
awk per Windows 10 Bash, molto più di un editor di testo
Nei precedenti articoli abbiamo visto come anche sul sistema operativo Windows 10 sia possibile eseguire in maniera nativa alcuni comandi linux, nello specifico abbiamo trattato dapprima i comandi base (http://www.ictpower.it/guide/editing-di-testo-con-windows-bash.htm) e successivamente grep e sed (http://www.ictpower.it/sistemi-operativi/grep-e-sed-ricerche-ed-editing-di-testo-non-interattivo-con-windows-10-bash.htm). Completiamo questa mini guida mostrando un estratto di quello che è possibile fare con awk, un vero e proprio linguaggio di programmazione per l’elaborazione dei testi, focalizzando l’attenzione su quali potrebbero essere i suoi impieghi per supportare la creazione e la modifica dei nostri script. Anche in questo caso ritengo utile la comprensione di alcuni elementi chiave degli articoli precedenti, quindi se siete alle prime armi nell’utilizzo dei comandi di editing linux consiglio di leggere le prime due parti della guida prima di continuare.
L’utilizzo di awk prevede, come molto spesso accade per l’editing di testo in ambiente linux, un testo in input passato al tool tramite immissione da tastiera o come risultato di una pipeline; questo testo sarà considerato come suddiviso per righe, ed ogni riga divisa in campi. Come impostazione di default si intende il carattere “invio” come delimitatore per le righe ed il carattere “spazio” per delimitare i campi. Per queste caratteristiche awk è molto usato per l’elaborazione dei file di testo strutturati.
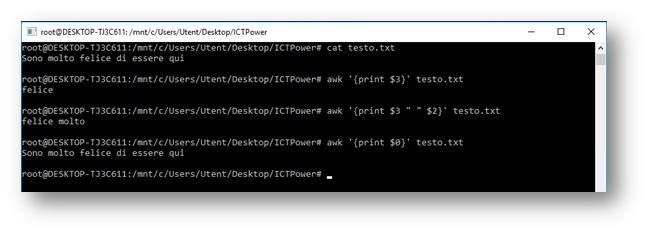
Il campo su cui lavorare viene indicato con delle variabili nel formato $N; indicheremo quindi $1 per il primo campo, $2 per il secondo, e così via. La variabile $0, invece, viene utilizzata per indirizzare awk sull’intera riga, anche se in questo caso è possibile ometterla perché considerata valore di default. Nel seguente esempio abbiamo un file denominato testo.txt e alcuni esempi di output ottenuti utilizzando l’azione print:
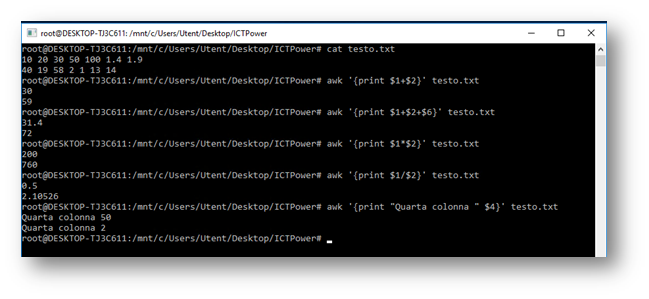
Possiamo utilizzare l’azione print insieme a delle semplici espressioni per eseguire delle operazioni tra i valori contenuti nelle colonne che compongono un file strutturato:
I comandi nel linguaggio awk sono strutturati in questo modo:
condizione { azione }
quando la condizione è soddisfatta, viene eseguita l’azione. La sintassi completa di awk sarà quindi:
awk ‘condizione { azione }’ file
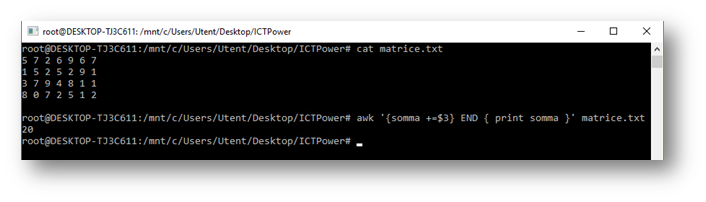
è possibile indicare la condizione in più modi, dalle più semplici espressioni regolari racchiuse dal carattere “/” a più complesse sequenze di comandi delimitate dagli operatori BEGIN ed END. Un esempio di semplice “programma” in awk mostra come le possibilità offerte da questo tool sono infinite, e ci consente di capire come da riga di comando sia possibile ottenere quello che forse fino ad ora avremmo fatto con Excel; in questo caso vogliamo eseguire la somma dei valori della terza colonna di una matrice di numeri contenuta in un file.
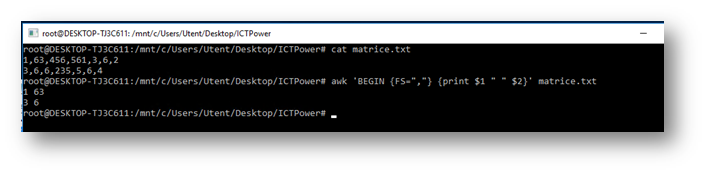
Come accennato in precedenza, è possibile che il file sia strutturato in maniera da separare i campi con caratteri diversi dallo spazio, come spesso accade nei file.csv, e dobbiamo indicare ad awk quale carattere considerare come separatore. Abbiamo la possibilità di indicare un separatore per l’input (variabile FS) ed uno per l’output (variabile OFS). Il valore di default per queste variabili è lo spazio. Vediamo cosa succede a seconda dei parametri che passiamo ad awk relativamente ai separatori di campo. FS ed OFS, che stanno a significare rispettivamente field separator ed output field separator, vanno indicati nella sezione BEGIN di awk.
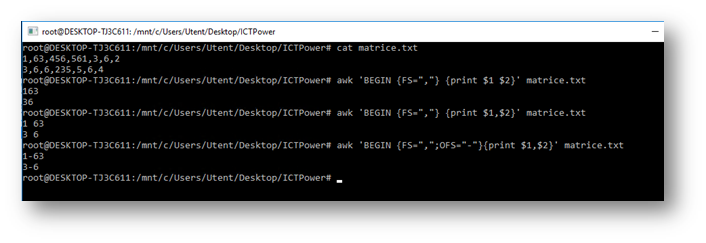
Nell’esempio appena visualizzato notiamo che utilizzando la virgola tra gli indicatori di colonna, awk considererà il separatore di output (carattere spazio di default o personalizzato con la variabile OFS), diversamente da quanto accade della notazione $1 $2 (senza virgole) in cui awk darà in output i due valori uniti. Possiamo separarli con uno spazio anche indicando $1 ” ” $2.
Se tutto questo può sembrare astratto non facciamo fatica ad immaginare una situazione in cui conoscere awk può darci una mano a risparmiare tempo. Valutiamo, ad esempio, la necessità di dover inserire nel database di questo sito l’agenda di un evento in cui viene indicato il numero dell’aula in cui ogni speaker terrà la propria sessione. Siamo in possesso di un file chiamato ictpower.csv dove sono presenti, separati da una virgola, i nomi degli speaker e il numero dell’aula in cui interverranno, e dobbiamo creare dei comandi SQL per automatizzare la procedura di inserimento. awk ci viene in aiuto fornendoci gli strumenti per eseguire questa operazione in un’unica riga di comando; e notiamo come nello screenshot seguente sia utilizzata la notazione \047 per scrivere il carattere apice.
In particolare il comando utilizzato è:
awk ‘BEGIN {FS=”,”} {print “INSERT INTO eventi (nome,cognome,aula) VALUES (\047” $1 “\047,\047” $2 “\047,” $3 “)”‘} ictpower.csv
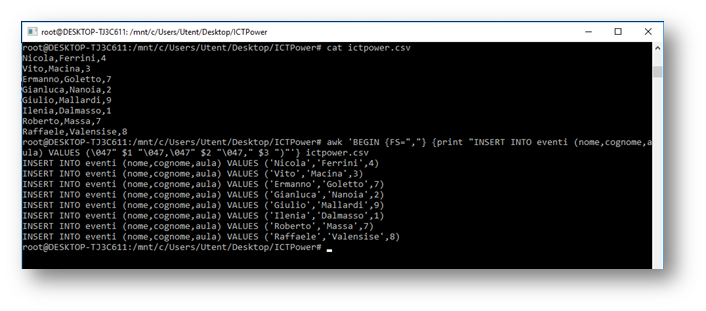
Anche qui notiamo la presenza di {FS=”,”}, che ci aiuta a trattare il file csv da riga di comando tenendo conto della suddivisione dei campi.
Una piccola nota: per scrivere le parentesi graffe in una shell DOS o in un editor di testo Windows utilizziamo il relativo codice ASCII inserendolo tenendo premuto il tasto ALT. In particolare avremo ALT+123 per la parentesi graffa aperta “{” e ALT+125 per quella chiusa “}”. Quando stiamo utilizzando Windows Bash questa combinazione di tasti non sortisce alcun effetto e siamo costretti – almeno per il momento – ad utilizzare il copia-incolla per l’immissione dallo standard input di questi caratteri.
Oltre ad FS ed OFS esistono altre variabili “native”, tra cui ricordiamo NF che indica il numero di campi (parole, colonne) ed NR che indica il numero di righe. Queste variabili sono aggiornate da awk subito dopo la lettura di ogni riga, in questo modo potremmo utilizzaread esempio:
awk ‘NF > 0’
per stampare tutte le righe non vuote di un file
awk ‘END { print NR }’
per ottenere il conteggio delle righe di un file
Vediamo ora come indicare la condizione da verificare su una determinata riga per eseguire delle operazioni su di essa. Come accennato nella sintassi di base, infatti, abbiamo la possibilità di indirizzare awk a lavorare solo su alcune righe, impostando una particolare espressione per esprimere la condizione da verificare per tenere una riga in considerazione. La modalità è identica al pattern di ricerca di sed, e dovremo indicare quindi la stringa da cercare tra due slash “/”.
Supponiamo di essere all’interno di una cartella contenente i file di configurazione di un servizio e di dover cercare dove è indicata la riga che contiene la stringa di connessione al database, che sappiamo essere associata alla variabile “connectionstring”; possiamo utilizzare awk per ottenere la stringa che cerchiamo eseguendo una delle seguenti righe di codice:
cat elenco.txt | awk ‘/connectionstring/ { print }’
awk ‘/connectionstring/ { print }’ *
E’ possibile salvare i comandi awk da eseguire (tutta la parte tra parentesi graffe) all’interno di un file, e richiamarne l’esecuzione con il comando
awk -f programma.awk fileinput1 fileinput2 …
E’ possibile passare in input delle variabili indicando -v variabile=valore
Questo è utile quando vogliamo eseguire una lunga serie di comandi, oppure abbiamo bisogno utilizzare variabili, vettori, cicli, condizioni, funzioni e tutto ciò che il linguaggio awk consente, in modo da lavorare con degli script molto più chiari dal punto di vista della lettura, a differenza di quanto accadrebbe se scrivessimo tutto il codice in un’unica riga.
Come immaginabile a questo punto sarebbe necessario un vero e proprio manuale di programmazione per conoscere tutti i segreti di questo linguaggio ma, come ripetuto più volte anche nei precedenti articoli, lo scopo di questa mini-guida è solo quello di iniziare a comprendere le potenzialità offerte dall’ambiente linux ora a disposizione su Windows 10, e comprendere così il perchè del suo arrivo inaspettato in casa Microsoft.