
Introduzione a Git e Github per principianti. Zero to Hero
Introduzione
Bentornati su ICTPower e grazie per avermi raggiunto su questo blog dove andremo ad affrontare e apprendere le potenzialità del sistema di versionamento Git.
Pochi giorni fa c’è stata la #POWERCON2022, che vi consiglio di rivedere tramite il nostro canale YouTube ICT Power La Community degli IT Pro – YouTube
In particolare, questo articolo si baserà, almeno in parte, su quanto discusso nella live di #POWERCON2022 nel talk “Git version control for System Administrators. From Zero to Hero“.
Se state cercando le slide della presentazione, non preoccupatevi, potete trovarle sul mio repository Github dedicato ai talks a questo link.
Prima di iniziare
Per utilizzare Git non sono necessari particolari strumenti, vi basterà un computer e un po’ di voglia di smanettare in vecchio stile, almeno per il momento.
Le istruzioni per installare Git (laddove non fosse già installato) le trovate nella documentazione ufficiale, con tutte le diverse opzioni a seconda del sistema operativo che utilizzate.
Vi invito ad aprire la vostra riga di comando preferita (Terminal, cmd.exe, Powershell…) e controllare che Git non sia già installato a sistema. Questo solitamente avviene già per installazioni di tipo Unix, ma nel dubbio andiamo ad aprire il nostro terminale e scriviamo git –version
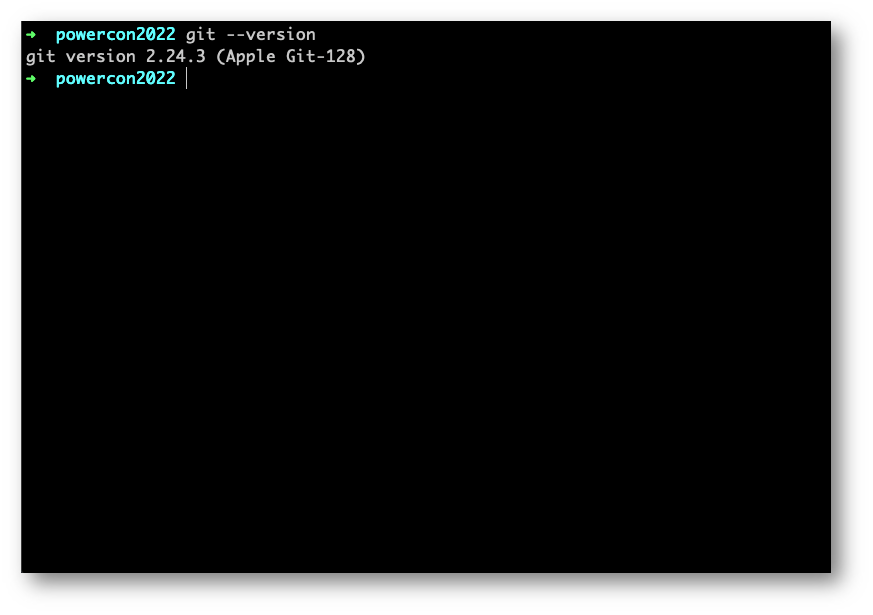
Laddove l’output fosse noto, come nello screenshot, vuol dire che l’installazione è già presente. In caso contrario semplicemente seguiamo la documentazione riportata sopra.
Mentre aspettiamo che Git venga installato a sistema, procediamo a creare un account, se non ne abbiamo già uno, sulla piattaforma di hosting Github.com all’indirizzo https://github.com/, premendo su Sign Up e rispondendo ai campi di Input proposti dal form di iscrizione di Github.
Proseguite nella creazione dell’account finché non vi troverete sul vostro profilo (a questo punto nuovo) sulla piattaforma Github.
E’ ancora presto per parlare di chiavi di autenticazione, chiavi SSH e access tokens personali con scadenze ma dobbiamo fin da subito sapere che per lavorare su Github e inviare le nostre modifiche verso i nostri repository (scopriremo dopo di cosa si tratta, se non avete visto il talk) dobbiamo assicurarci di farlo in totale sicurezza tramite uno dei metodi resi disponibili da Github. Uno di questo è quello di create degli Access Token con scadenza.
Per generare un nuovo Access Token possiamo andare a questo indirizzo https://github.com/settings/tokens/new e seguire la procedura, come da screenshot.
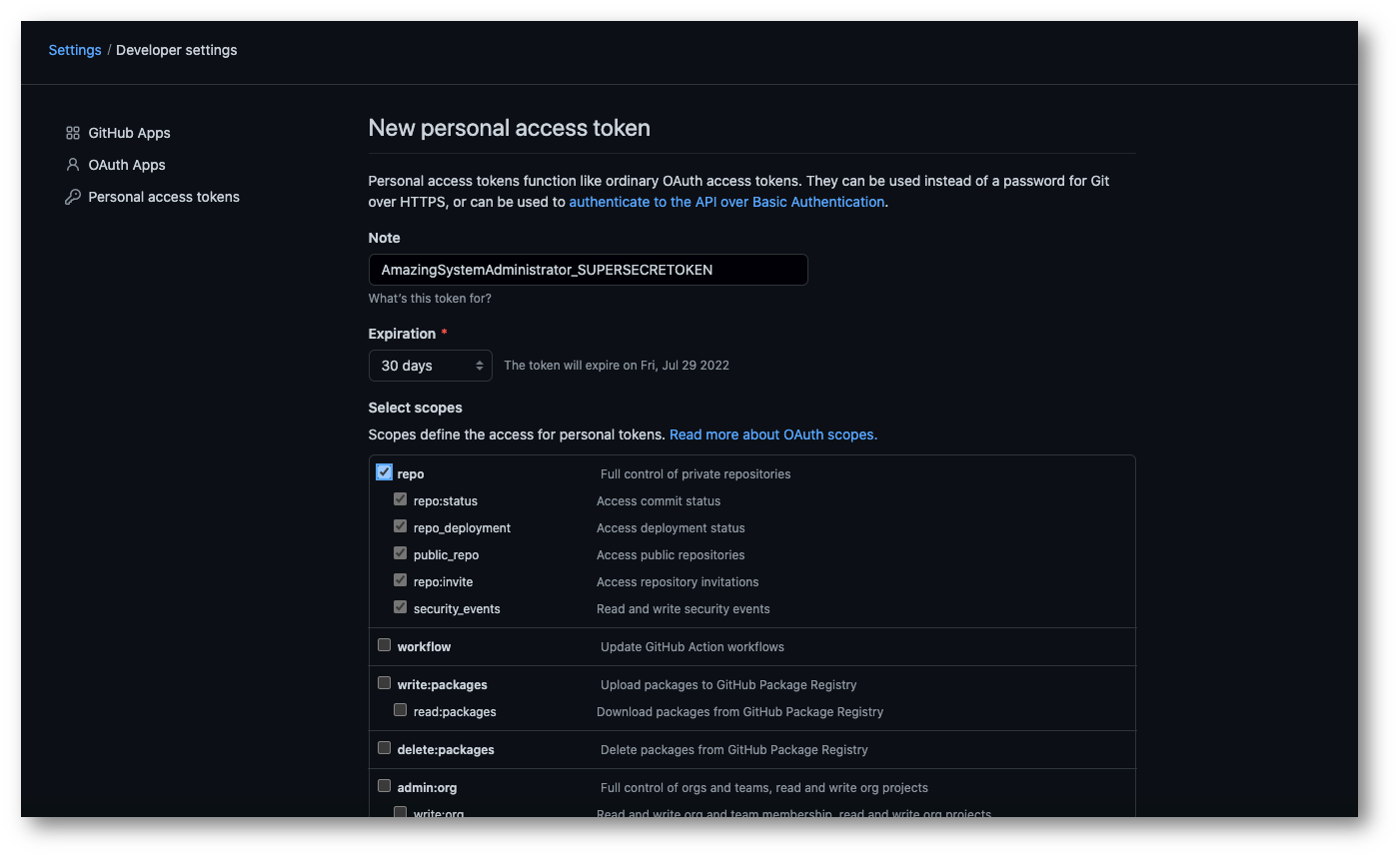
Dobbiamo fare attenzione a creare Access Tokens con i giusti permessi. Per quello che vogliamo fare sarà sufficiente avere permessi sul “repo”, quindi attiviamo solo quel flag.
L’invito è quello di creare poi successivamente delle chiavi SSH con cui lavorare dal vostro computer su Github, ma questo lo vedremo in altri articoli più avanzati.
Cos’è Git
Git a oggi è uno dei sistemi di versionamento (Version Control, da qui in poi VCS) più usati nel mondo della tecnologia e dello sviluppo.
È una tecnologia che permette a sviluppatori, system administrators, DevOps, SRE e chi più ne ha più ne metta di compartecipare e collaborare attivamente a progetti distribuiti di piccola, media e larga scala.
Si tratta di un sistema gratuito, open source e veloce che permette il version control in maniera distribuita, oppure locale, a seconda dell’uso che vorremmo farne.
Fu sviluppato nel 2005 da Linus Torvalds, creatore di Linux e parte della Linux Development Community, dopo che la Linux Development Community ebbe alcuni problemi nel continuare ad utilizzare BitKeeper, il VCS utilizzato fino a quel momento per fare il versionamento del Linux Kernel.
Questo nuovo sistema, Git, fu costruito tenendo ben in mente quelle che erano le necessità della Linux Development Community:
- Velocità
- design semplice
- sviluppo parallelo e non lineare
- Distribuzione
- capacità di gestire codici sorgente di grande entità (pensiamo appunto al Kernel di Linux)
Come abbiamo visto durante l’installazione, Git può essere utilizzato su tutti i sistemi operativi e possiamo decidere se utilizzarlo nella maniera corretta, cioè da riga di comando, oppure tramite strumenti GUI (graphical user interface, interfacce grafiche), che non è sbagliato ma farà sì che ogni sviluppatore senior vi guardi con sguardo arcigno.
Per essere corretti, ecco alcune GUI per utilizzare Git. Badate bene che utilizzare la GUI senza conoscere Git probabilmente farà effetto contrario a quello sperato in quanto risulterà meno semplice non conoscendone i comandi e le utilità.
- Github Desktop, direttamente da Github https://desktop.github.com/
- GitKraken, il mio preferito https://www.gitkraken.com/
Cos’è Github
Git è quindi una tecnologia che ci abilita al versionamento delle nostre risorse tecnologiche (codice sorgente, pagine scritte in markdown, pagine scritte in LaTeX, documenti, foto…) e Github è la piattaforma che ci permette di avvalerci di questa tecnologia.
Ci sono alternative a Github, nello specifico le più famose probabilmente sono Gitlab e Bitbucket, ma il concetto rimane lo stesso.
Utilizzeremo Git (la tecnologia) per fare versionamento e inviare i nostri file verso una piattaforma distribuita e remota (Github, Gitlab, Bitbucket).
Per gli esempi successivi utilizzeremo Github, quindi se non l’avete già fatto, vi invito a creare un account sulla piattaforma.
Github si presenta come “il luogo dove il mondo costruisce il proprio software” (molta umiltà, sicuramente, ma i numeri parlano abbastanza chiaro). Fu acquistata nel 2018 da Microsoft durante l’onda mediatica del “Microsoft Loves Linux” e da lì è cresciuta considerevolmente negli utilizzi e nelle feature che rende disponibili a tutti i suoi utilizzatori, per la maggior parte delle volte in maniera completamente gratuita.
Github infatti ha una serie di funzionalità premium tier ma sono tutte utilizzabili anche da chi non è iscritto come premium, ovviamente con dei limiti di utilizzo su alcune feature, rilevanti prevalentemente per chi si occupa di DevOps e CI/CD tramite questa piattaforma ma se non avete idea di cosa quelle parole significhino (almeno per ora) allora il problema non si pone!
Adesso che abbiamo una conoscenza teorica di Git e Github e possediamo un’installazione del primo e un account del secondo, andiamo a imparare come utilizzare entrambi.
Per creare un nuovo repository su Github possiamo andare all’indirizzo https://github.com/new oppure premere sul “New Repository” dalla nostra home, dopo essersi registrati.
(Prima di fare quello avreste dovuto cambiare il Theme da Light e Dark, ma questo è un esercizio che lascio a voi)
Accederemo quindi alla schermata dove inserire tutti i metadati riguardanti il nostro repository
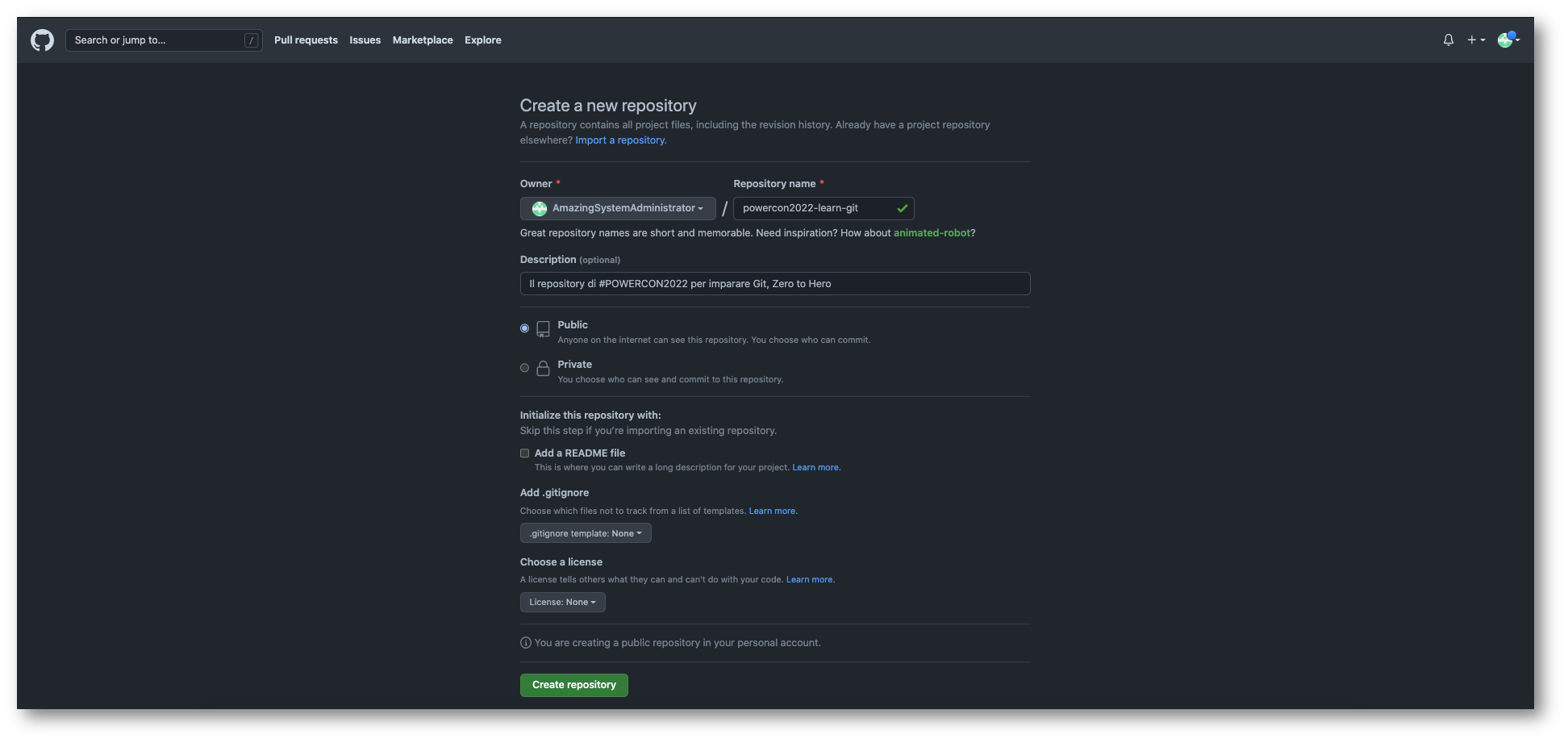
E dopo averlo fatto Github ci mostrerà alcuni comandi che possiamo usare per inizializzare il repository (che in questo momento esiste solo su Github) in locale oppure come aggiungere questa “remote origin” ad un repository locale che avevamo già creato.
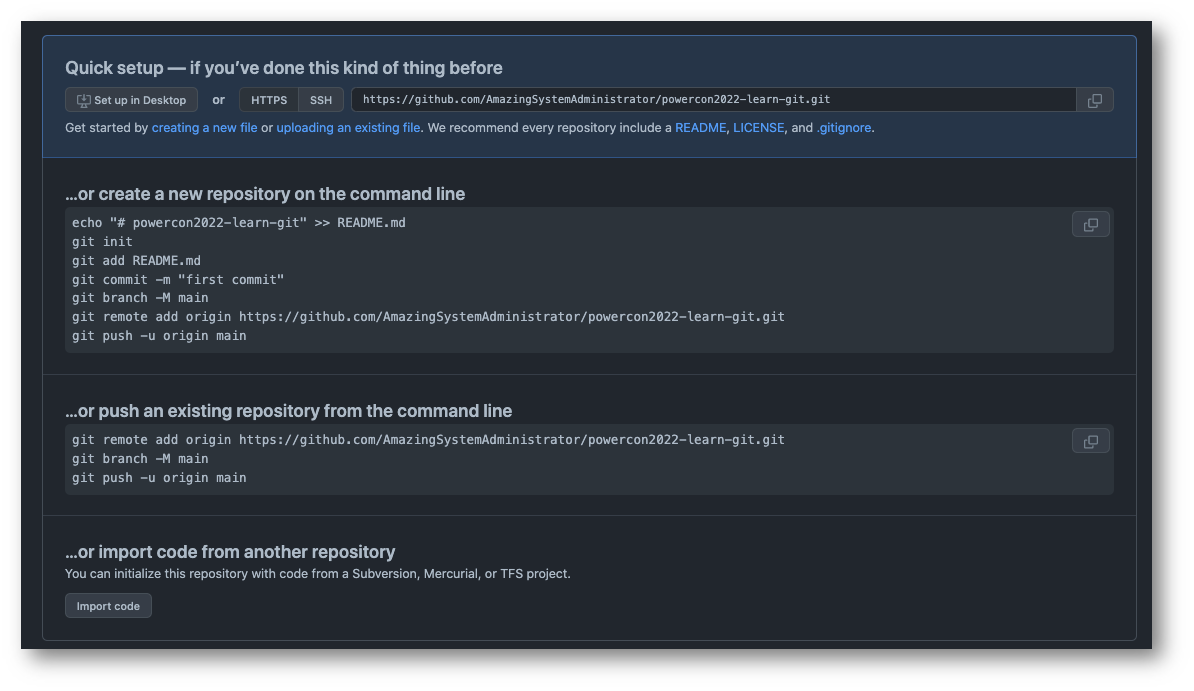
Lo so, sono tante parole. Non sappiamo nemmeno cosa sia un repository. Possiamo intuirlo, certo, ma non lo sappiamo.
Per ora accettiamo che quei comandi di Github li lasciamo lì, aperti su quella pagina, in attesa di utilizzarli in un secondo momento.
Spostiamoci invece sul nostro computer, in locale, e iniziamo a lavorare un po’ con Git!
I comandi di base
Sul mio computer ho preparato una cartella di lavoro da cui partire e che vi invito a replicare. Una qualsiasi cartella vuota va bene ad ogni modo.
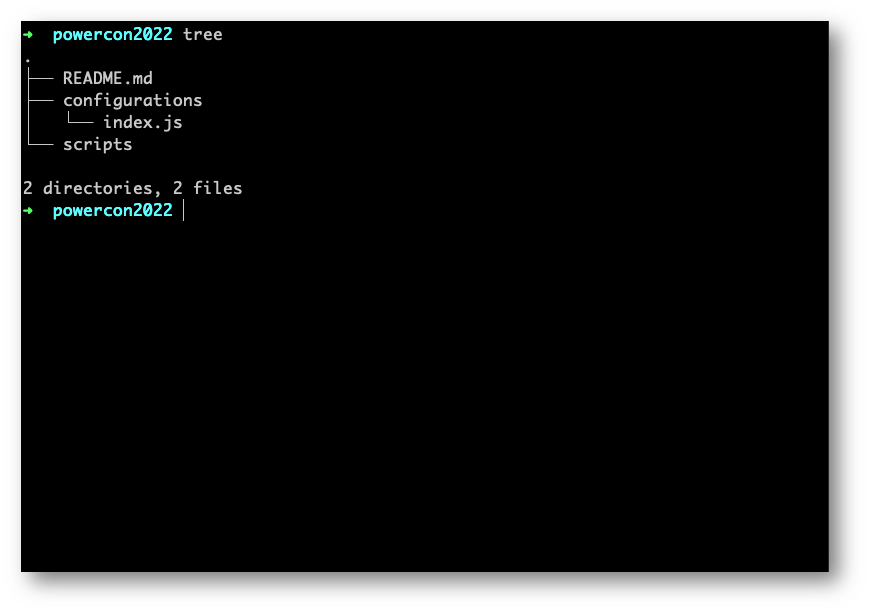
Come potete vedere dallo screenshot, avremo un file README.md e due cartelle. Non preoccupatevi del comando tree, è stato utilizzato solo per farvi vedere la struttura ad albero delle cartelle e dei file di progetto.
Per inizializzare la nostra cartella di progetto e trasformarla in un “repository”, ci basta utilizzare il comando git init
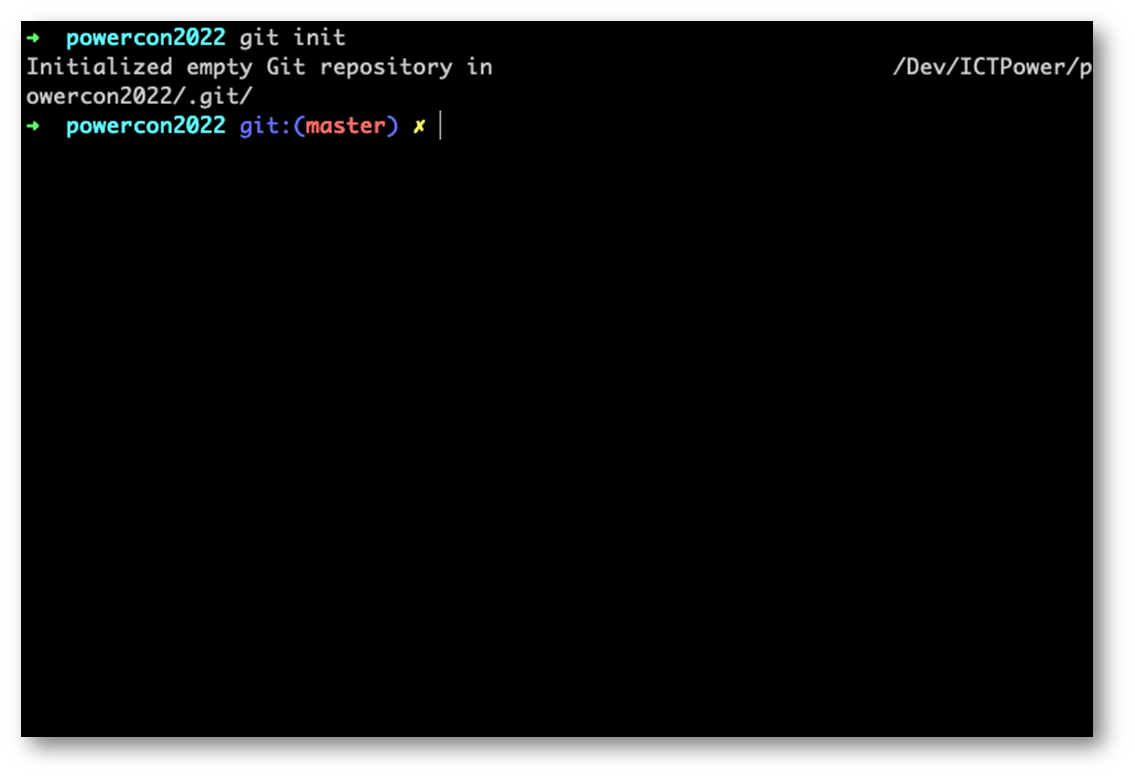
Dopo aver scritto git init avremo inizializzato la nostra cartella, facendola diventare a tutti gli effetti un repository Git.
Un repository non è altro che una cartella o workspace dove Git andrà a lavorare, elaborare e seguire i nostri file e i cambiamenti che questi subiranno nel tempo. Il modo in cui Git segue questi cambiamenti è esplicito; quindi, starà a noi avvertire Git che un cambiamento è avvenuto su file che aveva già seguito o che deve ancora seguire.
Ad esempio, in questo momento Git è inizializzato sul workspace powercon2022 (che è anche il nome locale della mia cartella) ma non sta seguendo alcun file o cartella, quindi qualsiasi cambiamento io faccia a questi non sarà “seguito” da Git.
Come fare allora per far sì che Git si renda conto dei file o cartelle che vengono cambiati?
Beh, dobbiamo semplicemente “aggiungere” questi file o cartelle alla memoria di Git, così che il software si renda conto che deve tracciarne i cambiamenti.
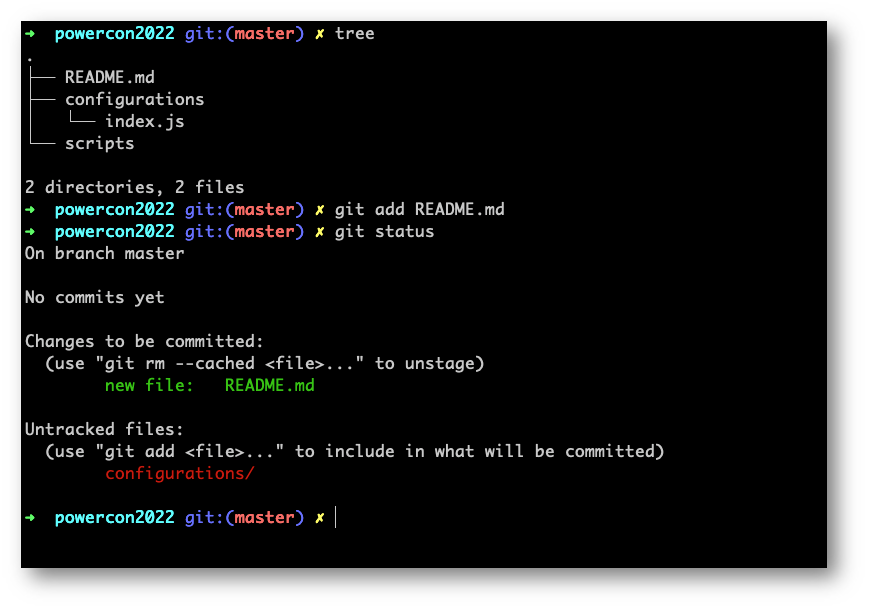
Andando a inserire il comando “git add [filename o cartella]” diciamo a Git di seguire quel file o cartella. Scrivendo invece “git status” Git ci farà vedere cos’è stato aggiunto alla lista dei file o cartelle da seguire e cosa, invece non stiamo seguendo.
Avete notato che Git non segnala la cartella scripts ma solo la cartella configurations, come “untracked”?
Questo perché una cartella vuota (che non contiene file) non è di interesse di Git.
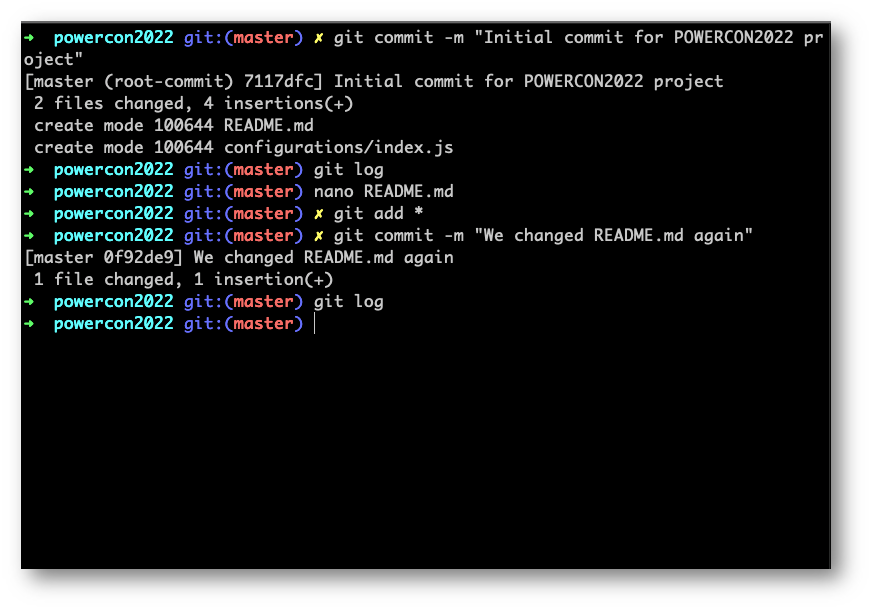
Per velocizzare l’aggiunta di file e cartelle in un solo comando, senza scriverne uno alla volta, possiamo fare “git add *”
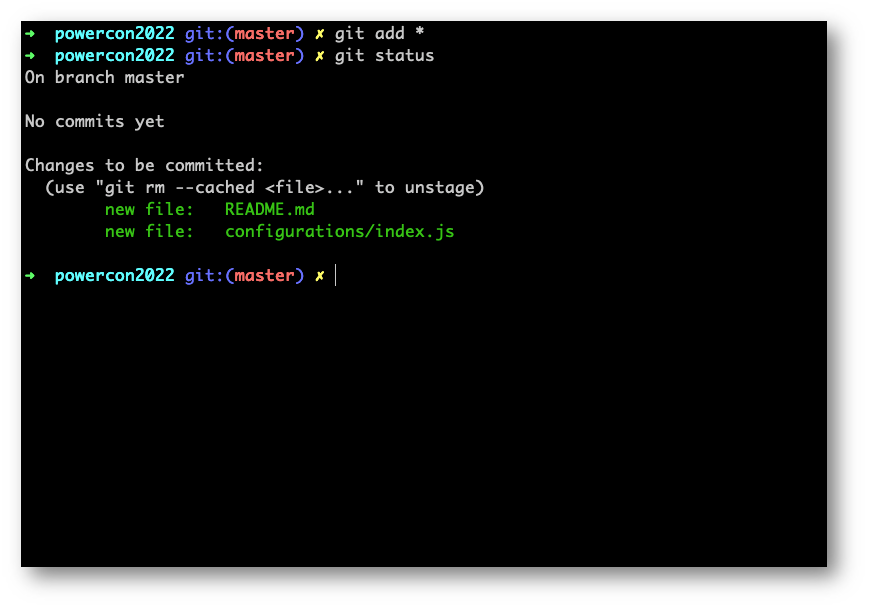
Noteremo come entrambi i file presenti nella root directory e nella cartella configurations siano adesso seguiti da Git. Con il comando “git add” abbiamo inserito tutti i file in un’area nota come “Staging Area”, dove Git registra i cambiamenti tra le versioni in locale e non ancora “salvate nel tempo” dei nostri file.
Cosa intendiamo con questo? Proviamo a fare una modifica al file README.md aggiungendo una nuova riga.
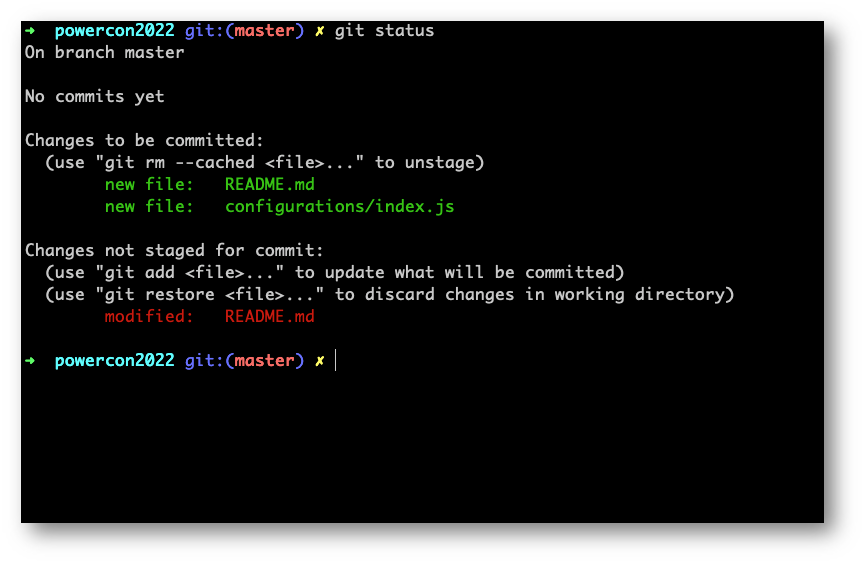
Modificando il file README.md e scrivendo il comando “git status” ci rendiamo conto che il cambiamento che abbiamo appena fatto su README.md è stato registrato da Git che ci invita a aggiungere e storicizzare ciò che abbiamo modificato per riportarlo nell’area di Staging, come descritto dal messaggio che vediamo in screenshot.
Per farlo non dovremo far altro che fare di nuovo “git add *”, oppure per il singolo file “git add README.md”, a scelta.
Come noterete dagli screenshot, la frase “No commits yet” identifica il fatto che non abbiamo creato nessun commit, nessun “punto nel tempo” o snapshot del nostro progetto. I file sono seguiti da Git ma non abbiamo registrato un punto, un commit, a cui tornare in qualsiasi momento vogliamo!
Facciamolo adesso 😊
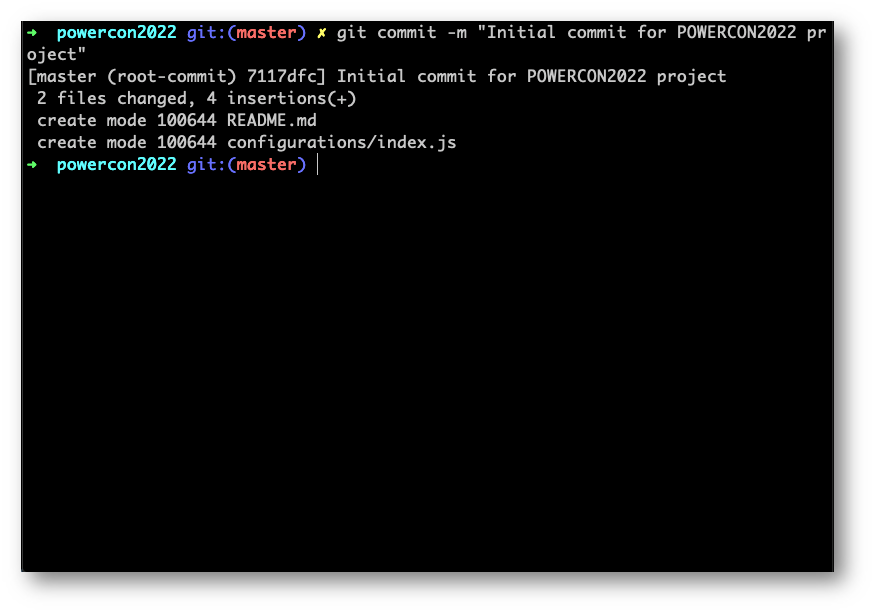
Abbiamo creato un commit che identificherà un punto nel tempo del nostro codice che rimarrà tale.
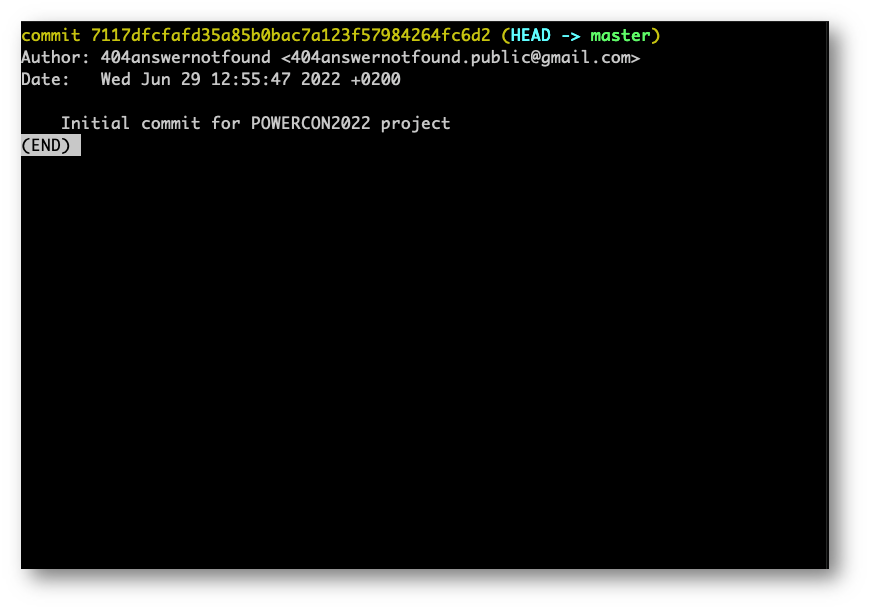
Facendo “git log” vedremo la hash di questo punto nel tempo, insieme ad altri dati utili come l’autore e la data insieme ad un utile messaggio che possiamo inserire nel nostro commit con il flag “-m”
Quindi git commit –m “descrizione del commit” creerà questo “point in time”.
Per creare ulteriori commit sarà sufficiente fare modifiche al codice, aggiungerle all’area di staging e creare un nuovo commit.
Per avere un dettaglio maggiore in quelli che sono i cambiamenti tra la fase di staging e la fase di commit possiamo utilizzare il comando “git diff –staged” e ci verrà mostrato quali differenze ci sono tra i file precedentemente inseriti nel commit (point in time, snapshot) e quelli che abbiamo appena inserito in staging (git add)
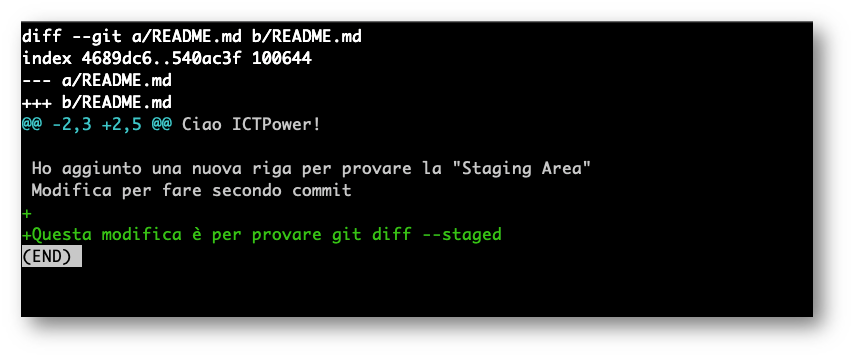
Con il “+” in verde saranno evidenziate le aggiunte, con il “-” in rosso le rimozioni. In cima troveremo che la differenza tra staging e commit è stata fatta solo per il file README.md essendo l’unico file che abbiamo modificato.
Proviamo adesso a muoverci “nel tempo” del nostro progetto con il comando “git checkout”
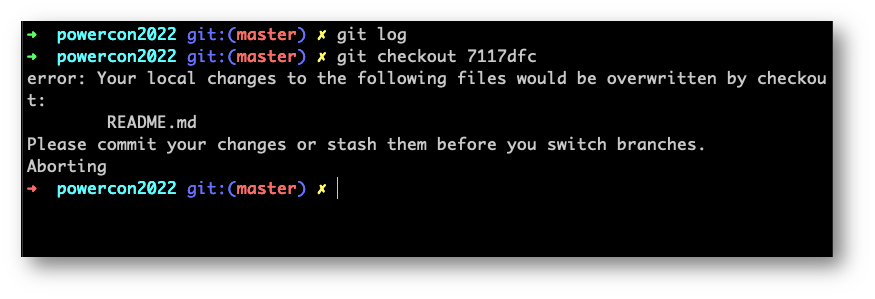
Se non avremo fatto il commit dei cambiamenti apportati precedentemente (nel nostro caso a README.md) verremo avvertiti di fare commit oppure “stash”, comando che rimuoverà quanto presente nell’area di staging fino a quel momento.
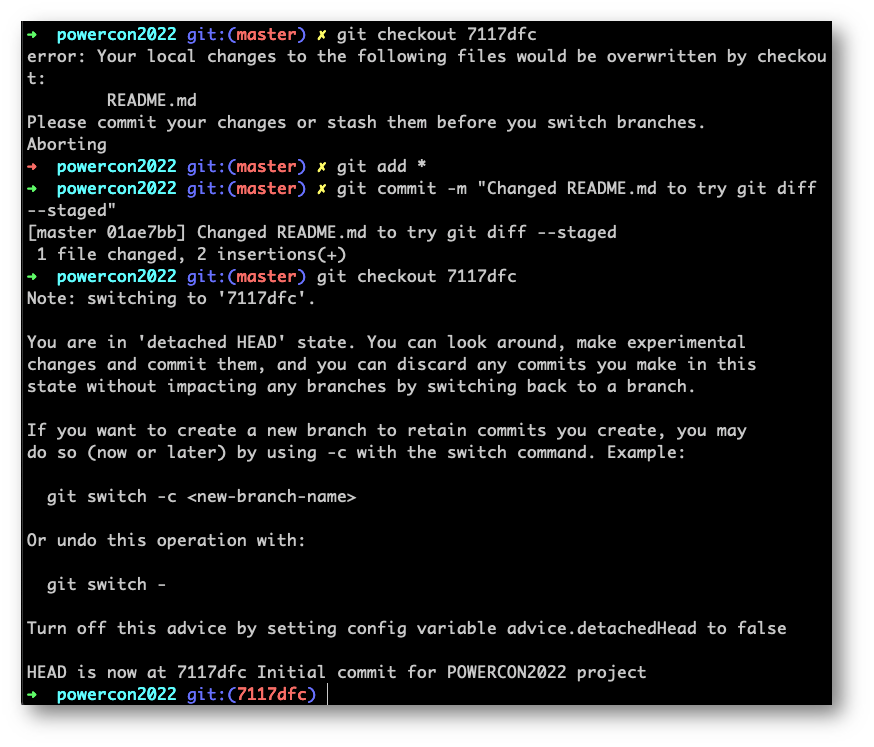
Le sette cifre con cui faremo checkout saranno le cifre iniziali della hash del commit dove vogliamo andare.
Per conoscere il commit e la sua hash sarà sufficiente fare “git log” come abbiamo visto, quindi “git checkout [hash]” per staccarsi dalla posizione attuale del progetto e raggiungere il precedente stato.
Anche Git ci aiuta mostrandoci un messaggio che spiega l’utilizzo di git checkout appena fatto.
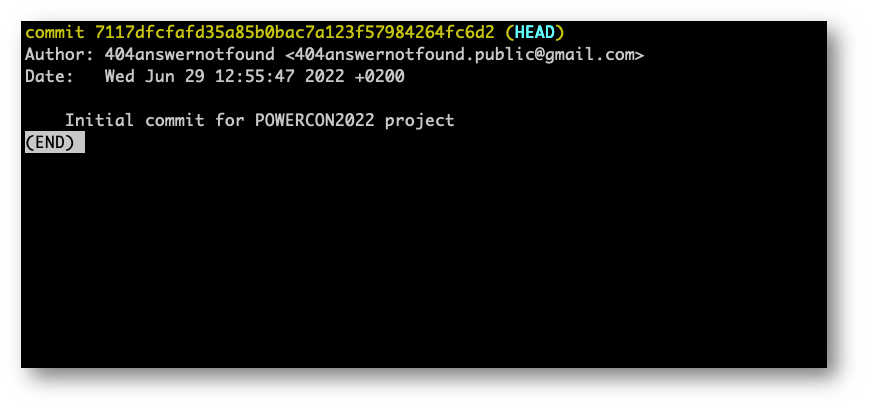
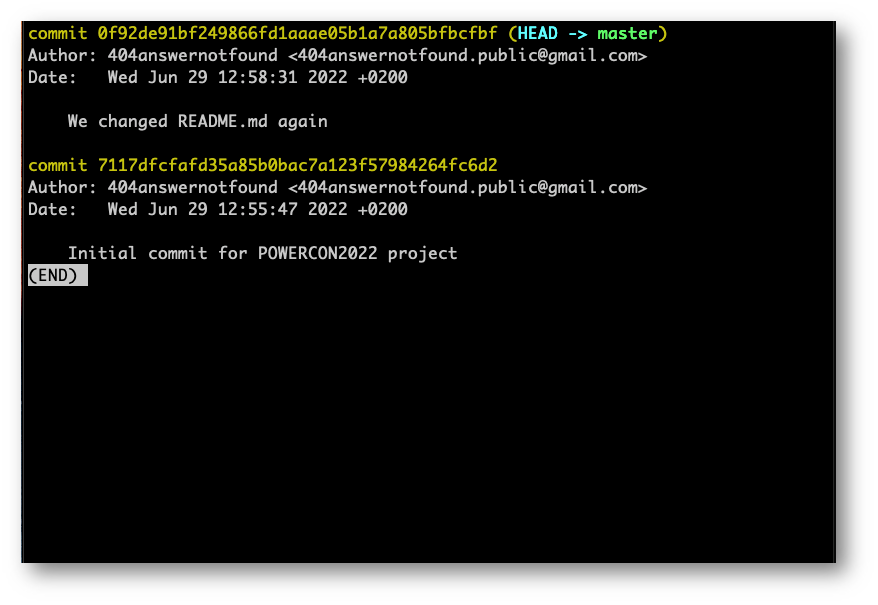
Facendo “git log” per tornare al punto dov’eravamo rimasti noteremo che dei tre commit fatti finora vediamo solo quello attuale (e quelli passati, laddove ce ne fossero, ma essendo il primo commit, non ha precedenti commit da mostrarci).
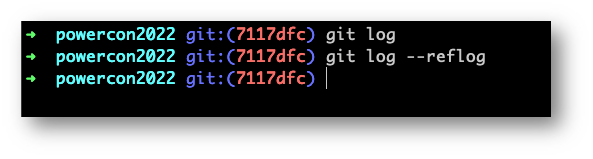
Per mostrarci i commit “futuri” rispetto a quello attuale (che appartiene al passato del nostro progetto) dovremo aggiungere il flag reflog.
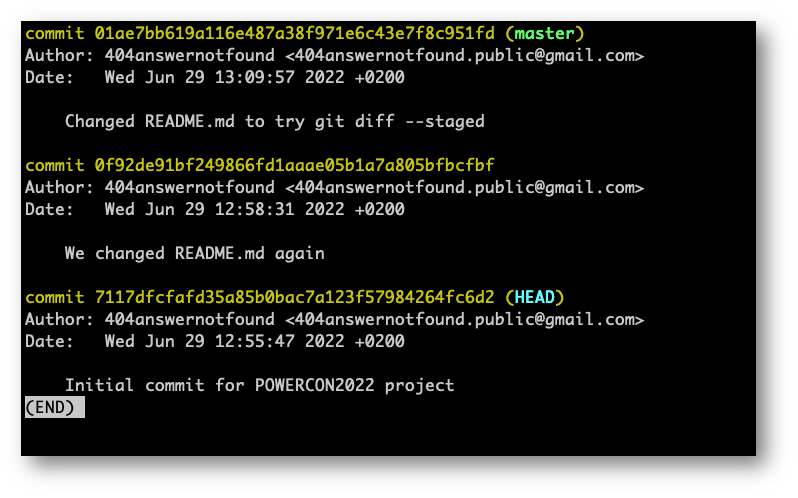
Adesso che siamo in grado di vedere l’intera “linea temporale” del nostro progetto, costruito con tanti commit (finora in locale), possiamo tornare sull’ultimo commit del ramo da cui siamo partiti. Nel caso specifico, il ramo “master” che d’ora in poi chiameremo “branch” per rimanere attuali con quelli che sono i termini di Git.
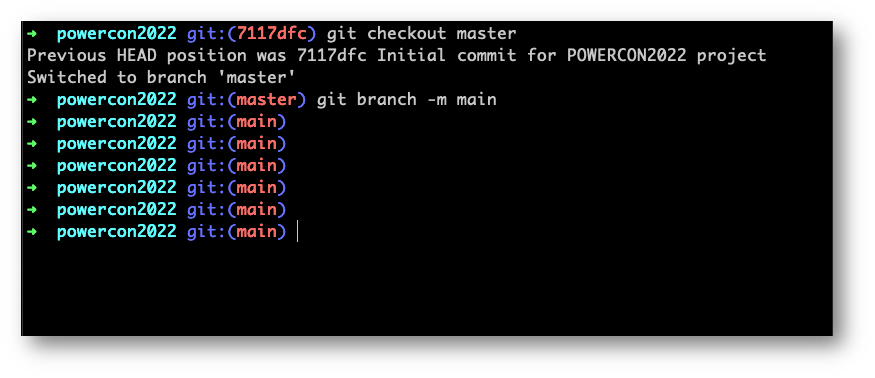
È molto importante, anche per questioni purtroppo attuali, andare a rinominare il “master” branch in “main”. Per saperne di più vi invito a leggere questo articolo.
Per non doverci pensare ogni volta che fate “git init”, potete utilizzare questo comando che andrà a riconfigurare la global configuration di Git:
git config –global init.defaultBranch main
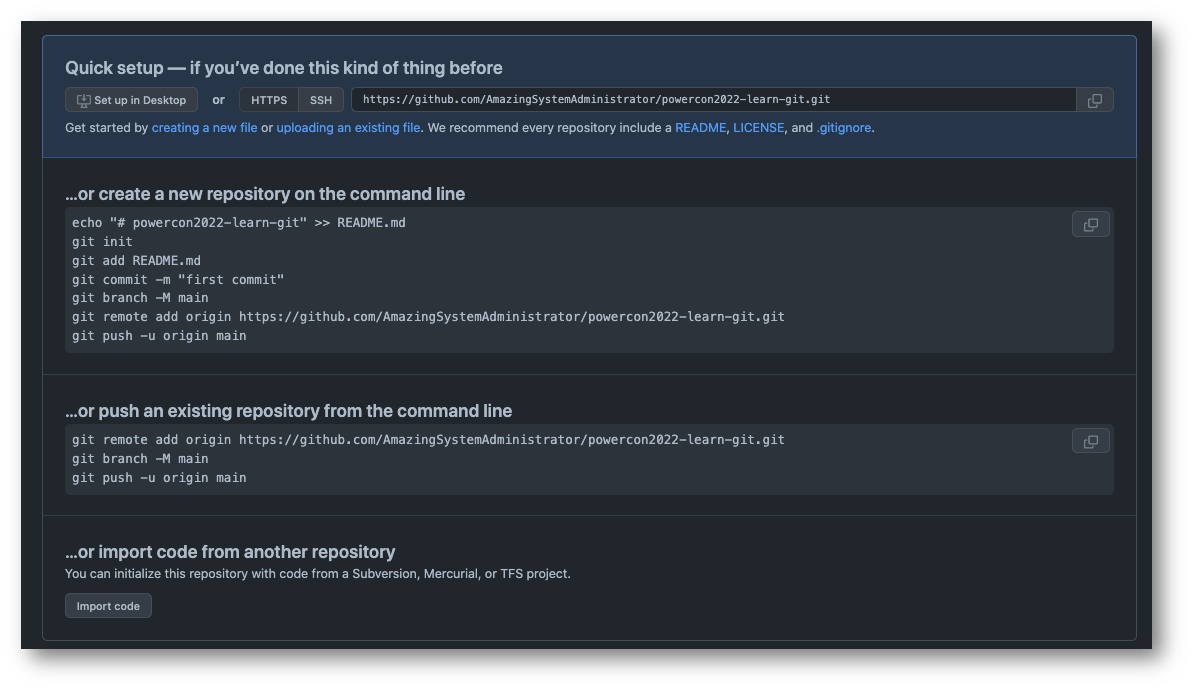
Vi ricordate tutte le informazioni che Github ci ha mostrato quando abbiamo creato il nostro primo repository? Ecco che tornano utili.
Come potete leggere dalla lista di comandi, molti dei quali abbiamo appena affrontato, adesso dobbiamo aggiungere la “remote origin” (il collegamento remoto) tra il nostro local repository e il repository remoto, cioè quello su Github.
Quindi:
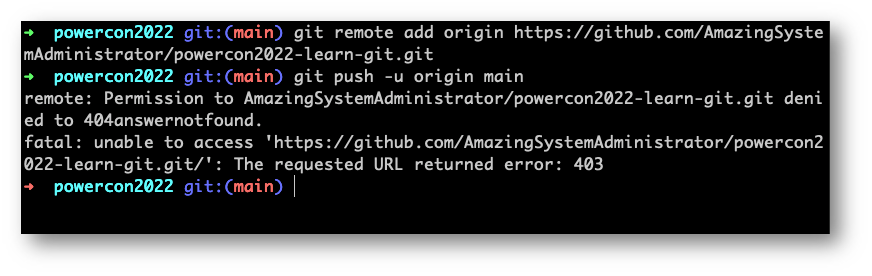
Se non abbiamo correttamente configurato il nostro utente per scrivere sul repository remoto che abbiamo creato su Github, oppure se stiamo utilizzando un utente diverso (come sto facendo io), dovremo andare a risolvere il problema sulle configurazioni del repository.
Con il vostro account personale non dovrete fare altro che seguire quanto descritto qui https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/creating-a-personal-access-token mentre nel caso di un repository utilizzato da più account, ad esempio per collaborare su un progetto open source, dobbiamo inserire chi può partecipare al repository.
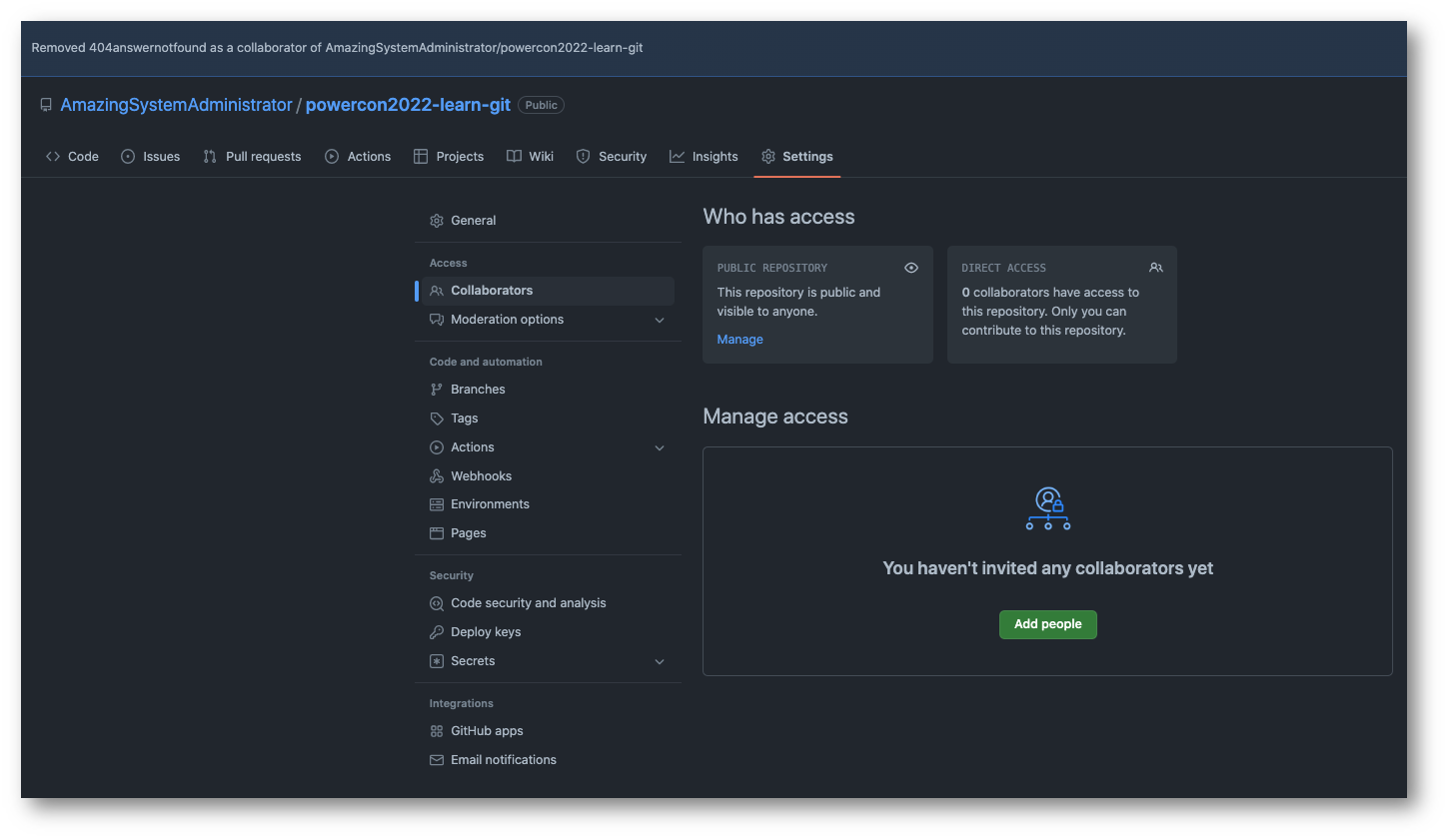
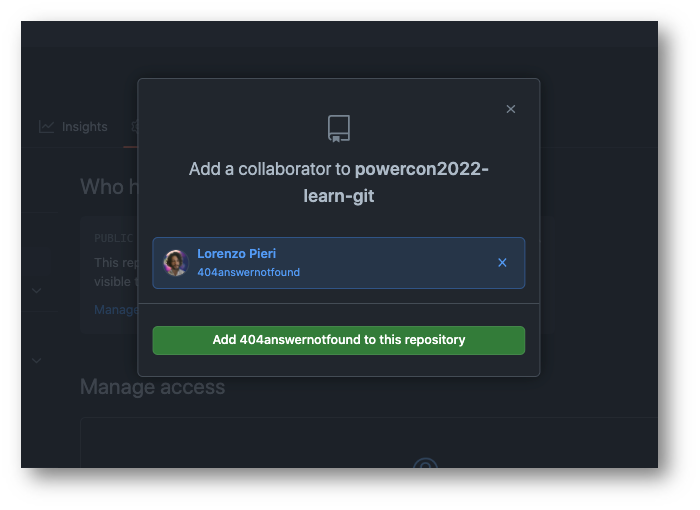
Tornando indietro al mio account personale su Github, troverò che, dopo aver accettato l’invito (che arriverà sia per mail che sulle notifiche di Github) avrò accesso alle funzioni di collaboratore diretto del repository.
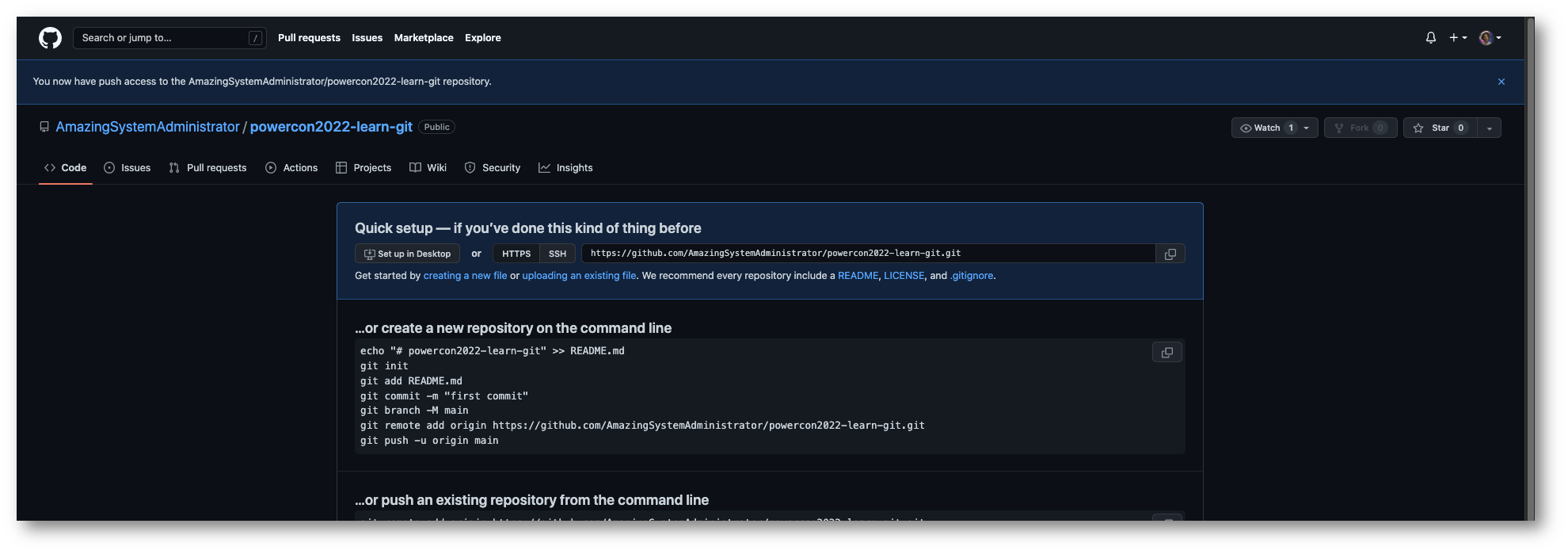
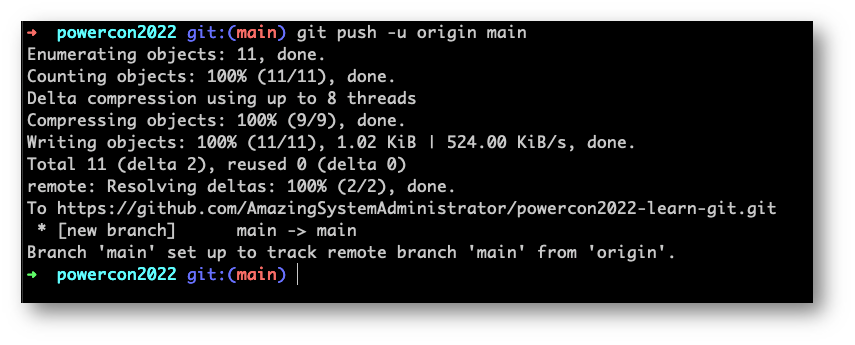
In questo modo potremo collaborare con altre persone su invito ma un modo ancora più vantaggioso e sicuro è quello che è noto come “Pull Request”.
In una “Pull Request”, il collaboratore “clona” – attraverso il comando “git clone” o scaricando direttamente il repository dalla piattaforma – il contenuto del repository e la sua storia, avrà quindi a disposizione tutti i commit, messaggi e log fatti sul repository fino a quel momento.
Per iniziare una Pull Request sarà sufficiente disporre del repository e lavorare su un branch (una linea, un ramo) diverso da quello principale, che è protetto e sul quale possono scrivere solo i “maintainer” del progetto.
Utilizziamo questo metodo e vediamo come lavorare e modificare il progetto così da permettere anche la review del nostro apporto prima che venga inserito nel “main branch”.
Andremo quindi a creare un nuovo ramo su cui lavorare e una piccola regola che a me piace seguire ci dice di chiamare quel ramo, quel branch, con un nome utile al riconoscimento di ciò che stiamo facendo sul repository. Aggiungeremo una feature, quindi il nome del ramo sarà “feature/script-hello-ictpower-world”
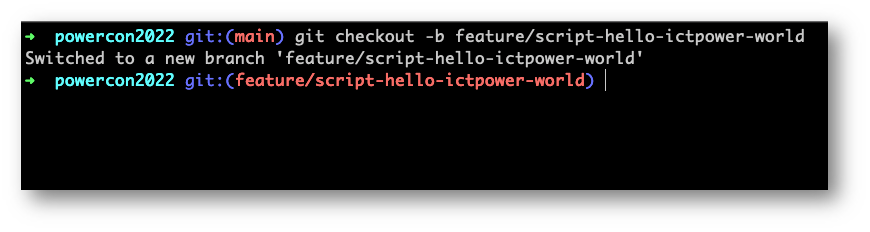
Torna quindi il comando checkout ma utilizzando il flag “-b” siamo in grado non sono di muoverci verso un commit, ma di creare un nuovo branch, una nuova ramificazione del nostro progetto, e spostarcisi sopra.
Adesso che abbiamo due branch e ogni branch avrà i propri commit, possiamo usare il nome del branch per spostarci verso di questo.
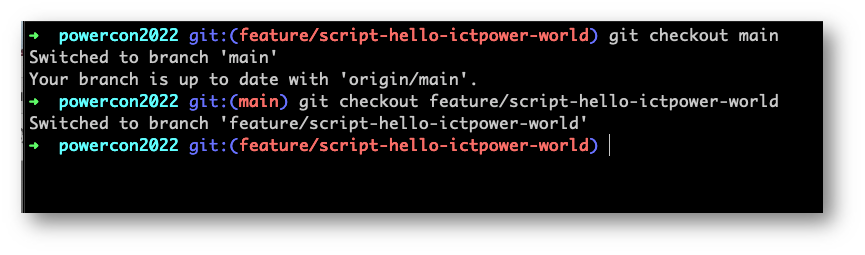
Questo branch ci sarà utile per fare le modifiche che vogliamo inserire e rendere commit per poi portarle online verso la remote origin di Github.
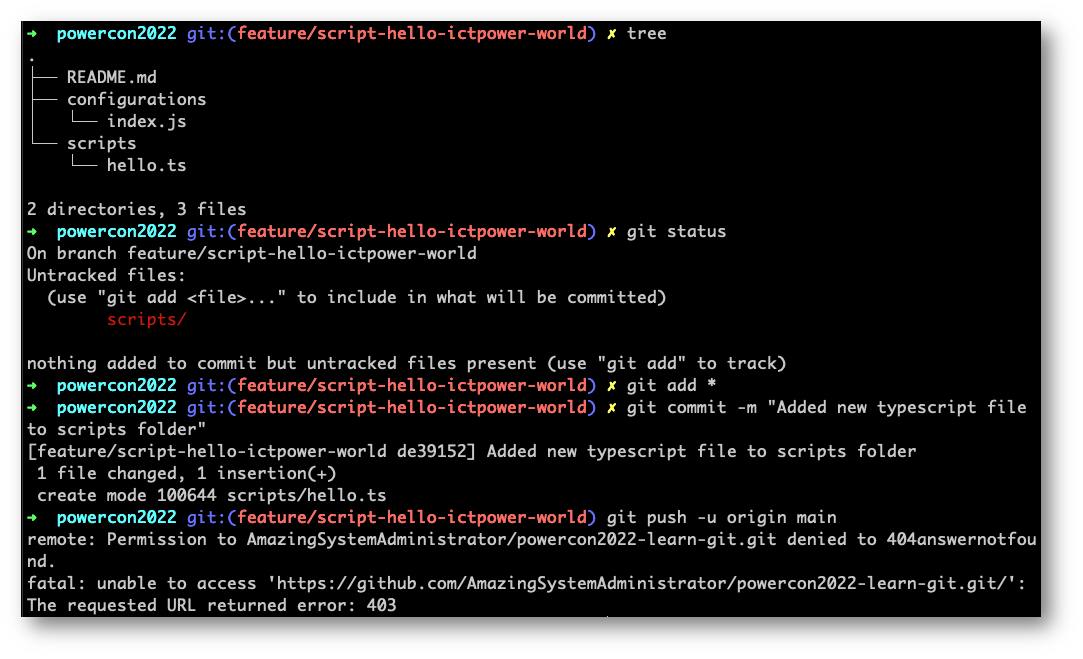
Siccome abbiamo modificato l’accesso diretto al repository, non sarà permesso il push direttamente su main ma dovremo inviare le nostre modifiche tramite il branch, creando così una pull request.
Il comando push, per come l’abbiamo visto, invia tutte le modifiche che sono state inserite nei commit verso la remote origin. Il comando pull, che vedremo più tardi, preleva tutte le modifiche che sono state inviate alla remote origin e che non abbiamo sul nostro local repository. Questo solitamente avviene in ambienti collaborativi dove più persone partecipano alla vita del progetto.
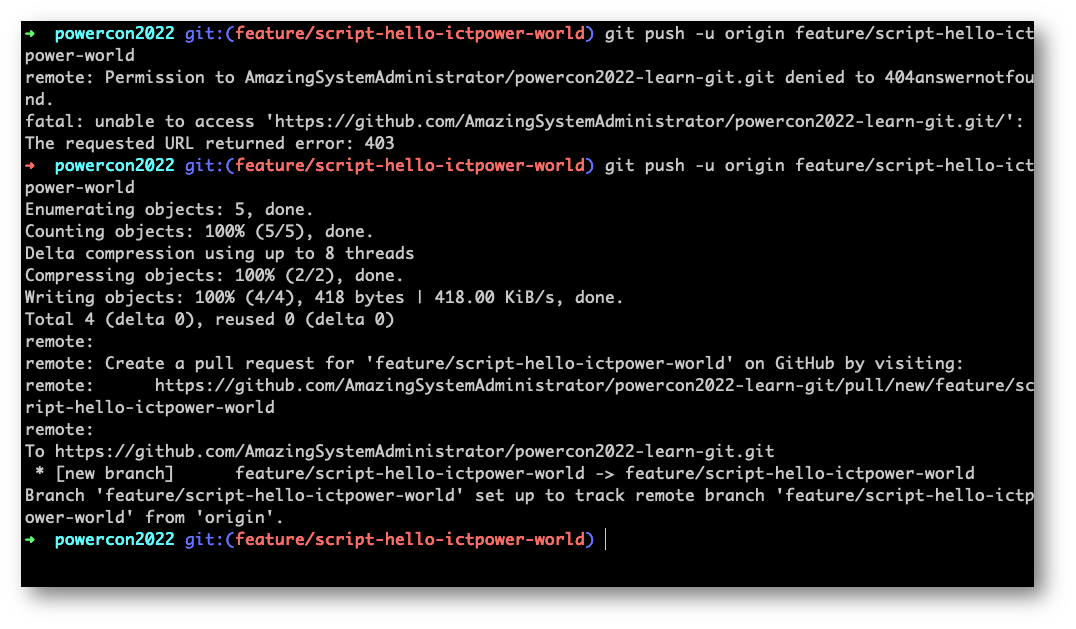
Sarà Git stesso a notificarci del fatto che abbiamo appena creato una Pull Request (PR) sulla nostra remote origin.
La PR dovrà essere richiesta su Github, direttamente sulla pagina del repository, da chi l’ha inviata. Io sto utilizzando il mio account Github personale (404answernotfound) e quindi andrò a vedere da lì!
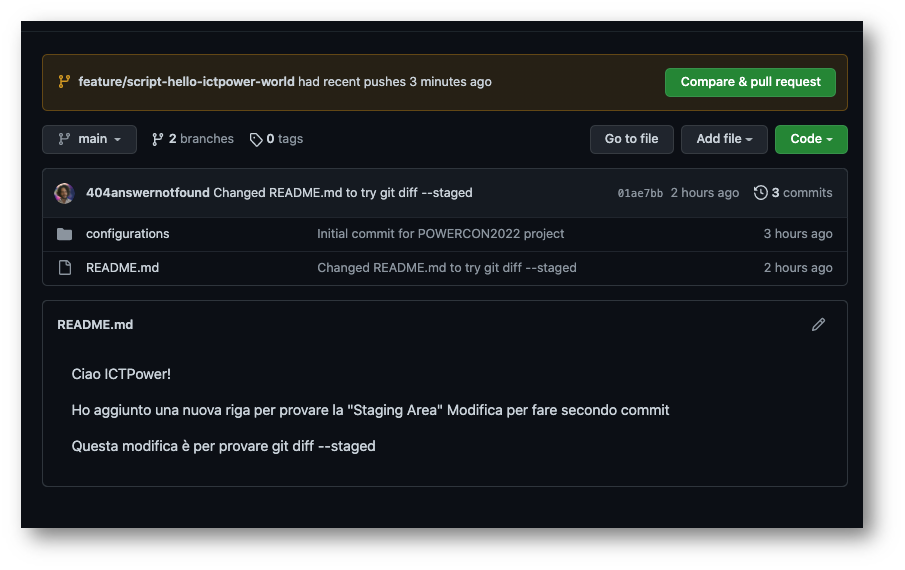
Troveremo la PR per fare “compare & pull request”, e siccome siamo collaboratori saremo in grado di farlo da soli. Nel caso non fossimo collaboratori ma avessimo voluto partecipare ad un progetto open source sarebbe stato necessario fare un “fork” e creare una “pull request” da quello, ma questo richiederà un altro articolo e un altro tutorial da fare insieme.
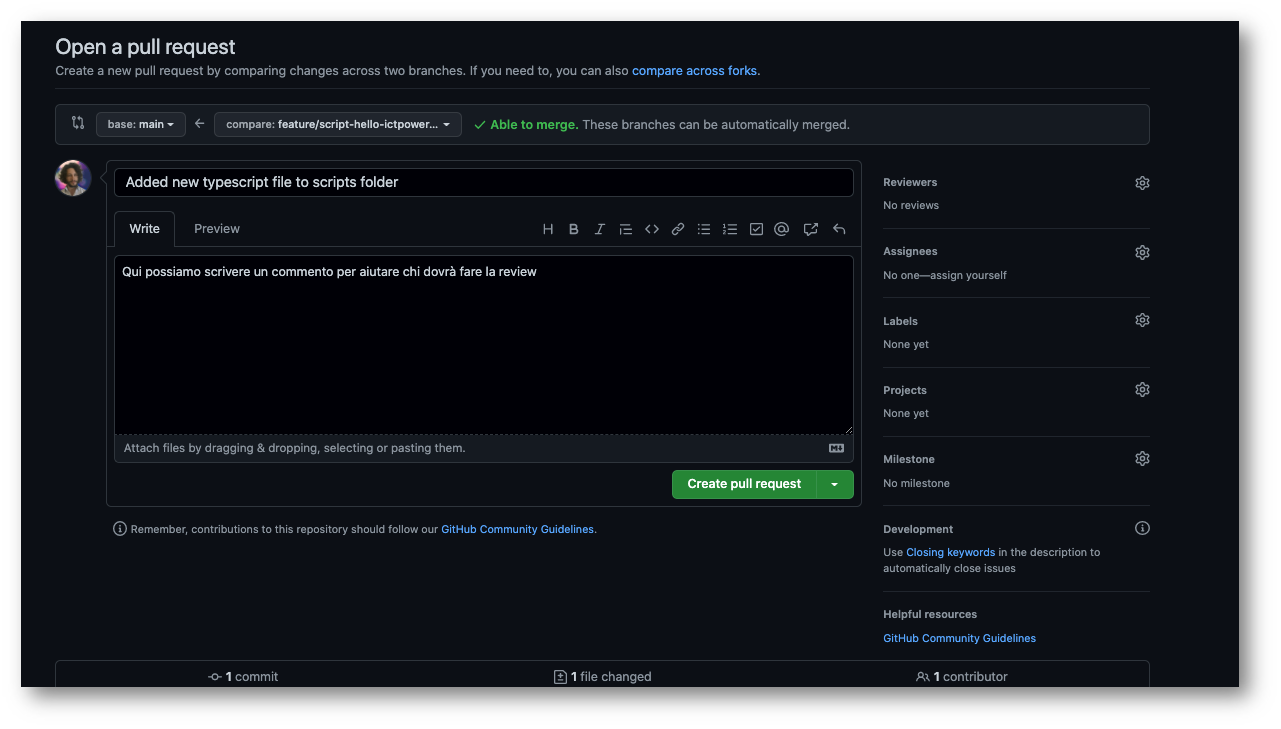
Apriamo la PR e aggiungiamo un commento che possa essere d’aiuto per chi dovrà fare la review, in questo caso noi.
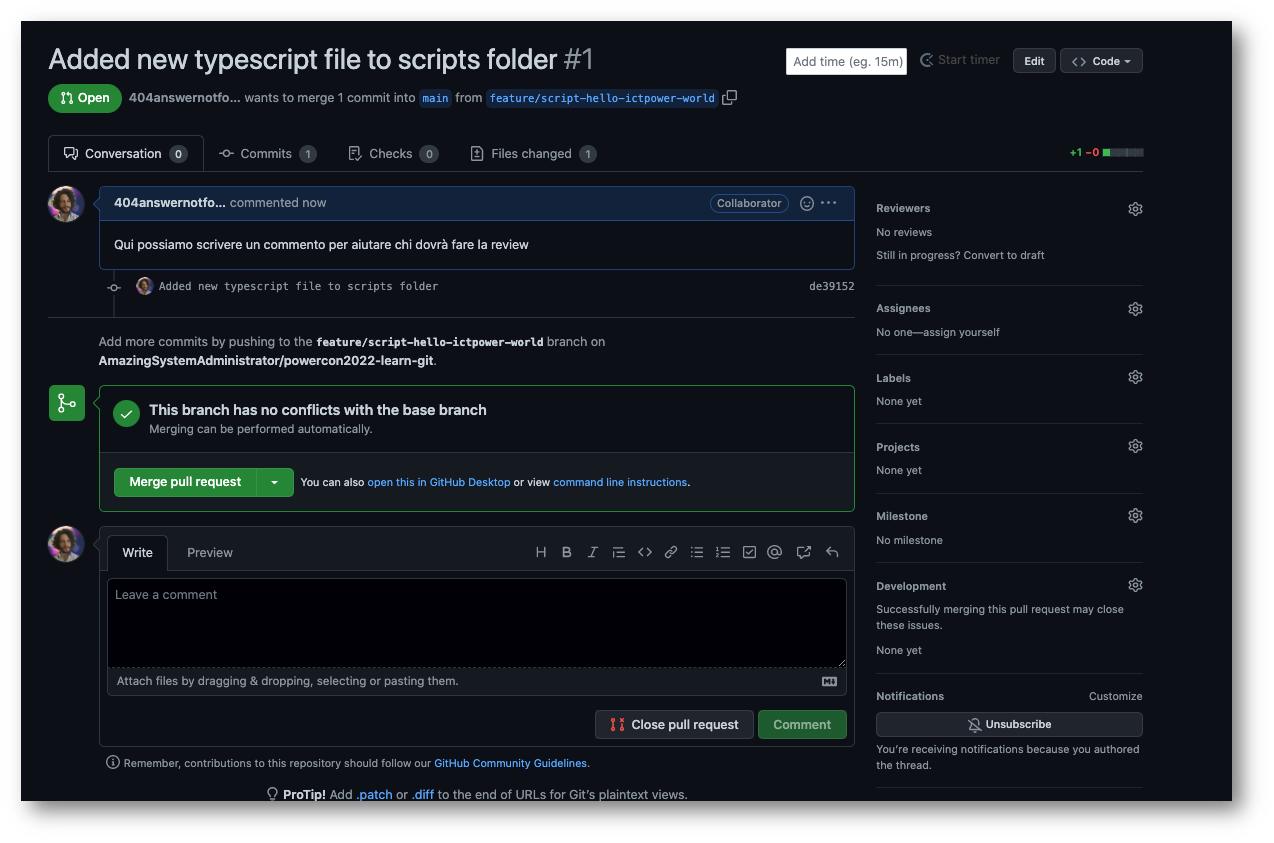
Il sistema, e se presente la pipeline di CI/CD, controlleranno che la merge request, nata dalla pull request appena creata, sia fattibile. In caso positivo ci sarà permessa la “Merge” e avremo a tutti gli effetti unito il codice del branch creato per la feature al codice del branch main, che è un branch protetto.
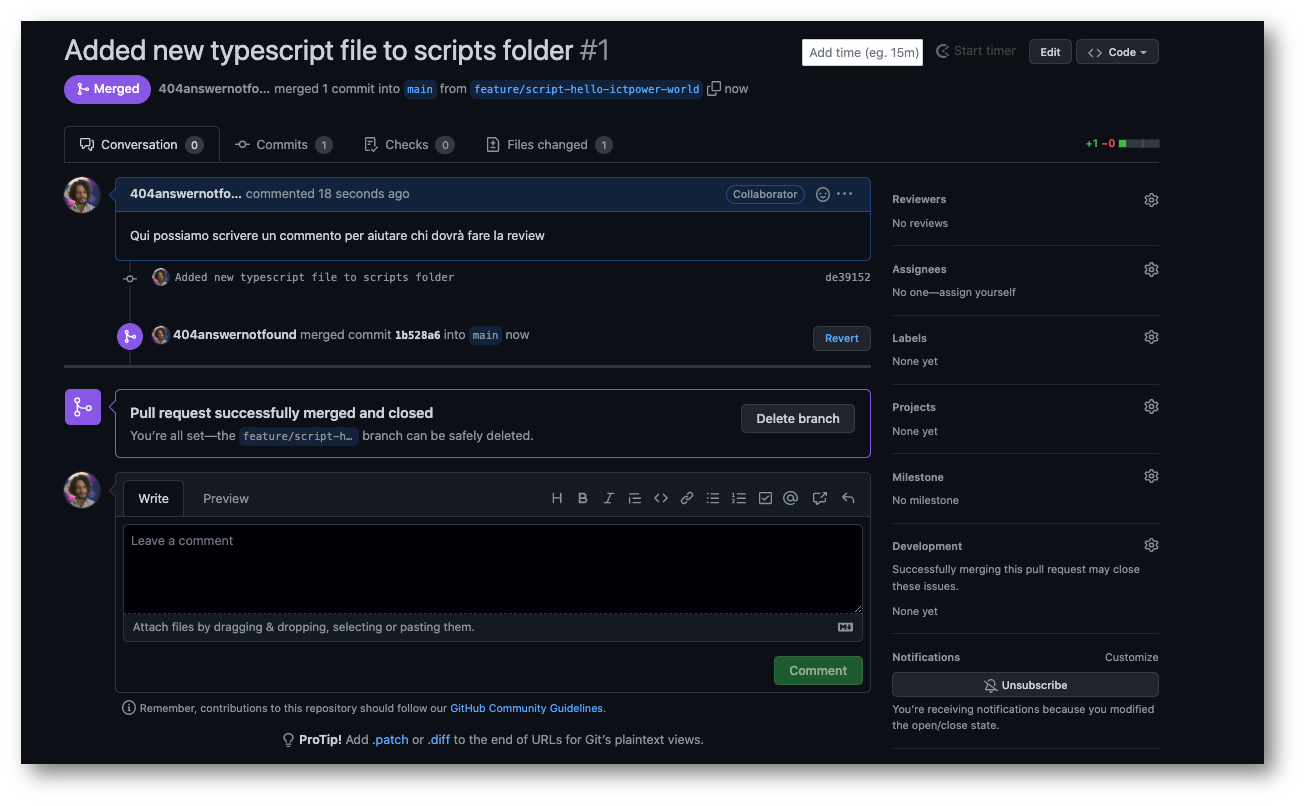
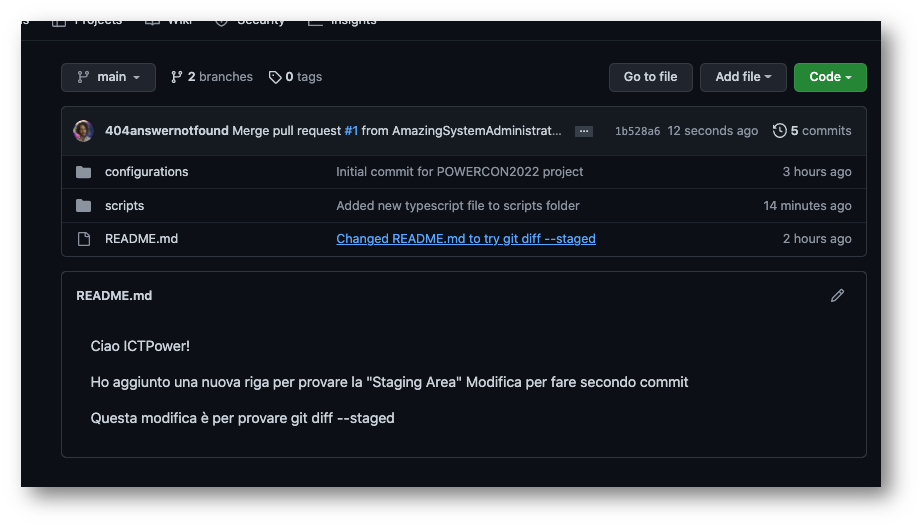
Risorse per continuare a studiare
Vi consiglio di studiare utilizzando queste risorse che troverete gratuitamente online.
- https://ohshitgit.com/
- https://rogerdudler.github.io/git-guide/
- https://learngitbranching.js.org/
- https://www.gitkraken.com/learn/git
- https://www.ciraltos.com/git-for-system-admin-scripting/
- https://skills.github.com/
- https://medium.com/ecuriosity/a-time-machine-for-programmers-aa3f04cf2afa
Come muoversi da qui in poi
Git sembra tanto semplice quanto complesso e i suoi usi sono molteplici e possono permettere il lavoro collaborativo in maniera efficace e efficiente, se utilizzati in maniera consapevole. Nei prossimi articoli sull’argomento andremo a vedere alcune pratiche un po’ più avanzate di Git e come collaborare su un progetto open source
Se intanto non sapete cosa fare, potete trovare altri articoli sul mio blog personale 404answernotfound.eu, e potete trovarmi su Twitter e LinkedIn!