
grep e sed – Ricerche ed editing di testo non interattivo con Windows 10 Bash
Come promesso alla fine del precedente articolo (http://www.ictpower.it/guide/editing-di-testo-con-windows-bash.htm) torniamo a parlare di comandi linux disponibili ora anche su Windows 10 Bash, partendo dalla conoscenza del comando grep e proseguendo con il tool di editing sed. Lasciamo ad un prossimo articolo, invece, il capitolo su awk. Di seguito troverete molti riferimenti a comandi o notazioni già trattate nell’articolo appena citato, quindi se non è chiaro l’utilizzo dei comandi base per le operazioni sui testi ne consiglio un’attenta lettura prima di procedere oltre.
L’utilizzo congiunto di sed ed awk permette di elaborare dei testi con lo scopo, ad esempio, di trasformarne in parte il contenuto o di estrapolarne delle informazioni formattandole nella maniera desiderata. Per effettuare tutte le operazioni sarà necessario conoscere una grande quantità di opzioni da passare ai comandi in fase di esecuzione, ma una volta comprese tutte le funzionalità sarà davvero difficile riuscire a farne a meno. In questo articolo vedremo come utilizzare le funzioni più comuni, ritenendolo un ottimo punto di partenza per iniziare a comprendere il potenziale valore di Windows Bash.
Il comando grep
grep è un comando bash dalla sintassi semplicissima che ci permette di ricercare all’interno dei file la presenza o meno di stringhe di testo, passando tali stringhe come variabili ben definite o come espressioni regolari. La sintassi del comando è:
grep stringa file.txt
in particolare in questo caso il comando cercherà tutte le righe nel file file.txt che contengono la stringa “stringa” e ce le restituirà nello standard output. Un semplice esempio chiarirà tutto:
creiamo un file denominato file.txt con il contenuto visualizzato dallo screenshot seguente:
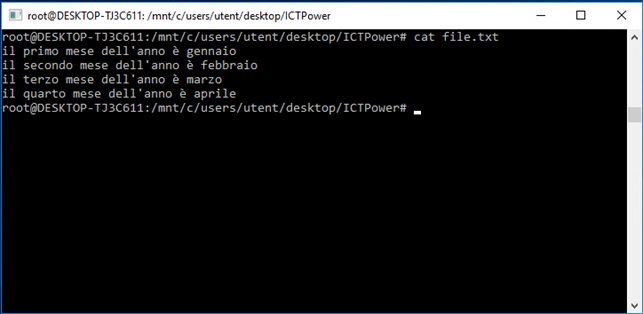
e vediamo cosa ritorna il comando grep a seconda delle espressioni passate tramite standard in; notiamo che possiamo utilizzare il punto come carattere “jolly”, per ricercare qualcosa di cui non ricordiamo perfettamente come è scritta, oppure per effettuare ricerche più complesse con una sola stringa. L’opzione –v, invece, esegue l’operazione inversa mostrando tutte le righe in cui l’espressione non è presente.
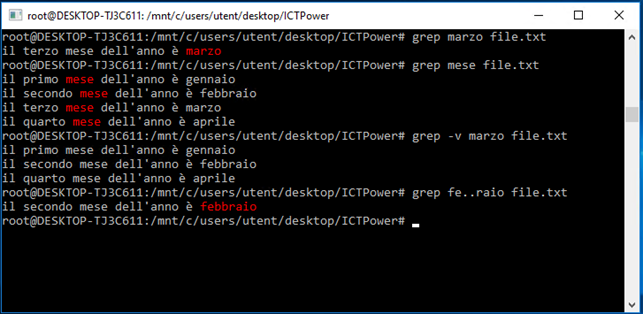
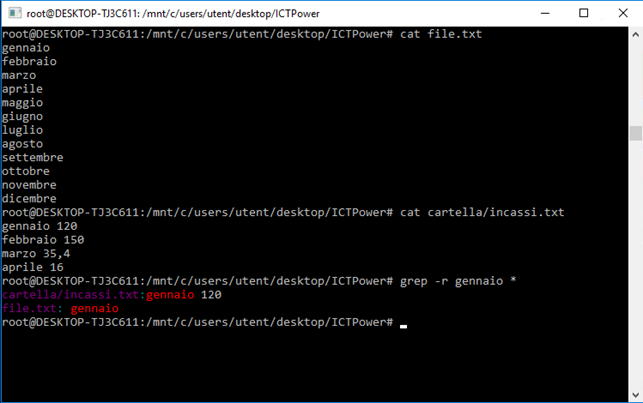
È molto utile, inoltre, l’opzione –r che ci consente di estendere la ricerca delle occorrenze in modo ricorsivo su tutti i files contenuti nelle sottocartelle in cui eseguiamo il comando. In questo caso oltre alla riga in cui viene individuata l’occorrenza, grep ci restituirà il nome del file in cui questa occorrenza esiste.
Vediamo cosa succede se eseguiamo il comando in un ambiente con un file.txt contenente i mesi dell’anno ed una cartella denominata “cartella” all’interno della quale esiste un file denominato incassi.txt con ipotetici incassi mensili.
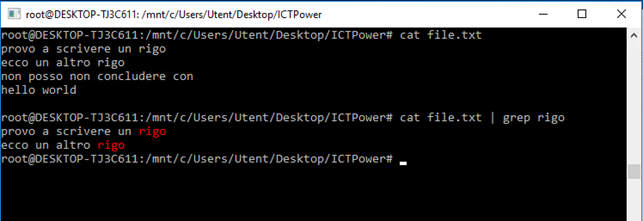
Anche questa volta è fondamentale ricordare che il comando grep può acquisire in input cìò che viene passato da altre operazioni o comandi con la notazione pipe. Un esempio renderà tutto immediatamente comprensibile:
Il comando sed
sed è un editor di testo non interattivo, quindi permette la modifica di file di testo senza aprire il file stesso in visualizzazione come invece succede con nano. sed esegue delle operazioni su un testo restituendo in output un’elaborazione dei dati in ingresso eseguita in base alle opzioni desiderate. E’ possibile passare il testo in ingresso attraverso l’immissione dei dati da tastiera (quindi attraverso lo standard in), attraverso un file, o come spesso risulta più efficace utilizzando il risultato di un altro comando eseguito precedentemente; in quest’ultimo caso i dati in ingresso verranno passati al comando sed tramite la notazione | (pipe). L’insieme dei comandi eseguiti consecutivamente e collegati con la notazione pipe viene chiamata pipeline.
La possibiltà di editare dei testi utilizzando un input diverso dalla tastiera o da un file rappresenta la vera forza di sed, chiamato così perché è l’abbreviazione di Stream Editor, poiché consente appunto di modificare il testo prodotto in output da un altro comando prima di salvarlo in un file.
sed agisce sul testo in un punto preciso chiamato “indirizzo”, oppure su una parte di testo delimitata da un “intervallo di indirizzi” effettuando delle “azioni” che vengono passate con l’opzione –e se specificate direttamente sulla riga di comando oppure –f se passate tramite file. Gli indirizzi possono essere indicati con espressioni formattate secondo alcune regole che vedremo in seguito.
Premetto che utilizzare in maniera agile il comando sed, e come vedremo in un prossimo articolo awk, vuol dire un po’ essere i padroni del mondo, ma per arrivare ad avere la massima confidenza con le infinite potenzialità di questi due tool bisogna andare avanti a piccoli passi. Iniziamo con la sintassi, apparentemente semplice:
sed [indirizzo[,indirizzo]]-e azione[testo] La notazione “-e” è facoltativa e si ottiene lo stesso risultato con il comando sed [indirizzo[,indirizzo]] azione[testo]
Tre azioni fondamentali sono visualizzare, cancellare e sostituire parte del testo, e vengono eseguite rispettivamente con le azioni /p (print) /d (delete) e /s (substitute).
Prima di andare avanti e comprendere le azioni è necessario capire bene come indicare a sed su quale parte di testo, o meglio su quale “indirizzo” lavorare. Per fare questo utilizziamo diverse notazioni, tra cui sono fondamentali:
il delimitatore “/” slash viene utilizzato per separare le parti di un comando, per esempio per sostituire stringaA con stringaB utilizzeremo l’espressione s/stringaA/stringaB/. Se abbiamo bisogno di includere il carattere “/” nella stringa, e dobbiamo evitare che sed lo utilizzi come delimitatore possiamo utilizzare i delimitatori alternativi, ovvero i due punti “:” oppure l’underscore “_” . sed sarà autonomamente in grado di capire quale delimitatore stiamo utilizzando.
L’indirizzo può indicare, ad esempio, il numero di riga su cui vogliamo effettuare delle modifiche, e come indicato qualche riga più in alto possiamo notare che possiamo passare nessuno, uno o due indirizzi al comando sed. Non passando alcun indirizzo sed considererà tutte le righe in input, se indichiamo un singolo indirizzo diremo a sed di considerare solo un numero di riga in particolare, se ne indichiamo due effettueremo le nostre modifiche su tutte le righe comprese tra il primo ed il secondo indirizzo.
Vediamo un esempio nel quale sostituiamo la prima occorrenza di una stringa in un file di testo:
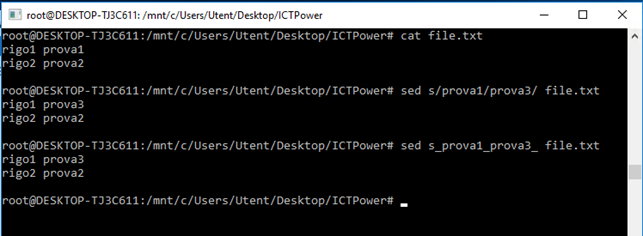
Particolare attenzione, va posta sul carattere speciale backslash “\”, che necessita di una notazione complessa per essere riconosciuto. La stringa che lo contiene va indicata tra apici singoli ed il carattere \ va sostituito con un doppio \\. Questo caso è molto importante se vogliamo utilizzare il comando sed per sostituire ad esempio dei path in alcuni file di configurazione come nell’esempio seguente:
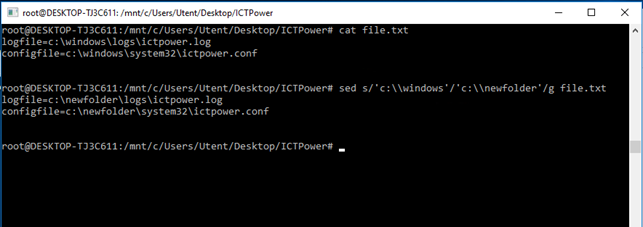
Come si può notare l’azione passata al comando è s/stringaA/stringaB/g. il flag /g indica a sed di effettuare la sostituzione su tutte le occorrenze, e non solo sulla prima di esse come accadrebbe senza tale notazione.
L’azione –i aggiunta al comando salva il file modificato sovrascrivendo l’originale, ed è possibile eventualmente effettuare una copia di backup del precedente file indicando l’estensione da aggiungere.
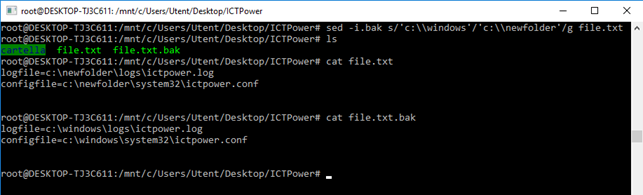
L’azione “d” permette di eliminare le righe contenenti una particolare espressione dall’interno del file (o dello stream di testo) su cui sed lavora.
Mostriamo alcuni esempi, utili anche per capire la sintassi delle espressioni regolari nelle loro varie forme per indirizzare sed sulla parte di testo desiderata; è possibile, infatti, indicare il numero di riga su cui eseguire le operazioni oltre che la stringa precisa:
sed ‘5d’ file.txt
restituirà il file.txt senza la quinta riga
sed /warning/d file.txt
restituirà il file.txt eliminando tutte le righe contenenti “warning”
sed 2,4d file.txt
restituirà il file.txt eliminando tutte le righe tra la seconda e la quarta (comprese)
L’azione “p” permette di ottenere in output le righe selezionate tramite l’espressione indirizzo. Il comando sed 1,3p file.txt restituisce file.txt con le righe da 1 a 3 scritte due volte. Questo potrebbe essere poco utile, se non accompagnato dall’azione –n, che consente di eliminare dall’output il file originale così da ottenere solo le righe richieste. Quindi, ad esempio, con il comando
sed –n 1,10p file.txt
Avremo in output le prime 10 righe di file.txt
Questo esempio svolge identica funzione del comando head file.txt visto nel precedente articolo.
Come abbiamo visto il tool in questione ha una grande flessibilità, considerando anche che questa è solo una minima parte di quello che sed ci consente. L’obiettivo di questa mini-guida, però, è quello di mostrare le potenzialità aggiunte da Bash all’ambiente Windows, e rimane poi all’utente la facoltà di approfondire le migliaia di sfaccettature che ogni comando possiede. Rimando a questo punto alla “guida ufficiale” del comando sed. E’ proprio così, ogni comando unix ha un suo “vademecum” in cui è possibile visualizzare tutti le azioni, i parametri e le opzioni utilizzabili con il comando stesso con una breve spiegazione per ognuno di essi. La nota interessante di questo punto è che anche su Windows Bash è possibile richiamare la guida, o meglio il manuale, di ogni comando con:
man comando
Nel nostro caso man sed restituirà il manuale di sed, manuale che è possibile consultare anche online su:
https://www.gnu.org/software/sed/manual/sed.txt
A questo punto non mi resta che invitare tutti a provare ad applicare queste nuove funzionalità nella vita sistemistica quotidiana ed attendere il prossimo articolo, dove faremo la conoscenza di awk!