

Apache Hadoop: BIG DATA a portata di Framework
Hadoop è un framework Open Source di Apache, concepito per offrire supporto ad applicazioni distribuite che elaborano grandi quantità di dati (Big Data) in parallelo, su cluster di grandi dimensioni (costituiti da migliaia di nodi), e semplificare le operazioni di storage e gestione di dataset assicurando un’elevata affidabilità e disponibilità.
Introduzione
Con la rapida diffusione dei Social Media, IoT (Internet of Things), tecnologie mobile e elettronica di consumo, il mercato IT e i colossi del ventunesimo secolo si sono adattati a gestire quantità di dati sempre superiori. Con i loro imponenti datacenter, si sono preoccupati di immagazzinare una grossa mole di dati per poi poterli analizzare e sfruttare a loro vantaggio. Con l’ausilio dei Big Data, che raccoglie dati di ogni tipo, è possibile studiare abitudini umane, creare reti sociali intelligenti, applicare concetti di business intelligence e tanto altro ancora.
“Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.” Definizione Gartnet
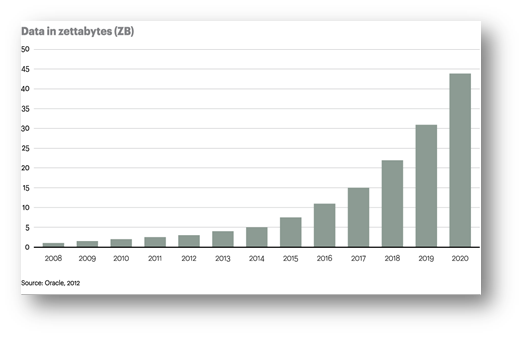
In uno studio Oracle del 2012, è stata fatta una previsione su come i dati mondiali immagazzinati aumenteranno; entro il 2020, infatti, dovranno essere gestiti circa 45 Zettabytes di dati.
Nel mondo dell’IT, i più grandi vendor si sono preoccupati di fornire una risposta a questa futura esigenza, fornendo servizi applicativi o infrastrutturali: Apache Hadoop, framework scritto in Java, nasce come progetto Open Source con l’obiettivo di distribuire grandi quantità di dati tramite Cluster di Server.
Apache Hadoop: How it’s work
Il framework è composto da tre moduli principali:
2. Hadoop Distributed File System (HDFS), file system distribuito dove vengono salvati i dati;
3. Hadoop YARN, Un framework per la pianificazione del lavoro e la gestione delle risorse del cluster;
4. Hadoop MapReduce, un modulo brevettato e introdotto da Google per supportare la computazione distribuita su grandi quantità di dati in cluster di computer.
MapReduce risulta essere il modulo alla base del successo di Apache Hadoop in quanto permette di distribuire grandi quantità di dati tra più nodi. Hadoop nella sua possibile configurazione NoSQL, tratta i dati adoperando la metodologia Key – Value, dove ogni dato viene associato in maniera univoca una chiave che sarà fondamentale per avviare il processo di MapReducing.

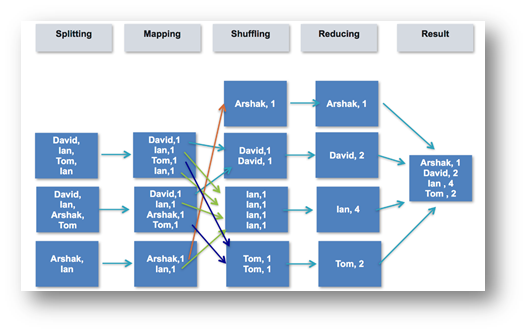
Nell’immagine è possibile notare il ciclo di vita di questo algoritmo, semplificato:
- Splitting, corrisponde ai vari dati che vengono separati tra vari nodi;
- Mapping, ad ogni dato viene associata una chiave univoca che lo indentifica;
- Shuffling, permette di associare e ordinare dati con chiave-valore identici;
- Reducing, si preoccupa di sommare i valori uguali;
- Result stampa l’output in un file system.
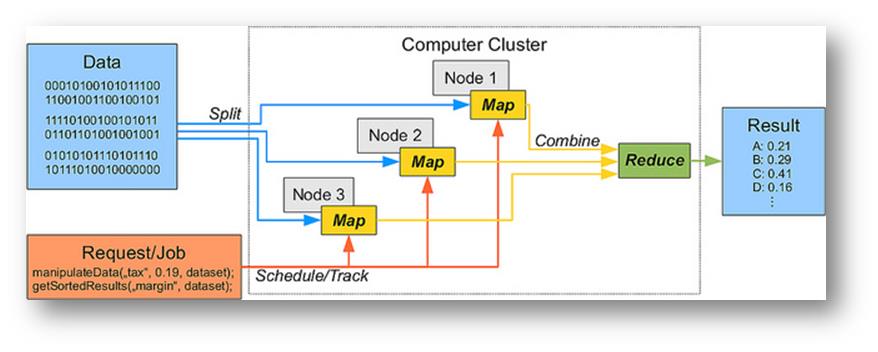
In figura si può notare una configurazione che distribuisce dati in input tra 3 nodi, applica il processo di Map e il conseguente JOB Reduce. Il Result viene immagazzinato in un file system che verrà distribuito.
Apache Hadoop, essendo un framework in grado di distribuire dati ridondandoli tra loro esistono 3 configurazioni diverse per gestire BIG DATA:
- Single Node;
- Pseudo-Distributed;
- Fully- Distributed.
Apache Hadoop è configurato inizialmente con i settaggi “Single Node”, dove per nodo singolo si intende un unico processo JAVA eseguito sulla macchina locale. Non sono eseguiti emulatori o processi e tutto viene eseguito tramite un’unica istanza JVM (Java virtual Machine). L’HDFS non viene adoperato ed è utilissimo solo in fase di debugging. Non è consigliato adoperare questa tipologia di configurazione per ambienti di produzione ma solo in fase di debugging.
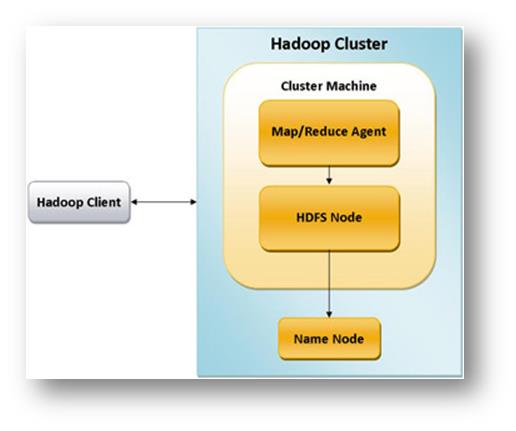
In questo caso, nel cluster Hadoop è presente un processo Java di MapReduce per trattare i dati del Client ed HDFS Node che risulta essere non Distribuito ma locale.
Il NameNode è il fulcro di un file system HDFS. Mantiene la struttura di directory di tutti i file nel file system, e traccia dove i dati vengono mantenuti nel cluster.
Nel caso di una configurazione “Pseudo- Distributed”, i processi vengono eseguiti sul server locale che simula un cluster di piccole dimensioni. Più processi Hadoop vengono eseguiti con più istanze JVM, ma sempre su un unico server. HDFS viene adoperato e sostituito al normale File System del server locale. Apache Hadoop nell’istanziare più processi Java permettono di emulare un nodo Master e nodi Slave.
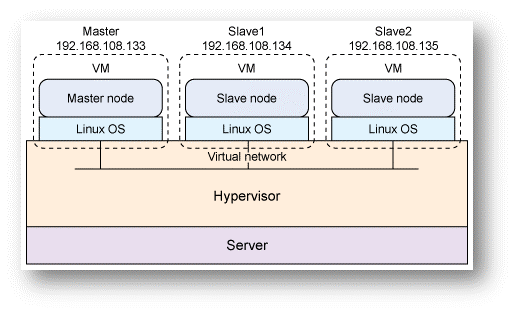
In questa configurazione, vengono istanziati più processi che simulano più server su un unico cluster collegati tra loro tramite rete virtuale. Il nodo Master tramite il processo YARN si preoccupa di allocare risorse e gestirle.
Nell’ultima tipologia di configurazione, devono essere creati N nodi collegati tra loro. È necessario configurare i nodi in rete tra loro e un Master che si occupa di gestire ed amministrare tutti i processi in corso sui di essi. Questa tipologia di configurazione permette di adottare misure base inerenti la Business continuity e Disaster Recovery in quanto uno o più nodi possono essere predisposti per effettuare la georeplica. È una configurazione ideale per ambienti di produzione medio-grandi con la possibilità di agire su tutti i nodi in qualunque momento.
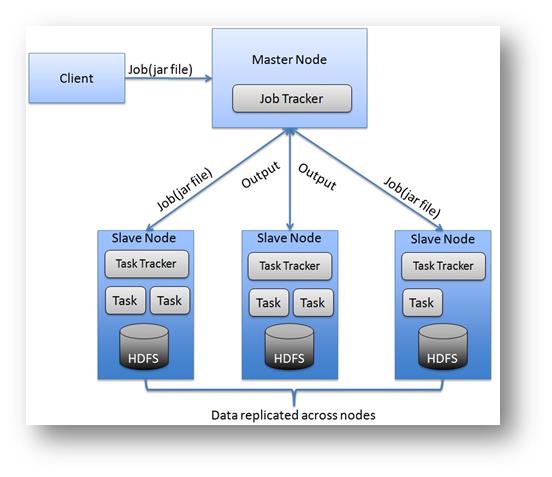
Osservando la figura è opportuno evidenziare come l’architettura in questo caso sia ben più complessa in quanto devono essere configurati N nodi Slave in rete, un nodo Master in grado di gestire gli SLAVE e i client con i loro applicativi in modo da poter interrogare e scrivere sui File System.
Nel prossimo approfondimento vedremo come configurare il framework per Big Data in una architettura Cloud Based su Microsoft Azure, in modo da poter testare la potenza di questo progetto Open Source usato dalle più grandi aziende del mondo.