
TPC-HS, il miglior benchmarking per Big Data applicato ad Hadoop
Una delle più grandi sfide per tutti coloro che si accingono a metter su un’infrastruttura in grado di gestire BIG DATA, è ottenere le migliori prestazioni possibili andando a variare N fattori e cercando di ottenere risultati soddisfacenti in un tempo relativamente breve.
Essendo Apache Hadoop un framework installabile sia su piattaforme Linux che Windows, è giusto porsi alcune domande.
- Qual è il miglior OS da applicare al framework, citato in precedenza, in termini di prestazioni?
- La mia infrastruttura come deve essere configurata per avere buoni tempi di calcolo?
- Come posso valutare la mia architettura generale?
Gli attori di questo studio sono stati il TPC-HS, Apache Hadoop e VSphere come ambiente per testare gli OS.
Obiettivo principale del TPC-HS è quello di definire e valutare in maniera oggettiva hardware, SO e il HDFS, generando delle metriche che valutano le performance architetturali.
TPC-HS tende a effettuare un vero e proprio stress test contemporaneo sull’hardware e sul SO applicato ad Hadoop. Grazie ad esso, può dare una chiara indicazione su come distribuire ed implementare cluster server Apache Hadoop e fornire indicazioni utili ai DBA su come risolvere eventuali problematiche. È opportuno ricordare che TPC.ORG nasce come progetto openSource in accordo con i più grandi vendor del mondo proprio per valutare Basi di Dati di ogni tipo; la versione HS, nella fattispecie Big Data.

Il TPC Benchmark contiene:
-
TPCx‑HS Specification document;
-
TPCx‑HS Users Guide documentation;
-
Uno script Shell dove settare l’ambiente di test;
-
Codice Java da eseguire per il test.
Questo kit deve essere adoperato secondo le adempienze descritte nel capitolo 2.1.3 del manuale TPC e non deve essere in alcun modo modificato in quanto potrebbe variare le metriche e rendere invalidante il test e risultati finali.
Il codice Java, esegue moduli con nome:
-
HSGen, che genera una quantità di dati stabilita ad inizio test;
-
HSDataCheck, che verifica la completezza del dataset e la sua replicazione remota;
-
HSSort ordina i dati in modo totale;
-
HSValidate è l’ultimo modulo che valida l’output ordinato.
HsGen, HSSort e HSValidate sono basati rispettivamente sulle 3 Classi Hadoop TeraGen che genera dati casuali, TeraSort effettua un ordinamento basato su le coppie chiave-valore e TeraValidate in grado di validare i due processi precedenti.
Come funziona Il TPC-HS?
Per eseguire in maniera corretta e generare risultati affidabili, il test deve seguire 5 passi distinti in maniera sequenziale.
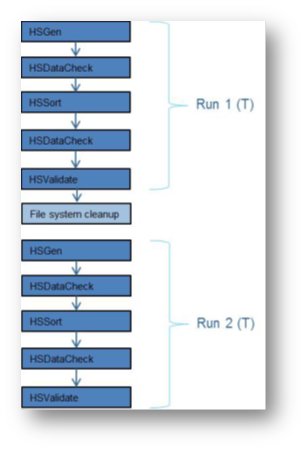
Nell’immagine è possibile notare come il programma esegua gli stessi passaggi due volte, chiamati RUN e vengono eseguiti in maniera pedissequa e successiva. In caso di errore, il processo riprende dal primo passaggio. Durante l’esecuzione delle RUN non devono essere compiute altre attività sulle macchine soggette a test in quanto potrebbero alterare il risultato finale. Il tempo totale per l’esecuzione di una RUN viene espresso in secondi ed è usato per il calcolo della metrica finale del TPC-HS.
In nessun punto del test l’OS può essere riavviato se non al termine del test. Se sono stati riscontrati errori insormontabili a livello applicativo, a livello del sistema operativo o fisico in una delle cinque fasi, il test deve considerarsi nullo. Se invece sono presenti errori risolti a livello applicativo, sistema operativo o fisico il TPC-HS cercherà di risolverli e procedere con la RUN.
Il TPC-HS, in accordo con il mandante del test, ha la possibilità di generare dimensioni multiple di dataset:
100 GB, 300 GB, 1 TB, 3 TB, 10 TB, 30 TB, 100 TB, 300 TB, 1000 TB, 3000 TB, 10000 TB (1 PB).
Performance Metric
La metrica che andremo a valutare principalmente corrisponde alla Performance Metric.
Questa metrica può essere calcolata per mezzo di questo algoritmo:
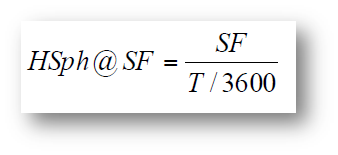
Dove “SF” corrisponde allo Scale Factor nonché la dimensione del dataset, “T” invece corrisponde al tempo totale in secondi per una RUN, “3600” risulta essere una conversione temporale.
Al termine della sperimentazione e test, un risultato TPC-HS può essere comparato solo con un altro risultato TPC-HS e con un medesimo Scale Factor. Risulta impossibile valutare diverse dimensioni del dataset in quanto richiedono un diverso costo e tempo computazionale.
Le dimensioni del dataset applicate alle architetture durante i test sono stati:
-
100 GB;
-
300 GB;
Si è preferito non eccedere sulla grandezza del dataset in quanto lo storage disponibile per i test era limitato a 2 TB.
Nella scelta degli OS, considerando che il framework Hadoop gira sia su Windows che su piattaforme Linux, si è scelto Ubuntu Server 14.04.4 LTS e Centos 7 Infrastructure Server. Si è invece scartata la possibilità di effettuare test su macchina Windows Server in quanto, seppur supportato, il TPC-HS risulta ancora instabile e poco affidabile.
In una seconda fase si è voluto evidenziare eventuali differenze di metrica tra architetture con OS uguali e dataset uguali andando però a variare la potenza di calcolo per mezzo dei processori. La RAM allocata sui server è rimasta invariata per tutto il durare dei test.
Come ultimo obiettivo, si è deciso di osservare l’andamento della metrica andando a variare semplicemente la tipologia di dischi e la loro velocità in scrittura e lettura.
Architettura Adoperata
Prima di procedere alla configurazione ed installazione dei vari OS testati, risulta indispensabile descrivere in maniera precisa i sistemi fisici che si andranno ad adoperare durante i test.
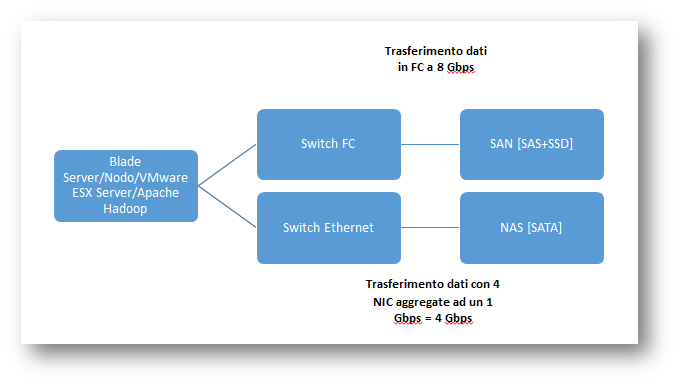
Su VMware sono stati installati i due OS, in momenti diversi: i primi confronti tra OS sono stati compiuti su Switch connesso via Ethernet e dischi SATA, in seconda analisi si è testato OS risultato superiore nel primo confronto con due tipologie di dischi e connessione differenti.
Dischi Applicati
In foto in basso possiamo trovare il datastore dove sono stati eseguiti i vari test.
Il rettangolo rosso corrisponde al NAS, composto da dischi SATA mentre il rettangolo blu corrisponde alla SAN con dischi SAS + SSD.

SATA
I dischi SATA presenti nello storage sono dischi da 7200 Giri a minuto, con quattro NIC (Network Interface Card) da 1 Gbps l’una, aggregati, in modo da avere 4 Gbps di trasferimento dati.
Il Serial ATA (abbreviazione dell’inglese “Serial Advanced Technology Attachment”), in sigla SATA, è una interfaccia per computer generalmente utilizzata per connettere hard disk o drive ottici.
SAS
I dischi SAS li troviamo nella SAN adoperata per i test, con dischi con 10000 giri al minuto, da 1.2 TB l’uno e con trasferimento su rete a 8 Gbps grazie ad una scheda di rete in fibra ottica.
Serial Attached SCSI (SAS) è una tecnologia o interfaccia di trasferimento dati, evoluzione della SCSI, studiata per lavorare sia con dispositivi ad accesso diretto, come i dischi fissi, sia per quelli ad accesso sequenziale, come i nastri magnetici. Il protocollo di comunicazione è seriale punto-punto diversamente dal bus SCSI di tipo parallelo introdotto nella metà degli anni ottanta.
SSD
Un’unità a stato solido o drive a stato solido (in sigla SSD dal corrispondente termine inglese solid-state drive) è una tipologia di dispositivo di memoria di massa basata su semiconduttore, che utilizza memoria allo stato solido (in particolare memoria flash) per l’archiviazione dei dati, anziché supporti di tipo magnetico come nel caso dell’hard disk classico.
Ne consegue che l’altra importante differenza con i classici dischi rigidi è la possibilità di memorizzare in maniera non volatile grandi quantità di dati, senza l’utilizzo di organi meccanici (piatti, testine, motori ecc.) come fanno invece gli hard disk tradizionali. La maggior parte delle unità a stato solido utilizza la tecnologia delle memorie flash NAND, che permette una distribuzione uniforme dei dati e di “usura” dell’unità.

Configurazione del TPC-HS
Dopo aver configurato sul Server Apache Hadoop, si rimanda al link per la configurazione, è possibile passare al download e configurazione del file TPC-HS. Tramite www.tpc.org è possibile scaricare il file per il benchmarking, previa registrazione.
http://www.tpc.org/tpc_documents_current_versions/current_specifications.asp
Dopo aver scaricato l’archivio occorre estrarlo e raggiungere, muovendosi tra le directory fino a:
94670ba4-6c82-4cd4-b185-d3f944178486-tpcx-hs-tool\TPCx-HS_Kit_v1.3.0_external\TPCx-HS-Runtime-Suite/Benchmark_Parameters.sh
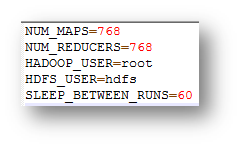
In questo file, che è indispensabile configurare per la corretta esecuzione del TPC, è possibile settare il numero di MAP e REDUCER, stabilire l’USER sul quale Apache Hadoop viene eseguito, l’USER sul quale HDFS è configurato, SLEEP_BETWEEN_RUNS corrisponde invece alla pausa in secondi tra una RUN ed un’altra.
Raccolta dei Risultati
Per poter descrivere in modo scientifico ed accurato il benchmarking ci si è avvalsi di una tabella fornita da TPC.org, come previsto da regolamento. Dopo aver avviato i due demoni di Apache Hadoop, ci si colloca nella directory principale del TPC, tramite terminale, dove lanceremo questo comando :
-
./TPCx-HS-master.sh OPTIONS
-
OPTIONS:
-
-h Help
-
-g <TPCx-HS option 1,2,3 or 4>
-
-
Run TPCx-HS for 100GB
-
Run TPCx-HS for 300GB
-
Run TPCx-HS for 1TB
-
Run TPCx-HS for 3TB
-
Run TPCx-HS for 10TB
-
Run TPCx-HS for 30TB
-
Run TPCx-HS for 100TB
-
Run TPCx-HS for 300TB
-
Run TPCx-HS for 1PB
Considerando lo spazio presente nello storage, si è preferito adoperare un dataset da 100GB e 300GB in quanto oltre al semplice stress test del sistema, si vuole analizzare se vi sono differenze tra l’uso di sistemi operativi e come variano le metriche al variare di alcune caratteristiche fisiche particolari. Durante l’arco temporale prestabilito, si sono effettuati 16 TEST complessivi dove si sono andati a raccogliere tutti i log finali e risultati ottenuti.
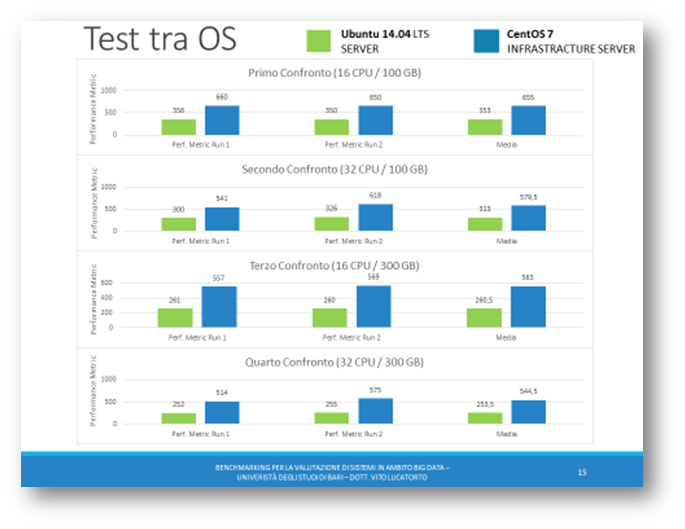
Nei primi test basati su OS, è possibile evidenziare che a parità di Core adoperati e RAM allocata si hanno risultati sostanzialmente differenti. Risulta come è possibile vedere da grafico come CentOS Server risulti essere del doppio più performante rispetto ad Ubuntu Server.
Per esigenze operative si è evitato di collocare lo storage in una SAN adoperata per le normali operazioni diurne e notturne aziendali. Si è preferito allocare uno storage dedicato in modo da non sovraccaricare le operazioni aziendali e rendere più affidabili i risultati.
Dopo aver notato la superiorità CentOS rispetto ad Ubuntu, si è voluto provare un confronto tra CentOS con dischi SATA e CentOS con dischi SAS + SSD.
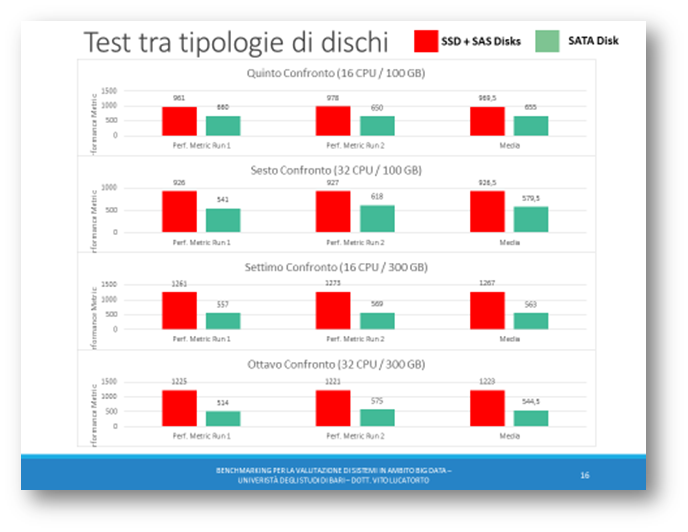
In questo secondo confronto, grazie al grafico, è possibile notare come le colonne colorate di rosso, indicanti i dischi SSD + SAS collegati su switch FC, risultano essere del doppio più performanti rispetto ai dischi SATA collegati in Ethernet.
Dulcis in fundo grazie a questo studio è emerso come, Apache Hadoop è meno sensibile a variazioni del numero di CPU e dimensione del Dataset. Risultanti più evidenti e nettamente superiori vengono riscontrati nell’utilizzo della tipologia dischi, noto collo di bottiglia a livello informatico, e mezzo di trasferimento dati.