
Proteggere dati reali con Microsoft Purview: introduzione a Exact Data Match (EDM)
La protezione dei dati sensibili è ormai un elemento imprescindibile nelle strategie di sicurezza delle organizzazioni. Microsoft Purview offre un insieme estremamente ampio di funzionalità per identificare, classificare e proteggere informazioni di diversa natura, consentendo di affrontare scenari semplici e complessi con un approccio unificato.
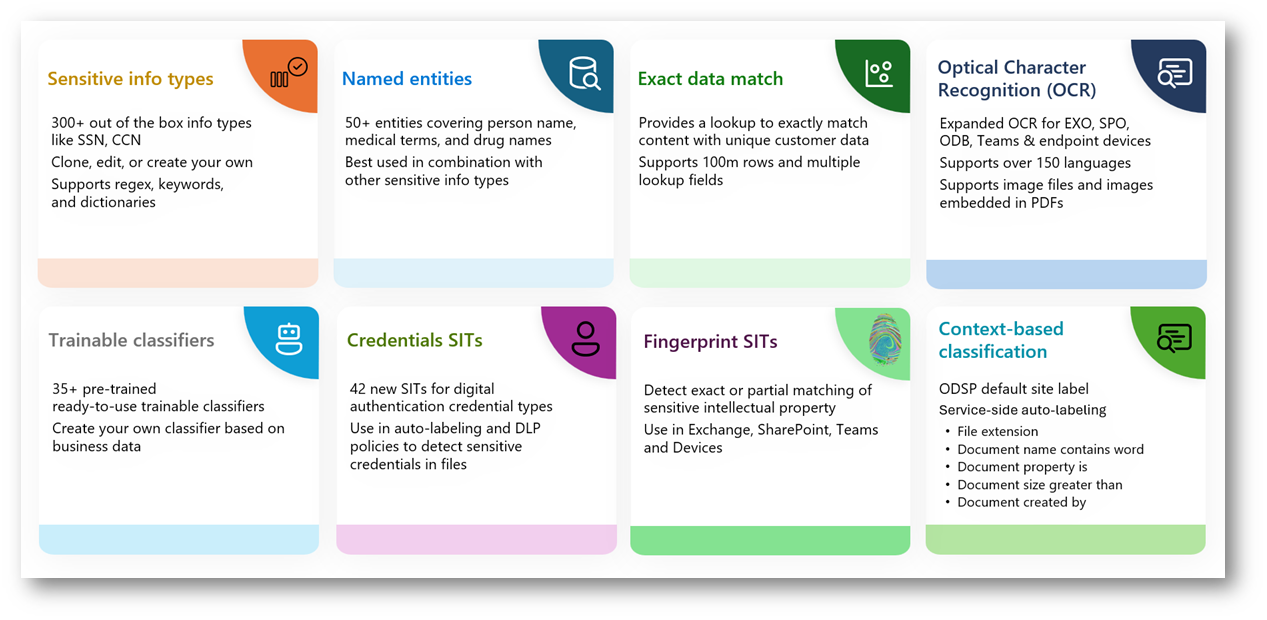
Figura 1 – Classificatori disponibili in Microsoft Purview
Esistono situazioni in cui non è sufficiente definire un pattern o una regola: l’organizzazione potrebbe avere la necessità di proteggere esattamente un insieme di valori provenienti da database aziendali ufficiali. È proprio in questo scenario che entra in gioco Exact Data Match (EDM).
Mentre le categorie standard e personalizzate si basano su pattern, parole chiave e regole, EDM utilizza un approccio diverso: consente di caricare un dataset strutturato e trasformarlo in un modello di corrispondenza sicura. Questo modello è in grado di identificare esattamente i valori desiderati all’interno dei contenuti aziendali.
Questo metodo riduce notevolmente i falsi positivi e consente alle organizzazioni di proteggere informazioni che non seguono schemi fissi, ma che possono essere identificate solo attraverso un confronto diretto con un archivio ufficiale.
Ad esempio, è particolarmente utile in situazioni come:
- ID cliente o numeri di contratto;
- Identificativi interni non standard;
- Liste di dipendenti, fornitori o partner.
Vi ricordate il DocumentID introdotto nell’articolo precedente, quando abbiamo creato una Sensitive Information Type custom? Bene, lo ritroviamo anche qui.
Proprio quel campo diventa ora il perno del nostro esempio pratico con EDM dove non ci limitiamo a riconoscere pattern, ma vogliamo identificare valori esatti provenienti da una fonte strutturata.
Per questa demo ho costruito un dataset composto da 40 righe, basato su articoli reali disponibili su ICT Power. Ogni elemento contiene titolo, autore, data di pubblicazione e un insieme di parole chiave. Il DocumentID viene assegnato come identificatore univoco per simulare un codice ufficiale presente nei sistemi aziendali.
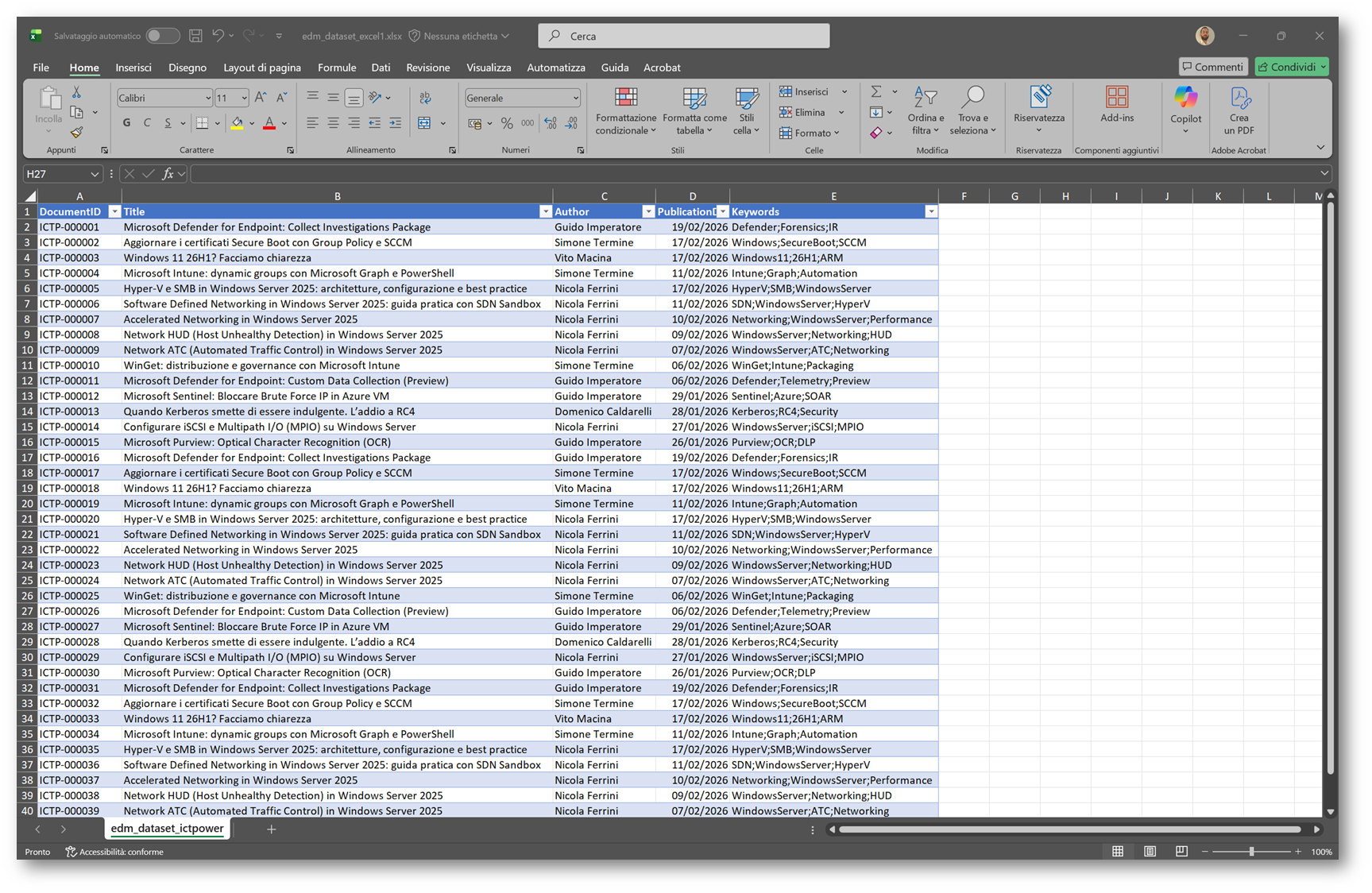
Figura 2 – Dataset EDM articoli ICT Power
Creazione EDM classifiers
Ora vedremo come questo dataset viene trasformato in un modello EDM caricato nel portale Microsoft Purview e utilizzato concretamente in una policy di protezione dei dati.
Nella console di Microsoft Purview, andate su Solutions, quindi scegliete Information Protection o Data Loss Prevention, selezionate Classifiers e, nella sezione EDM classifiers, cliccate su Create EDM classifier.
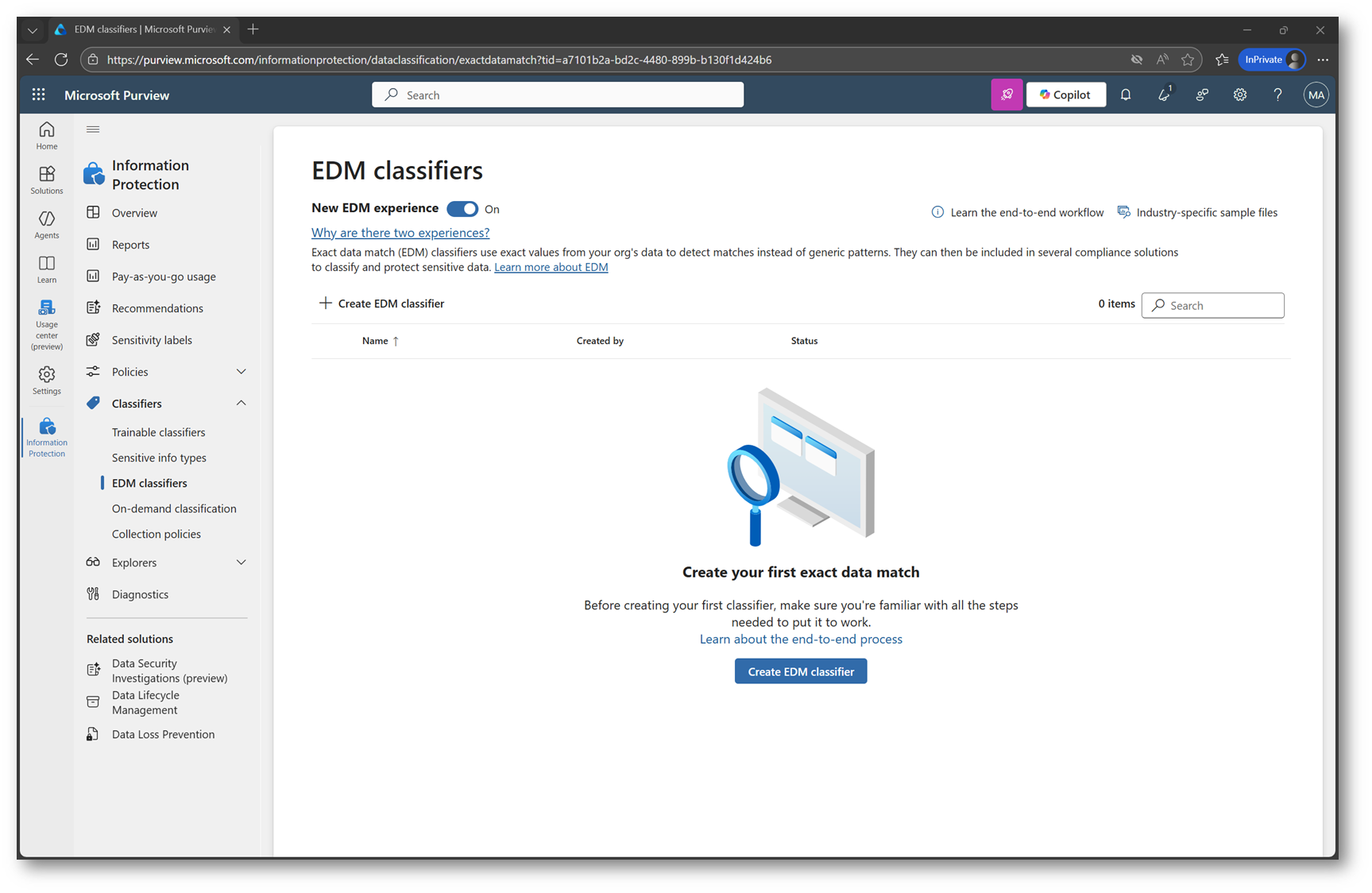
Figura 3 – Creazione EDM classifier
Scegliete un nome e una descrizione appropriati per l’EDM Classifier. È consigliabile usare una denominazione semplice e descrittiva per rendere più agevole sia il riconoscimento che l’utilizzo.
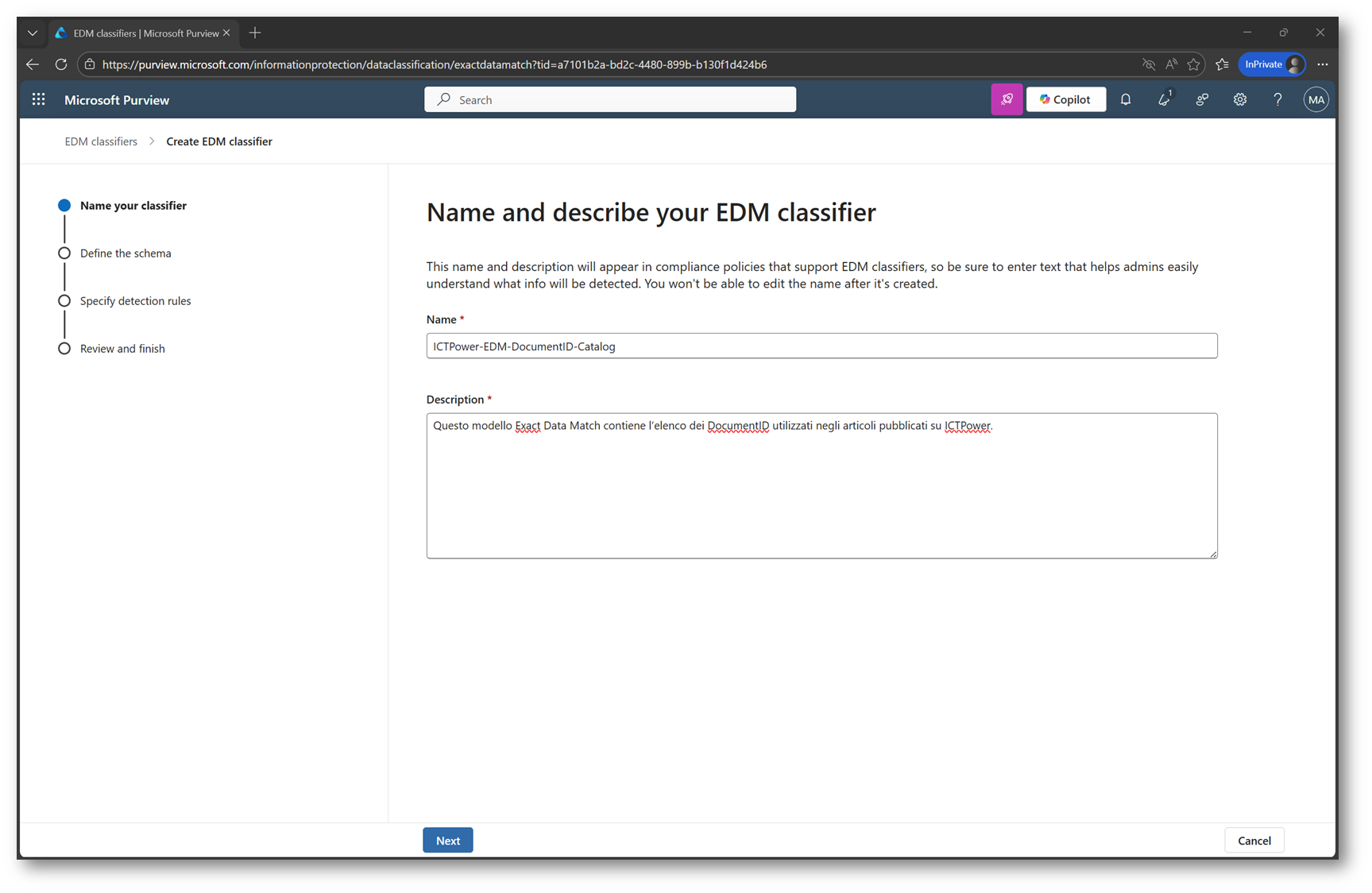
Figura 4 – Inserimento nome e descrizione del nuovo EDM classifier
Nel passo successivo del wizard, Microsoft Purview ci mette di fronte a due modalità: definire manualmente i campi del modello oppure caricare un file di esempio che rappresenti la struttura dei dati che intendiamo utilizzare.
Poiché il dataset a disposizione è già organizzato in formato tabella, ho scelto di procedere caricando direttamente un file CSV di sample, ottenuto dal file Excel contenente le informazioni degli articoli pubblicati su ICT Power.
Questa modalità è particolarmente efficace quando i dati sorgente sono già completi e coerenti, perché il wizard è in grado di riconoscere automaticamente le colonne e facilitare la selezione dei campi da includere nel modello EDM.
Figura 5 – Scelta della modalità di configurazione schema EDM
Nel passaggio successivo, il wizard ci chiede di caricare il file CSV che utilizzeremo come sample dataset per definire la struttura dell’EDM classifier. Nel mio caso ho scelto di esportare il file Excel degli articoli ICT Power in formato CSV utilizzando la virgola come delimitatore, in modo da garantire la compatibilità con il portale Purview.
È importante prestare particolare attenzione alla corretta gestione dei caratteri speciali, perché elementi come virgolette, apostrofi tipografici, accenti “strani” o virgole presenti all’interno dei campi di testo possono causare errori di parsing o una lettura non corretta delle colonne.
Quindi, una volta verificata la pulizia del file, è possibile procedere con il caricamento e lasciare che Purview riconosca automaticamente i campi del dataset, facilitando la creazione dello schema EDM.
Figura 6 – Caricamento sample file EDM
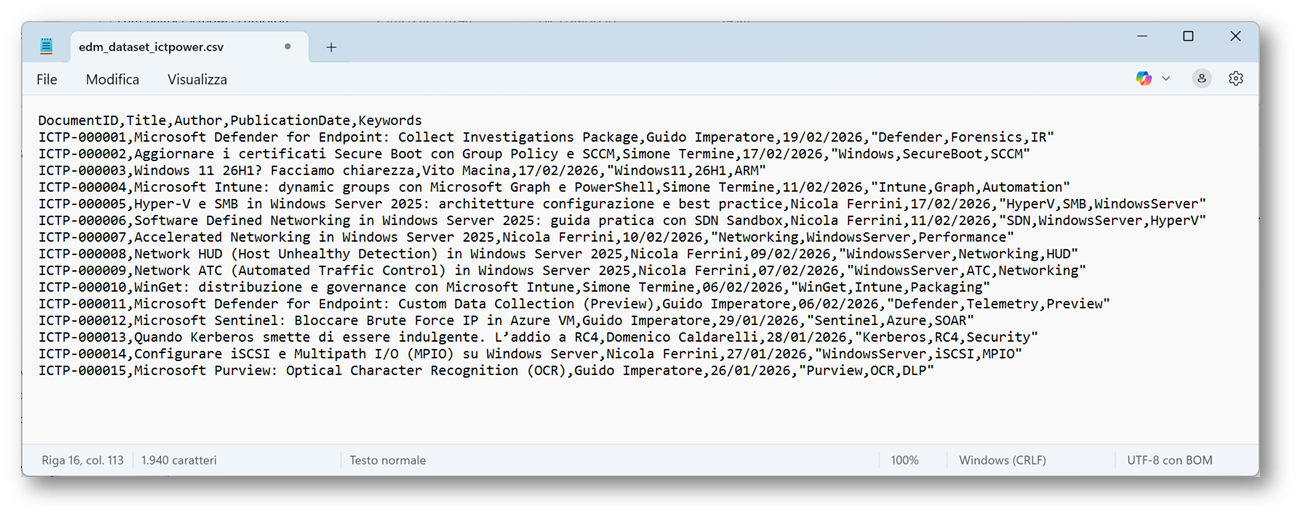
Figura 7 – Sample data EDM
In questa fase del wizard, Purview ci mostra l’anteprima delle colonne rilevate all’interno del CSV, permettendoci di verificare che la struttura del file sia stata interpretata correttamente. Questo passaggio è fondamentale perché rappresenta il momento in cui possiamo assicurarci che il dataset sia coerente con lo schema che si vuole utilizzare per il modello EDM.
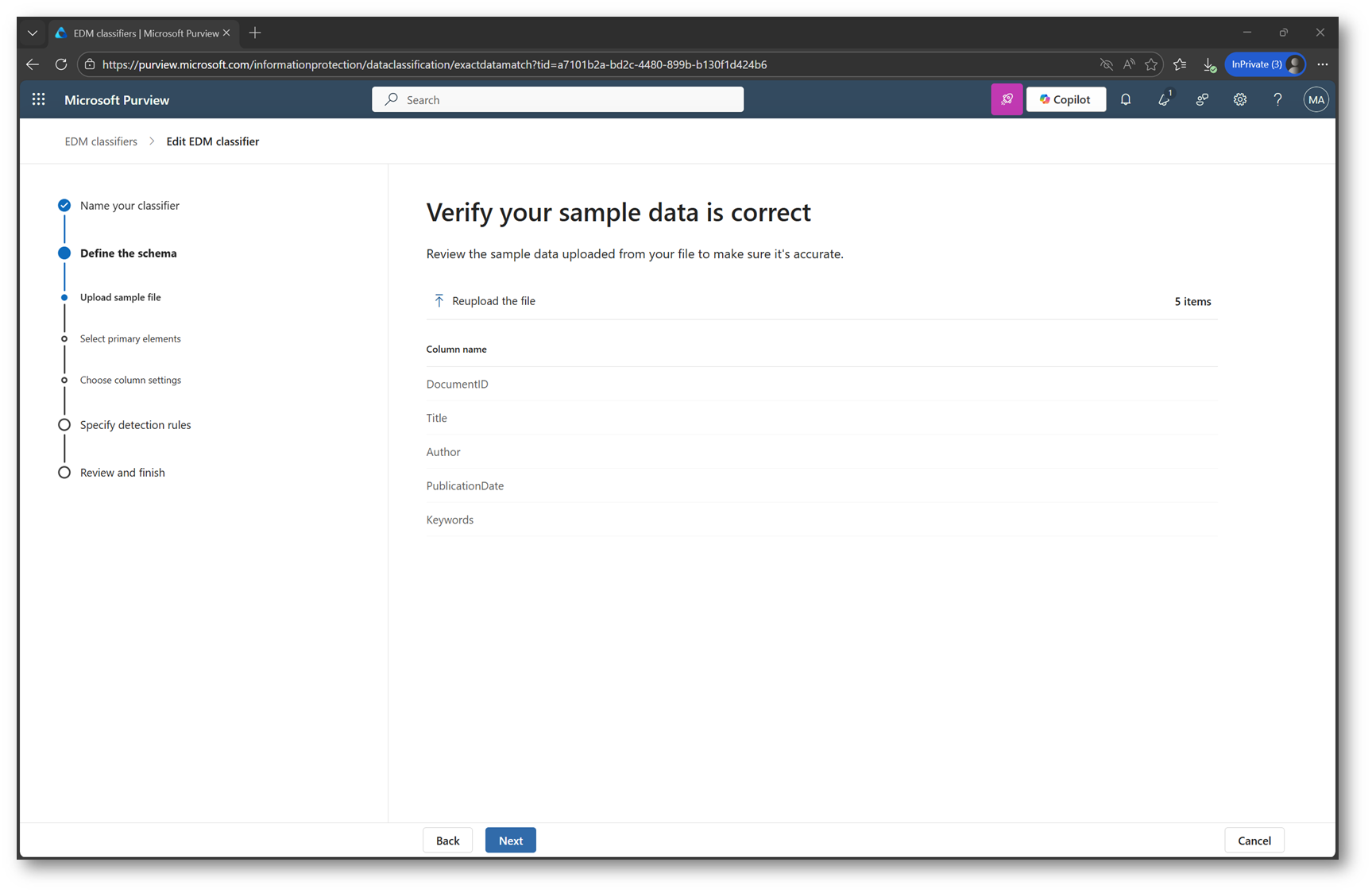
Figura 8 – Verifica sample data EDM
Nella schermata successiva, viene richiesto di definire quale colonna del dataset debba essere utilizzata come Primary element, ovvero il campo sul quale verrà effettuato il match esatto tramite il modello EDM. Nel mio caso la colonna centrale è DocumentID, che rappresenta l’identificativo univoco utilizzato per distinguere ogni elemento del dataset.
Una caratteristica molto comoda della nuova esperienza di EDM è la capacità del sistema di riconoscere automaticamente eventuali Sensitive Information Types già presenti nel tenant. Quando Purview analizza l’anteprima del file, infatti, tenta di associare le colonne del dataset a SIT già esistenti in modo da semplificare notevolmente la configurazione.
Proprio per questo, durante la selezione del Primary element, Purview ha riconosciuto automaticamente la Sensitive Information Type custom associata alla colonna
DocumentID.
In questa fase è inoltre possibile scegliere la modalità di match tra:
- Singletoken match: adatta ai valori compatti e univoci come, ad esempio, il DocumentID.
- Multitoken match: utile quando i dati da confrontare sono composti da più elementi (es. nomi, indirizzi, stringhe strutturate)
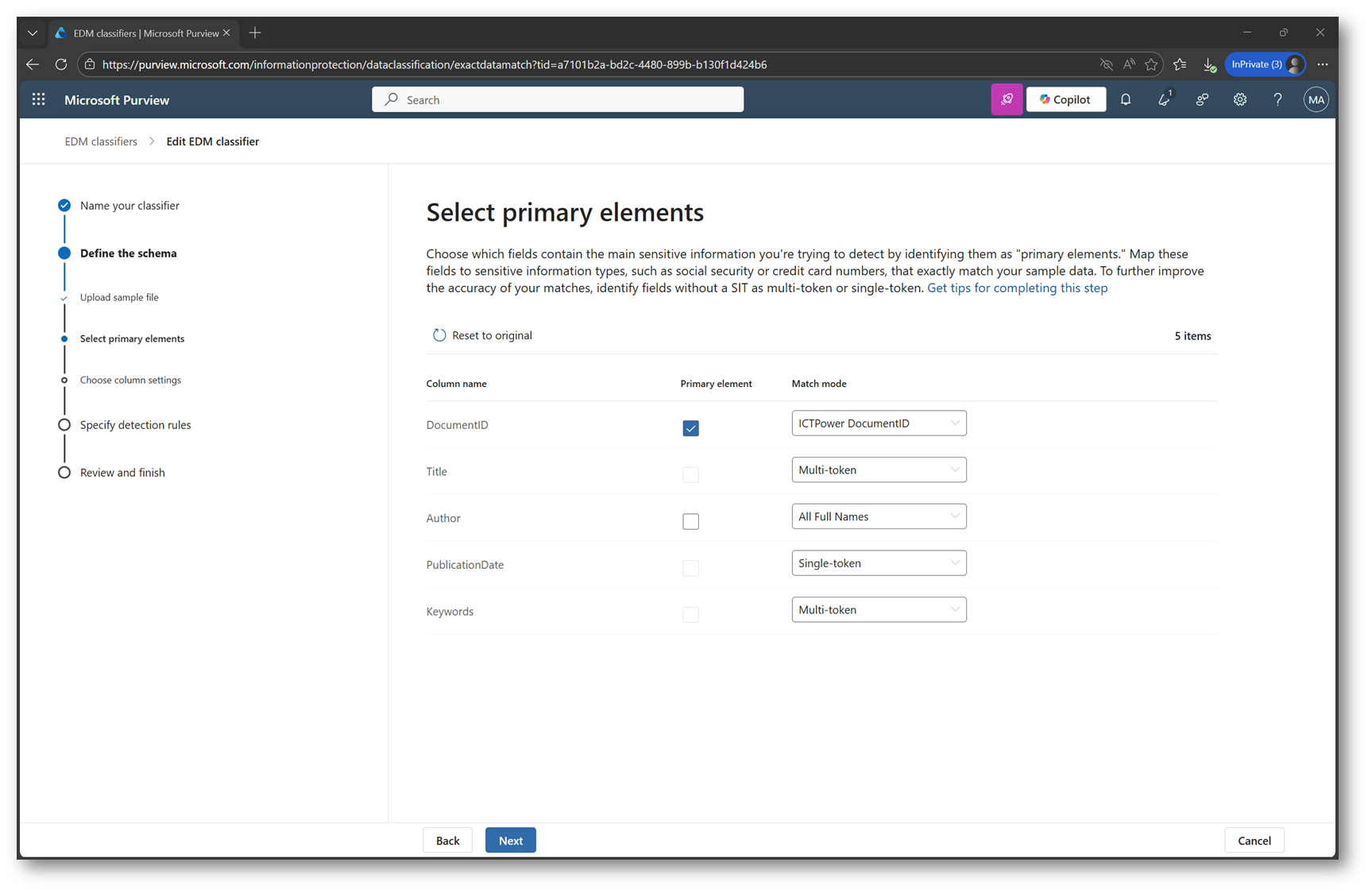
Figura 9 – Selezione primary element e match-mode dei campi del dataset
Ora il wizard ci permette di definire i parametri avanzati relativi al contenuto delle colonne del dataset. Si tratta di impostazioni fondamentali per garantire che il modello EDM interpreti correttamente i dati durante la fase di hashing e durante il confronto con i contenuti reali del tenant.
Per ciascuna colonna identificata nel CSV, Purview consente infatti di specificare:
- se i valori devono essere trattati come case-sensitive o case-insensitive,
- se vanno ignorati delimitatori o caratteri di punteggiatura,
- eventuali normalizzazioni che possono influire sul risultato del match.
Queste opzioni diventano particolarmente importanti quando si lavora con colonne testuali che potrebbero contenere variazioni non significative (come differenze di maiuscole/minuscole, simboli, separatori o caratteri non uniformi).
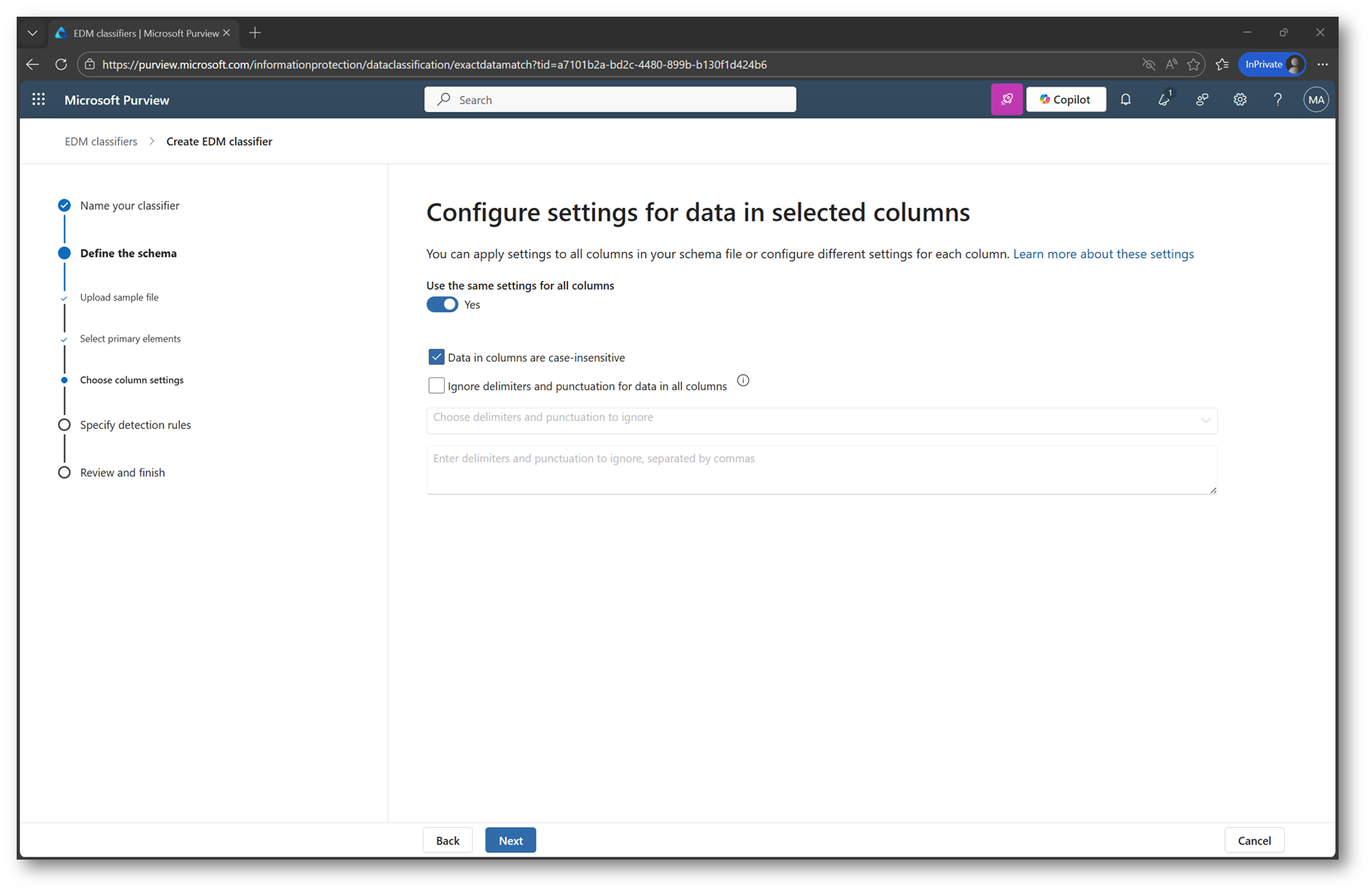
Figura 10 – Configurazione dei parametri avanzati relativi al contenuto delle colonne del dataset
In questa schermata Purview ci permette di definire come il modello EDM debba valutare il Primary element (nel nostro caso DocumentID) e come debbano essere conteggiati i match.
Le opzioni principali sono:
- Narrow mode: match basato solo sul Primary element.
- Wide mode: match basato su Primary element + evidence della stessa riga.
- Primary match‑level counting: conta i match del Primary element, indipendentemente dalla riga.
- Row‑level counting: considera la riga EDM come unità del match (Primary + evidence insieme).
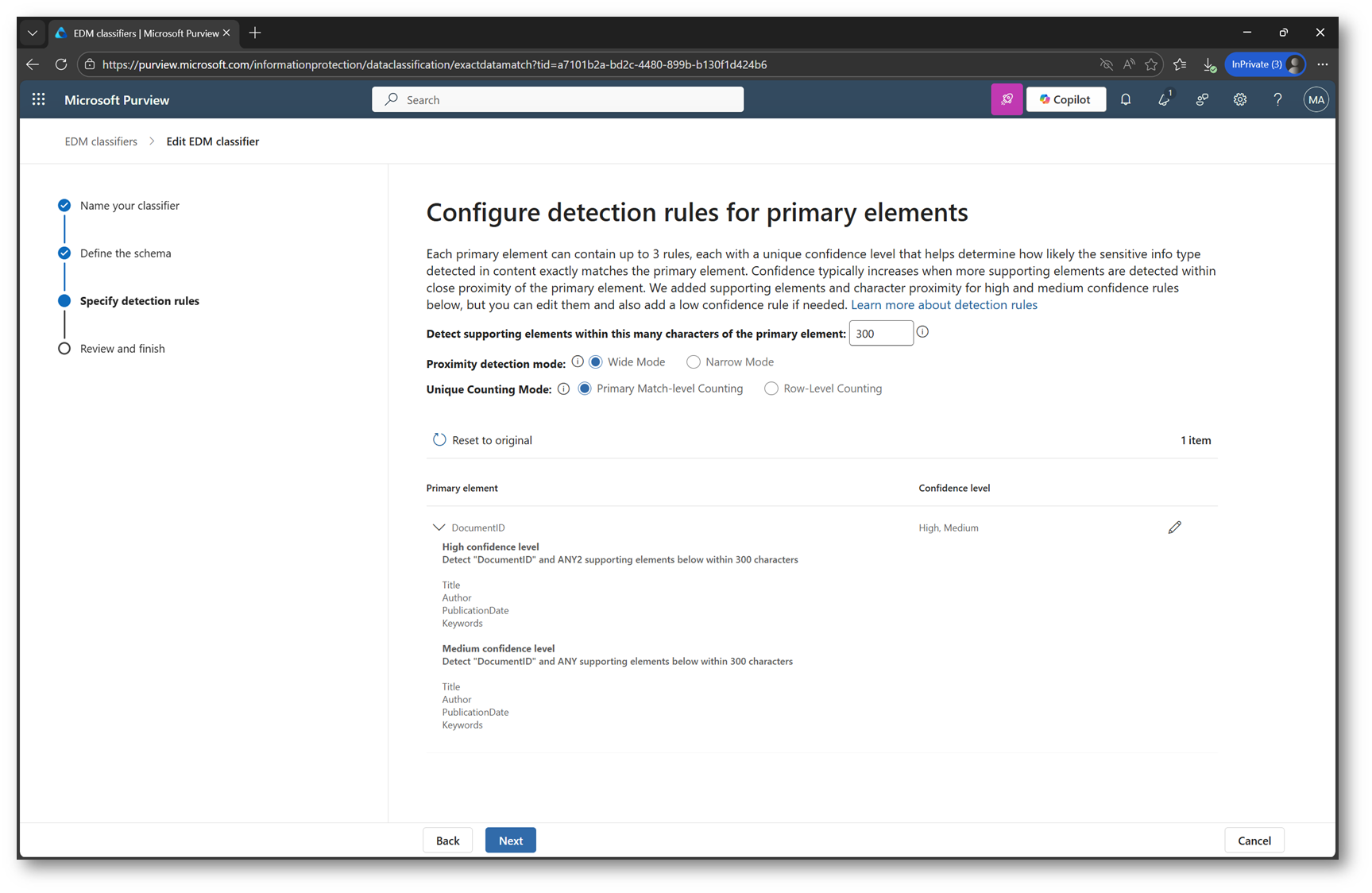
Figura 11 – Configurazione detection rule del primary element in EDM
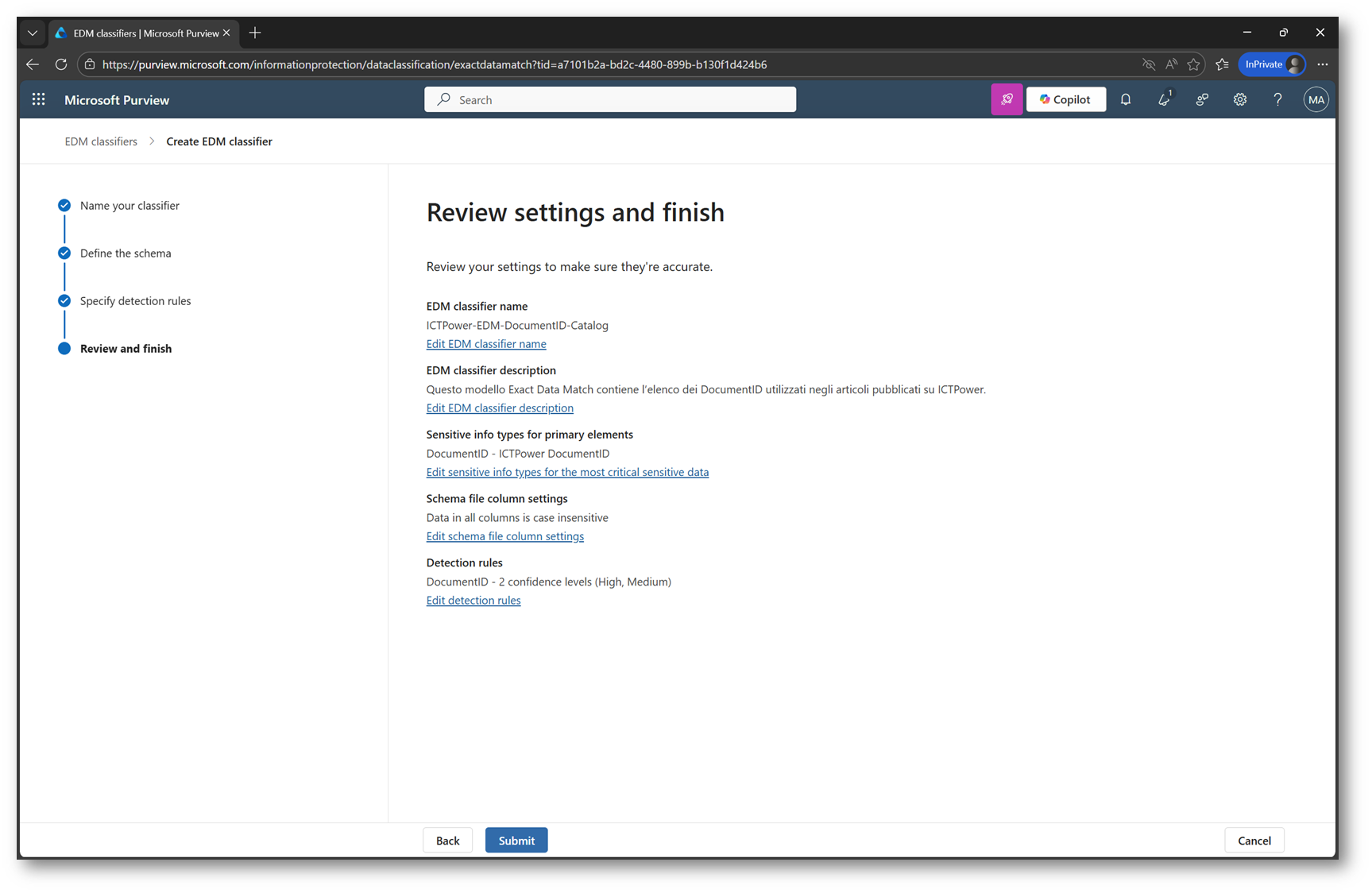
Figura 12 – Ovierview dell’EDM classifier
Nell’ultimo passaggio del wizard, Purview ci mostra il riepilogo del modello EDM appena configurato. Prima di procedere è importante copiare il valore (è possibile recuperarlo anche in un secondo momento)
dello Schema name: questo identificativo sarà infatti necessario nella fase successiva, quando andremo a caricare il source file durante l’upload del dataset EDM.
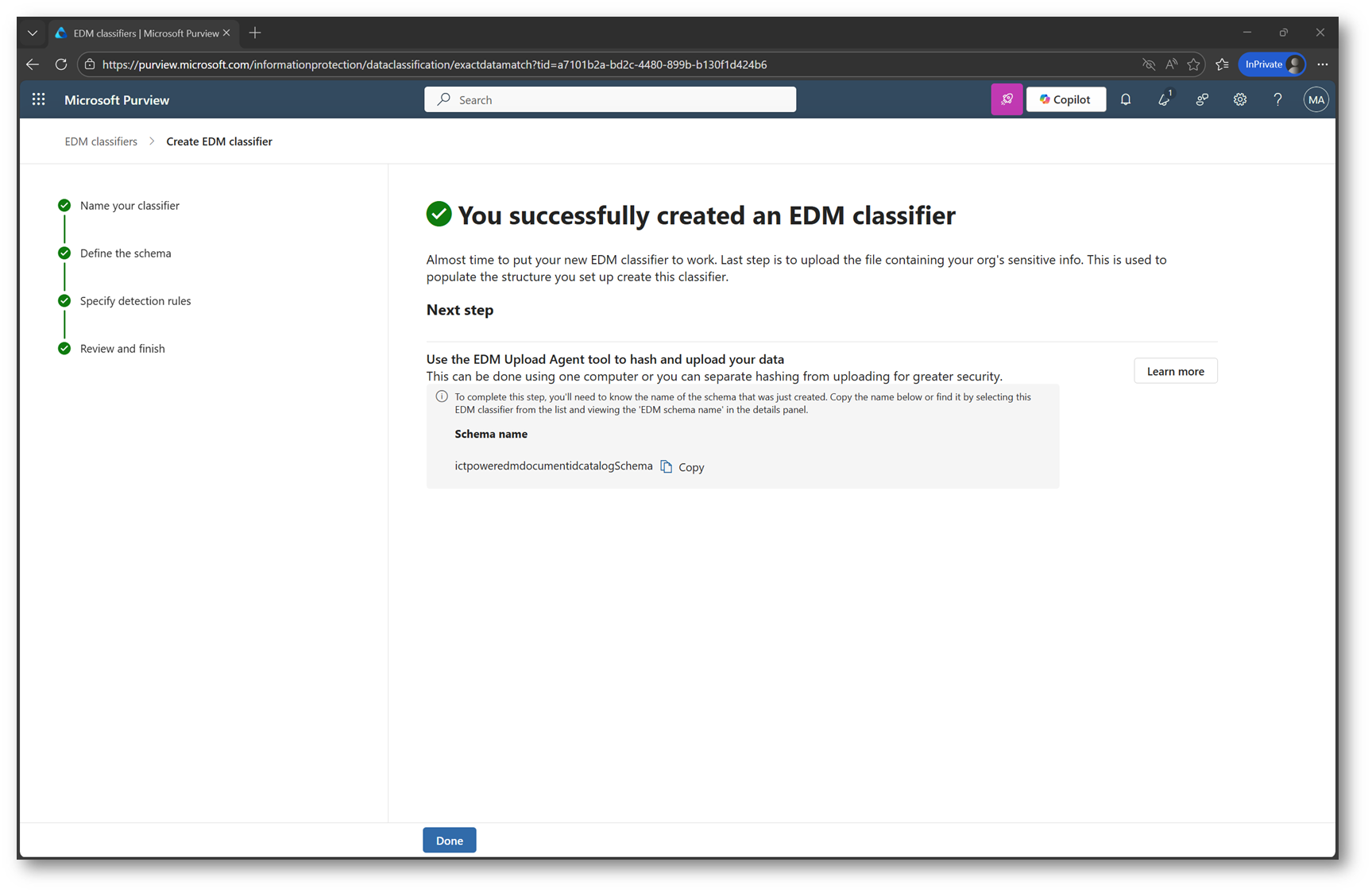
Figura 13 – Fine wizard creazione classifier EDM
Una volta completata la creazione dell’EDM classifier, Purview ci mostra la schermata riepilogativa del modello. In questa fase lo stato riporta “Source file not uploaded yet”, indicando che il classifier è stato definito correttamente ma non dispone ancora del dataset necessario per poter essere indicizzato ed utilizzato nelle policy DLP o di autolabeling.
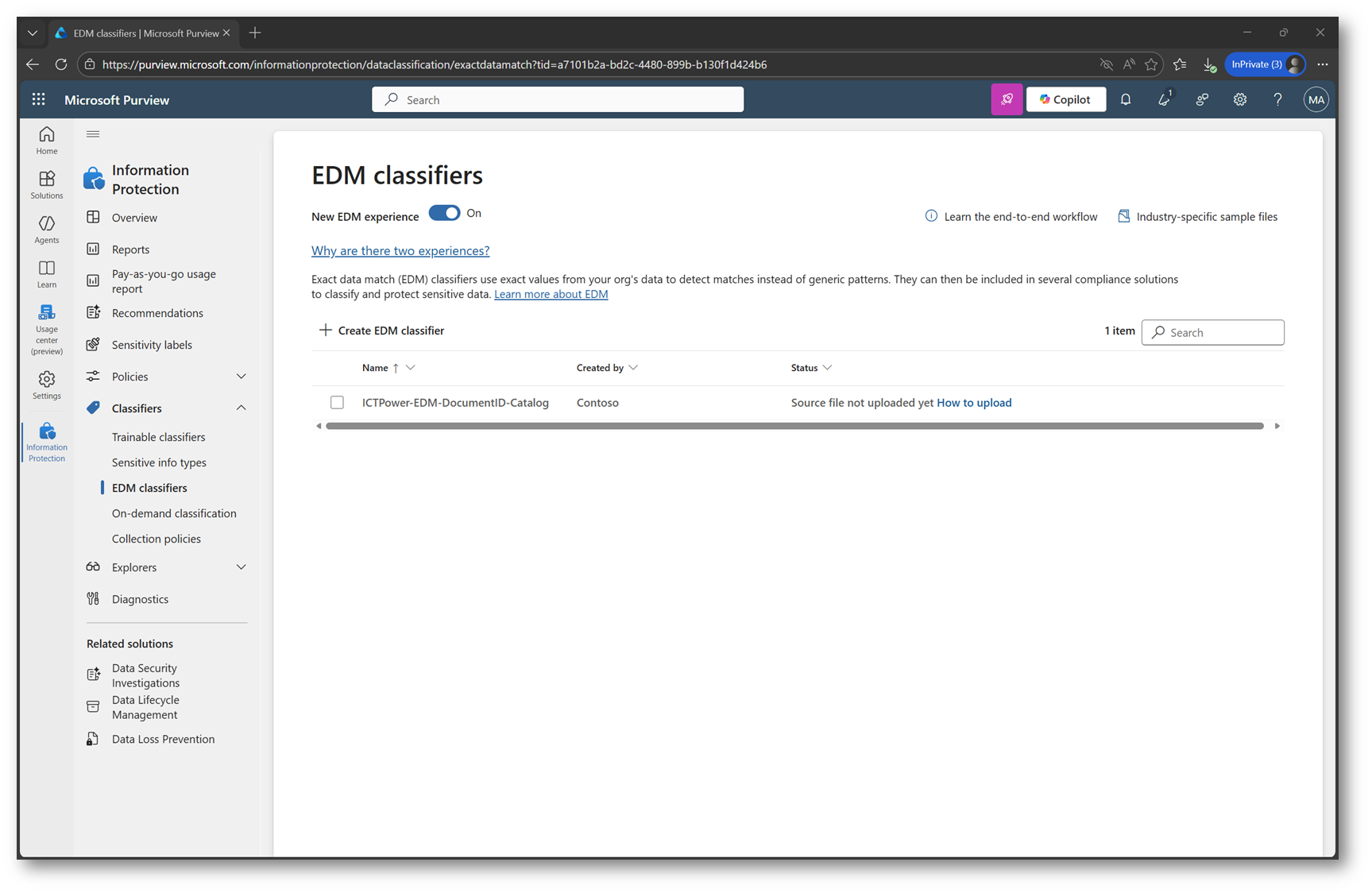
Figura 14 – Stato dell’EDM classifier: “Source file not uploaded yet”
Questo comportamento è del tutto normale: la creazione del classifier rappresenta solo la prima metà del processo. Per rendere il modello effettivamente operativo è necessario procedere con l’upload del source file, ovvero la versione “hashata” del nostro CSV (generata tramite lo strumento fornito dal wizard).
Caricamento del source file
Prima di poter caricare il source file, Purview richiede di smarcare un prerequisito fondamentale: l’account che esegue l’upload del file deve appartenere al gruppo EDM_DataUploaders in Microsoft Entra ID.
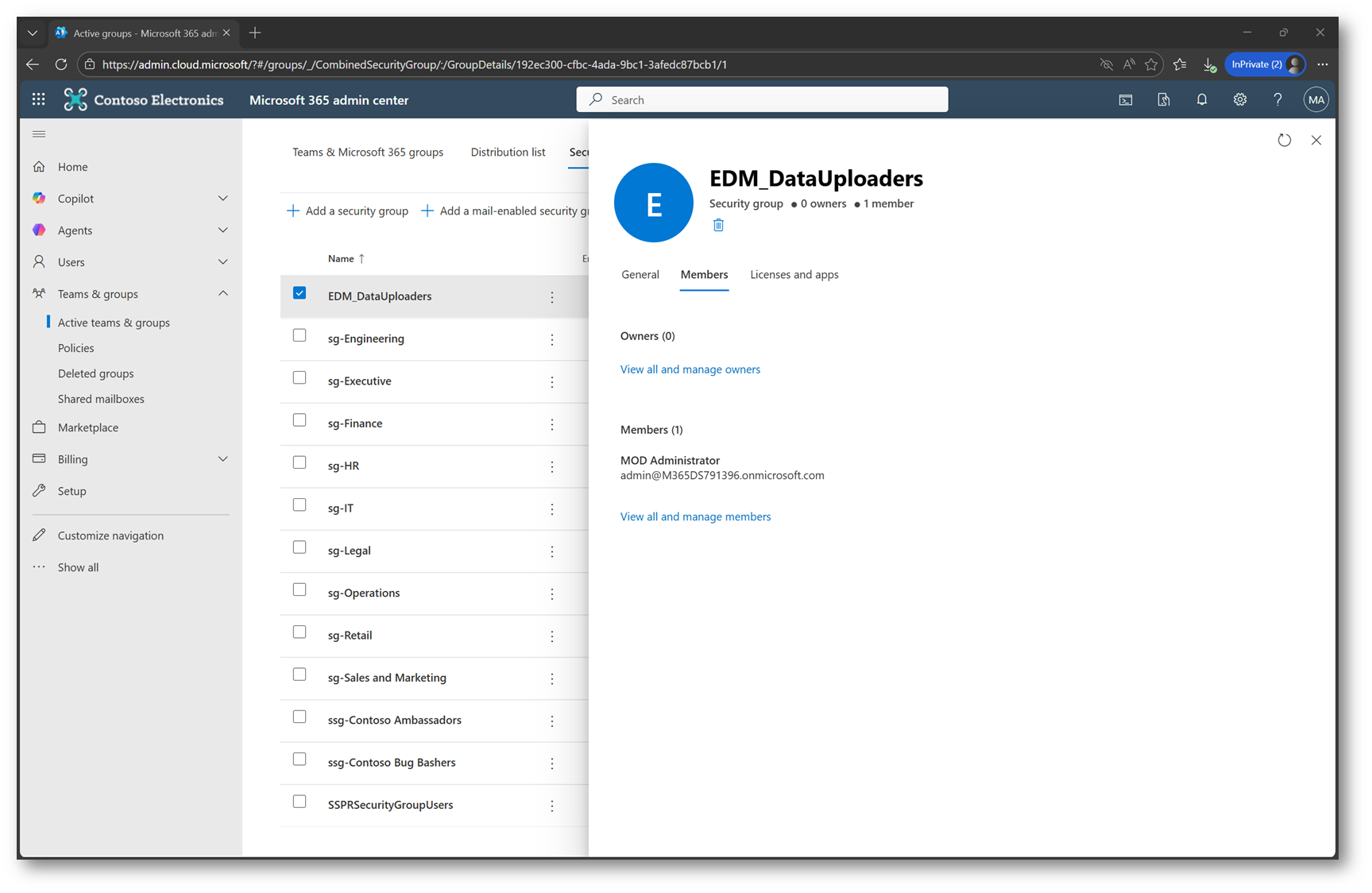
Figura 15 – Aggiunta al gruppo EDM_DataUploaders in Entra ID
Ora possiamo procedere con il download del Microsoft Exact Data Match Upload Agent dal sito ufficiale Hash and upload the sensitive information source table for exact data match sensitive information types | Microsoft Learn e seguire il wizard di installazione.
Come cartella di destinazione, vi consiglio di specificare “C:\EDM\Data\“.
Figura 16 – Wizard Microsoft Exact Data Match Upload Agent
Figura 17 – Wizard Microsoft Exact Data Match Upload Agent
Figura 18 – Wizard Microsoft Exact Data Match Upload Agent
Il primo requisito consiste nell’avviare l’agent (tramite prompt dei comandi con diritti di admin e con il comando “EdmUploadAgent.exe /authorize) e autenticarsi con l’account aggiunto al gruppo
EDM_DataUploaders.
Questo passaggio consente di autorizzare l’agent a operare all’interno del tenant e a caricare dataset EDM.
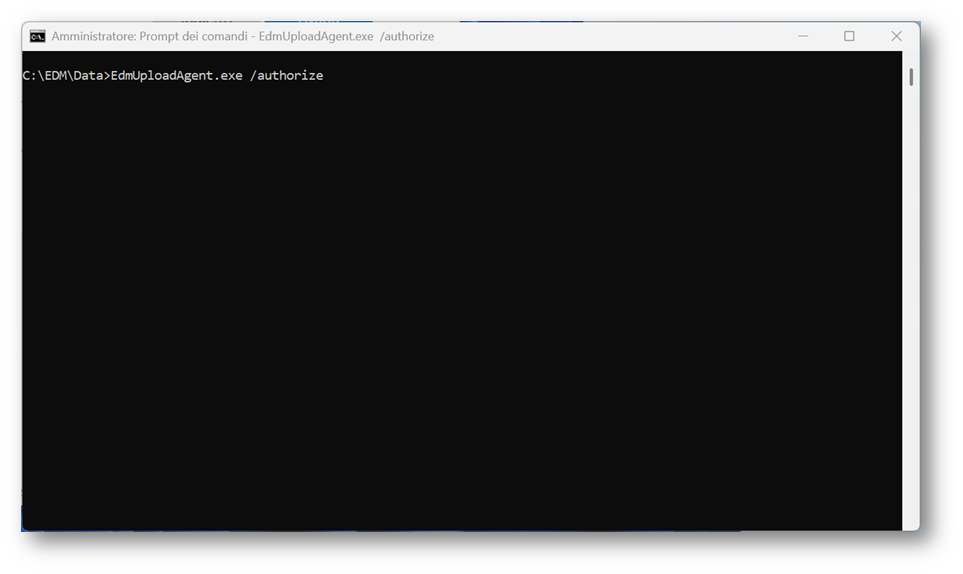
Figura 19 – Autorizzazione dell’EDM Upload Agent sul dispositivo Windows
Figura 20 – Accesso nell’agent tramite prompt
Una volta autorizzato l’agent, bisogna procedere a salvare in locale lo schema XML associato al modello EDM.
Per farlo, è necessario utilizzare lo schema name copiato in precedenza durante la creazione dell’EDM classifier nel wizard e lanciare il comando EdmUploadAgent.exe /SaveSchema /DataStoreName [nome dello schema].
Verrà generato un file, nella cartella di installazione, con il nome schema ed estensione xml (nel mio caso ictpoweredmdocumentidcatalogschema.xml) che serve a collegare il dataset al relativo data store, garantendo che l’upload venga associato al classifier corretto.
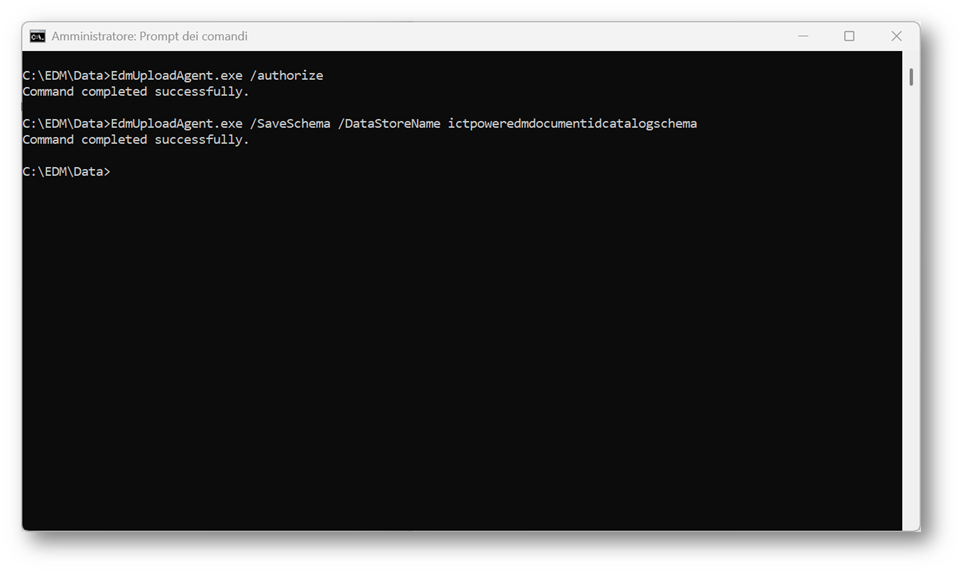
Figura 21 – Salvataggio dello Schema file in locale
Per semplificare le operazioni di validazione e upload, ho copiato il file edm_dataset_ictpower.csv direttamente nella cartella di installazione del Microsoft EDM Upload Agent. Questa scelta non è obbligatoria, mq evita di dover specificare percorsi lunghi o complessi nei comandi e riduce il rischio di errori dovuti a path non correttamente risolti durante l’esecuzione dell’agent.
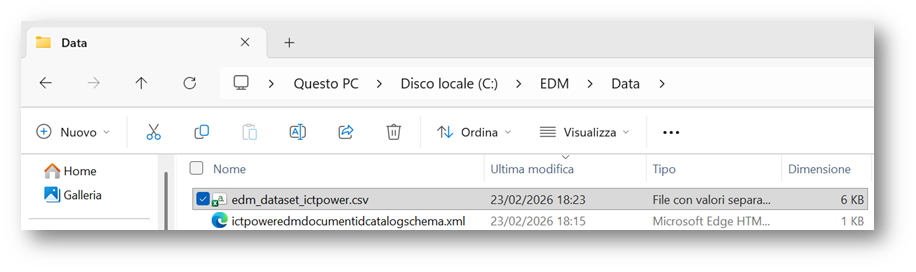
Figura 22 – Dataset e schema nella cartella di installazione dell’agent
In questo modo i comandi possono essere lanciati utilizzando percorsi più semplici e immediati, mantenendo nella stessa directory anche lo schema XML e la cartella destinata agli hash.
Ciò rende l’intero flusso di lavoro EDM più lineare, soprattutto quando si effettua il caricamento per la prima volta o quando si devono ripetere più iterazioni del dataset.
Prima dell’upload, è fondamentale verificare che il file CSV sia strutturato correttamente.
Il comando /ValidateData analizza:
- la struttura delle colonne;
- la formattazione dei valori;
- la presenza di righe corrotte;
- eventuali campi fuori formato.
Questo passaggio intercetta errori nel dataset prima dell’hashing e garantisce che il file sia idoneo all’upload.
Comando: EdmUploadAgent.exe /ValidateData /DataFile [data file] /Schema [schema file]
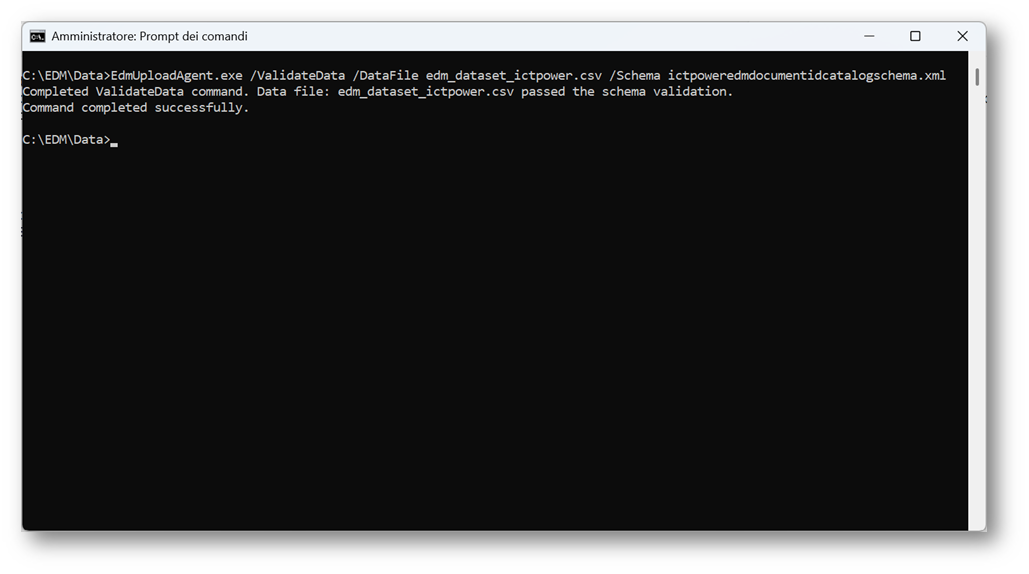
Figura 23 – Validazione del dataset
Una volta autorizzato l’agent, salvato lo schema e validata la base dati ora è possibile caricare il dataset hashato nel data store EDM.
Comando: EdmUploadAgent.exe /UploadData /DataStoreName [DS Name] /DataFile [data file] /HashLocation [hash file location] /Schema [Schema file] /AllowedBadLinesPercentage [value]
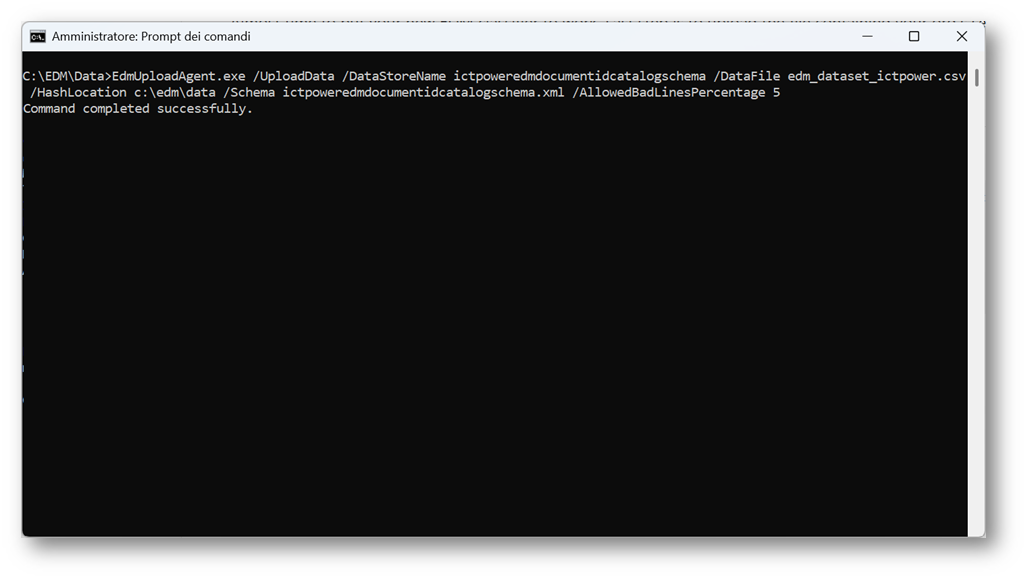
Figura 24 – Caricamento del dataset
A questo punto, tornando nella sezione EDM classifier del portale Purview, lo stato del modello risulta aggiornato a “Index complete”, indicando che il dataset è stato elaborato correttamente e che tutti i valori presenti nel file sono stati indicizzati con successo.
Questo conferma che il data store EDM è pronto all’uso e che la Sensitive Information Type generata dal modello può essere impiegata nelle policy di protezione dei dati.
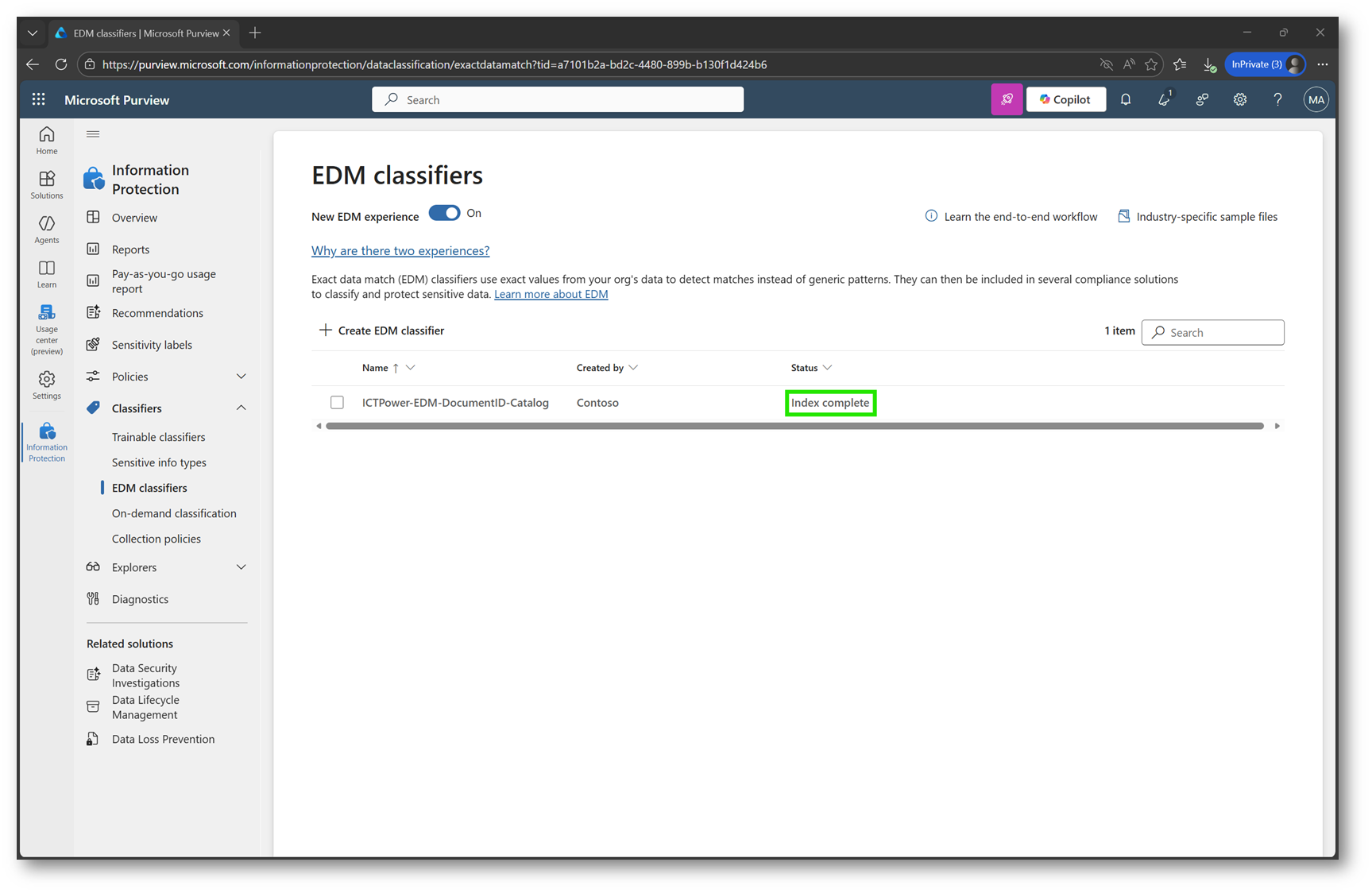
Figura 25 – Indicizzazione completata
Con l’indicizzazione completata, si può procedere alla fase successiva: il test dell’EDM classifier.
Questo passaggio permette di verificare concretamente il corretto funzionamento del modello all’interno del tenant.
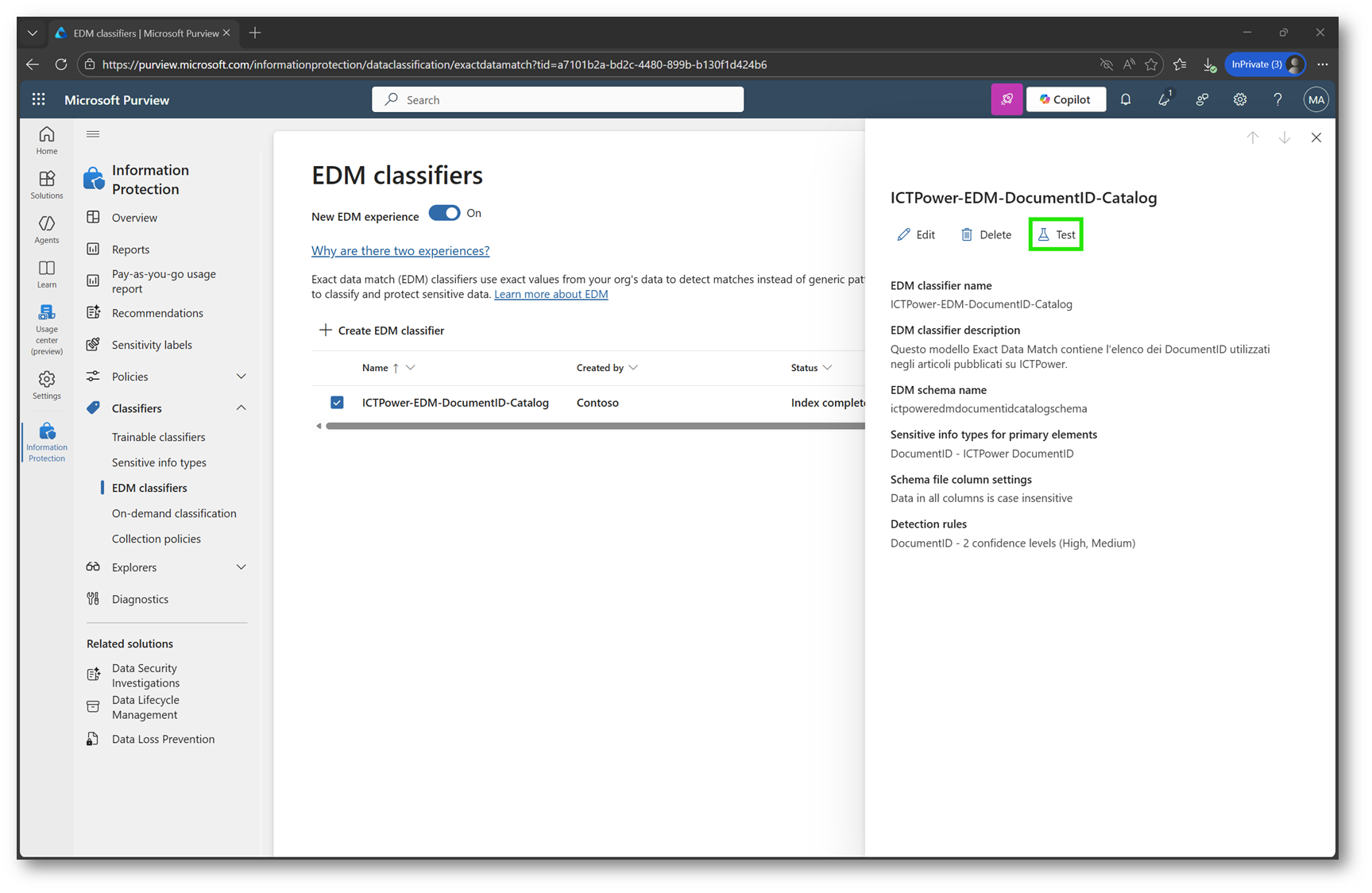
Figura 26 – Test EDM classifier
Nel mio caso ho utilizzato un file .docx di esempio contenente sia valori presenti nel dataset (che devono produrre un match), sia varianti non valide (che non devono essere rilevate).
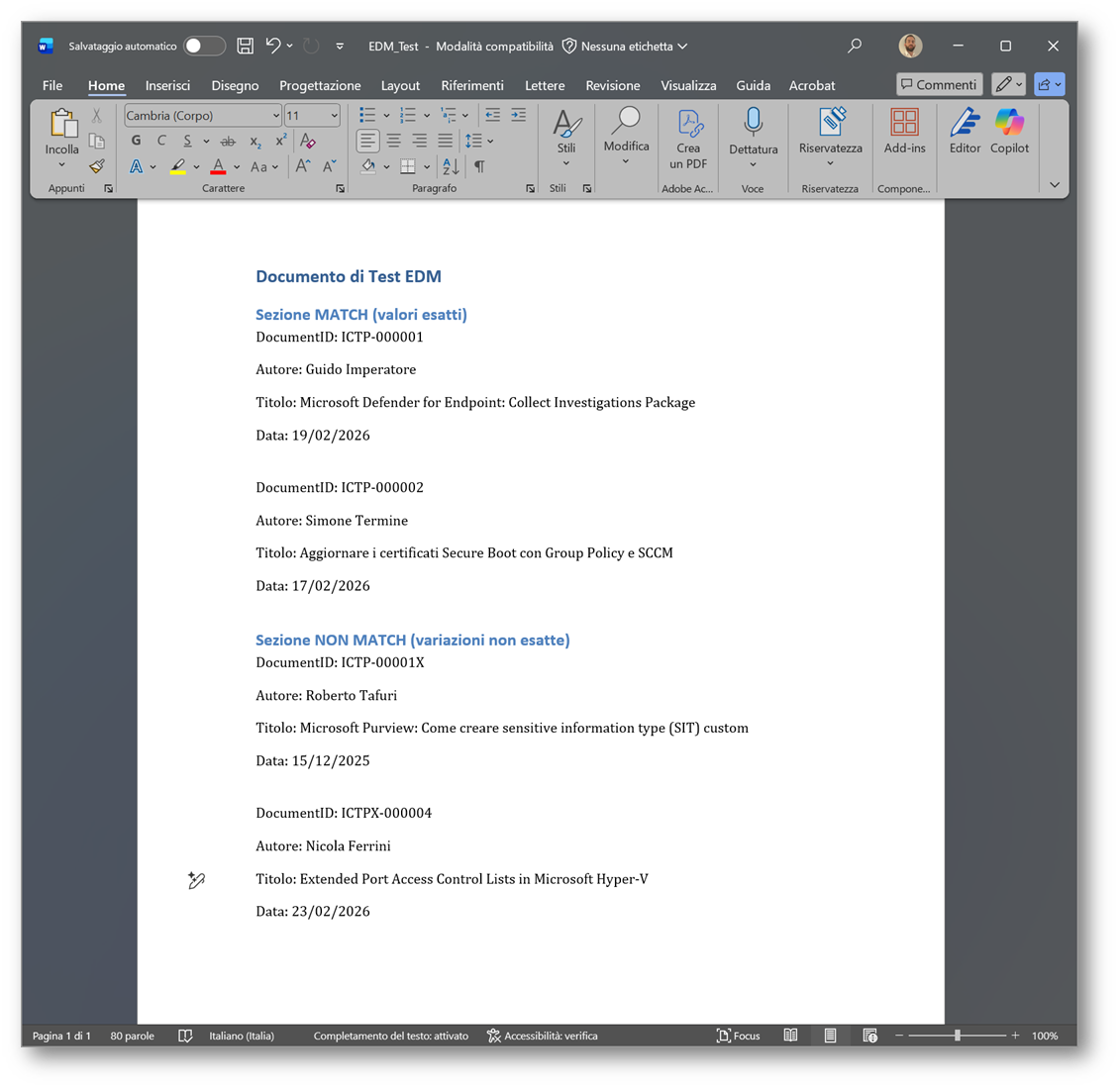
Figura 27 – Documento per testare EDM classifier
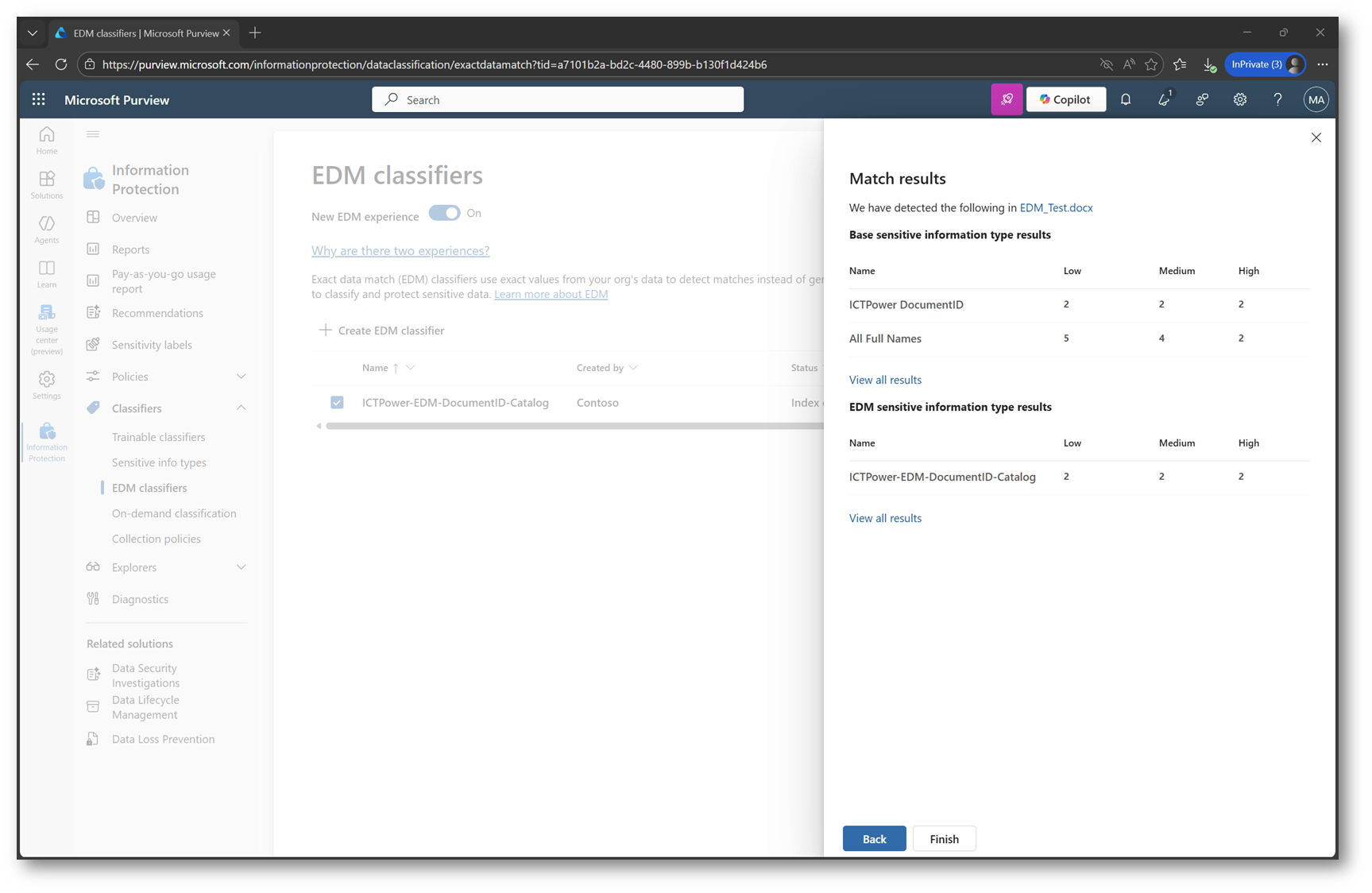
Figura 28 – Risultato test EDM classifier
A questo punto il classifier è pienamente operativo: la relativa SIT-EDM generata dal modello è ora pronta per essere utilizzata nelle policy DLP, nelle regole di autoetichettatura e in tutti gli altri componenti di Microsoft Purview che supportano l’Exact Data Match.
Conclusione
Con la nuova esperienza di configurazione di Exact Data Match, Microsoft Purview rende l’intero processo molto più lineare e intuitivo. Dalla definizione dello schema, alla validazione del dataset, fino all’indicizzazione finale, ogni passaggio consente di costruire un modello solido e pronto per essere utilizzato in scenari reali di prevenzione della perdita dei dati.
Per chi desidera approfondire ulteriormente il funzionamento di Exact Data Match e tutte le impostazioni disponibili nella nuova esperienza, è possibile consultare la documentazione ufficiale Microsoft Create exact data match sensitive information type in the New Experience workflow | Microsoft Learn