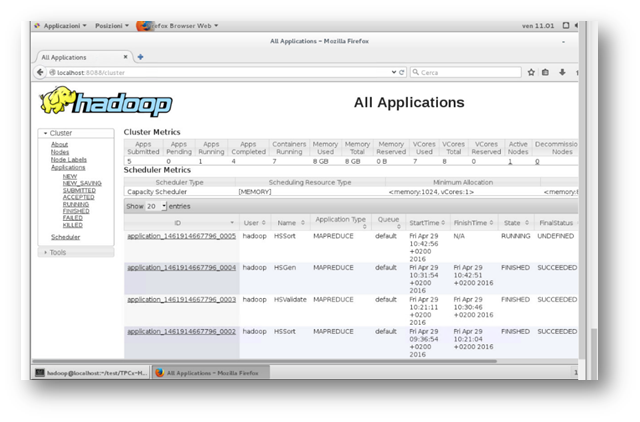
Implementare Apache Hadoop in Microsoft Azure
Dopo aver affrontato Apache Hadoop nella sua descrizione generale, in questo articolo ci occuperemo di come implementare il semplice framework Apache Hadoop senza l’uso di applicativi in grado di gestire il data processing. È importate specificare che Apache Hadoop, è un framework in grado di gestire solo HDFS e il processo di MapReduce:
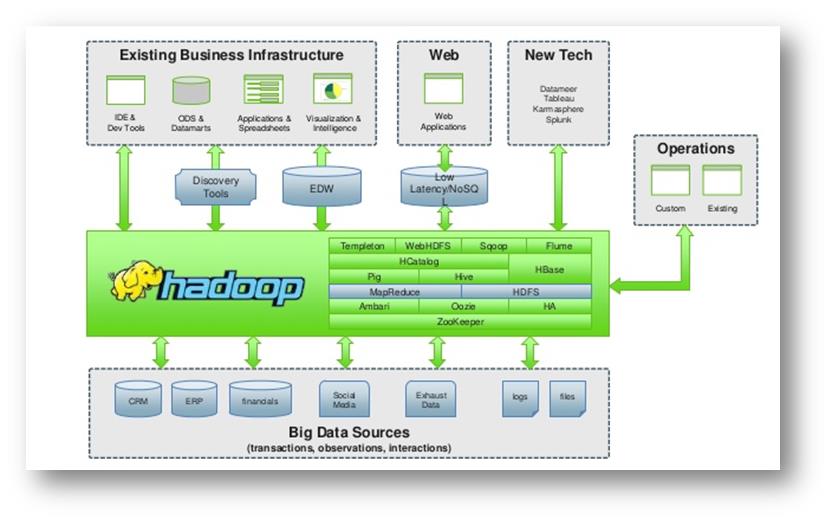
Come si nota nell’immagine, per poter interfacciare eventuali applicativi di vario genere è necessario installare in maniera parallela software come Pig, Hive, HBase etc.
Hadoop per il suo funzionamento deve essere installato su OS che sia Windows o Linux: in questa sperimentazione verrà installato su Ubuntu 16.04 LTS SERVER a 64 bit; per comodità il sistema Operativo Server, verrà installato su Microsoft Azure, in grado di creare macchine virtuali per ogni scopo, scalabili ed in grado di erogare prestazioni elevate.
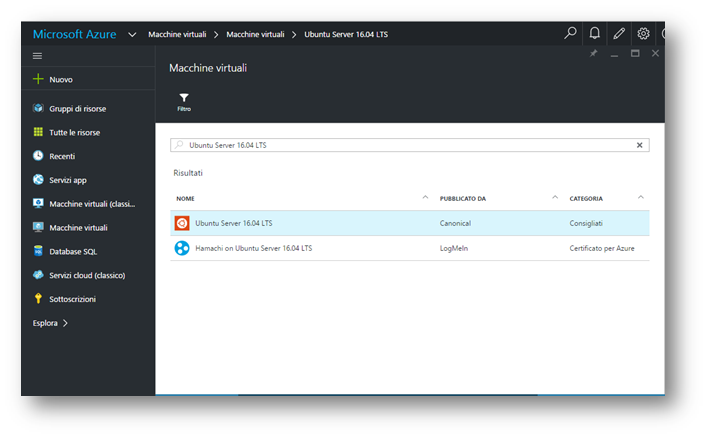
Seguendo le immagini, tramite il menu verticale occorre cliccare su “Macchine Virtuali“, all’interno cercare “Ubuntu Server 16.04 LTS” ed infine “Crea“.
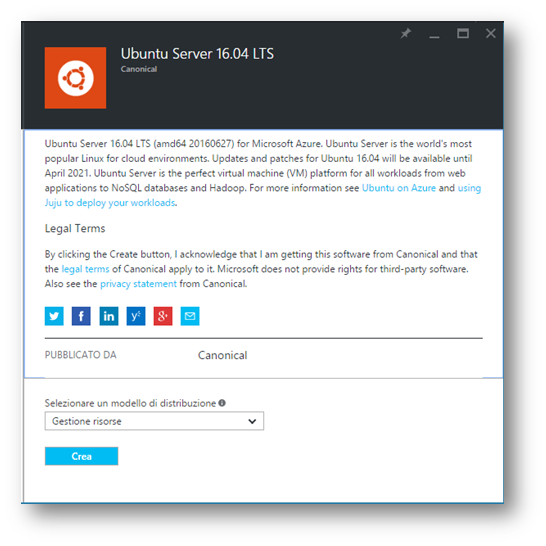
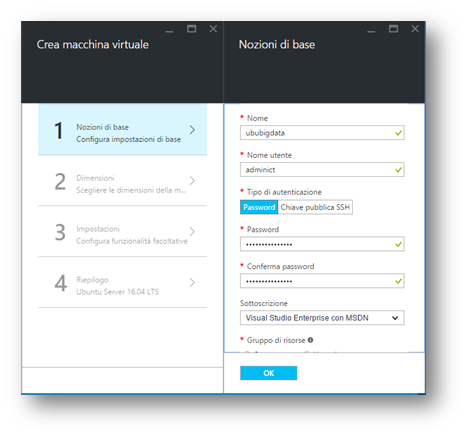
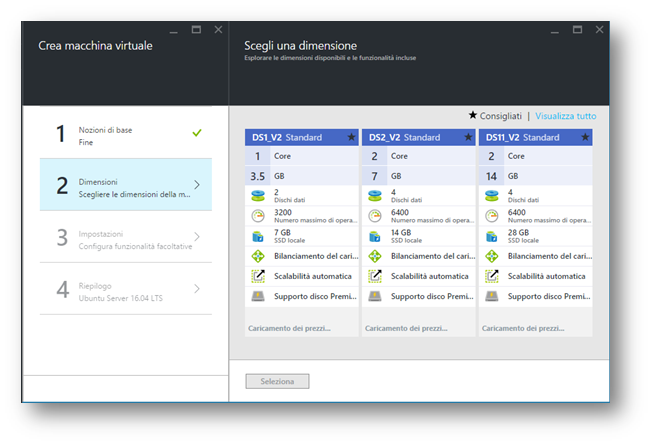
Dopo aver cliccato sul tasto “Crea“, compare la finestra dove poter creare la nostra macchina virtuale e settarla a dovere, scegliendo anche le caratteristiche fisiche della macchina stessa.
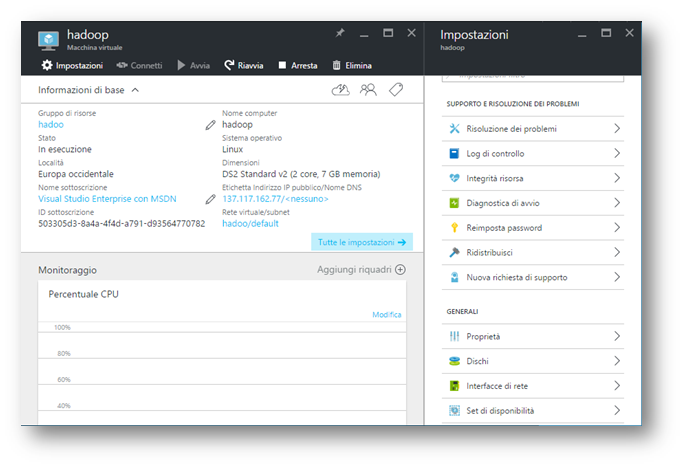
Al termine del provisioning, è possibile entrare all’interno del pannello amministrativo della macchina virtuale, dove in home page si osservano le informazioni principali, tra cui alcuni pulsanti in grado di riavviare o arrestare la macchina.
Al termine dell’installazione, si è verificato che tutti i servizi e processi fossero partiti in regola per poi iniziare la configurazione del sistema per accogliere Apache Hadoop.
Per poter collegarsi è necessario utilizzare il protocollo SSH, digitando IP e porta sul quale collegarsi nell’applicativo “Putty”.
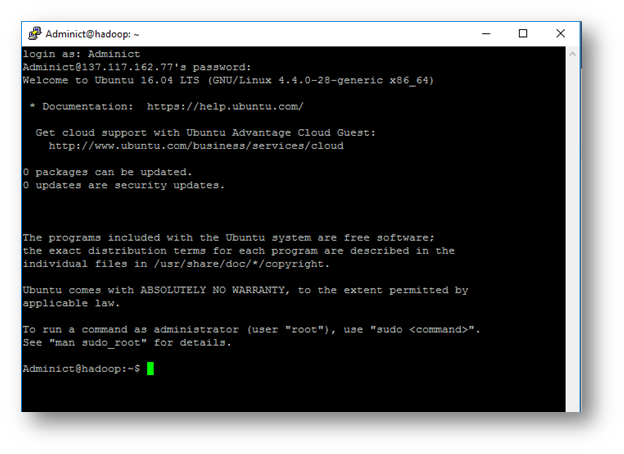
Dopo essersi loggati, di seguito vengono riportati tutti i comandi per poter preparare il sistema ad accogliere Hadoop 2.7.1 e poterlo eseguire correttamente.
Prima di procedere all’installazione e configurazione di Hadoop, è necessario verificare che siano presenti, su Ubuntu Server, alcuni packages necessari:
Oracle JDK 1.8
-
sudo apt-get purge openjdk*
-
sudo apt-get install software-properties-common
-
sudo add-apt-repository ppa:webupd8team/java
-
sudo apt-get update
-
sudo apt-get install oracle-java8-installer
La versione di Apache Hadoop che andremo ad installare risulta essere compatibile con Java 7/8. Gli stessi sviluppatori consigliano per Hadoop 2.7.1 la versione Java 8 Oracle.
Maven
-
Sudo apt-get -y install maven
Maven è un software opensource, sviluppato da Apache, che aiuta ad organizzare in modo efficiente programmi eseguibili Java.
Grazie a Maven è possibile avere una standardizzazione della struttura di un progetto compilazione, test ed esporti automatici, gestione e download automatico delle librerie necessarie al progetto e creazione automatica di un semplice sito di gestione del progetto.
Librerie Native
-
sudo apt-get -y install build-essential autoconf automake libtool
-
sudo apt-get -y install cmake zlib1g-dev pkg-config libssl-dev
ProtocoBuffer 2.5.0
-
sudo apt-get -y install libprotobuf-dev protobuf-compiler
Bzip2
-
sudo apt-get install bzip2 libbz2-dev
Jansson
-
sudo apt-get install libjansson-dev
Linux FUSE
-
sudo apt-get install fuse libfuse-dev
Ultimo package, corrisponde al Filesystem in userspace. Anch’esso risulta essere un progetto open source, il quale installa un modulo per architetture linux, che permette agli utenti non root di creare un proprio file system senza dover scrivere codice a livello kernel. Fuse risulta essere molto utile per creare e scrivere filesystem virtuali semplicemente collegandosi alla partizione desiderata.
Terminata l’installazione di questi package, possiamo iniziare il download di Hadoop 2.7.1 tramite repository ufficiali:
-
tar -zxf hadoop-2.7.1-src.tar.gz
-
cd hadoop-2.7.1-src
Terminata l’estrazione dell’archivio possiamo compilare tramite maven
-
mvn package -Pdist -DskipTests -Dtar
Altri due elementi come SSH e Rsync che saranno indispensabili per collegarsi al nodo:
-
sudo apt-get install ssh
-
sudo apt-get install rsync
Organizziamo il SO in modo da creare un gruppo di lavoro Hadoop e utente hduser:
-
sudo addgroup hadoop
-
sudo adduser --ingroup hadoop hduser
-
sudo adduser hduser sudo
-
sudo su hduser
Hadoop applica SSH, adoperando un canale criptato protetto per comunicare con gli altri nodi per gestire i demoni HDFS e MapReduce. Per verificare l’accesso tramite SSH è opportuno copiare la chiave RSA generata in modo da autenticare il nodo.
-
ssh-keygen -t rsa -P ""
-
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Al termine verifichiamo che è possibile accedere tramite SSH in questo modo:
-
ssh localhost
A questo punto deve essere recuperato il file generato dalla compilazione maven:
-
sudo cp hadoop-2.7.1-src/hadoop-dist/target/hadoop-2.7.1.tar.gz /home/hduser/
-
sudo tar -zxf hadoop-2.7.1.tar.gz
Spostiamo la cartella creata in /usr/local/hadoop
-
sudo mkdir /usr/local/hadoop
-
sudo mv /home/hduser/hadoop-2.7.1/* /usr/local/hadoop/
-
sudo chown hduser:hadoop -R /usr/local/hadoop
-
sudo mkdir -p /usr/local/hadoop_tmp/hdfs/namenode
-
sudo mkdir -p /usr/local/hadoop_tmp/hdfs/datanode
-
sudo chown hduser:hadoop -R /usr/local/hadoop_tmp/
Avendo fissato ed installato Hadoop nel sistema locale, adesso è possibile passare alla configurazione sul quale si sviluppa Hadoop.
I file che andremo a modificare per la configurazione in Pseudo-distribuited sono:
-
~/.bashrc
-
/usr/local/hadoop/etc/hadoop/hadoop-env.sh
-
/usr/local/hadoop/etc/hadoop/core-site.xml
-
/usr/local/hadoop/etc/hadoop/hdfs-site.xml
-
/usr/local/hadoop/etc/hadoop/yarn-site.xml
-
/usr/local/hadoop/etc/hadoop/mapred-site.xml
~/.Bashrc
All’intero di questo file sono presenti tutte le variabili ambientali del sistema operativo linux in esecuzione. È possibile, editando questo file, modificare la Shell Linux. Le nostre modifiche saranno utili per indicare al sistema operativo il corretto percorso di Apache Hadoop e della JVM di Java.
-
Su -l hduser
-
Sudo nano ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
Hadoop-Env.Sh
Questo file contiene alcune impostazioni sulle variabili di ambiente utilizzate da Hadoop. È possibile utilizzare questi per influire su alcuni aspetti del comportamento del demone Hadoop, come ad esempio i file di log in cui vengono archiviati, la quantità massima di memoria utilizzata, ecc
-
sudo nano /usr/local/hadoop/etc/hadoop/hadoop-env.sh
In questo file andiamo a specificare il path della JVM presente nel sistema
JAVA_HOME=/usr/lib/jvm/java-8-oracle
Core-Site.Xml
In questo file XML comunichiamo ad Hadoop dove il Namenode si trova nel cluster.
-
sudo nano /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Yarn-Site.Xml
-
sudo nano /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
Hdfs-Site.Xml
Contiene i settaggi di configurazione per il demone HDFS; il Namenode, eventuale Secondary NameNode e il DataNode. Qui possiamo configurare eventuali politiche di replica e permessi di scrittura e lettura del HDFS.
-
sudo nano /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop_tmp/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop_tmp/hdfs/datanode</value>
</property>
</configuration>
Mapred-Site.Xml
Questo file contiene le configurazioni per i demoni MapReduce insieme al Jobtracker e task-trackers.
-
sudo nano /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn </value>
</property>
Terminata la configurazione Pseudo Distribuita è possibile passare alla formattazione del nodo (namenode) andando a generare il filesystem:
-
hdfs namenode -format
Tramite questo comando, vengono cancellati tutti i dati precedenti nel filesystem HDFS e generato uno nuovo.
Avvio dei Demoni
Dopo aver eseguito tutti i passaggi analizzati fino ad ora, possiamo avviare Hadoop in questo modo:
-
start-dfs.sh
-
start-yarn.sh
Per poter verificare se i due demoni sono attivi basta digitare:
-
Jps
5424 DataNode
5621 SecondaryNameNode
5820 ResourceManager
6031 Jps
5295 NameNode
5951 NodeManager
Per stoppare i demoni sarà necessario digitare:
-
stop-dfs.sh
-
stop-yarn.sh
Portali di Management
Apache Hadoop possiede un’interfaccia grafica che è possibile raggiungere tramite Browser andando ad interrogare queste pagine web:
-
Name Node status: http://localhost:50070/dfshealth.jsp
-
Job Tracker status: http://localhost:50030/jobtracker.jsp
-
Task Tracker status: http://localhost:50060/tasktracker.jsp
-
Data Block Scanner Report: http://localhost:50075/blockScannerReport