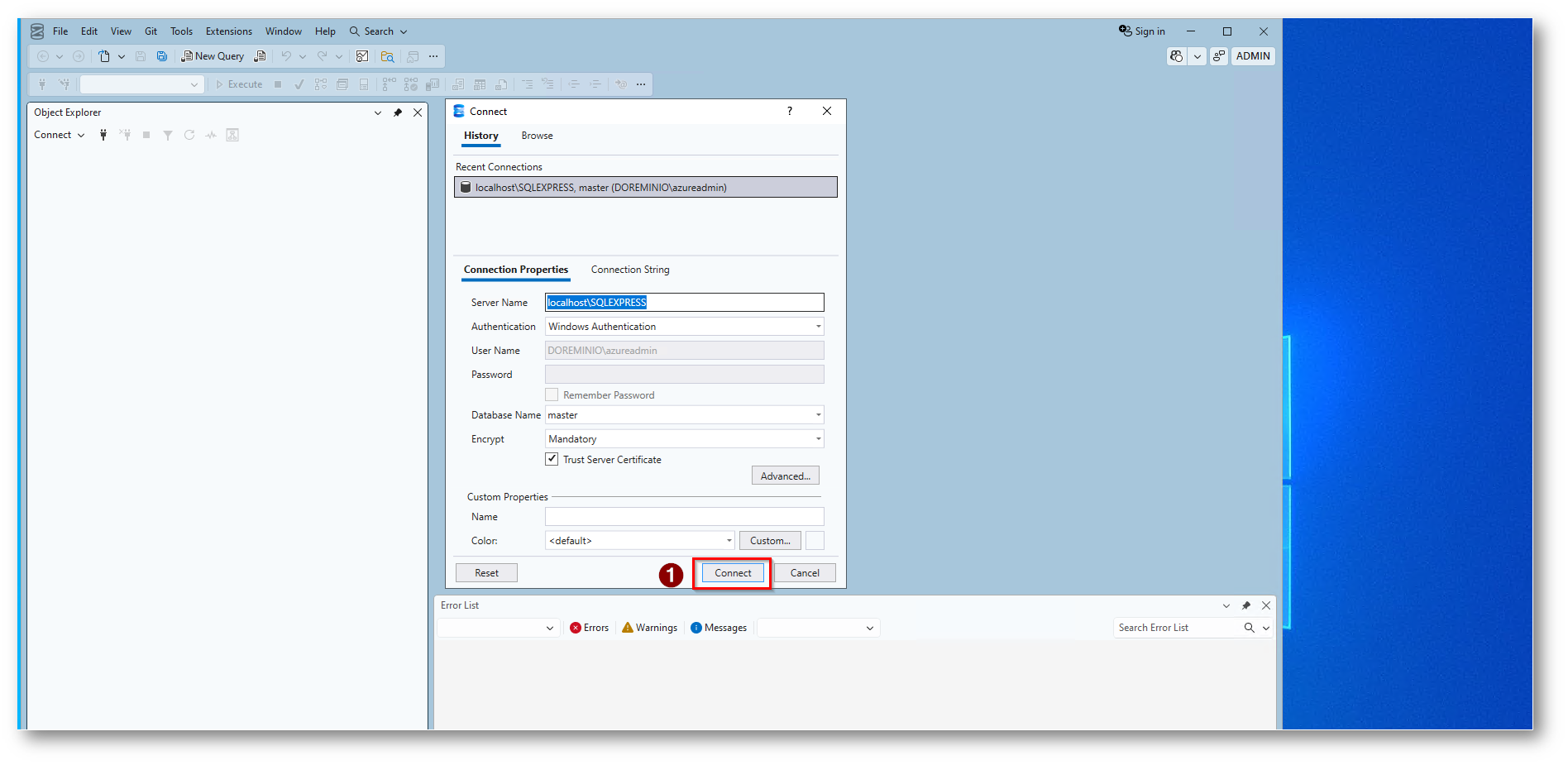
Figura 30: Collegamento al database tramite SQL Server Management Studio
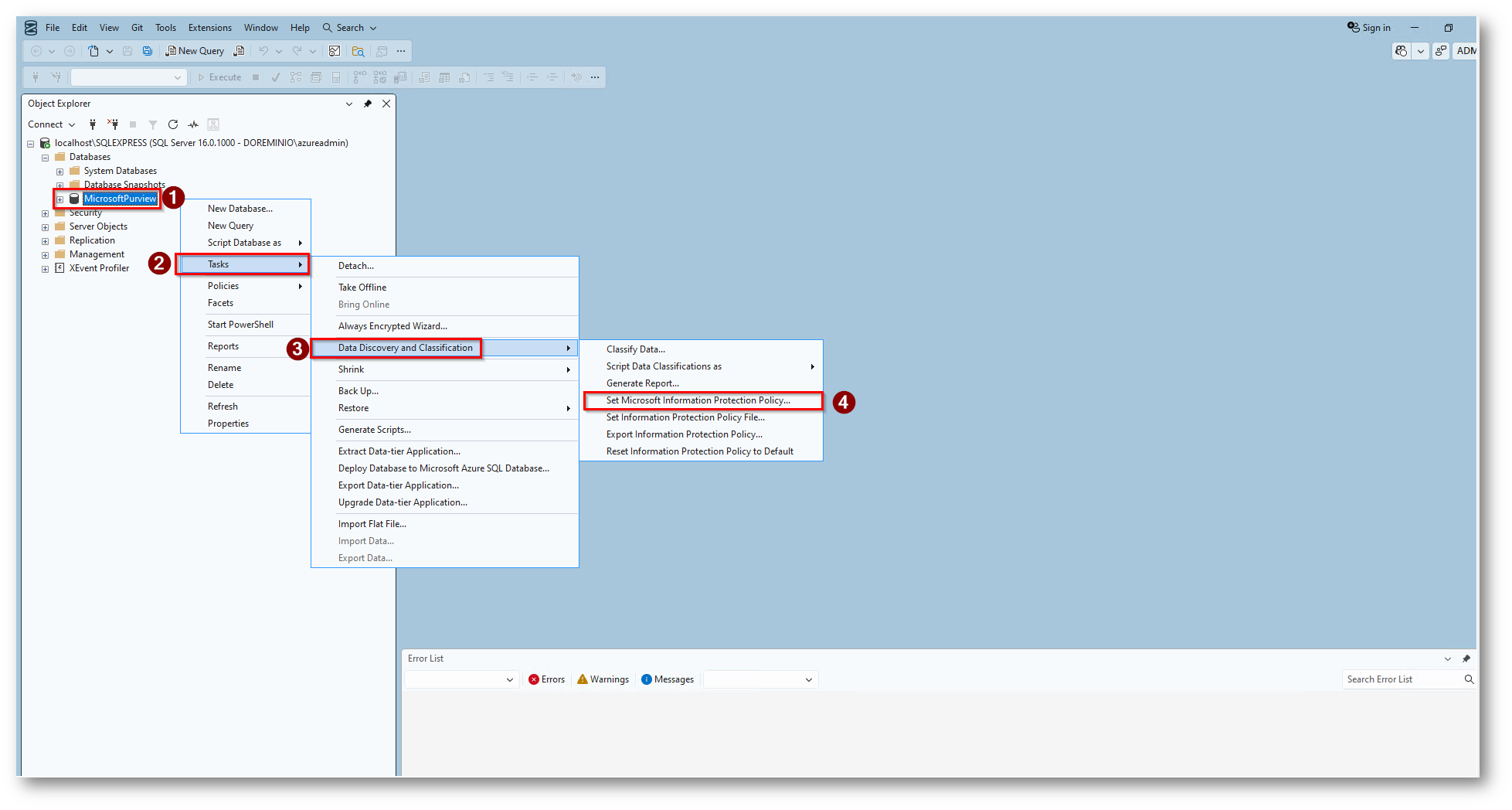
Figura 31: Procediamo con i passaggi per “collegare” la classificazione del database con il servizio di Microsoft Purview
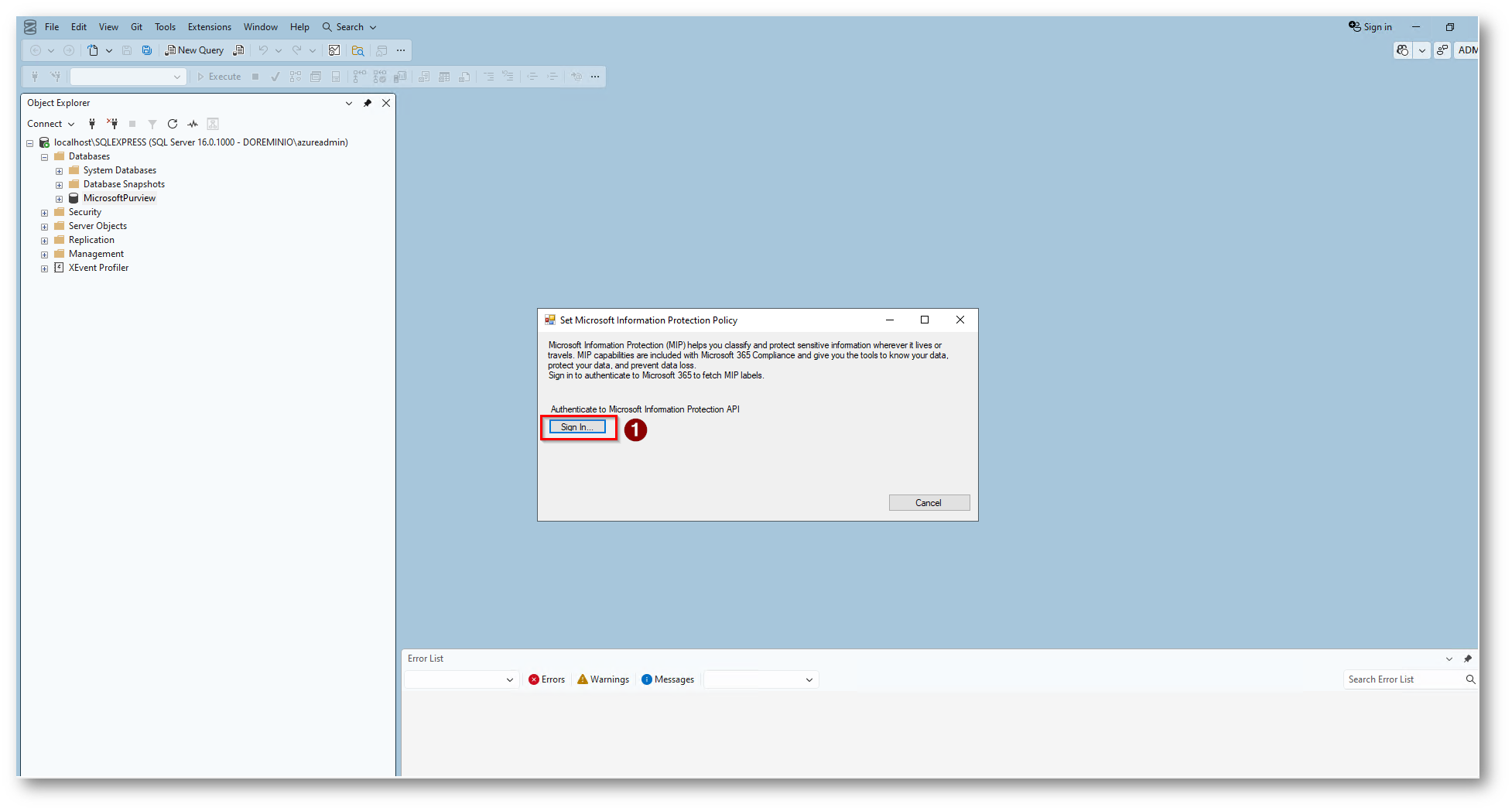
Figura 32: Richiesta di Login per caricare le Label di Information Protection, io accederò con il mio utente
Figura 33: Inserimento utente che ha associato delle Label
Figura 34: Inserimento credenziali e Login con la nostra utenza
Figura 35: All’utente è associata una CA Policy che richiede il secondo fattore di autenticazione
Figura 36: Policy creata correttamente
Ora possiamo procedere a classificare i file con le Policy presenti in Microsoft Purview
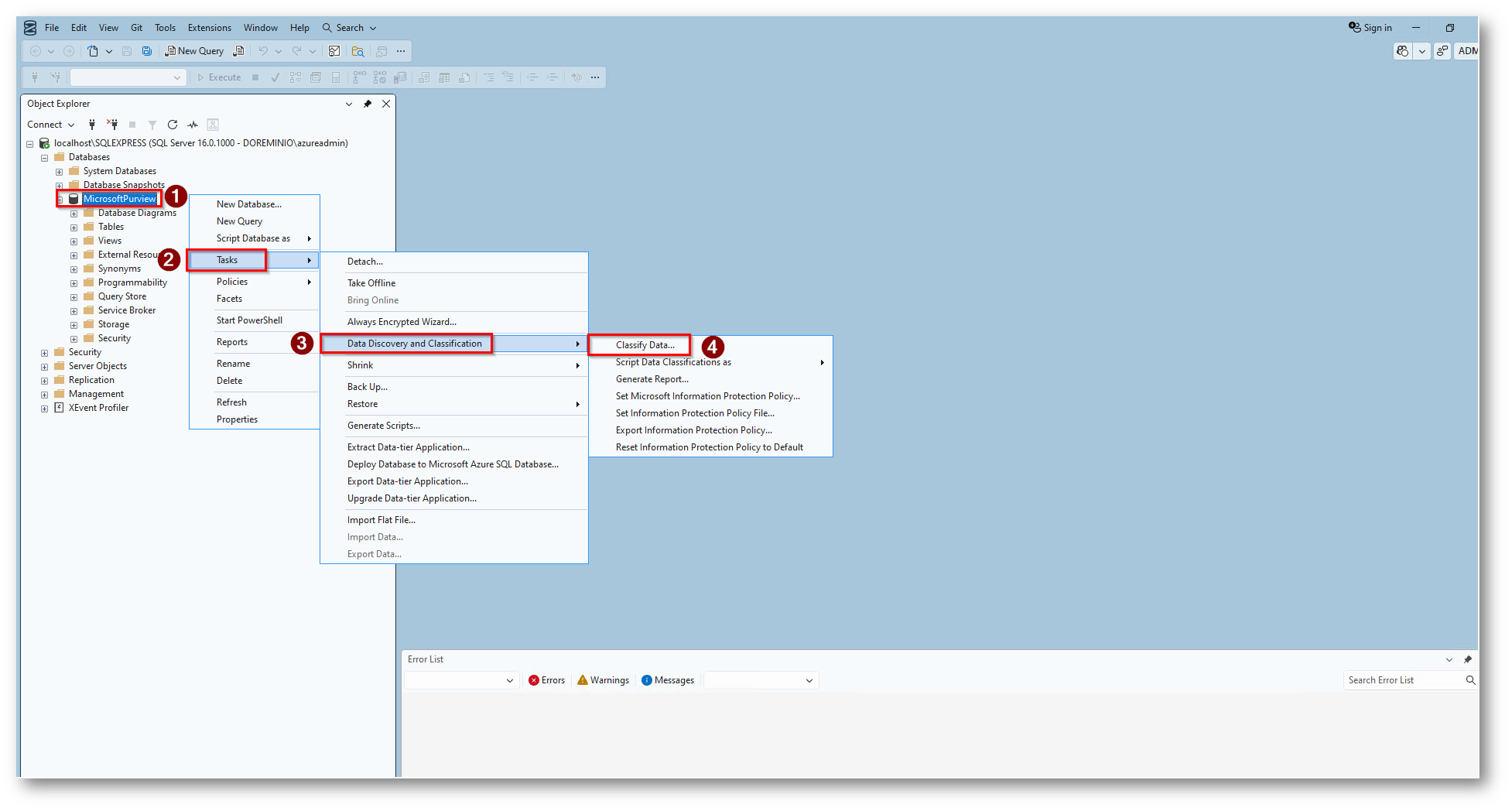
Figura 37: Procediamo alla classificazione dei dati con le policy presenti in Microsoft Purview
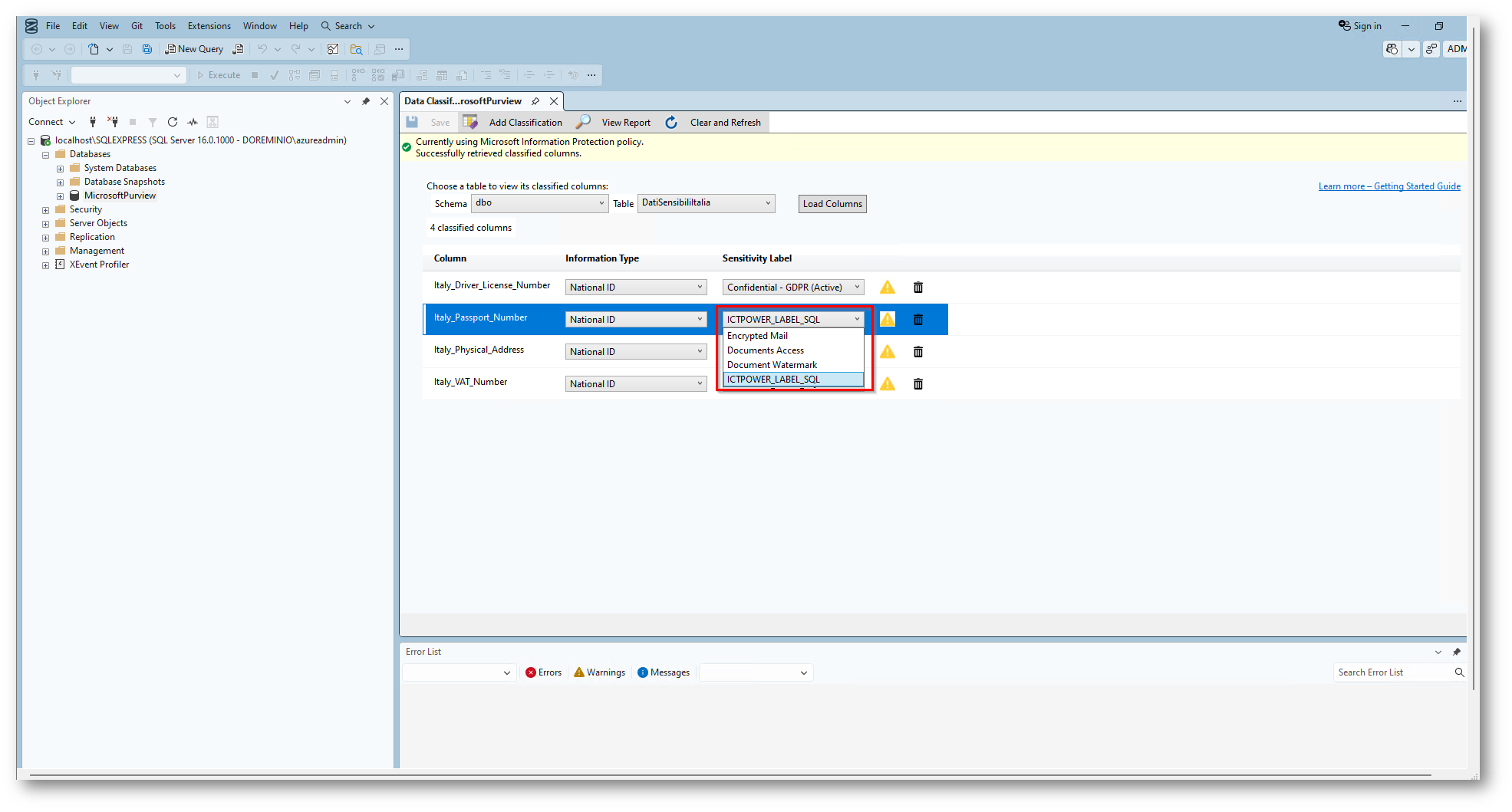
Figura 38: Vedete che ora vengono rilevate le Label associate all’utente con cuoi abbiamo accesso e possiamo salvarle
Specifico che il triangolo di colore Giallo indica che la Label associata non rispecchia la classificazione, ve lo indico così se dovesse capitarvi sapete a cosa è dovuto.
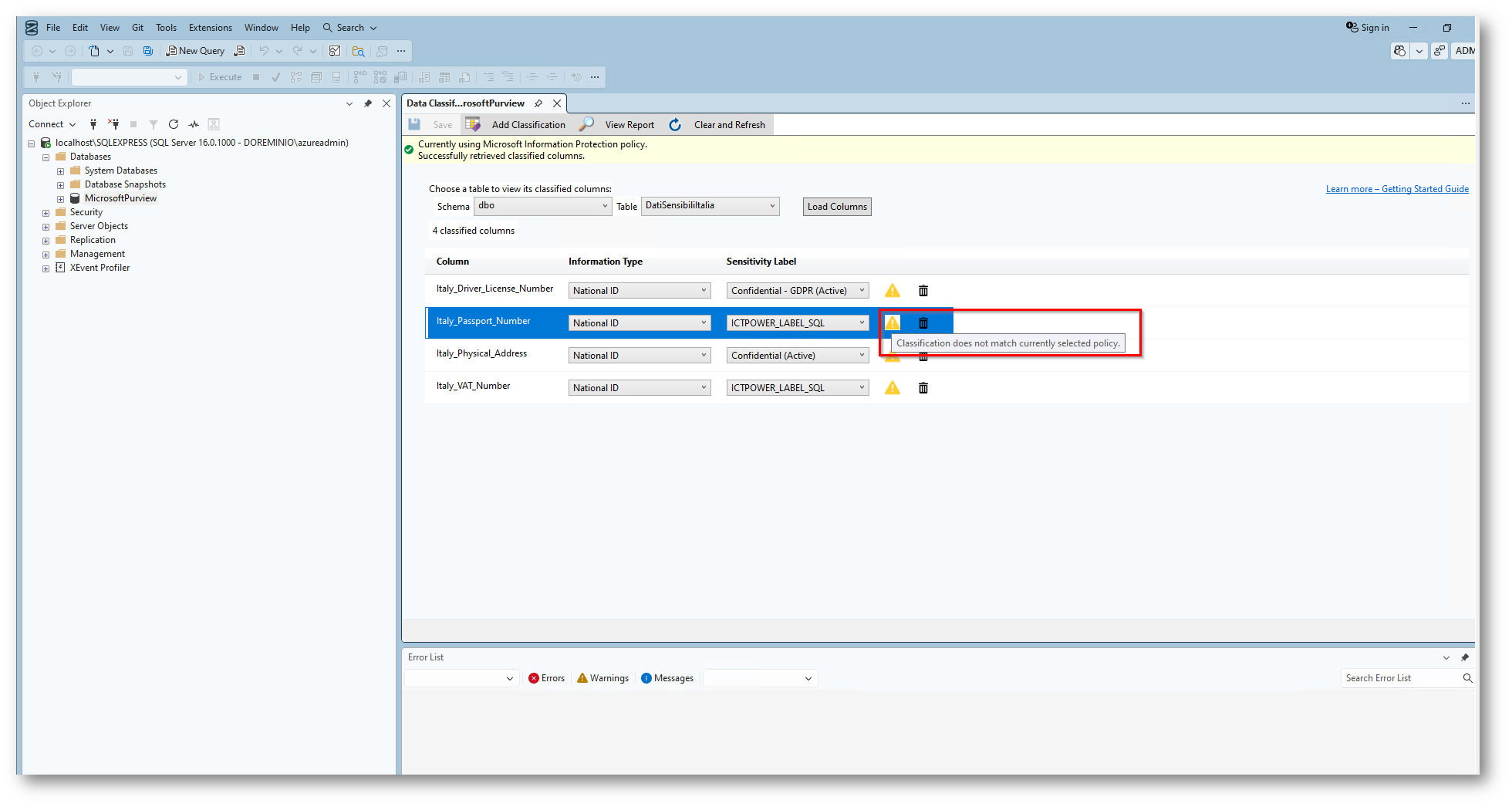
Figura 39: Label che non rispetta la classificazione
Cosa succede dopo l’applicazione di un’etichetta di classificazione
Dopo aver applicato un’etichetta di riservatezza a una colonna di un database SQL, non viene attivata automaticamente alcuna protezione tecnica sul dato. La colonna rimane accessibile secondo i permessi SQL esistenti e il comportamento delle applicazioni non subisce variazioni. Questo è un aspetto fondamentale da chiarire, poiché la classificazione non equivale a crittografia, mascheramento o blocco degli accessi.
L’effetto principale dell’etichetta è l’aggiunta di metadati di classificazione persistenti, che descrivono in modo esplicito la natura e il livello di sensibilità del dato. In questo modo l’informazione diventa visibile, tracciabile e governabile all’interno dei processi di sicurezza e compliance.
Questa classificazione consente di ottenere piena visibilità sui dati sensibili, supportare attività di audit e dimostrare la conformità normativa. La protezione, in questa fase, è quindi di tipo informativo e organizzativo, non ancora tecnico.
Il valore della classificazione emerge quando le etichette vengono utilizzate come base per policy di sicurezza e Data Loss Prevention, che possono applicare controlli coerenti quando i dati vengono utilizzati, esportati o condivisi. In questo modello, la protezione non è nell’etichetta in sé, ma nei controlli che fanno riferimento a quella classificazione.
È quindi essenziale distinguere tra classificazione ed enforcement: la classificazione definisce che tipo di dato è, mentre l’enforcement stabilisce cosa è consentito fare con quel dato. SQL Server continua a gestire l’enforcement tramite i propri meccanismi nativi, mentre Microsoft Purview fornisce il livello di governance e coerenza.
L’etichetta non protegge direttamente il dato, ma rappresenta il prerequisito fondamentale per costruire una strategia efficace di sicurezza, governance e conformità orientata al dato.
Esempio di utilizzo della classificazione con una policy di Data Loss Pfrevention (DLP)
Supponiamo di avere un database SQL che contiene una tabella con una colonna etichettata come dato personale o dato altamente riservato, ad esempio un codice fiscale o un numero di documento. La colonna è stata classificata tramite Microsoft Purview e l’etichetta è correttamente applicata.
Dal punto di vista di SQL Server, nulla cambia: le query continuano a funzionare e gli utenti autorizzati possono leggere il dato. Tuttavia, nel momento in cui quel dato esce dal database, entra in gioco la Data Loss Prevention.
Immaginiamo che un utente esegua una query e esporti il risultato in un file Excel, oppure che un’applicazione prelevi quei dati e li salvi in un file o li invii via email. Grazie alla classificazione applicata alla colonna, il dato viene riconosciuto come sensibile anche nel nuovo contesto. A questo punto una policy DLP può intervenire.
La policy DLP, ad esempio, può rilevare che il file contiene informazioni classificate come riservate e impedire l’invio tramite email verso destinatari esterni, oppure consentirlo solo dopo una giustificazione o l’approvazione di un responsabile. In alternativa, può bloccare il caricamento del file su servizi cloud non autorizzati o applicare automaticamente un’etichetta di protezione al documento generato.
In questo scenario, la DLP non agisce sul database, ma sull’uso del dato. La classificazione applicata alla colonna consente alla policy di capire che tipo di informazione è coinvolta e di applicare controlli coerenti con il livello di rischio definito dall’organizzazione.
Questo esempio chiarisce un punto fondamentale: la DLP protegge il dato quando viene utilizzato o condiviso, non quando è semplicemente archiviato. Senza la classificazione a monte, la policy DLP non avrebbe elementi sufficienti per distinguere un file innocuo da uno contenente dati sensibili.
La protezione, quindi, non è il risultato di una singola funzionalità, ma dell’integrazione tra classificazione del dato e policy di controllo, che insieme permettono di ridurre in modo significativo il rischio di perdita o diffusione non autorizzata delle informazioni.
Conclusioni
L’integrazione di Microsoft Purview con SQL permette di passare da una gestione reattiva dei dati a un approccio strutturato e governato. Non si tratta solo di uno strumento tecnico, ma di un “abilitatore” per una cultura del dato più consapevole, sicura e orientata al valore. Se correttamente implementato, Purview può diventare un pilastro fondamentale della strategia data aziendale.
Avere a disposizione strumenti, che in modo centralizzato permettono ai reparti Legal e IT di ottimizzare tempo e risorse, a mio avviso è un must per le organizzazioni moderne.