
Implementazione e configurazione di Microsoft Azure HDInsight
Dopo aver osservato nell’articolo precedente una prima introduzione del framework Apache Hadoop, in grado di gestire BIG DATA tramite cluster di server distribuiti, a partire dal processo di MapReduce sino alle tipologie di configurazioni, in questa pubblicazione si analizzeranno e descriveranno i passaggi per configurare HDInsight sulla piattaforma Cloud Microsoft Azure.
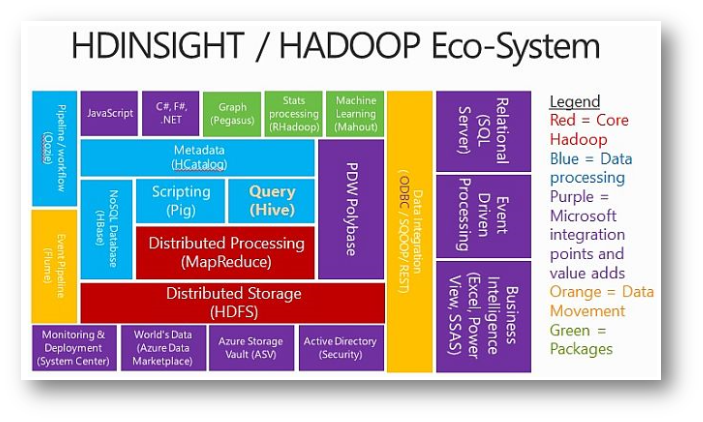
Azure HDInsight distribuisce ed esegue il provisioning dei cluster Apache Hadoop gestiti nel cloud, offrendo un framework progettato per elaborare, analizzare e creare report sui Big Data con elevata affidabilità e disponibilità. HDInsight usa la distribuzione Apache Hadoop ed esso colleziona al suo intero un ecosistema di componenti dedicato interamente a Big Data, come Apache HBase, Apache Spark, e Apache Storm, Apache Ambari, in grado di inglobare dati strutturati e non.
Al contrario di quanto si possa credere, creare un’infrastruttura tanto complessa in grado di gestire BIG DATA, su Microsoft Azure risulta essere a portata di pochi Click. Innanzitutto occorre collegarsi sul portale dedicato https://portal.azure.com/
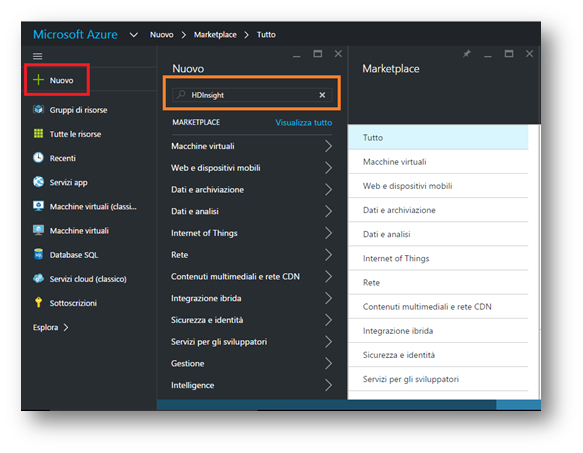
Dopo aver effettuato il login, il modo migliore per potersi districare tra i tanti servizi offerti da Microsoft Azure risulta essere la ricerca.
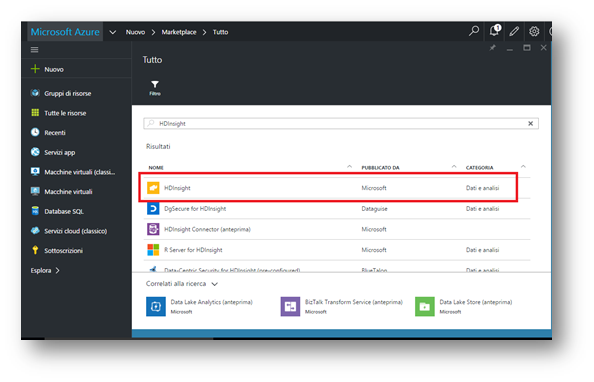
Al termine della ricerca Azure restituisce tutti i prodotti inerenti a “HDInsight”. Scegliamo la prima voce pubblicato da Microsoft con categoria Dati e Analisi.
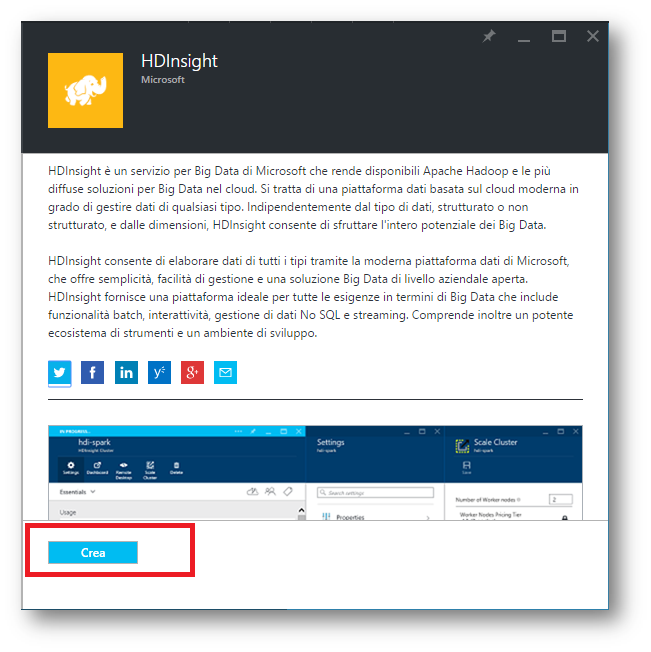
Il passo successivo, dopo aver cliccato su HDInsight mostra le informazioni principali e tramite il tasto “crea” è possibile metter su la nostra infrastruttura per Big Data.
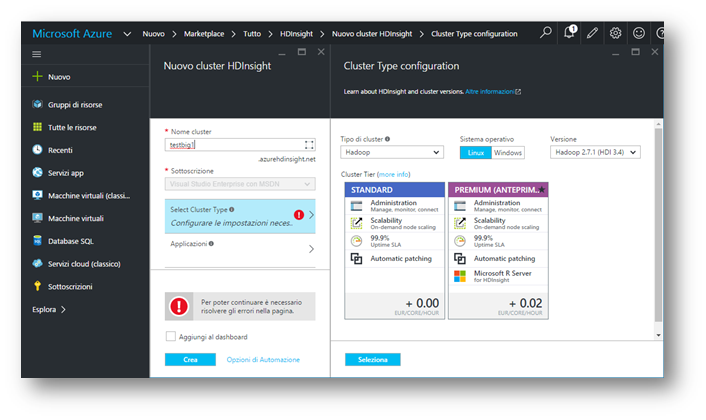
Dopo aver cliccato su “Crea”, Azure mostra nella sua schermata scorrevole orizzontale, una serie di voci obbligatorie per la corretta configurazione di HDInsight.
Il “nome Cluster” corrisponde ad un dominio di terzo livello che verrà creato e servirà per poter accedere tramite protocollo https al pannello di management.
Il Cluster Type permette di selezionale la tipologia di cluster dove configurare e creare l’architettura per Big Data. è possibile scegliere tra diversi tipi di framework disponibili:
- Hadoop, permette l’elaborazione distribuita di terabyte di dati;
- HBase, utilizza un cruscotto con database NoSQL;
- Storm, è in grado di elaborare in maniera affidabile flussi di dati infiniti in tempo reale;
- Spark, usato per analisi dei dati;
Può essere selezionabile anche la tipologia di sistema operativo LINUX o WINDOWS ed anche la versione del framework da installare.
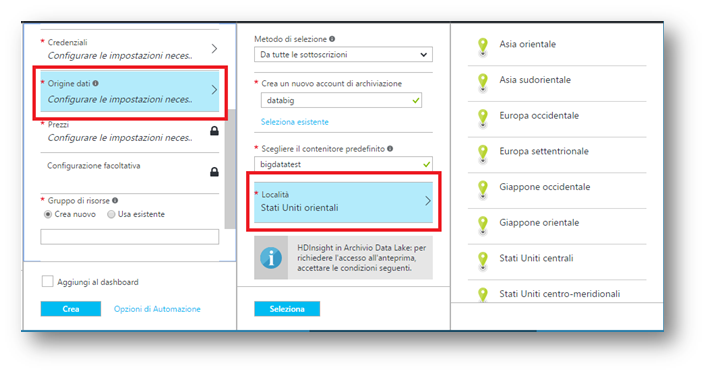
Prima di terminare la nostra configurazione, occorre creare le credenziali per l’accesso al cluster e generare un utente e password per l’autenticazione tramite SSH oppure solo un utente per l’autenticazione tramite CHIAVE PUBBLICA.
Arrivati in questo passaggio, bisogna settare dove il nostro cluster sarà collocato e corrisponderà al sito primario. La località risulta importante per due fattori principali: latenza e EU Privacy Law: vi è la possibilità di effettuare un provisioning della nostra infrastruttura in tutto o quasi il globo terreste grazie ai datacenter sparsi per il mondo, adempiendo così ad una serie di richieste che il mercato impone in termini legali e di prestazioni.
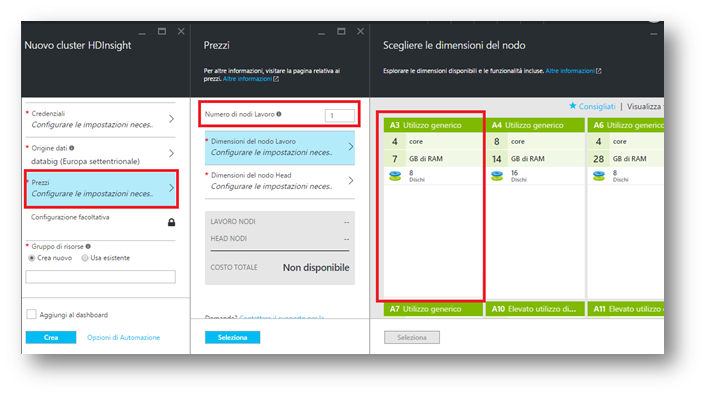
Ultimo passaggio ma non per importanza risulta essere la scelta del numero di nodi da impiegare per l’architettura distribuita e le loro caratteristiche fisiche per i nodi master e slave.
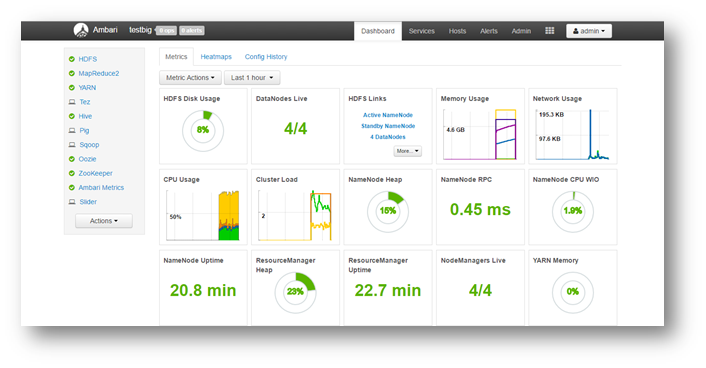
Definito il gruppo di risorse che corrisponde essere un semplice collettore di risorse sotto un unico nome, cliccato il tasto crea, un “omino” con tesserino Microsoft si preoccuperà di configurare Network, storage e Server nel datacenter scelto da noi.
Terminata la configurazione di HDInsight, è possibile collegarsi tramite URL composta da https://nomescelto.azurehdinsight.net oppure tramite SSH, precedentemente configurato. Nell’immagine, l’URL risponde alla richiesta mostrando, dopo aver effettuato il login, un pannello amministrativo organizzato da Apache AMB
Cos’è AMBARI?
Il progetto Apache Ambari ha lo scopo di rendere la gestione di Hadoop più semplice attraverso lo sviluppo di software per il provisioning, la gestione e il monitoraggio cluster Apache Hadoop. Ambari fornisce un’interfaccia intuitiva e di facile utilizzo per la gestione Hadoop tramite una web application che implementa le API REST.
L’Applicativo Ambari permette agli amministratori di sistema di:
-
Implementazione di Hadoop Cluster tramite:
- Procedura guidata step-by-step per l’installazione di Apache Hadoop attraverso N nodi;
- Gestione dei servizi di Hadoop per i Cluster.
- Procedura guidata step-by-step per l’installazione di Apache Hadoop attraverso N nodi;
- Ambari fornisce la gestione centralizzata per l’avvio, l’arresto, e la riconfigurazione dei servizi Hadoop.
-
Monitoraggio dei Cluster Hadoop;
- Ambari fornisce un cruscotto per il monitoraggio della salute e lo stato del cluster Hadoop;
- Ambari sfrutta le Ambari Metrics System per la collezione di metriche;
- Ambari sfrutta Ambari Alert framework, utile come sistema di allerta. Notifica eventuali anomalie (ad esempio, un nodo va giù, lo spazio su disco è in esaurimento, ecc).
Nel prossimo approfondimento vedremo come realizzare una delle configurazioni più usate applicate ad Apache Hadoop. Con l’ausilio di Macchine Virtuali e un OS open source sarà possibile implementare Apache Hadoop in configurazione pseudo-distribuited su Microsoft Azure.
- Ambari fornisce un cruscotto per il monitoraggio della salute e lo stato del cluster Hadoop;