
Cluster Hyper-V e dipendenza da Active Directory: analisi tecnica e scenari di emergenza
Quando progettate un Failover Cluster basato su Hyper-V, date spesso per scontato che l’infrastruttura di Active Directory sia semplicemente “sempre lì”, stabile e disponibile. In condizioni normali è così. Ma quando vi trovate davanti a un riavvio completo dell’ambiente, magari dopo un blackout importante o durante un’attività di disaster recovery, la domanda diventa improvvisamente concreta: cosa succede al cluster se AD non è raggiungibile?
In questo articolo voglio portarvi esattamente su questo punto. Non parleremo di come si crea un cluster, né di come si configura una macchina virtuale altamente disponibile. Diamo per acquisito che abbiate già implementato un’infrastruttura corretta e funzionante. Ho scritto tanto sull’argomento: Hai cercato cluster – ICT Power
Il focus è un altro: capire quanto il cluster dipenda realmente da Active Directory, in quali momenti questa dipendenza sia critica e quali siano le procedure di emergenza quando l’AD DS non risponde.
È fondamentale distinguere tra un cluster già operativo e un cluster che deve avviarsi da zero. Nel primo caso, la perdita temporanea dell’accesso ai Domain Controller può avere un impatto limitato; nel secondo, l’assenza di autenticazione può impedire al servizio ClusSvc di inizializzarsi correttamente. Ed è proprio in questo scenario che molti ambienti scoprono di avere un punto debole architetturale.
Vedremo quindi cosa accade durante il bootstrap del Windows Server Failover Clustering, perché esistono oggetti come il CNO e perché la loro validazione passa attraverso il dominio. Analizzeremo cosa è realmente supportato da Microsoft quando l’Active Directory non è disponibile e quali comandi consentono un avvio forzato in condizioni di emergenza, con tutti i rischi che questo comporta.
L’obiettivo è darvi consapevolezza tecnica. Perché un cluster altamente disponibile non è tale se non avete valutato anche lo scenario in cui manca proprio il servizio che ne garantisce l’identità: il dominio.
Dipendenza architetturale da Active Directory
Un Failover Cluster domain-joined utilizza Active Directory come meccanismo di identità e autenticazione. Ogni nodo è un normale account computer di dominio e, al momento della creazione del cluster, viene generato un oggetto specifico chiamato Cluster Name Object (CNO).
Il CNO rappresenta l’identità del cluster nel dominio ed è utilizzato per creare eventuali Virtual Computer Object (VCO) associati ai ruoli clusterizzati.
Durante la fase di creazione il cluster scrive in AD, registra gli SPN necessari per l’autenticazione Kerberos e valida le credenziali degli account coinvolti. Una volta operativo, però, il cluster non interroga continuamente il dominio: l’infrastruttura AD diventa critica soprattutto nelle fasi di autenticazione e bootstrap.
La dipendenza quindi non è “continua”, ma è strutturale.
Cluster già in esecuzione senza accesso ad Active Directory
Se il cluster è già online e il quorum è stato formato correttamente, la perdita temporanea del Domain Controller non comporta l’arresto immediato delle VM. Il servizio ClusSvc continua a gestire le risorse utilizzando la configurazione locale e lo stato già stabilito.
- Il failover automatico resta operativo.
- Le macchine virtuali continuano a funzionare.
Tuttavia, le operazioni che richiedono autenticazione Kerberos attiva, come alcune Live Migration o nuove connessioni amministrative, possono fallire in assenza di un Domain Controller raggiungibile.
Il cluster può quindi tollerare un’assenza temporanea di Active Directory, ma non è progettato per operare indefinitamente senza infrastruttura di autenticazione.
Riavvio completo del cluster senza accesso ad Active Directory
Il comportamento cambia radicalmente se tutti i nodi vengono spenti e riaccesi in assenza di un Domain Controller disponibile.
Durante l’avvio:
- Il nodo deve autenticare il proprio account computer.
- Il servizio Cluster Service (ClusSvc) deve validare l’identità del cluster.
- Il CNO deve essere riconosciuto come oggetto valido in AD.
Se il dominio non è raggiungibile, l’autenticazione può fallire e il cluster può non formarsi. In molti casi il servizio cluster non riesce a portarsi in stato online e le VM non vengono avviate automaticamente.
Qui si manifesta la reale dipendenza da Active Directory: non tanto nel runtime, quanto nel processo di bootstrap.
Dopo il blackout avete riacceso i nodi Hyper-V e, aprendo la console Failover Cluster Manager, vi trovate davanti al messaggio:
“The operation has failed. An error occurred connecting to the cluster… one or more nodes not responding to WMI calls.”
Quello che sta succedendo non è (necessariamente) un problema di WMI in sé. È un effetto collaterale della mancata inizializzazione corretta del servizio ClusSvc su uno o più nodi, in questo caso HV2.
La console MMC prova a interrogare il nodo tramite WMI, ma il servizio cluster non è operativo oppure non è riuscito a formare il cluster perché durante il bootstrap non è riuscito a validare l’identità del nodo e del CNO contro Active Directory.
In uno scenario di riavvio completo:
- Il nodo tenta di autenticare il proprio account computer.
- Il servizio cluster prova a validare l’oggetto cluster nel dominio.
- Se il Domain Controller non è ancora disponibile, l’inizializzazione può fallire.
La console quindi segnala un errore di comunicazione WMI, ma la causa reale può essere l’assenza di autenticazione di dominio al momento dell’avvio.
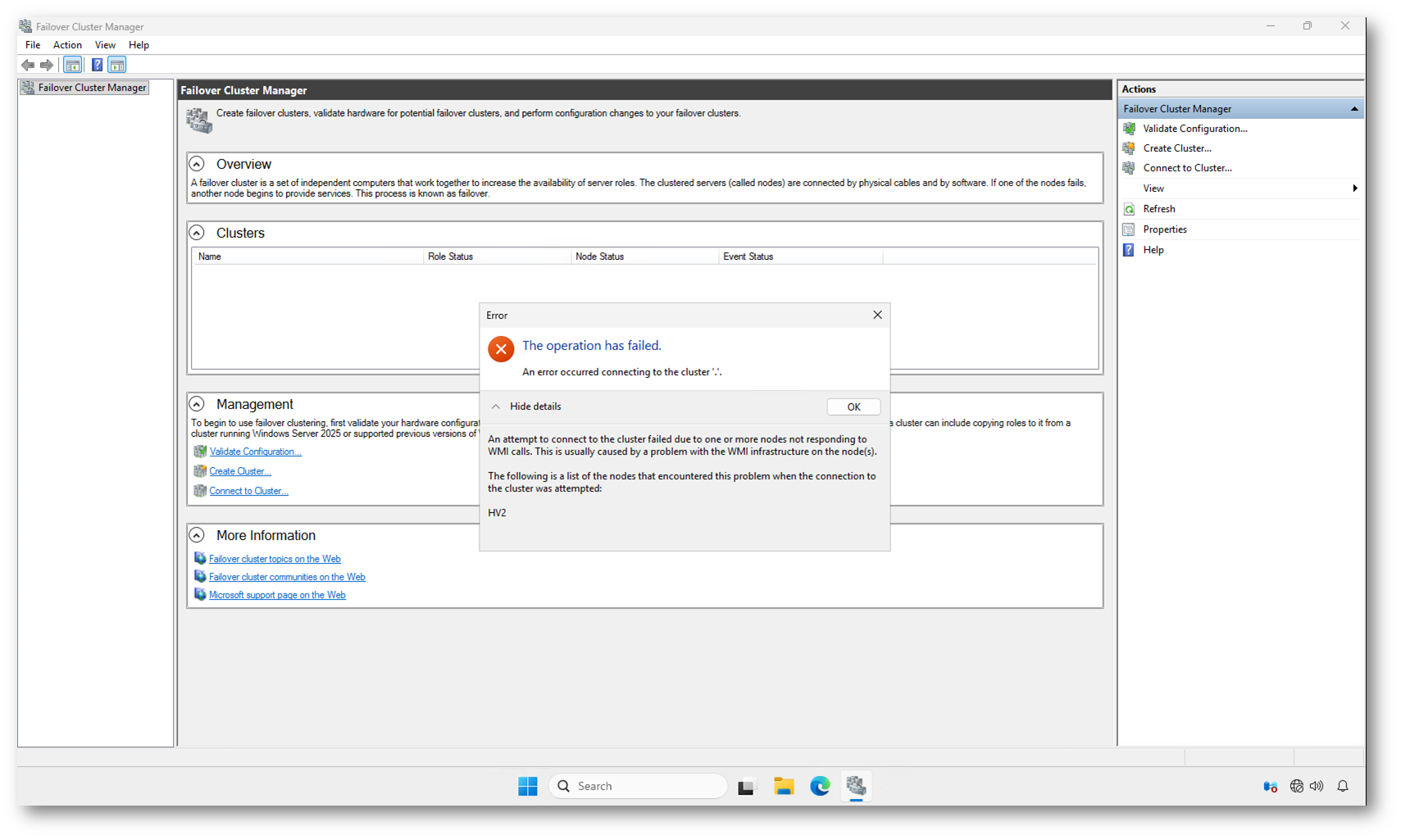
Figura 1: Failover Cluster Manager non riesce a connettersi al nodo HV2 dopo un riavvio completo in assenza temporanea di Active Directory, impedendo la formazione del cluster
Dopo l’errore in console, ho verificato lo stato del servizio con:
|
1 2 |
Get-Service -Name clussvc |
Il risultato mostra Status: Running per il servizio Cluster Service.
Questo è il punto che spesso genera confusione: il servizio ClusSvc è avviato, ma il cluster non è realmente formato.
Quando il nodo si avvia, il servizio cluster parte come processo di sistema. Tuttavia, per portare il cluster in stato online deve:
- autenticare l’account computer nel dominio
- validare il CNO in Active Directory
- negoziare il quorum con gli altri nodi
Se durante questa fase il Domain Controller non è disponibile, il servizio può risultare tecnicamente in esecuzione ma incapace di completare la formazione del cluster.
In altre parole: servizio attivo non significa cluster funzionante.
È per questo che la console MMC non riesce a connettersi, anche se PowerShell indica che il servizio è avviato. Il problema non è il processo locale, ma la mancata inizializzazione completa dell’identità del cluster.
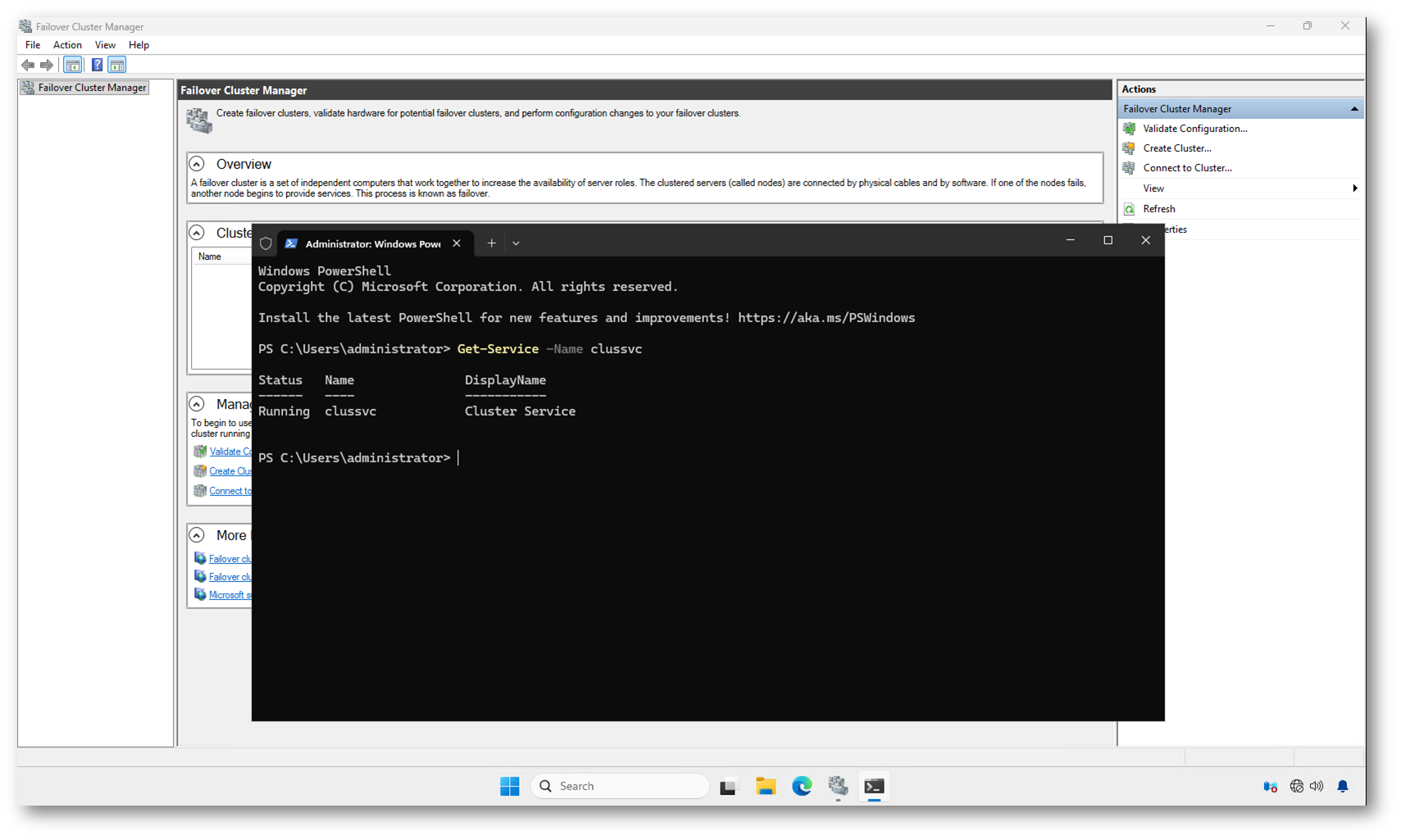
Figura 2: Il servizio ClusSvc è in stato Running, ma il cluster non riesce a formarsi perché l’autenticazione verso Active Directory non è completata
A questo punto ho cambiato prospettiva. Volevo rendermi conto se le VM si fossero comunque avviate, indipendentemente dal funzionamento del cluster.
Da Hyper-V Manager, collegandomi al nodo HV1, ho visto che il ruolo Hyper-V è operativo e che la VM precedentemente accesa si è riavviata automaticamente. Questo è coerente: il servizio Hyper-V non dipende dal cluster per avviarsi e le VM partono comunque.
Il problema emerge quando tentate di connettervi al nodo HV2. Il messaggio è esplicito:
WinRM cannot process the request… We can’t sign you in with this credential because your domain isn’t available.
Qui non stiamo più parlando di cluster, ma di autenticazione Kerberos.
Hyper-V Manager utilizza WinRM e autenticazione di dominio per connettersi a un host remoto. Se il Domain Controller non è disponibile, Kerberos non può emettere o validare ticket e la connessione viene rifiutata con errore 0x80090311.
Questo conferma due aspetti importanti:
- Il servizio Hyper-V può funzionare localmente.
- L’autenticazione remota basata su dominio non è disponibile.
In altre parole, l’host è acceso e operativo, ma l’infrastruttura di identità non è raggiungibile. È lo stesso principio che impedisce al cluster di formarsi correttamente: senza dominio non c’è autenticazione centralizzata.
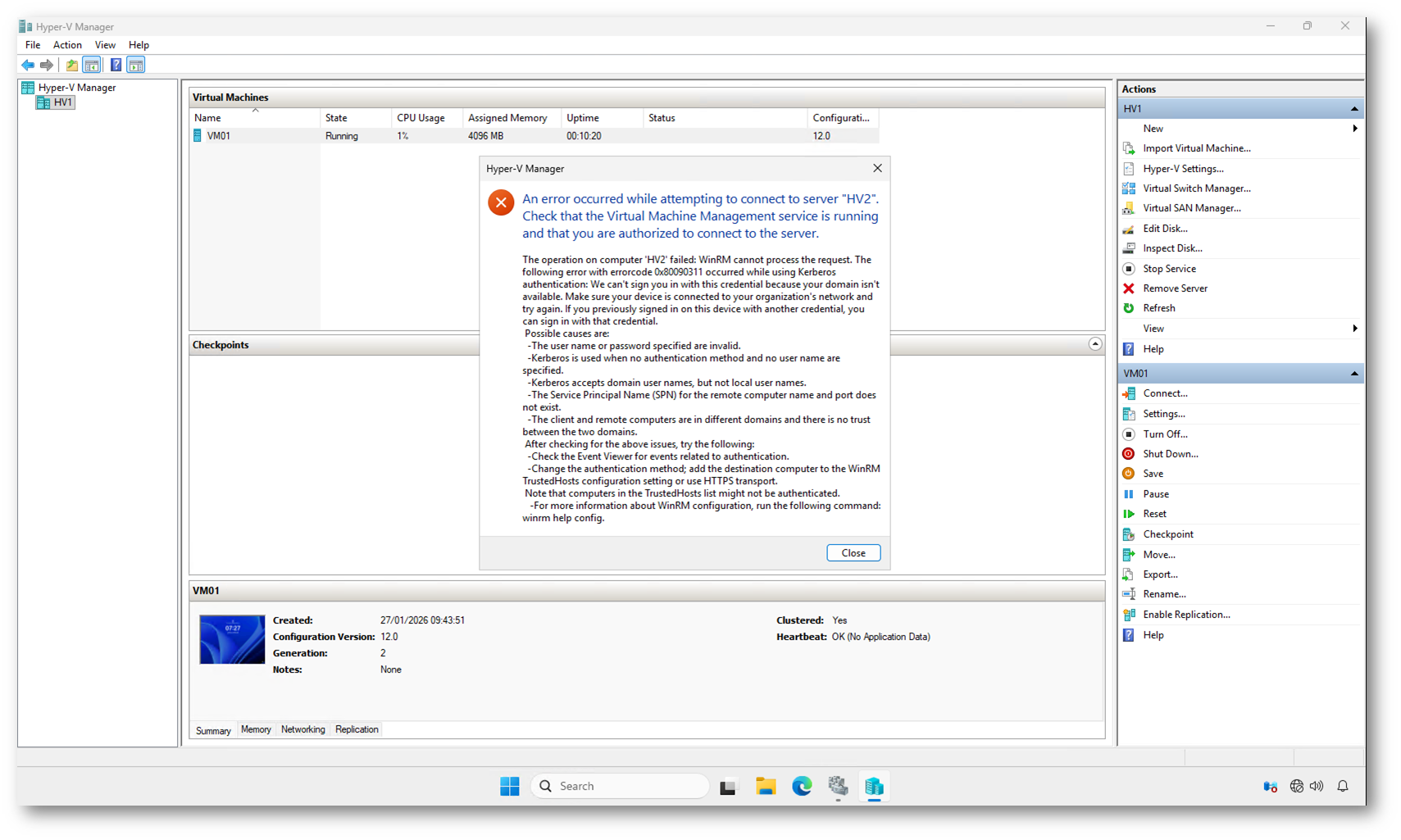
Figura 3: Errore Kerberos 0x80090311 durante la connessione remota a HV2: il nodo è attivo, ma il Domain Controller non è disponibile e l’autenticazione di dominio fallisce
Avvio del cluster con un solo nodo disponibile
Dopo il blackout si è avviato correttamente solo HV1, mentre HV2 risulta con Cluster Service Stopped.
La domanda è legittima: possiamo avviare il cluster con un solo nodo?
La risposta è: dipende dal quorum.
Se il modello di quorum richiede la maggioranza dei nodi e uno non è disponibile, il comando Start Cluster tenterà l’avvio normale rispettando le regole di quorum. Se non c’è maggioranza, l’operazione fallisce perché il cluster non può garantire coerenza dei dati.
Il pulsante Start Cluster esegue infatti un avvio standard:
- verifica la presenza degli altri nodi
- controlla il quorum
- tenta la formazione del cluster in modalità sicura
Quando questa procedura non riesce, tipicamente perché un nodo è offline o il Domain Controller non è disponibile, avete la possibilità di utilizzare Force Cluster Start.
Questa opzione equivale, lato PowerShell, a:
|
1 2 |
Start-ClusterNode -FixQuorum |
oppure:
|
1 2 |
net start clussvc /forcequorum |
Con Force Cluster Start forzate la formazione del cluster su quel singolo nodo, ignorando temporaneamente le regole standard di quorum. È una modalità di emergenza, utile ad esempio per riavviare una VM che ospita un Domain Controller.
Va però utilizzata con consapevolezza: se un altro nodo fosse ancora attivo isolatamente, potreste creare una condizione di split-brain, con due istanze incoerenti del cluster.
In questo scenario, con un solo nodo realmente operativo e l’altro spento o non avviabile, il force start è una procedura corretta per ripristinare il servizio e diventa la vostra ancora di salvezza.
NOTA: la modalità di avvio forzato del quorum è disponibile fin da Windows Server 2008, cioè da quando esiste l’attuale architettura Windows Server Failover Cluster.
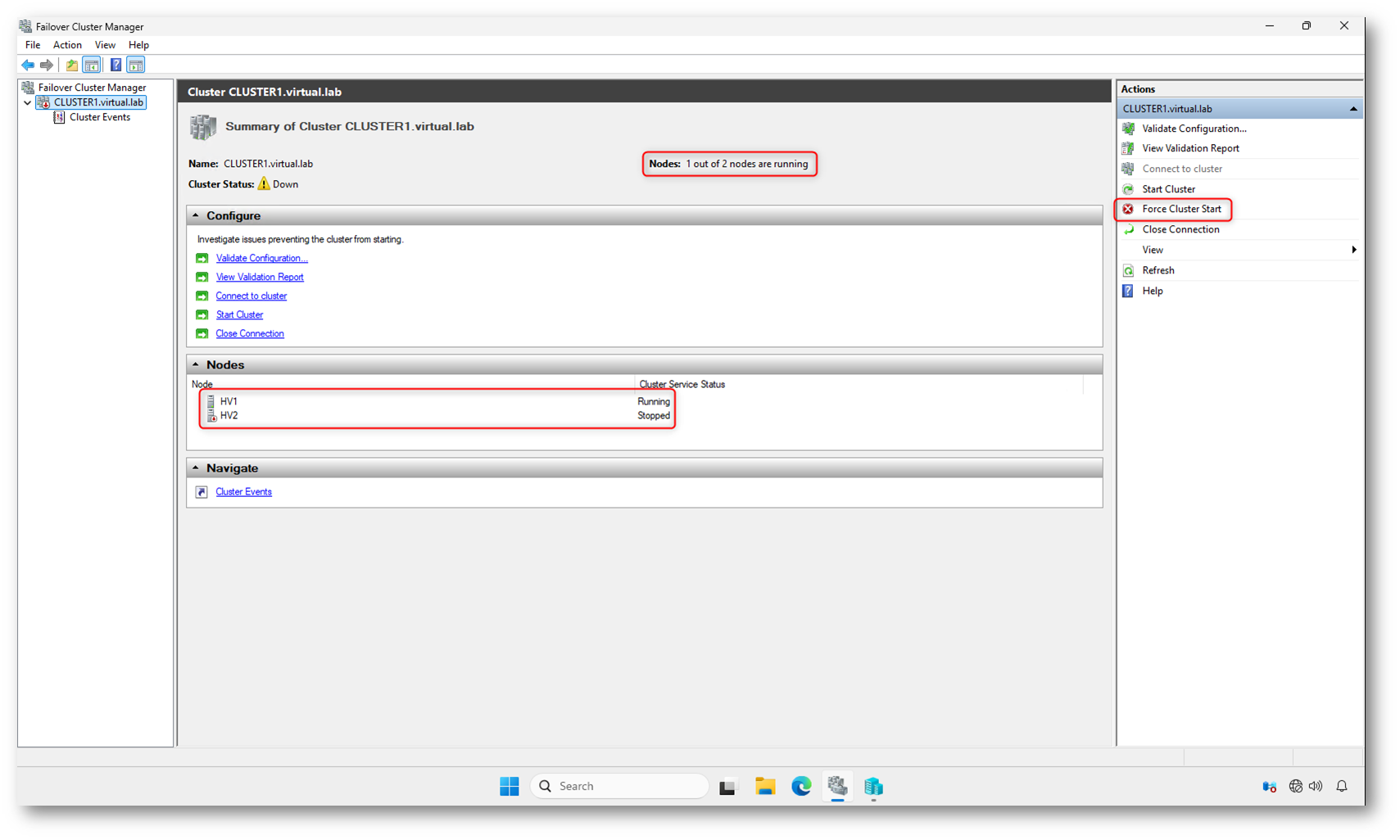
Figura 4: Avvio del cluster con un solo nodo disponibile: Start Cluster tenta la formazione standard, mentre Force Cluster Start consente l’avvio forzato ignorando temporaneamente il quorum
Quando selezionate Force Cluster Start, compare un messaggio molto chiaro:
Forcing the cluster to start can have unexpected results. This includes the loss of cluster configuration.
Questo avviso non è formale. È tecnico.
Il cluster mantiene la propria configurazione in un database distribuito tra i nodi e protetto dal meccanismo di quorum. Il quorum serve proprio a garantire che esista una sola versione autorevole della configurazione.
Con il Force Start state dicendo al nodo:
“Considerati autorevole anche senza maggioranza.”
Se esistesse un altro nodo attivo isolatamente, o se i dischi condivisi contenessero uno stato differente, potreste trovarvi con:
- configurazioni divergenti
- risorse duplicate
- potenziale split-brain
- perdita di modifiche recenti
Il warning parla di possibile perdita della configurazione perché, forzando l’avvio, il nodo utilizza la copia locale del database cluster come riferimento. Se quella copia non è la più aggiornata, lo stato del cluster potrebbe non riflettere l’ultima configurazione valida.
Nel mio scenario, con HV2 non operativo e nessun altro nodo attivo, il rischio è controllato. Ma il messaggio serve a ricordare che state bypassando il meccanismo di protezione principale del cluster: il quorum.
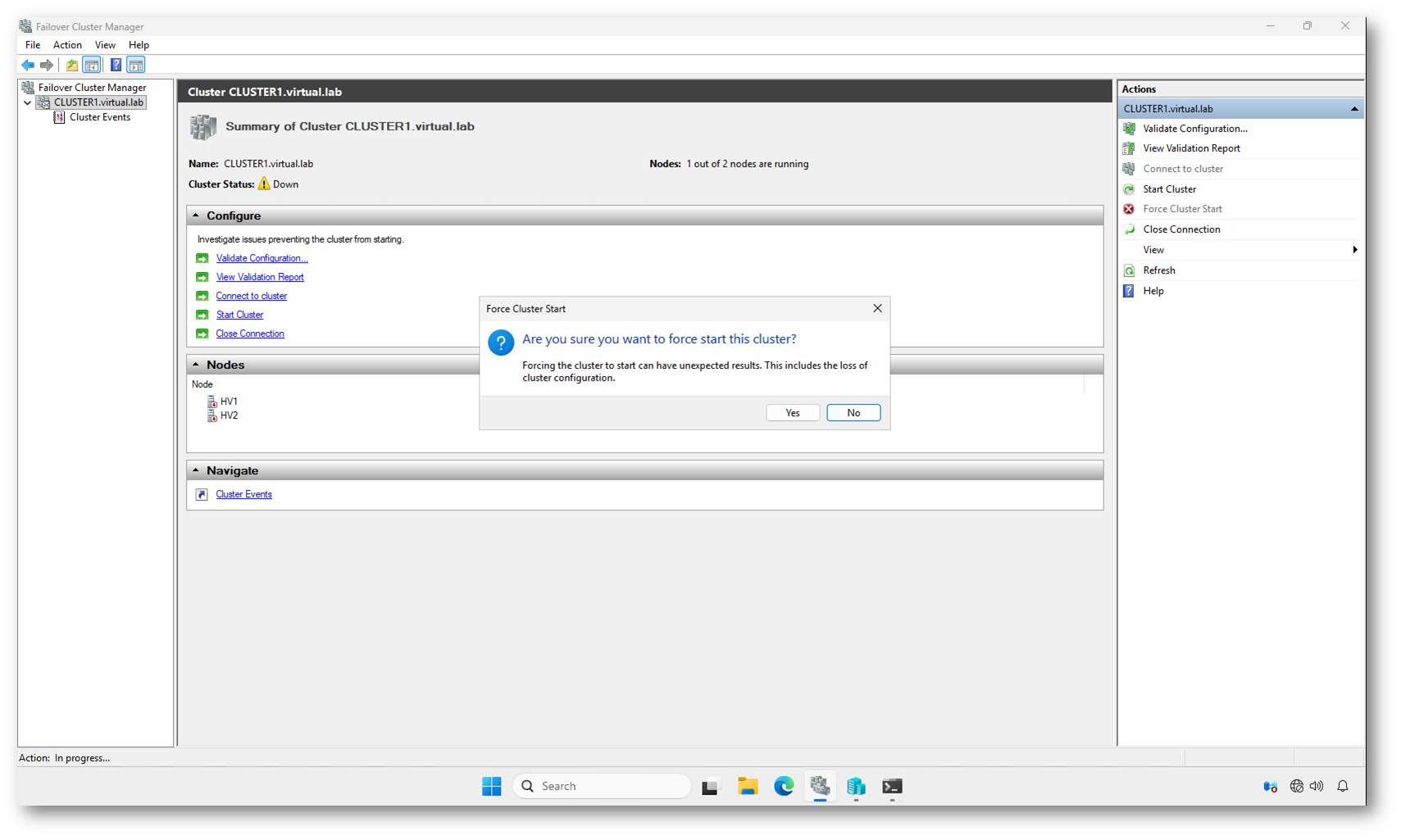
Figura 5: Avviso di Force Cluster Start: l’avvio forzato ignora temporaneamente il quorum e può causare incoerenze o perdita della configurazione se altri nodi risultano attivi
Dopo aver confermato il warning, il cluster viene avviato utilizzando l’opzione ForceQuorum.
La finestra mostra chiaramente:
Attempting to start the cluster using ForceQuorum option…
Questo significa che il nodo HV1 sta formando il cluster considerandosi temporaneamente autorevole, ignorando la necessità della maggioranza dei voti prevista dal modello di quorum.
Tecnicamente sta accadendo questo:
- Il servizio ClusSvc carica il database cluster locale.
- Viene ignorato il requisito di maggioranza.
- Il nodo assume la proprietà del cluster.
- Le risorse vengono inizializzate in base alla configurazione presente localmente.
È un’operazione legittima in scenari di disaster recovery, ma rappresenta una deviazione dal comportamento normale del cluster.
In questo momento:
- Il cluster può tornare operativo.
- Le VM possono essere riavviate.
- L’infrastruttura può riprendere servizio.
Tuttavia, il sistema resta in uno stato di quorum forzato finché non viene ristabilita la topologia completa e non rientra il secondo nodo.
Questa schermata rappresenta il passaggio chiave tra ambiente fermo e ripristino operativo controllato.
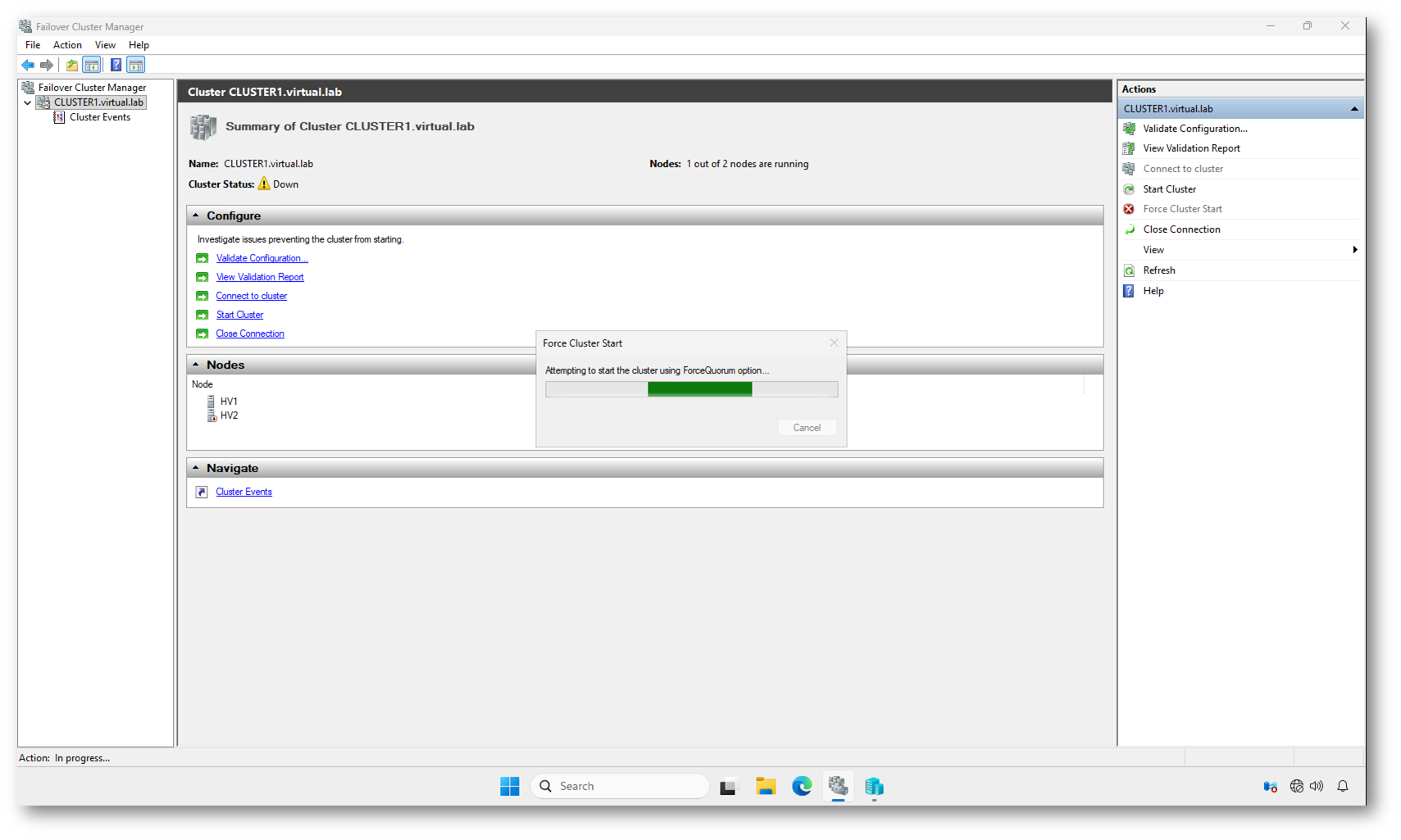
Figura 6: Avvio del cluster con opzione ForceQuorum
Come si può vedere dalla schermata sotto, il servizio cluster è effettivamente avviato e il cluster risulta online sul nodo corrente. Il Server Name è Online, segno che il cluster è stato formato, in questo caso grazie al ForceQuorum.
Tuttavia, nelle Cluster Core Resources, il File Share Witness è in stato Failed.
Questo significa che:
- Il database cluster è stato caricato.
- Il nodo ha assunto la proprietà del cluster.
- Ma il witness non è raggiungibile.
Ed è qui che emerge l’errore architetturale.
Il File Share Witness è ospitato sul Domain Controller (\\DC1\FSW). Se il DC è spento, o non ancora disponibile dopo il blackout, il cluster perde automaticamente il voto del witness.
In un modello Node and File Share Majority, questo è critico: il witness rappresenta il terzo voto necessario a garantire la maggioranza (nel mio caso di un cluster a due nodi). Posizionarlo sullo stesso DC che potrebbe non avviarsi significa introdurre una dipendenza circolare:
- Il cluster ha bisogno del quorum per avviarsi.
- Il quorum dipende dal witness.
- Il witness dipende dal DC.
È un errore molto diffuso, spesso fatto per comodità, ma che in caso di riavvio completo compromette la resilienza dell’intera infrastruttura.
Il servizio cluster può partire, ma l’architettura non è realmente fault tolerant.
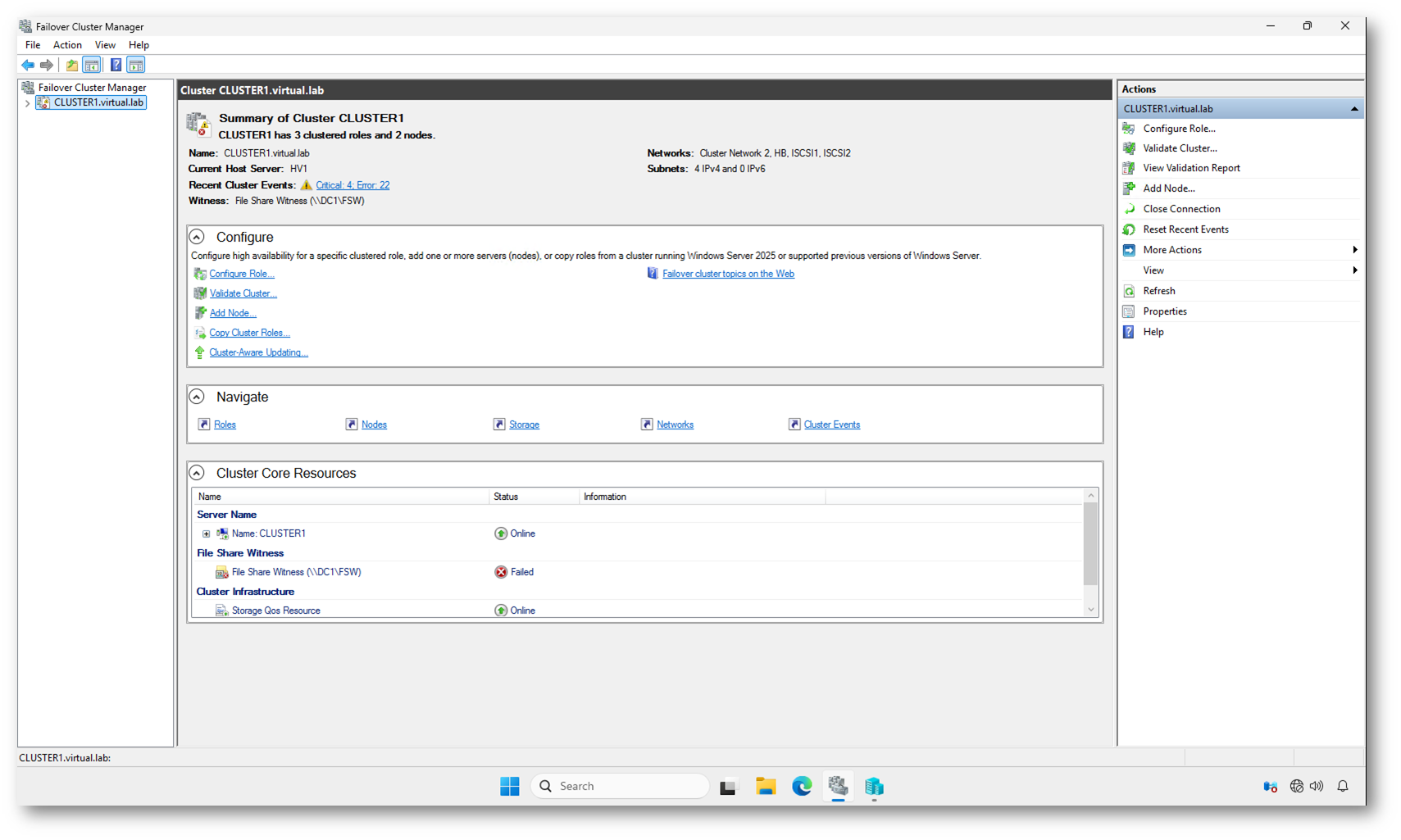
Figura 7: Il Cluster Service è attivo, ma il File Share Witness risulta Failed perché ospitato sul Domain Controller non disponibile
Dopo il Force Cluster Start, il cluster risulta online sul nodo HV1, ma nella sezione Roles vedete le macchine virtuali in stato Pending o Loading.
Questo comportamento è coerente con quanto visto negli eventi precedenti.
Quando il cluster viene avviato in modalità forzata:
- il nodo diventa proprietario delle risorse,
- il database di configurazione viene caricato dalla copia locale,
- le risorse vengono inizializzate una per una.
Se però il Network Name del cluster non riesce ad autenticarsi verso Active Directory, alcune risorse restano temporaneamente in stato di attesa. In particolare:
- le VM clusterizzate devono essere “attaccate” al contesto cluster,
- le dipendenze vengono verificate,
- eventuali controlli di autenticazione possono rallentare l’inizializzazione.
È importante distinguere tra:
- VM effettivamente spente,
- VM in fase di inizializzazione cluster,
- VM operative ma non ancora completamente registrate come risorsa online.
In uno scenario di blackout con dominio non disponibile, è normale osservare questo stato transitorio finché le risorse non completano la propria inizializzazione locale.
Se le VM risultano effettivamente in esecuzione a livello Hyper-V ma ancora in Loading lato cluster, significa che l’infrastruttura di virtualizzazione è attiva, mentre il layer di orchestrazione cluster sta ancora tentando di sincronizzarsi.
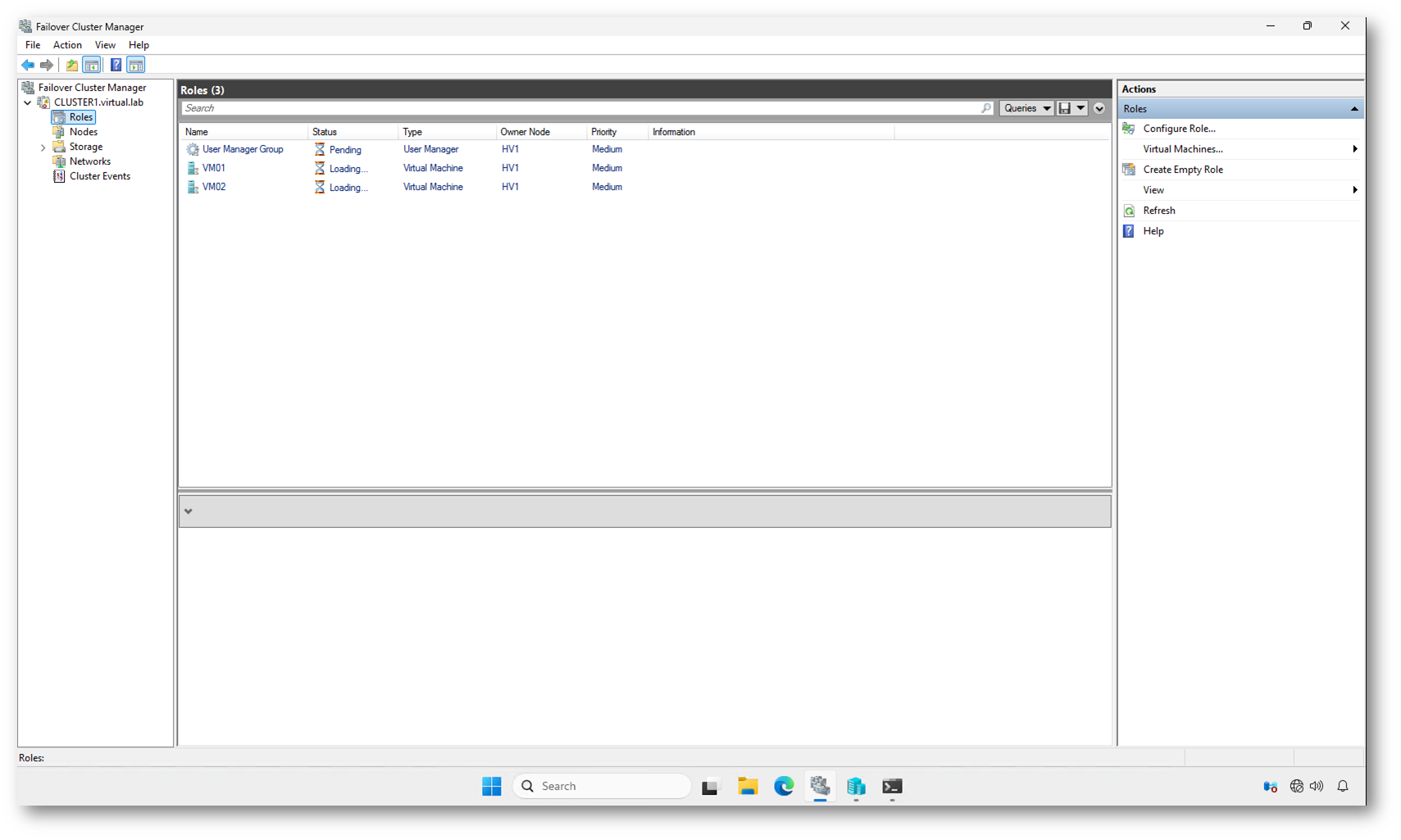
Figura 8: Dopo il Force Cluster Start, le VM risultano in stato Pending/Loading; il cluster è attivo su un solo nodo ma non ha ancora completato la piena inizializzazione delle risorse, anche a causa dell’assenza di Active Directory
Come si può vedere dalla figura sotto, il ruolo User Manager Group è Running, mentre le VM risultano Off. Il cluster è attivo, ma le macchine virtuali non vengono necessariamente avviate automaticamente in questa fase, soprattutto se l’ambiente è stato riavviato in modalità di emergenza.
NOTA: Il ruolo User Manager Group non è una macchina virtuale, ma un ruolo applicativo clusterizzato. Si tratta del servizio User Manager di Windows (User Management Service), che gestisce componenti legati agli account utente locali e ad alcune funzionalità di gestione identità a livello di sistema.
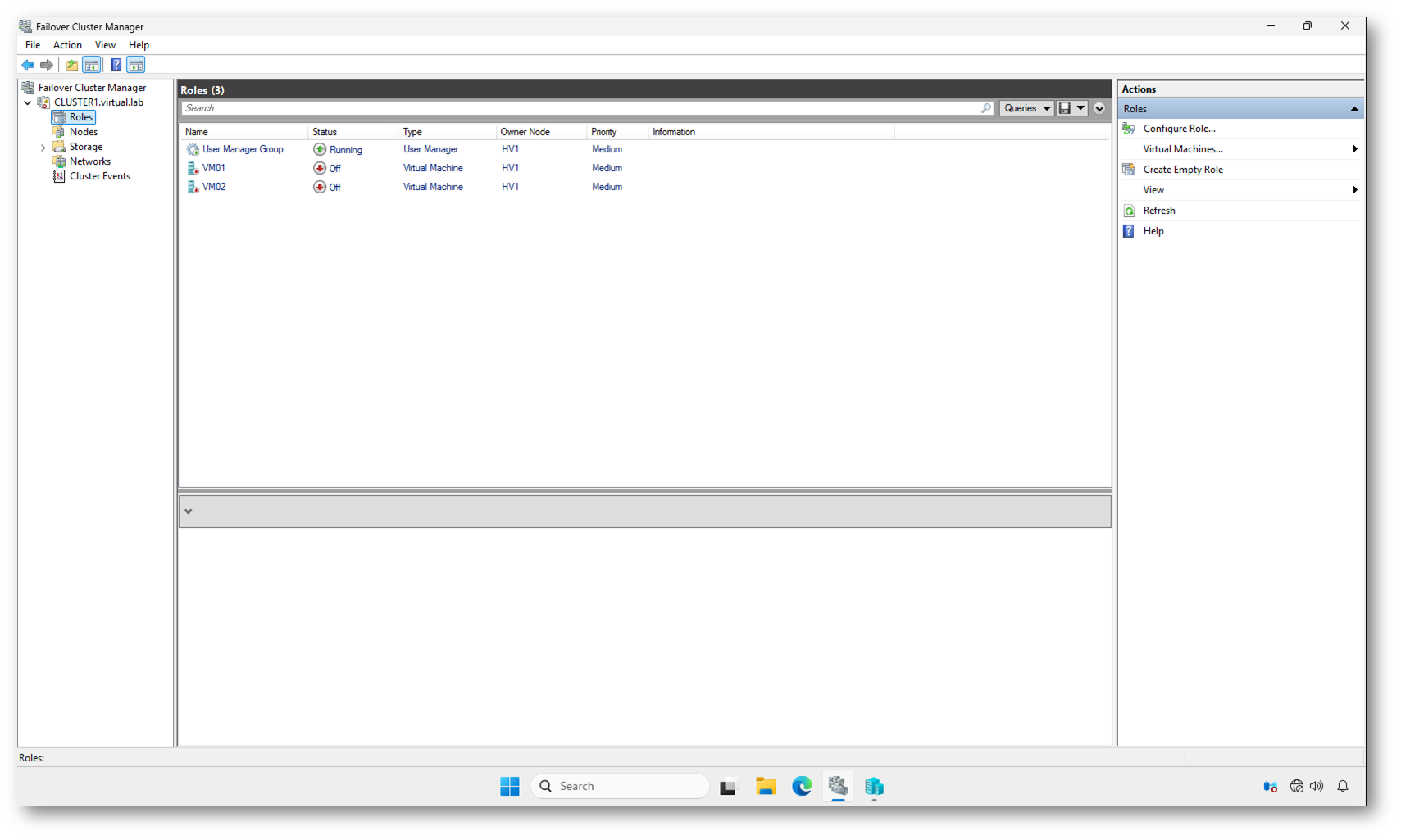
Figura 9: Dopo il Force Cluster Start, HV1 assume la proprietà del cluster e le risorse possono essere portate online
Ho provato ad avviare le VM e si sono avviate senza problemi.
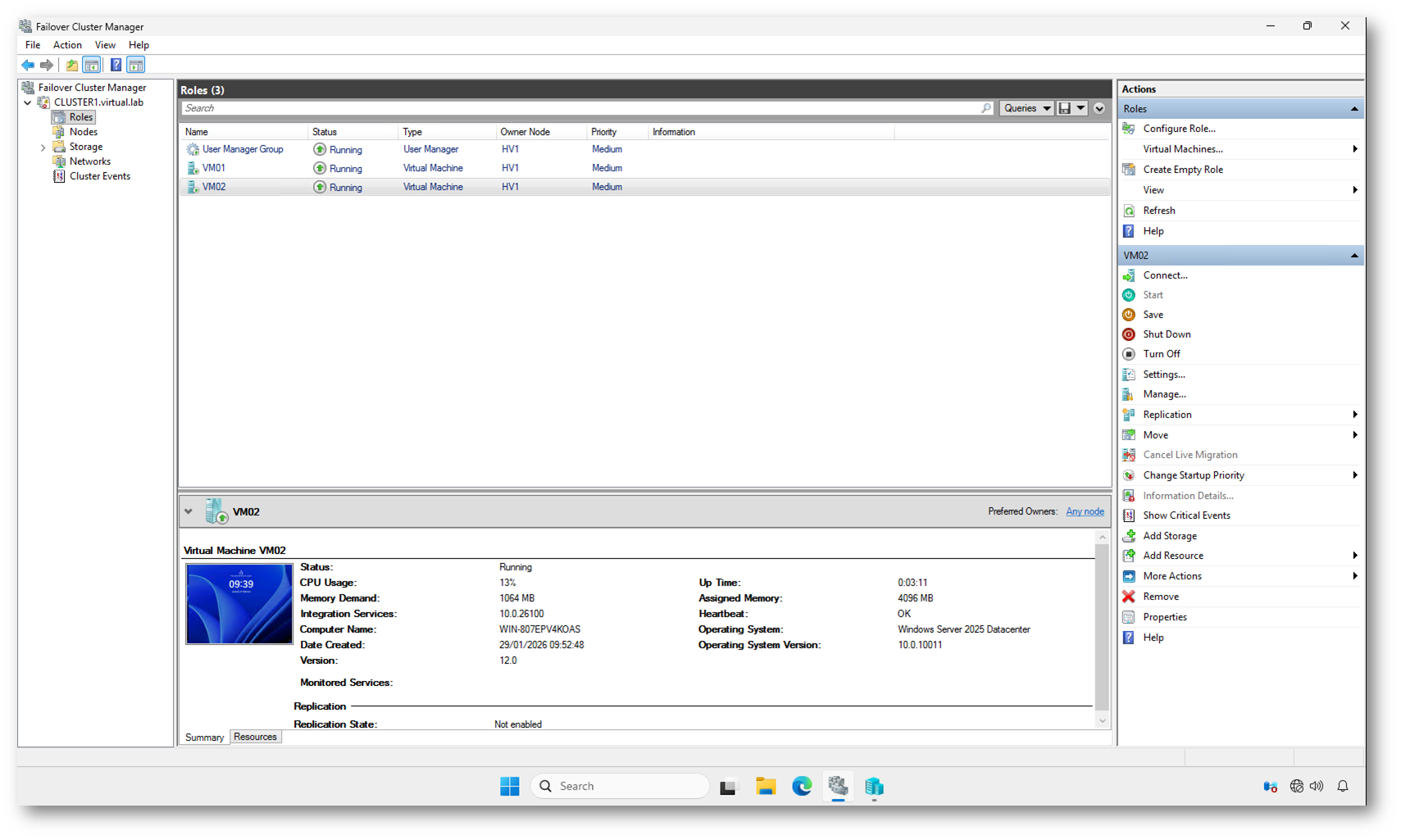
Figura 10: Avvio manuale delle VM dopo il Force Cluster Start effettuato con successo
Negli Eventi di cluster compare un errore chiaro (Event ID 1683):
The cluster service was unable to reach any available domain controller on the domain.
Il cluster ora è attivo perché avete bypassato il quorum standard, ma il servizio continua a tentare la validazione del Cluster Name Object (CNO) contro Active Directory.
L’errore non impedisce l’avvio forzato, ma indica che:
- non è possibile autenticare il Network Name del cluster
- le operazioni che dipendono da Kerberos potrebbero non funzionare
- eventuali risorse che richiedono autenticazione di dominio possono restare in stato di errore
È importante capire che il cluster è operativo in modalità “degradata”. La sua identità di dominio non è verificata e tutte le funzionalità che dipendono dall’accesso a un Domain Controller restano limitate.
Finché almeno un Domain Controller non torna raggiungibile, il cluster resta in uno stato funzionale ma non pienamente conforme al modello di sicurezza previsto.
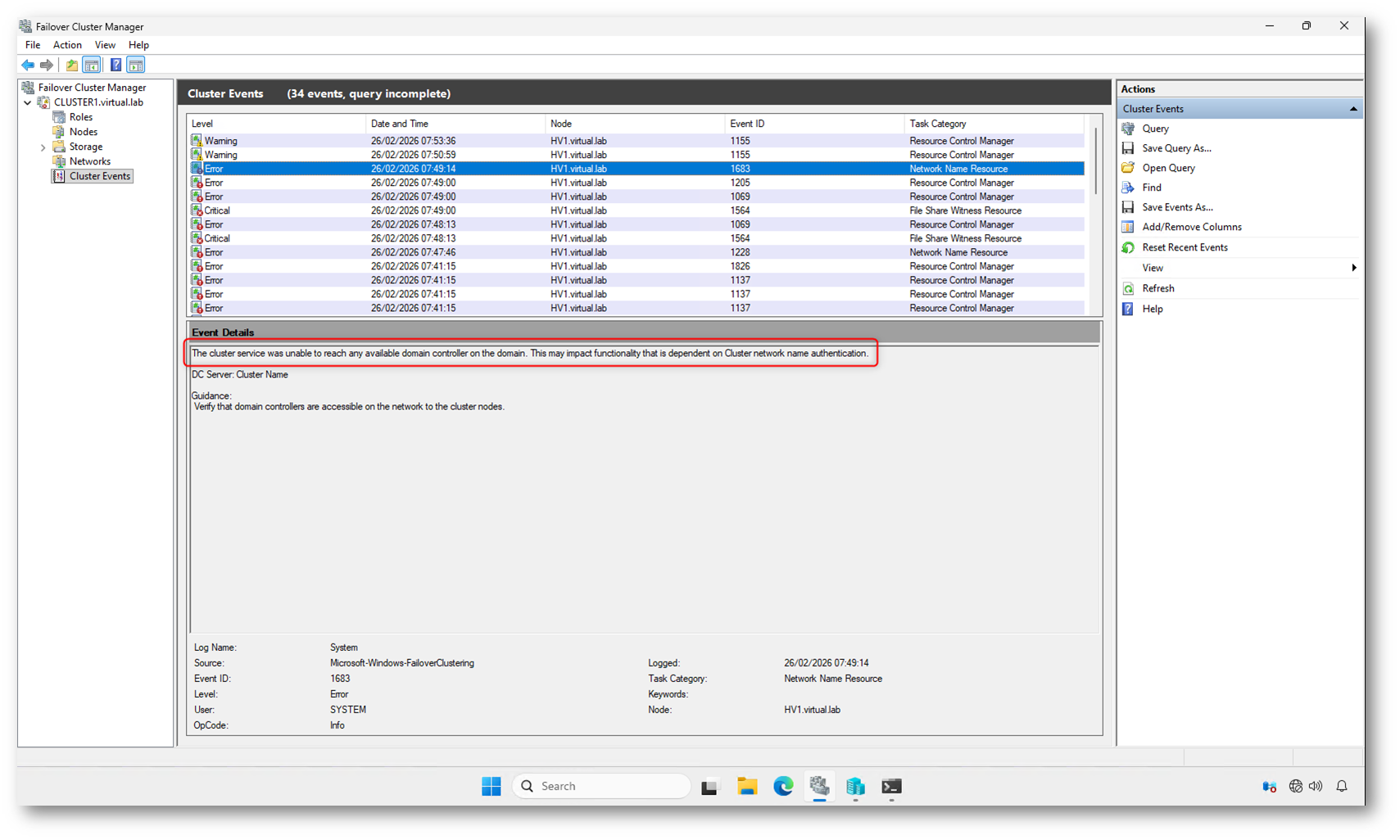
Figura 11: il servizio cluster è attivo ma non riesce a contattare alcun Domain Controller, confermando l’assenza di Active Directory durante il bootstrap
Avvio anche il secondo nodo
Come potete vedere dalla figura sotto; il cluster è operativo su HV1, mentre HV2 risulta Down.
Significa che:
- Il servizio ClusSvc su HV2 non è ancora attivo oppure
- Il nodo è acceso ma non ha ancora ristabilito la comunicazione cluster
- Non partecipa al quorum
Notate che il nodo Down non contribuisce al voto corrente. Il cluster sta quindi operando di fatto come single-node in modalità di emergenza.
Quando avviate HV2, il servizio cluster sul secondo nodo:
- Rileva l’esistenza del cluster.
- Contatta il nodo proprietario (HV1).
- Verifica la coerenza del database cluster.
- Entra prima in stato Joining.
- Poi passa a Up.
Questo è il momento in cui il quorum torna in modalità normale e il cluster esce dalla condizione forzata.
Finché il secondo nodo è Down, l’ambiente è funzionante ma non realmente ad alta disponibilità. Con il rientro del nodo, l’architettura torna coerente e resiliente.
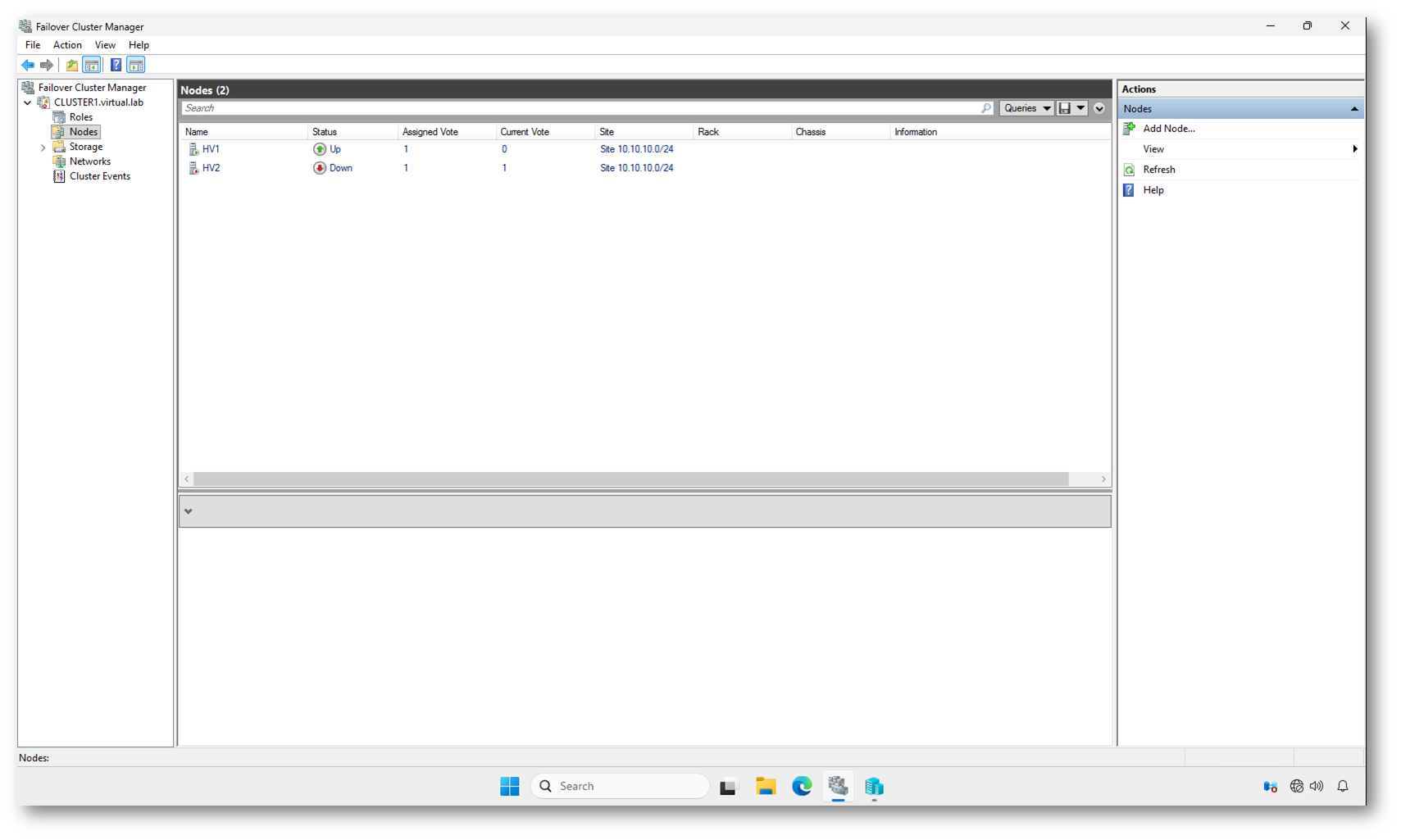
Figura 12: Il nodo HV2 è in stato Down: il cluster è operativo solo su HV1 finché il secondo nodo non viene riavviato e reintegrato nel quorum
Dopo essere riuscito ad avviare anche HV2, nella sezione Nodes ho visto comparire lo stato Joining.
Il fatto che il nodo riesca a entrare in Joining indica che la comunicazione inter-nodo funziona correttamente e che non esistono più condizioni di isolamento.
Se nel frattempo è tornato disponibile almeno un Domain Controller, l’autenticazione del CNO viene completata e il cluster torna in uno stato pienamente coerente. Se invece il dominio è ancora assente, il nodo può comunque unirsi, ma eventuali risorse dipendenti dall’autenticazione continueranno a segnalare errori finché AD non sarà raggiungibile.
Dopo qualche secondo, lo stato dovrebbe passare a Up, con assegnazione del voto nel quorum e ripristino della piena operatività del cluster.
Questo è il momento in cui l’ambiente esce realmente dalla modalità di emergenza.
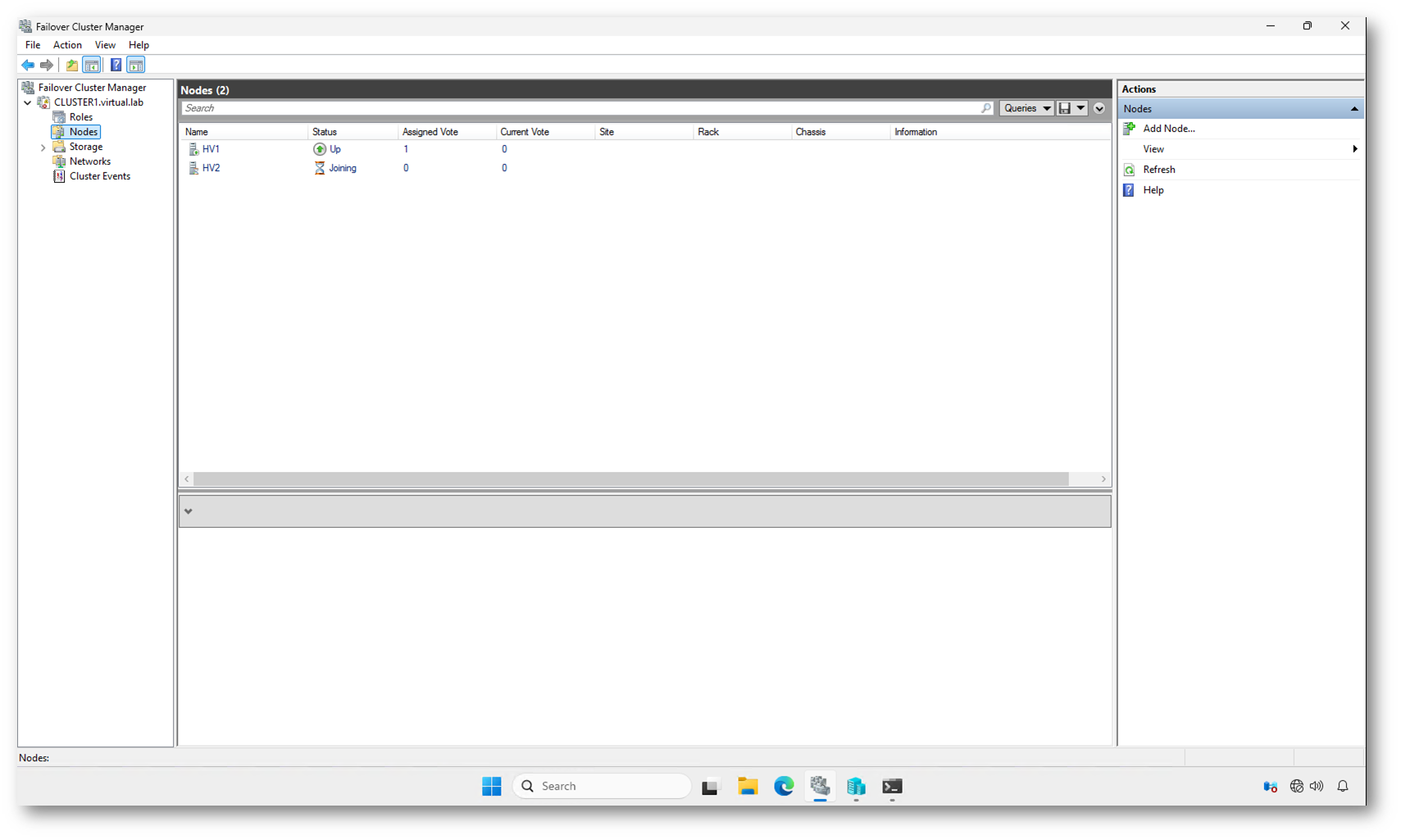
Figura 13: Il nodo HV2 entra in stato Joining. Il servizio cluster è attivo e sta sincronizzando la configurazione con il nodo già operativo, ripristinando il quorum
Dopo qualche secondo dall’avvio di HV2, lo stato passa da Down/Joining a Up.
Questo significa che:
- Il secondo nodo ha completato la sincronizzazione del database cluster.
- Il quorum non è più in modalità forzata.
- Il cluster è tornato in configurazione standard.
- La resilienza è ripristinata.
In questo momento l’infrastruttura esce ufficialmente dalla modalità di emergenza. Il cluster non è più “single node autorevole”, ma è tornato a funzionare secondo il modello previsto dal quorum configurato.
Questo è il punto in cui potete considerare concluso il recovery post-blackout: Il cluster è operativo, il quorum è valido e l’alta disponibilità è nuovamente garantita.
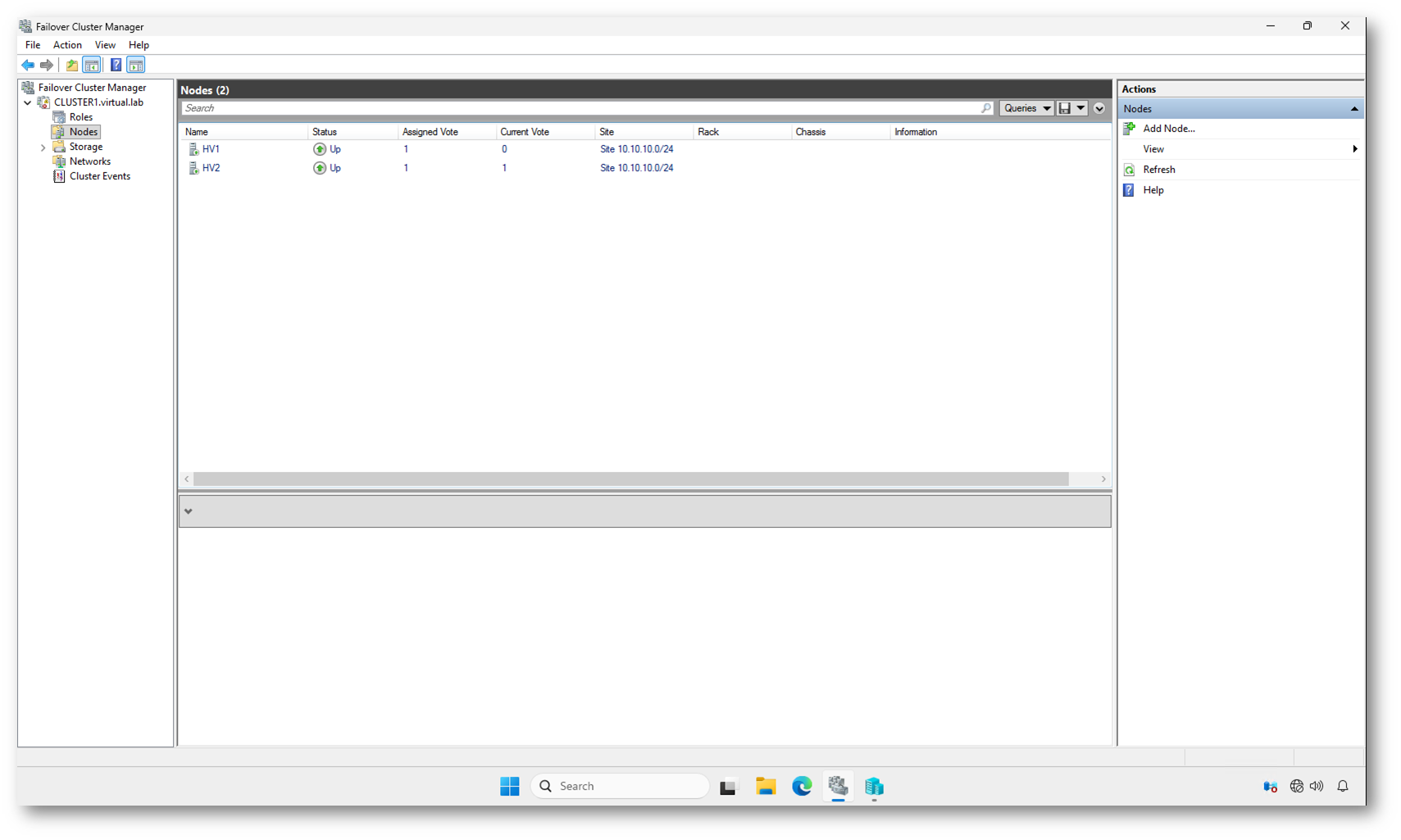
Figura 14: Entrambi i nodi risultano Up: il quorum è ristabilito e il cluster è tornato in modalità operativa standard
Live Migration senza Active Directory: perché fallisce
Il cluster è partito.
Le VM sono accese.
Entrambi i nodi risultano Up.
Ma non è tutto oro quel che luccica. Infatti, quando provate a eseguire una Live Migration da HV1 a HV2, l’operazione fallisce.
L’errore è chiaro:
No authority could be contacted for authentication (0x80090311)
Qui non è il cluster ad avere un problema. È l’autenticazione.
La Live Migration in un cluster domain-based utilizza Kerberos per autenticare la comunicazione tra i nodi Hyper-V. Kerberos, per definizione, necessita di un Domain Controller raggiungibile che possa emettere e validare i ticket di sicurezza.
Se Active Directory non è disponibile, il servizio cluster può comunque avviarsi in modalità di emergenza e le VM possono essere portate online. Tuttavia, quando si tenta un’operazione che richiede autenticazione tra nodi, come la Live Migration, il processo si blocca perché non esiste un’autorità che possa validare le credenziali.
Il codice errore 0x80090311 è inequivocabile: il sistema non riesce a contattare un’autorità di autenticazione.
Questo dimostra un punto fondamentale: il cluster può funzionare in modalità degradato senza AD, ma non è pienamente operativo. Finché Active Directory non torna disponibile, alcune funzionalità critiche restano inevitabilmente non utilizzabili.
Nella figura sotto si può vedere che ho lanciato la Live Migration e che lo stato della macchina rimane in Migration Queued in attesa che il cluster contatti un domain controller per l’autenticazione del servizio di spostamento della VM.
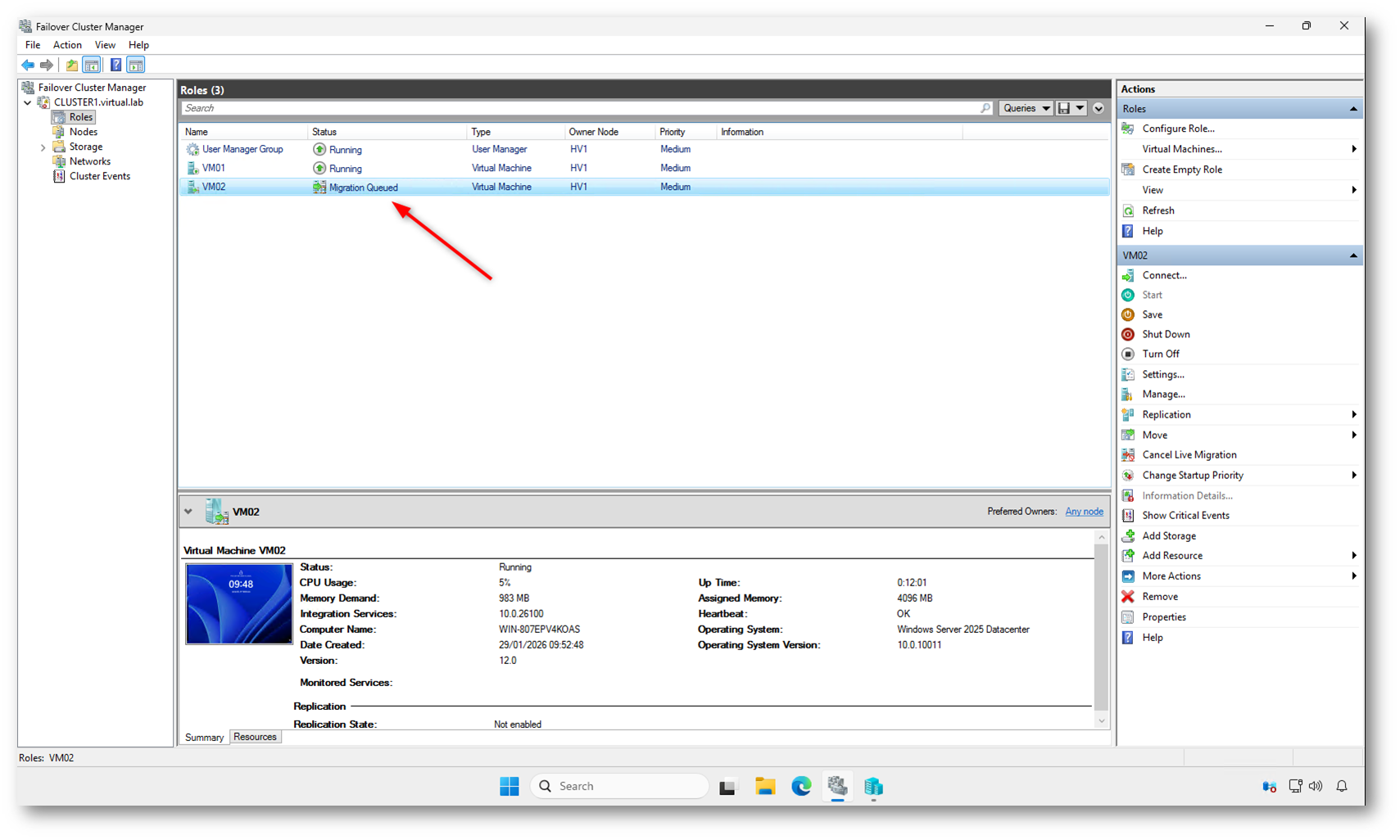
Figura 15: Tentativo di Live Migration con stato “Migration Queued”
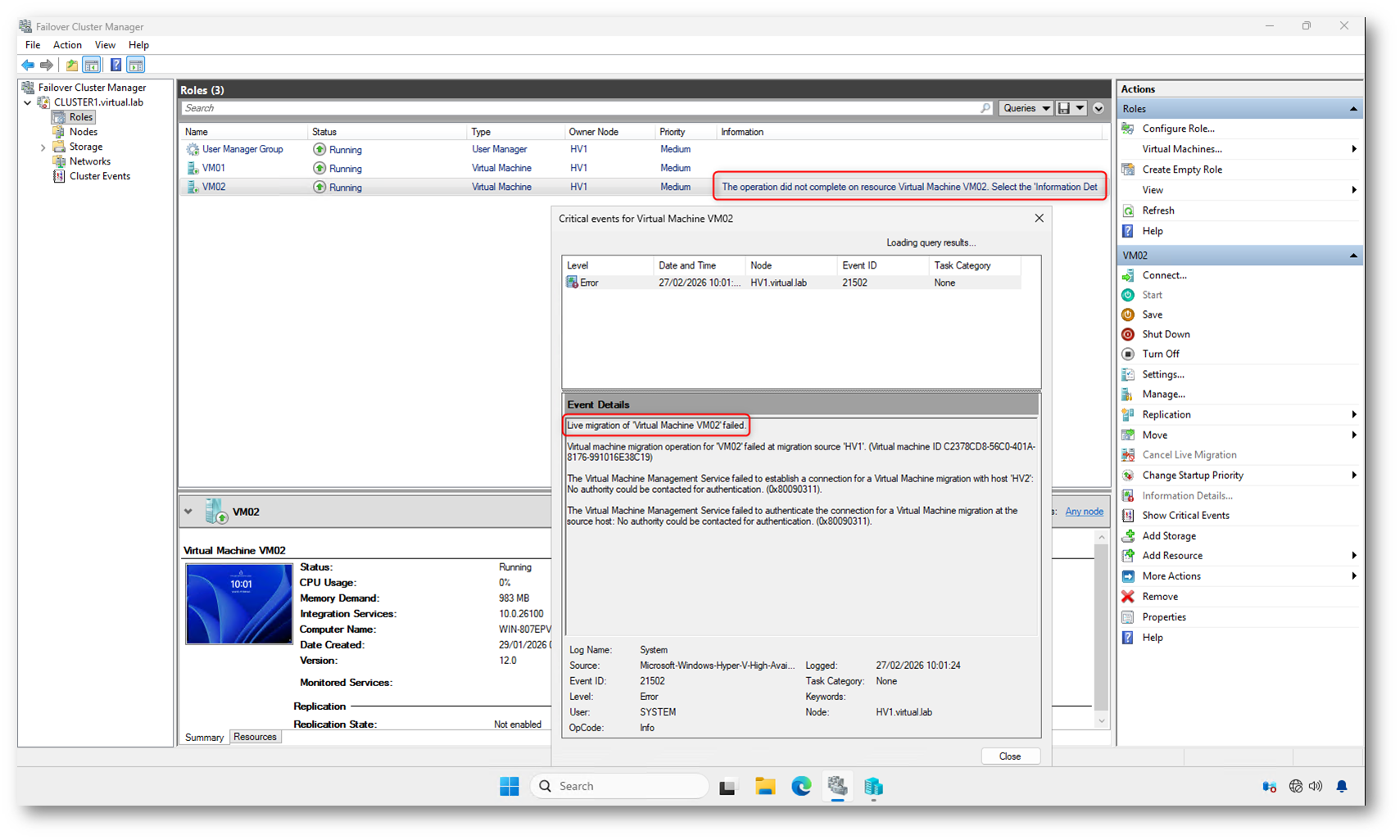
Figura 16: Errore durante la Live Migration: autenticazione Kerberos fallita per assenza di Domain Controller (0x80090311)
Best practice: come evitare di restare senza Active Directory
Se avete un Failover Cluster Hyper-V, dovete partire da un presupposto architetturale molto semplice: il cluster dipende da Active Directory, quindi Active Directory non può dipendere dal cluster.
Sembra banale. Non lo è.
La prima best practice è avere almeno due Domain Controller virtuali, distribuiti su nodi differenti, ma non clusterizzati.
Un Domain Controller non deve essere configurato come ruolo cluster. Deve essere una VM “normale”, ospitata su un nodo del cluster, con avvio automatico configurato a livello Hyper-V e senza alcuna dipendenza dal servizio cluster per il proprio funzionamento.
L’avvio automatico è fondamentale perché, in caso di riaccensione totale dell’infrastruttura, il DC deve partire immediatamente dopo il boot dell’host, senza attendere la formazione del quorum o l’inizializzazione del cluster. Il controller di dominio deve essere disponibile prima che il cluster tenti di autenticarsi.
Se scegliete questa soluzione, assicuratevi di avere un numero adeguato di Domain Controller funzionanti, distribuiti sui diversi nodi del cluster. Tutti devono essere VM non clusterizzate, come già detto, e non concentrate su un singolo host. La distribuzione riduce il rischio che la perdita di un nodo renda indisponibile l’intera infrastruttura di autenticazione.
Potete inoltre valutare l’utilizzo di Hyper-V Replica per proteggere i Domain Controller anche all’interno dello stesso cluster o verso un sito remoto.
Ad esempio, in un cluster a due nodi, potete incrociare le repliche: il DC in esecuzione su HV1 viene replicato su HV2 e viceversa. In questo modo ogni nodo ospita la replica dell’altro Domain Controller.
In caso di guasto di un host, di indisponibilità prolungata o di perdita del cluster primario, è possibile attivare rapidamente la replica e riaccendere il DC sul nodo alternativo o sul sito secondario, ripristinando prima di tutto l’infrastruttura di identità.
L’obiettivo è chiaro: garantire che almeno un Domain Controller possa essere avviato rapidamente, anche se il cluster principale non è ancora pienamente operativo.
Domain Controller virtuali sì, ma non clusterizzati
Come potete vedere dalla figura sotto, il Domain Controller (DC01) in esecuzione su HV1, con una caratteristica fondamentale: Clustered: No
Questo è corretto. Un Domain Controller virtuale non deve essere configurato come ruolo cluster. Deve essere una VM “standalone” gestita da Hyper-V, non dal servizio cluster.
Perché? Se il DC fosse un ruolo cluster, la sua accensione dipenderebbe dal cluster stesso. Ma il cluster, per funzionare correttamente, ha bisogno di Active Directory. Si creerebbe una dipendenza circolare: Cluster → DC → AD → Cluster
In caso di riavvio completo dell’infrastruttura, rischiate di bloccarvi prima ancora di poter intervenire.
In questo scenario invece:
- Il nodo Hyper-V si avvia.
- La VM DC01 parte automaticamente.
- Active Directory torna disponibile.
- Il cluster può autenticarsi correttamente e riprendere le funzionalità complete.
È una differenza architetturale enorme.
Il principio è semplice:
Il Domain Controller può stare sul cluster, ma non deve dipendere dal cluster.
Se progettate così l’infrastruttura, nella maggior parte dei casi non vi troverete mai nella condizione di dover forzare il quorum per far ripartire l’ambiente.
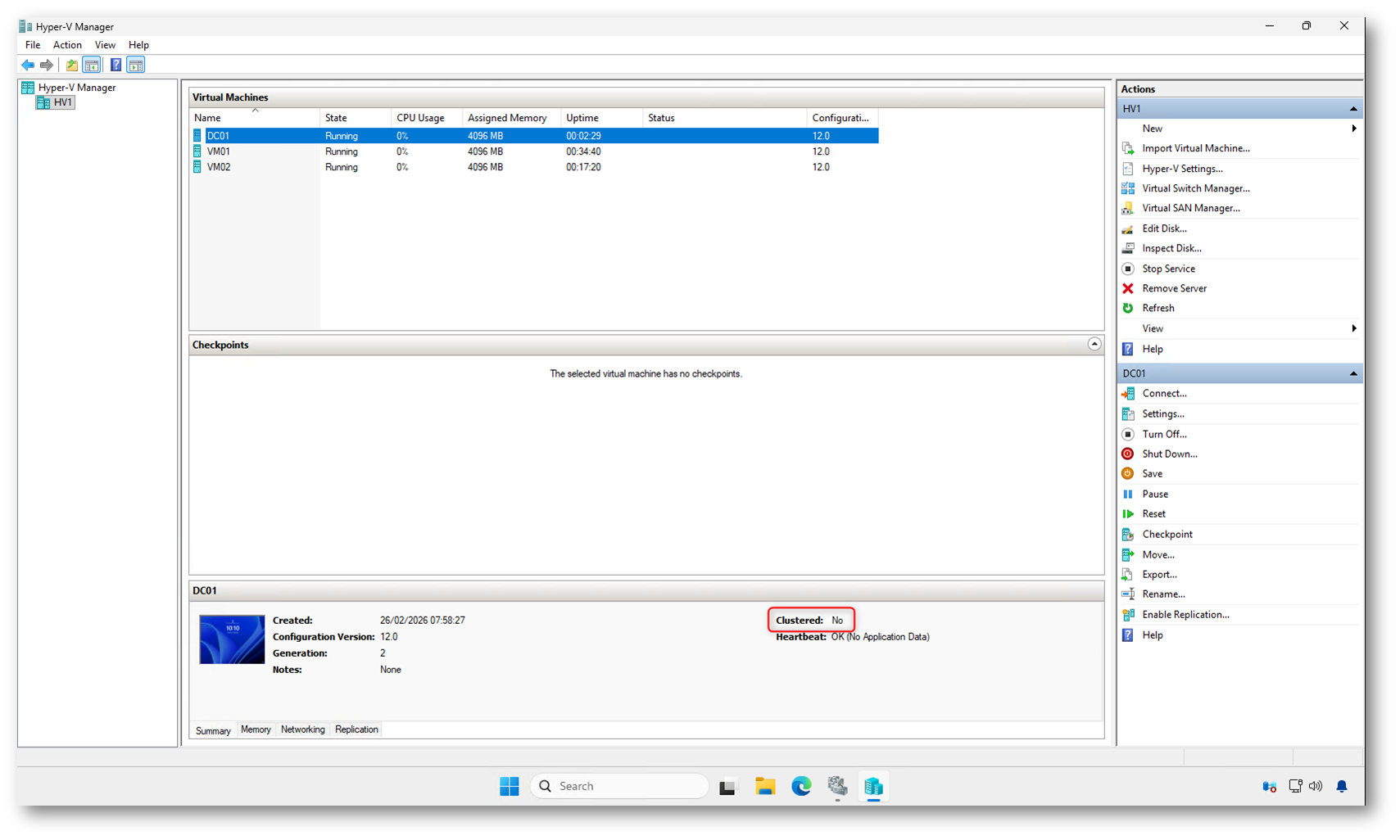
Figura 17: Domain Controller virtuali sì, ma non clusterizzati
È sufficiente contattare un solo Domain Controller? Serve quello con i ruoli FSMO?
Per il corretto funzionamento di un Failover Cluster è sufficiente che sia raggiungibile almeno un Domain Controller scrivibile del dominio. Il cluster utilizza Active Directory per l’autenticazione tramite Kerberos, per la gestione del Cluster Name Object (CNO) e per eventuali aggiornamenti degli oggetti computer. Non è necessario che il DC disponibile detenga specifici ruoli FSMO: il cluster non richiede che sia online il PDC Emulator o altri ruoli operativi per funzionare correttamente.
Quello che conta davvero è che il Domain Controller sia scrivibile, correttamente replicato e raggiungibile dalla rete dei nodi. Un RODC non è sufficiente per garantire piena operatività. In altre parole, non importa quale DC sia acceso, purché ce ne sia almeno uno in grado di rispondere alle richieste di autenticazione del cluster.
Ripristinato Active Directory: la Live Migration torna operativa
Dopo l’avvio di almeno un Domain Controller e il ripristino della piena raggiungibilità di Active Directory, il comportamento del cluster cambia immediatamente.
La Live Migration, che prima falliva con errore di autenticazione (0x80090311), torna a funzionare correttamente.
Finché AD non è disponibile, il cluster può ospitare e avviare VM, ma non può garantire tutte le funzionalità di alta disponibilità.
Nella figura sotto si vede chiaramente che la VM VM02 ha come Owner Node: HV2. Questo significa che la migrazione tra i nodi è stata completata con successo.
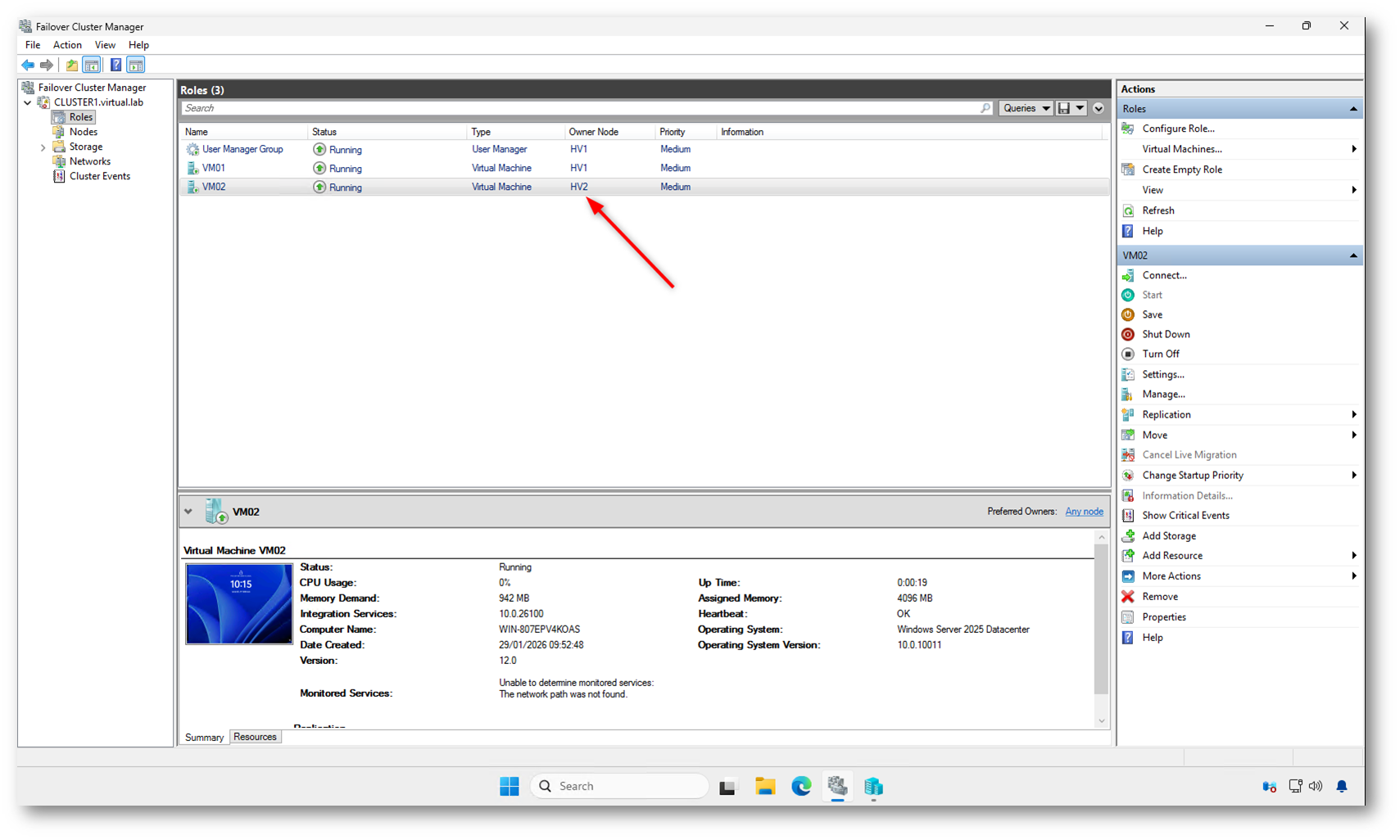
Figura 18: Dopo il ripristino di Active Directory, la Live Migration viene completata con successo
Scenario critico: tutti i Domain Controller sono VM nel cluster
Questo è lo scenario che più spesso porta all’utilizzo del Force Cluster Start.
Avete due o più nodi Hyper-V in cluster.
Tutti i Domain Controller sono macchine virtuali ospitate su quello stesso cluster.
Avviene un blackout completo oppure uno spegnimento totale dell’infrastruttura.
Alla riaccensione i nodi Hyper-V partono, ma il servizio cluster non riesce a raggiungere Active Directory. Il cluster resta in stato Down perché non può autenticare i nodi né validare il Cluster Name Object.
Nel frattempo, i Domain Controller non si avviano, perché sono VM gestite dal cluster.
Il cluster aspetta AD, ma AD è dentro il cluster. In architettura IT si parla di “chicken and egg problem”
In questa condizione l’unico modo per ripartire è forzare il quorum su un nodo, avviare il cluster in modalità emergenza e poi accendere manualmente almeno un Domain Controller. Solo dopo il ripristino di AD l’infrastruttura torna completamente operativa.
Non è un bug. È una scelta architetturale errata.
Il cluster può ospitare i Domain Controller, ma non deve mai trovarsi nella condizione in cui l’intera foresta dipende esclusivamente da VM che a loro volta dipendono dal cluster per partire.
Sequenza corretta di recovery
In assenza di Domain Controller raggiungibili, la sequenza di recovery è obbligata:
- Avviare un nodo Hyper-V.
- Utilizzare Force Cluster Start (ForceQuorum).
- Portare online manualmente almeno un Domain Controller.
- Attendere la piena disponibilità di Active Directory.
- Avviare o riunire gli altri nodi al cluster.
- Verificare quorum e funzionalità (Live Migration inclusa).
Solo dopo il ripristino di AD il cluster torna completamente operativo.
Best practice Microsoft ufficiali
La documentazione Microsoft sul Failover Clustering e su Active Directory Domain Services è molto chiara: il cluster è un’entità domain-based e presuppone la disponibilità di Active Directory.
Microsoft raccomanda:
- Più Domain Controller per dominio.
- Distribuzione su host differenti.
- Nessuna dipendenza circolare tra servizi core.
- Configurazione corretta del quorum (witness inclusa).
Il principio architetturale è sempre lo stesso: i servizi di infrastruttura devono poter ripartire senza dipendenze incrociate.
Perché Microsoft raccomanda almeno un DC esterno
Microsoft raccomanda fortemente che almeno un Domain Controller sia indipendente dal cluster o comunque non dipendente dal suo stato di quorum.
Un DC esterno (fisico, in un altro cluster o in un sito secondario) garantisce che:
- Kerberos sia disponibile all’avvio.
- Il CNO possa essere autenticato.
- Il cluster possa partire in modo ordinario.
- Non si verifichi il blocco “chicken-and-egg”.
Non è una questione di alta disponibilità del DC. È una questione di bootstrap dell’infrastruttura. Se almeno un Domain Controller è sempre disponibile, il cluster non avrà mai bisogno di essere avviato in modalità forzata.
Ordine di avvio consigliato
In caso di riavvio completo dell’ambiente, l’ordine corretto è:
- Storage (se esterno).
- Host Hyper-V.
- Domain Controller.
- Verifica replica AD e DNS.
- Avvio del cluster.
- Avvio delle VM applicative.
Questo ordine elimina le ambiguità e riduce drasticamente la necessità di forzare il quorum.
Alternative supportate: cluster senza dipendenza da Active Directory
In alcune situazioni può essere utile o necessario creare un Failover Cluster senza dipendere da un controller di dominio Active Directory. Questo è supportato ufficialmente da Microsoft e può essere realizzato utilizzando cluster in workgroup o meccanismi alternativi di autenticazione.
Workgroup Cluster
Un Workgroup Cluster è un cluster di failover in cui i nodi non sono membri di un dominio Active Directory, ma appartengono a un normale gruppo di lavoro. Microsoft ha introdotto questa possibilità a partire da Windows Server 2016, rendendo possibile creare cluster anche senza AD. Nel cluster in workgroup ogni nodo mantiene la propria identità locale e non vengono creati oggetti computer in Active Directory. Potete dare un’occhiata alla mia guida Implementare Workgroup Cluster e Multi-Domain Cluster in Windows Server 2016 – ICT Power
Una delle principali sfide dei cluster in workgroup è l’autenticazione tra nodi. Senza Active Directory non sono disponibili i servizi Kerberos/AD per autenticare i nodi e le risorse cluster.
In Windows Server 2025 viene prevista la possibilità di utilizzare autenticazione basata su certificati (PKU2U) tra nodi in workgroup, consentendo anche la Live Migration tra i nodi senza dominio, come ho mostrato nella mia guida Windows Server 2025 – Live migration con gli Hyper-V Workgroup Cluster – ICT Power
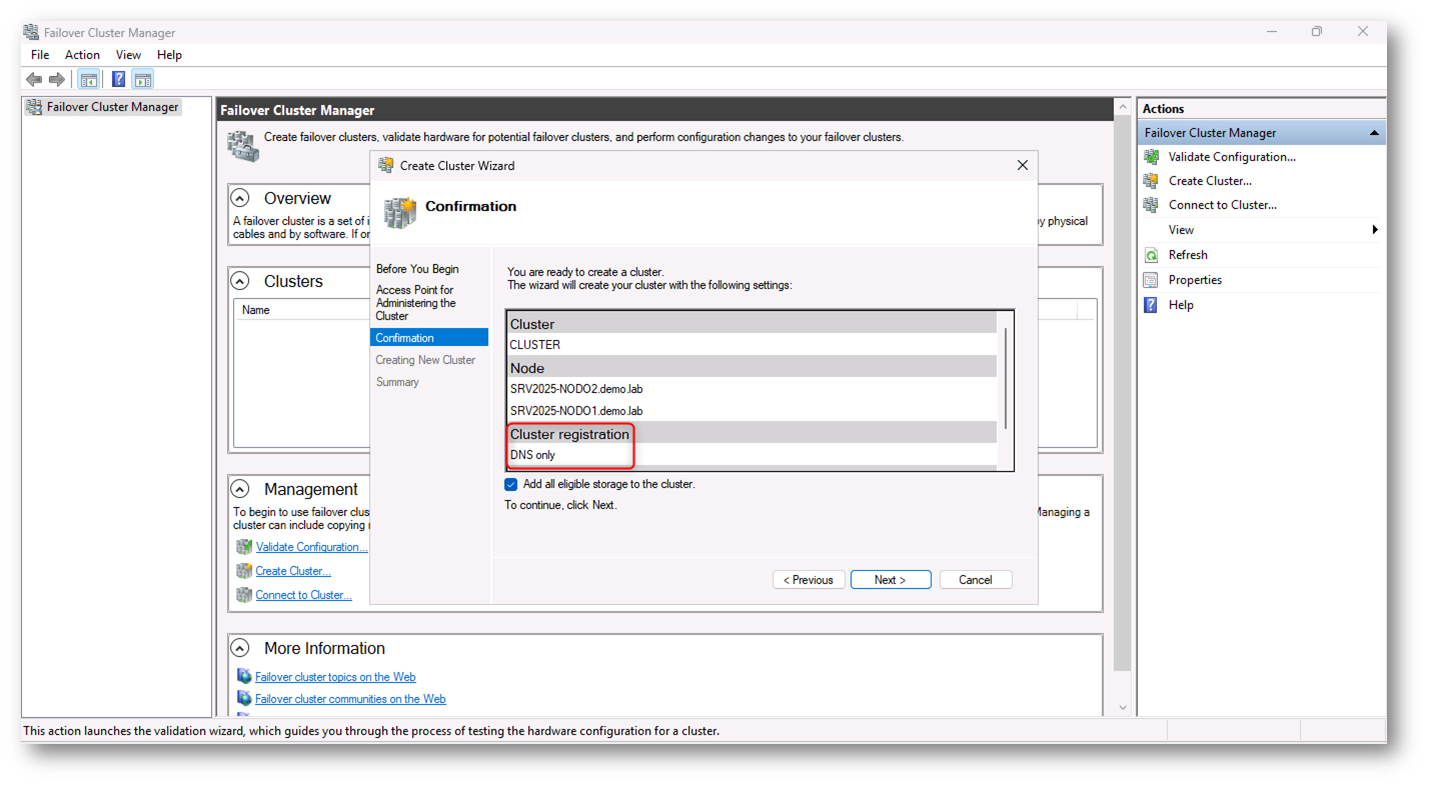
Figura 19: Creazione del cluster con opzione Cluster registration: DNS only, modalità che consente di non creare l’oggetto computer del cluster in Active Directory (AD-detached)
Limitazioni operative rispetto a un cluster domain-joined
Un workgroup cluster è una soluzione supportata e perfettamente funzionante, ma non è equivalente, dal punto di vista funzionale, a un cluster integrato in Active Directory.
La differenza principale riguarda il modello di autenticazione. In un cluster domain-joined l’autenticazione è basata su Kerberos e sull’infrastruttura di identità centralizzata fornita da AD. Questo significa delega, gestione dei permessi tramite gruppi di dominio, integrazione con criteri di sicurezza aziendali e amministrazione coerente su larga scala.
Nel workgroup cluster tutto questo non esiste. L’autenticazione tra nodi si basa su account locali identici oppure su certificati, e la gestione della sicurezza non è centralizzata. Funziona, ma richiede maggiore attenzione operativa e un controllo più rigoroso delle configurazioni.
Anche sul piano dei workload ci sono differenze. Alcuni ruoli tradizionalmente integrati con Active Directory, in particolare determinati scenari di File Server ad alta disponibilità, non sono supportati o richiedono adattamenti significativi in ambiente workgroup. Inoltre, la risoluzione dei nomi e la configurazione DNS non possono appoggiarsi a una struttura AD integrata e spesso richiedono configurazioni manuali o soluzioni alternative.
In un contesto enterprise, dove identità, sicurezza e gestione centralizzata sono elementi strutturali dell’architettura, queste differenze diventano rilevanti. Per questo motivo un cluster in workgroup va valutato attentamente e adottato con piena consapevolezza dei limiti operativi rispetto a uno scenario domain-joined.
Quando è appropriato utilizzare un Workgroup Cluster
Un workgroup cluster ha senso quando l’assenza di Active Directory è una scelta consapevole o una necessità tecnica.
Può essere appropriato in ambienti isolati, laboratori, sedi remote prive di dominio, scenari edge oppure infrastrutture in cui non si vuole introdurre una dipendenza da un dominio centrale. È anche una soluzione interessante quando si devono clusterizzare nodi appartenenti a domini differenti senza configurare trust complessi, oppure in contesti dove si vuole ridurre al minimo l’infrastruttura di supporto.
Non è una soluzione “di ripiego”. È un modello diverso, con un diverso equilibrio tra semplicità infrastrutturale e integrazione con servizi di identità centralizzati.
Detto questo, in ambienti di produzione tradizionali dove sono richieste gestione centralizzata, autenticazione federata, integrazione con policy aziendali e piena compatibilità con tutti i workload Microsoft, il cluster domain-joined rimane lo scenario raccomandato.
La scelta non è tecnica in senso assoluto. È architetturale.
| Caratteristica | Cluster Domain-Joined | Workgroup Cluster |
| Identità del cluster | Basata su Active Directory (CNO e oggetti computer) | Nessun oggetto in AD |
| Autenticazione | Kerberos con delega | Account locali identici o certificati (PKU2U) |
| Dipendenza da AD | Necessaria | Non richiesta |
| Live Migration | Integrata con Kerberos | Supportata, ma configurazione manuale |
| Gestione permessi | Gruppi e policy di dominio | Gestione locale su ogni nodo |
| Risoluzione nomi | DNS integrato in AD | DNS manuale o file HOSTS |
| File Server HA avanzato | Supporto completo | Limitazioni su alcuni scenari |
| Sicurezza centralizzata | Completa | Non centralizzata |
| Complessità iniziale | Più semplice in ambiente AD esistente | Maggiore configurazione manuale |
| Scenario ideale | Produzione enterprise | Edge, lab, ambienti isolati |
Tabella 1 – Confronto tecnico: Cluster Domain-Joined vs Workgroup Cluster
Conclusioni
Un Failover Cluster basato su Hyper-V può avviarsi e portare online le VM anche in assenza temporanea di Active Directory, ma non può garantire piena operatività senza un Domain Controller raggiungibile. Il punto non è se il cluster “funzioni” senza AD. Il punto è quando smette di funzionare correttamente.
Durante il normale runtime può sopravvivere. Durante un riavvio completo può bloccarsi. Durante operazioni che richiedono Kerberos, come la Live Migration, può fallire.
La vera lezione non riguarda il comando ForceQuorum, ma l’architettura. Se Active Directory è parte integrante dell’identità del cluster, allora deve essere progettata con lo stesso livello di resilienza.
Il problema non è la dipendenza da AD. Il problema è non aver progettato AD come servizio altamente disponibile.